MD-PNOP: Equation-Recast Neural Operators for Minimal-Data Extrapolation and PDE Solver Acceleration
Pith reviewed 2026-05-18 19:57 UTC · model grok-4.3
The pith
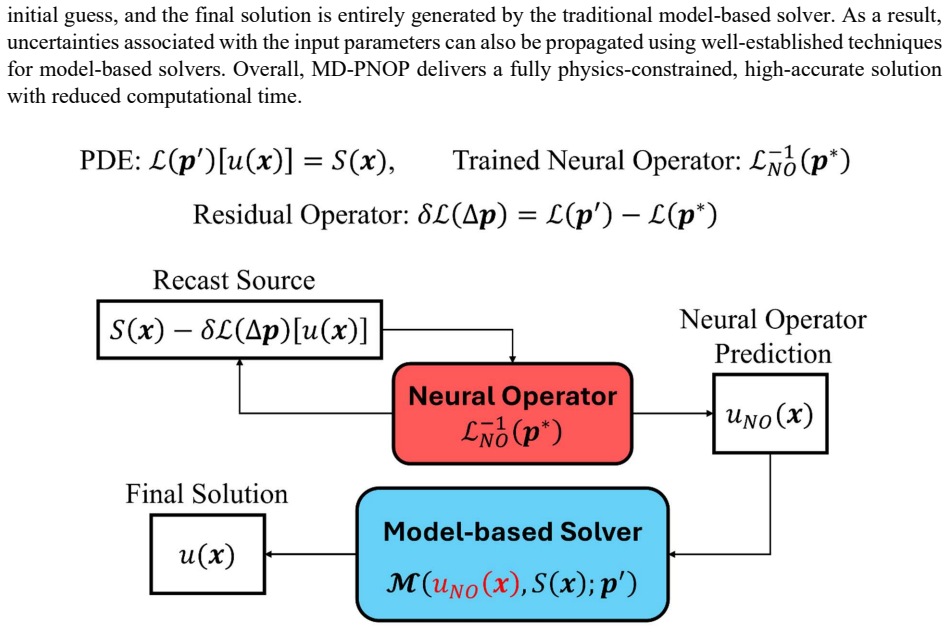
A neural operator trained on one constant parameter set accelerates PDE solutions for heterogeneous, sinusoidal, and discontinuous parameters by treating operator mismatches as source terms inside an iterative solver.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The MD-PNOP framework recasts the difference between the true parameter-dependent operator and a pretrained neural operator as additional source terms. These source terms are incorporated into an iterative solution scheme, allowing the pretrained operator to serve as an improved initial guess for solving PDEs with heterogeneous, sinusoidal, or discontinuous parameter distributions. This enables extrapolation from a single training configuration without retraining while guaranteeing that the governing equations are fully satisfied at convergence.
What carries the argument
The equation-recast formulation that represents the parameter-induced operator difference as an additive source term incorporated into the iterative PDE solver.
If this is right
- Neural operators trained only on constant parameters accelerate solutions for heterogeneous, sinusoidal, and discontinuous parameter distributions.
- The approach achieves approximately 50 percent reduction in computational time.
- Full-order fidelity is maintained for fixed-source, single-group eigenvalue, and multigroup coupled eigenvalue problems.
- The framework works with both DeepONet and FNO architectures and preserves the original physics constraints.
Where Pith is reading between the lines
- The same recast idea could lower the amount of training data needed for parametric neural operators by removing the requirement to sample many different parameter combinations upfront.
- Because the iteration step remains unchanged, the method may transfer to other iterative PDE solvers used in fluid flow or structural mechanics without major redesign.
- Faster per-solve times could shorten outer optimization loops that repeatedly vary material properties or boundary conditions.
Load-bearing premise
The difference between the true parameter-dependent operator and the pretrained neural operator can be represented as an additive source term that the iterative solver corrects without introducing persistent bias or requiring retraining.
What would settle it
Applying the method to a new discontinuous or highly varying parameter field and finding that the iterative solver either diverges or converges to a solution whose error exceeds that of a direct high-fidelity solve would falsify the central claim.
Figures









read the original abstract
The computational overhead of traditional numerical solvers for partial differential equations (PDEs) remains a critical bottleneck for large-scale parametric studies and design optimization. We introduce a Minimal-Data Parametric Neural Operator Preconditioning (MD-PNOP) framework, which establishes a new strategy for accelerating parametric PDE solvers while strictly preserving physical constraints. To address the extrapolation limitation of neural operators, parameter-induced operator difference is recast as additional source terms and incorporated into an iterative solution scheme using a pretrained neural operator. This equation-recast formulation enables systematic parameter extrapolation from a single training configuration to a broad range of unseen parameter settings without retraining. The neural operator predictions are then embedded into iterative PDE solvers as improved initial guesses, thereby reducing convergence iterations without sacrificing accuracy. Unlike purely data-driven approaches, MD-PNOP guarantees that the governing equations remain fully enforced, eliminating concerns regarding loss of physics or interpretability. The framework is architecture-agnostic and is demonstrated using both DeepONet and FNO for Boltzmann transport equation solvers in neutron transport applications. Numerical results demonstrate that neural operators trained on a single set of constant parameters successfully accelerate solutions with heterogeneous, sinusoidal, and discontinuous parameter distributions. Moreover, MD-PNOP consistently achieves approximately 50% reduction in computational time while maintaining full-order fidelity for fixed-source, single-group eigenvalue, and multigroup coupled eigenvalue problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the MD-PNOP framework, which recasts parameter-induced differences in the governing operator as additive source terms within an iterative PDE solver. A neural operator (DeepONet or FNO) is pretrained on a single constant-parameter configuration and used solely as an improved initial guess; the iteration then enforces the original physics. Numerical demonstrations on Boltzmann transport problems claim successful extrapolation to heterogeneous, sinusoidal, and discontinuous parameter fields, with an approximately 50% reduction in wall-clock time while preserving full-order fidelity for fixed-source, single-group eigenvalue, and multigroup coupled eigenvalue problems.
