Access Paths for Efficient Ordering with Large Language Models
Pith reviewed 2026-05-21 22:28 UTC · model grok-4.3
The pith
A budget-aware optimizer dynamically selects near-optimal access paths for LLM-based ordering that match or exceed the accuracy of the best static methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
No single physical implementation of semantic ordering is optimal across all datasets; a test-time scaling law links sorting cost to ordering quality for comparison-based methods; therefore a budget-aware optimizer that combines heuristics, LLM-as-Judge scoring, and consensus aggregation can choose access paths whose resulting ranking accuracy is on par with or better than the best static choice on every benchmark tested.
What carries the argument
The budget-aware optimizer for the LLM ORDER BY operator, which applies heuristic rules, LLM-as-Judge evaluation, and consensus aggregation to pick a near-optimal physical access path at runtime.
If this is right
- Runtime selection removes the need to commit to one sorting algorithm before seeing the data or the budget.
- Semantic ordering becomes practical for large tables because the merge-sort variant and the optimizer together control both cost and quality.
- LLM-powered database systems can treat ordering as an optimizable operator rather than a fixed black-box step.
- The same selection logic could be reused when other semantic operators are added to analytic pipelines.
Where Pith is reading between the lines
- Similar optimizers might later be applied to other LLM-based operators such as joins or filters.
- The observed cost-quality scaling could be used to set budgets automatically in production query planners.
- Extending the approach to streaming or incremental data would require only modest changes to the merge-sort component.
Load-bearing premise
That evaluations based on LLM-as-Judge with consensus aggregation produce stable, unbiased estimates of ordering quality that hold for datasets and models beyond those used in the study.
What would settle it
Apply the optimizer to a fresh dataset whose true ordering is known, run each static method to completion, and check whether the dynamically chosen path ever falls more than a small margin below the accuracy of the single best static method.
Figures




read the original abstract
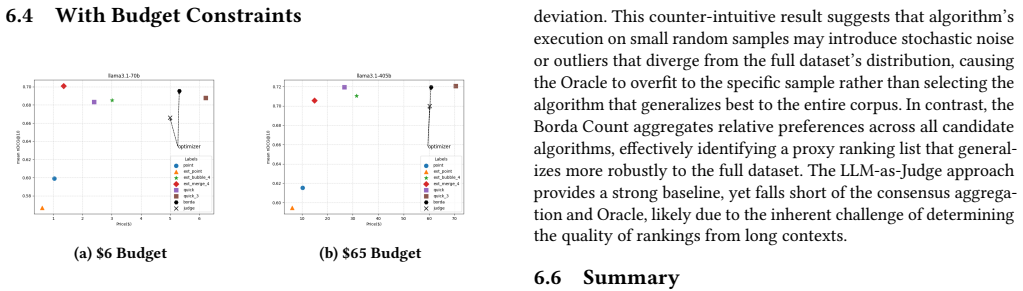
In this work, we present the \texttt{LLM ORDER BY} semantic operator as a logical abstraction and conduct a systematic study of its physical implementations. First, we propose several improvements to existing semantic sorting algorithms and introduce a semantic-aware external merge sort algorithm. Our extensive evaluation reveals that no single implementation offers universal optimality on all datasets. From our evaluations, we observe a general test-time scaling relationship between sorting cost and the ordering quality for comparison-based algorithms. Building on these insights, we design a budget-aware optimizer that utilizes heuristic rules, LLM-as-Judge evaluation, and consensus aggregation to dynamically select the near-optimal access path for LLM ORDER BY. In our extensive evaluations, our optimizer consistently achieves ranking accuracy on par with or superior to the best static methods across all benchmarks. We believe that this work provides foundational insights into the principled optimization of semantic operators essential for building robust, large-scale LLM-powered analytic systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the LLM ORDER BY semantic operator as a logical abstraction and systematically studies its physical implementations. It proposes improvements to existing semantic sorting algorithms along with a semantic-aware external merge sort, observes a general test-time scaling relationship between sorting cost and ordering quality for comparison-based methods, and designs a budget-aware optimizer that combines heuristic rules, LLM-as-Judge evaluation, and consensus aggregation to select near-optimal access paths. The central empirical claim is that this optimizer consistently achieves ranking accuracy on par with or superior to the best static methods across all benchmarks.
Significance. If the empirical results hold under proper validation, the work offers foundational insights into principled optimization of semantic operators for LLM-powered analytic systems. The systematic study of access paths, the introduction of a semantic-aware external merge sort, and the identification of a scaling relationship between cost and quality are concrete strengths that could inform future database designs integrating large language models.
major comments (2)
- [Evaluation section] Evaluation section: The headline claim that the optimizer 'consistently achieves ranking accuracy on par with or superior to the best static methods across all benchmarks' (abstract) rests on LLM-as-Judge evaluations with consensus aggregation, yet no correlation to human ground truth, inter-annotator agreement, or objective proxies (such as downstream query precision on labeled data) is reported. This assumption is load-bearing for the superiority result and risks circular reinforcement if the same judge mechanism influences both path selection and accuracy measurement.
- [Evaluation section] Evaluation section: The abstract reports high-level observations that no single method is universally optimal and that the optimizer matches or beats static baselines, but provides no quantitative error bars, dataset sizes, number of runs, or statistical tests. Without these, the reliability and generalizability of the central empirical claim cannot be assessed.
minor comments (1)
- [Abstract] The abstract could specify the concrete benchmarks, models, and dataset scales used in the 'extensive evaluations' to help readers immediately gauge the scope of the reported results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation methodology. We address each major comment below and will incorporate revisions to strengthen the empirical claims.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: The headline claim that the optimizer 'consistently achieves ranking accuracy on par with or superior to the best static methods across all benchmarks' (abstract) rests on LLM-as-Judge evaluations with consensus aggregation, yet no correlation to human ground truth, inter-annotator agreement, or objective proxies (such as downstream query precision on labeled data) is reported. This assumption is load-bearing for the superiority result and risks circular reinforcement if the same judge mechanism influences both path selection and accuracy measurement.
Authors: We agree that the shared use of LLM-as-Judge for both optimizer path selection and final accuracy measurement introduces a risk of circular reinforcement. In the revised manuscript, we will add a dedicated validation subsection that reports correlation between LLM-as-Judge scores and human annotations on a sampled subset of queries from each benchmark. We will also report inter-annotator agreement statistics and, where possible, an objective proxy such as precision on a labeled downstream task. This addition will clarify the reliability of the judge mechanism independent of the optimizer. revision: yes
-
Referee: [Evaluation section] Evaluation section: The abstract reports high-level observations that no single method is universally optimal and that the optimizer matches or beats static baselines, but provides no quantitative error bars, dataset sizes, number of runs, or statistical tests. Without these, the reliability and generalizability of the central empirical claim cannot be assessed.
Authors: We acknowledge that the current presentation lacks the quantitative details necessary for assessing reliability. In the revised evaluation section and abstract, we will explicitly report dataset sizes, the number of independent runs per experiment, error bars (standard deviation or confidence intervals), and results of statistical significance tests (e.g., paired t-tests or Wilcoxon tests) comparing the optimizer against the best static baseline on each benchmark. These additions will be placed in the main evaluation tables and text. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper derives its budget-aware optimizer from empirical observations of test-time scaling relationships between sorting cost and ordering quality, obtained through evaluations of multiple semantic sorting implementations including a proposed semantic-aware external merge sort. The optimizer then applies heuristic rules, LLM-as-Judge evaluations, and consensus aggregation to select access paths. Reported ranking accuracy is presented as an outcome of extensive benchmark comparisons against static methods. No equations, self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text that would make any central claim equivalent to its inputs by construction. The derivation remains self-contained via experimental methodology and independent benchmark results rather than tautological reuse of fitted values or prior author work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we design a budget-aware optimizer that utilizes heuristic rules, LLM-as-Judge evaluation, and consensus aggregation to dynamically select the near-optimal access path
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we observe a general test-time scaling relationship between sorting cost and the ordering quality for comparison-based algorithms
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Code-Switching Information Retrieval: Benchmarks, Analysis, and the Limits of Current Retrievers
Code-switching creates a fundamental performance bottleneck for multilingual retrievers, causing drops of up to 27% on new benchmarks CSR-L and CS-MTEB, with embedding divergence as the key cause and vocabulary expans...
Reference graph
Works this paper leans on
-
[1]
TruLens: Evals and Tracing for LLMs and Agents
[n.d.]. TruLens: Evals and Tracing for LLMs and Agents. https://www.trulens. org/. Accessed: 2025-11-25
work page 2025
-
[2]
Paritosh Aggarwal, Bowei Chen, Anupam Datta, Benjamin Han, Boxin Jiang, Nitish Jindal, Zihan Li, Aaron Lin, Pawel Liskowski, Jay Tayade, Dimitris Tsirogiannis, Nathan Wiegand, and Weicheng Zhao. 2025. Cortex AISQL: A Production SQL Engine for Unstructured Data. arXiv:2511.07663 [cs.DB] https://arxiv.org/abs/2511.07663
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Meta AI. 2024. Llama 3.1: Multilingual, Long-Context Large Language Models (8 B, 70 B, 405 B). https://ai.meta.com/blog/meta-llama-3-1/. Accessed: 2025-11-24
work page 2024
-
[4]
Ashwin Alaparthi, Paul Loh, and Ryan Marcus. 2025. ScaleLLM: A Technique for Scalable LLM-augmented Data Systems. InCompanion of the 2025 International Conference on Management of Data. 11–14
work page 2025
-
[5]
Amazon Web Services. 2024. Bringing Generative AI to the Data Warehouse with Amazon Bedrock and Amazon Redshift. https: //repost.aws/articles/ARJszlMEepRti6xoM-0fsBmw/bringing-generative- ai-to-the-data-warehouse-with-amazon-bedrock-and-amazon-redshift AWS re:Post article; accessed: 2025-08-17
work page 2024
-
[6]
Francesco Barbieri, Jose Camacho-Collados, Luis Espinosa-Anke, and Leonardo Neves. 2020. TweetEval: Unified Benchmark and Comparative Evaluation for Tweet Classification. InFindings of the Association for Computational Linguistics: EMNLP 2020. Association for Computational Linguistics, 1644–1650. https: //doi.org/10.18653/v1/2020.findings-emnlp.148
-
[7]
BerriAI. 2025. LiteLLM: Python SDK and proxy server for calling 100+ LLM APIs. GitHub repository. https://github.com/BerriAI/litellm Accessed: 2025-11-28
work page 2025
-
[8]
Gavin Brown, Mark Bun, Vitaly Feldman, Adam Smith, and Kunal Talwar. 2021. When is memorization of irrelevant training data necessary for high-accuracy learning?. InProceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing (STOC ’21). ACM, 123–132. https://doi.org/10.1145/3406325.3451131
-
[9]
Yu Chen, Ke Yi, Jun Zhang, and Guoliang Li. 2006. Two-Level Sampling for Join Size Estimation. InProceedings of the 2006 ACM SIGMOD International Conference on Management of Data (SIGMOD ’06). ACM, Chicago, Illinois, USA, 759–770. https://doi.org/10.1145/1142473.1142571
- [10]
- [11]
-
[12]
Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Campos, Ellen M. Voorhees, and Ian Soboroff. 2021. TREC Deep Learning Track: Reusable Test Collections in the Large Data Regime. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’21). ACM, 2369–2375. https://doi.org/10.1145/3404835.3463249
-
[13]
Andrew Drozdov, Honglei Zhuang, Zhuyun Dai, Zhen Qin, Razieh Rahimi, Xu- anhui Wang, Dana Alon, Mohit Iyyer, Andrew McCallum, Donald Metzler, et al
-
[14]
arXiv preprint arXiv:2310.14408(2023)
Parade: Passage ranking using demonstrations with large language models. arXiv preprint arXiv:2310.14408(2023)
-
[15]
Peter Emerson. 2013. The original Borda count and partial voting.Social Choice and Welfare40, 2 (2013), 353–358. https://doi.org/10.1007/s00355-011-0603-9
-
[16]
Avrilia Floratou, Fotis Psallidas, Fuheng Zhao, Shaleen Deep, Gunther Hagleither, Wangda Tan, Joyce Cahoon, Rana Alotaibi, Jordan Henkel, Abhik Singla, et al
-
[17]
Nl2sql is a solved problem... not!. InCIDR
- [18]
-
[19]
Phillip B. Gibbons and Yossi Matias. 1998. New Sampling-Based Summary Statistics for Improving Approximate Query Answers. InProceedings of the 1998 ACM SIGMOD International Conference on Management of Data (SIGMOD ’98). ACM, Seattle, Washington, USA, 331–342. https://doi.org/10.1145/276304.276346
- [20]
- [21]
-
[22]
Google Cloud. 2025. Introduction to AI and ML in BigQuery. https://cloud. google.com/bigquery/docs/bqml-introduction Accessed: 2025-08-17
work page 2025
-
[23]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. 2025. A Survey on LLM-as- a-Judge. arXiv:2411.15594 [cs.CL] https://arxiv.org/abs/2411.15594
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Zijian He, Reyna Abhyankar, Vikranth Srivatsa, and Yiying Zhang. 2025. Cognify: Supercharging gen-ai workflows with hierarchical autotuning. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 932–943
work page 2025
- [25]
-
[26]
Daomin Ji, Hui Luo, Zhifeng Bao, and Shane Culpepper. 2025. Table integration in data lakes unleashed: pairwise integrability judgment, integrable set discovery, and multi-tuple conflict resolution.The VLDB Journal34, 36 (2025). https: //doi.org/10.1007/s00778-025-00917-9
-
[27]
Maurice G Kendall. 1938. A new measure of rank correlation.Biometrika30, 1-2 (1938), 81–93
work page 1938
- [28]
-
[29]
Donald E. Knuth. 1997.The Art of Computer Programming(3 ed.). Vol. 1. Addison- Wesley, Reading, MA
work page 1997
-
[30]
Jiale Lao, Andreas Zimmerer, Olga Ovcharenko, Tianji Cong, Matthew Russo, Gerardo Vitagliano, Michael Cochez, Fatma Özcan, Gautam Gupta, Thibaud Hottelier, H. V. Jagadish, Kris Kissel, Sebastian Schelter, Andreas Kipf, and Im- manuel Trummer. 2025. SemBench: A Benchmark for Semantic Query Processing Engines. arXiv:2511.01716 [cs.DB] https://arxiv.org/abs/...
- [31]
-
[32]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al . 2023. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Processing Systems36 (2023), 42330–42357
work page 2023
-
[33]
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michi- hiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al
-
[34]
Holistic evaluation of language models.arXiv preprint arXiv:2211.09110 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Jimmy Lin, Xueguang Ma, Sheng-Chieh Lin, Jheng-Hong Yang, Ronak Pradeep, and Rodrigo Nogueira. 2021. Pyserini: A Python Toolkit for Reproducible Infor- mation Retrieval Research with Sparse and Dense Representations. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR)
work page 2021
-
[36]
Yiming Lin, Mawil Hasan, Rohan Kosalge, Alvin Cheung, and Aditya G. Parameswaran. 2025. TWIX: Automatically Reconstructing Structured Data from Templatized Documents. arXiv:2501.06659 [cs.DB] https://arxiv.org/abs/ 2501.06659
-
[37]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, Rana Shahout, et al. 2025. Palimpzest: Optimizing ai-powered analytics with declarative query processing. InProceedings of the Conference on Innovative Database Research (CIDR). 2
work page 2025
-
[38]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. Lost in the Middle: How Language Models Use Long Contexts. arXiv:2307.03172 [cs.CL] https://arxiv.org/abs/2307.03172
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Jian Luo, Xuanang Chen, Ben He, and Le Sun. 2024. Prp-graph: Pairwise rank- ing prompting to llms with graph aggregation for effective text re-ranking. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 5766–5776
work page 2024
- [40]
-
[41]
Conrado Martínez. 2004. Partial Quicksort. InProceedings of the 6th Workshop on Algorithm Engineering and Experiments and the 1st Workshop on Analytic Algorithmics and Combinatorics (ALENEX/ANALCO). SIAM, New Orleans, LA, USA, 1–8
work page 2004
-
[42]
Morris, Chawin Sitawarin, Chuan Guo, Narine Kokhlikyan, G
John X. Morris, Chawin Sitawarin, Chuan Guo, Narine Kokhlikyan, G. Edward Suh, Alexander M. Rush, Kamalika Chaudhuri, and Saeed Mahloujifar. 2025. How much do language models memorize? arXiv:2505.24832 [cs.CL] https: //arxiv.org/abs/2505.24832
- [43]
-
[44]
OpenAI. 2024. OpenAI FAQ: How should I set the temperature parameter? https://platform.openai.com/docs/faq/faq. Accessed: 2025-11-30
work page 2024
-
[45]
OpenAI. 2024. Structured model outputs. OpenAI API Guide. https://platform. openai.com/docs/guides/structured-outputs Structured outputs ensure model responses adhere to a supplied JSON Schema. Accessed: 2025-08-25
work page 2024
-
[46]
OpenIntro. 2025. NBA Player Heights (2008–09 Season). R package openintro, dataset nba_heights. Available at https://www.openintro.org/data/index.php? data=nba_heights, accessed 2025-08-25
work page 2025
-
[47]
Christos Chrysovalantis Papadopoulos, Alkis Simitsis, and Torben Bach Pedersen
-
[48]
InProceedings of the 41st IEEE International Conference on Data Engineering (ICDE)
HAIDES: Adaptive Approximation of Inference Queries over Unstructured Data. InProceedings of the 41st IEEE International Conference on Data Engineering (ICDE). 2394–2407
-
[49]
Liana Patel, Siddharth Jha, Carlos Guestrin, and Matei Zaharia. 2024. Lotus: Enabling semantic queries with llms over tables of unstructured and structured 13 data.arXiv e-prints(2024), arXiv–2407
work page 2024
-
[50]
Tanu Prabhu. 2020. Population by Country — 2020. https://www.kaggle.com/ datasets/tanuprabhu/population-by-country-2020. Accessed: 2025-11-24
work page 2020
- [51]
- [52]
-
[53]
Stephen Robertson, Hugo Zaragoza, et al . 2009. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends®in Information Retrieval 3, 4 (2009), 333–389
work page 2009
-
[54]
Donald G. Saari. 2023. Selecting a Voting Method: The Case for the Borda Count. Constitutional Political Economy34, 3 (2023), 357–366. https://doi.org/10.1007/ s10602-022-09380-y
work page 2023
- [55]
-
[56]
Dario Satriani, Enzo Veltri, Donatello Santoro, Sara Rosato, Simone Varriale, and Paolo Papotti. 2025. Logical and Physical Optimizations for SQL Query Execution over Large Language Models.Proceedings of the ACM on Management of Data3, 3 (2025), 1–28
work page 2025
-
[57]
P Griffiths Selinger, Morton M Astrahan, Donald D Chamberlin, Raymond A Lorie, and Thomas G Price. 1979. Access path selection in a relational database management system. InProceedings of the 1979 ACM SIGMOD international conference on Management of data. 23–34
work page 1979
-
[58]
Nihar B Shah and Martin J Wainwright. 2018. Simple, robust and optimal ranking from pairwise comparisons.Journal of machine learning research18, 199 (2018), 1–38
work page 2018
- [59]
-
[60]
Snowflake, Inc. 2025. Snowflake Cortex AISQL (including LLM functions). https://docs.snowflake.com/user-guide/snowflake-cortex/aisql?lang=de/ Pre- view feature documentation; accessed: 2025-08-17
work page 2025
- [61]
- [62]
-
[63]
Zhaoze Sun, Qiyan Deng, Chengliang Chai, Kaisen Jin, Xinyu Guo, Han Han, Ye Yuan, Guoren Wang, and Lei Cao. 2025. QUEST: Query Optimization in Unstructured Document Analysis. InProceedings of the VLDB Endowment
work page 2025
- [64]
-
[65]
Hongtao Wang, Taiyan Zhang, Renchi Yang, and Jianliang Xu. 2025. Cequel: Cost-Effective Querying of Large Language Models for Text Clustering. InPro- ceedings of the 34th ACM International Conference on Information and Knowl- edge Management (CIKM). Association for Computing Machinery, 2998–3008. https://doi.org/10.1145/3746252.3761074
-
[66]
Jiayi Wang, Yuan Li, Jianming Wu, Shihui Xu, and Guoliang Li. 2025. Unify: A System For Unstructured Data Analytics.Proceedings of the VLDB Endowment 18, 12 (2025), 5287–5290. https://doi.org/10.14778/3750601.3750653
-
[67]
Xinyi Wang, Antonis Antoniades, Yanai Elazar, Alfonso Amayuelas, Alon Al- balak, Kexun Zhang, and William Yang Wang. 2025. Generalization v.s. Mem- orization: Tracing Language Models’ Capabilities Back to Pretraining Data. arXiv:2407.14985 [cs.CL] https://arxiv.org/abs/2407.14985
-
[68]
Yining Wang, Liwei Wang, Yuanzhi Li, Di He, and Tie-Yan Liu. 2013. A theoretical analysis of NDCG type ranking measures. InConference on learning theory. PMLR, 25–54
work page 2013
-
[69]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reason- ing in large language models.Advances in neural information processing systems 35 (2022), 24824–24837
work page 2022
-
[70]
Rui Wen, Zheng Li, Michael Backes, and Yang Zhang. 2024. Membership Inference Attacks Against In-Context Learning. InProceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security (CCS ’24). ACM, Salt Lake City, UT, USA, 3481–3495. https://doi.org/10.1145/3658644.3690306
-
[71]
Sampling-Based Query Re-Optimization
Wentao Wu, Jeffrey F. Naughton, and Harneet Singh. 2016. Sampling-Based Query Re-Optimization. arXiv:1601.05748 [cs.DB] https://arxiv.org/abs/1601. 05748
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[72]
Jialin Yang, Dongfu Jiang, Lipeng He, Sherman Siu, Yuxuan Zhang, Disen Liao, Zhuofeng Li, Huaye Zeng, Yiming Jia, Haozhe Wang, Benjamin Schneider, Chi Ruan, Wentao Ma, Zhiheng Lyu, Yifei Wang, Yi Lu, Quy Duc Do, Ziyan Jiang, Ping Nie, and Wenhu Chen. 2025. StructEval: Benchmarking LLMs’ Capabilities to Generate Structural Outputs. arXiv:2505.20139 [cs.SE]...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [73]
- [74]
- [75]
- [76]
-
[77]
Fuheng Zhao, Shaleen Deep, Fotis Psallidas, Avrilia Floratou, Divyakant Agrawal, and Amr El Abbadi. 2024. Sphinteract: Resolving Ambiguities in NL2SQL through User Interaction.Proceedings of the VLDB Endowment18, 4 (2024), 1145–1158
work page 2024
-
[78]
Zhanhao Zhao, Shaofeng Cai, Haotian Gao, Hexiang Pan, Siqi Xiang, Naili Xing, Gang Chen, Beng Chin Ooi, Yanyan Shen, Yuncheng Wu, and Meihui Zhang. 2025. NeurDB: On the Design and Implementation of an AI-powered Autonomous Database. arXiv:2408.03013 [cs.DB] https://arxiv.org/abs/2408.03013
-
[79]
Lixi Zhou, Qi Lin, Kanchan Chowdhury, Saif Masood, Alexandre Eichenberger, Hong Min, Alexander Sim, Jie Wang, Yida Wang, Kesheng Wu, et al. 2024. Serv- ing Deep Learning Models from Relational Databases.Advances in Database Technology-EDBT27, 3 (2024), 717–724
work page 2024
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.