Significance. If the central claim holds, the work provides a practical route to minimal-data extrapolation for neural operators by hybridizing them with traditional iterative solvers rather than relying on direct data-driven prediction. This architecture-agnostic approach could be valuable for parametric studies in neutron transport and similar fields where retraining per parameter distribution is prohibitive. The explicit preservation of the governing equations is a clear strength relative to purely learned surrogates.
major comments (2)
- [Numerical results (as summarized in abstract)] The central claim of full-order fidelity for discontinuous parameter distributions rests on the assertion that the recast source term produces a contraction whose fixed point satisfies the unmodified equations. No convergence analysis or residual plots are supplied to confirm that lag in source evaluation or non-smoothness of the difference operator does not leave a persistent bias, especially in the eigenvalue cases.
- [Numerical results (as summarized in abstract)] The reported ~50% computational-time reduction is presented without error bars, iteration-count histograms, or ablation of the source-term approximation quality. It is therefore impossible to determine whether the speedup is robust across problem sizes or merely an artifact of the chosen test cases.
minor comments (2)
- [Abstract] The abstract states that the framework is demonstrated with both DeepONet and FNO, yet no comparative table or figure isolating the effect of architecture choice is referenced.
- [Methods] Notation for the recast source term and the precise definition of the operator difference should be introduced with an equation number in the methods section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary and constructive major comments. We address each point below with clarifications on the mathematical structure and concrete proposals for additional numerical evidence in the revision.
read point-by-point responses
-
Referee: The central claim of full-order fidelity for discontinuous parameter distributions rests on the assertion that the recast source term produces a contraction whose fixed point satisfies the unmodified equations. No convergence analysis or residual plots are supplied to confirm that lag in source evaluation or non-smoothness of the difference operator does not leave a persistent bias, especially in the eigenvalue cases.
Authors: We appreciate the referee drawing attention to this point. The recast formulation defines the source term to exactly compensate for the parameter-induced operator difference, so that any fixed point of the iteration satisfies the original unmodified equations regardless of lagging: if the base operator satisfies L0(u) = f - Delta(u), then L0(u) + Delta(u) = f recovers the target operator. While a full contraction mapping proof is not provided, the fixed-point property holds by construction even for non-smooth Delta. To empirically verify absence of persistent bias, we will add residual histories and convergence plots for the discontinuous-parameter and eigenvalue cases in the revised manuscript, showing residuals driven to solver tolerance without offset. revision: yes
-
Referee: The reported ~50% computational-time reduction is presented without error bars, iteration-count histograms, or ablation of the source-term approximation quality. It is therefore impossible to determine whether the speedup is robust across problem sizes or merely an artifact of the chosen test cases.
Authors: We agree that the current presentation would benefit from additional statistical detail. In the revised manuscript we will report the time-reduction metric with error bars computed over repeated runs, include histograms of iteration counts for each problem class (fixed-source, single-group eigenvalue, multigroup), and add an ablation comparing source-term quality when the neural-operator prediction is used versus a simple lagged iterate. These additions will allow assessment of robustness beyond the specific test cases shown. revision: yes
Circularity Check
No significant circularity: MD-PNOP uses physics-enforcing iteration with NO as non-load-bearing initial guess
full rationale
The paper's core derivation recasts the parameter-induced operator difference explicitly as an additive source term inside a standard iterative PDE solver. The neural operator (pretrained on a single constant-parameter case) supplies only an improved initial guess; convergence and accuracy are guaranteed by the outer iteration enforcing the unmodified governing equations to full-order tolerance. This structure is self-contained against external benchmarks: the final output satisfies the original PDE by construction of the solver, not by redefinition or fitting of the neural prediction itself. No self-definitional equations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided derivation chain. The method is therefore a hybrid preconditioner whose central claim (extrapolation without retraining plus ~50% speedup) rests on the iterative correction step rather than on any tautological reduction to the training data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Iterative PDE solvers converge to the correct solution when supplied with a sufficiently accurate initial guess.
Reference graph
Works this paper leans on
-
[1]
Introduction Partial differential equations (PDEs) are fundamental tools for modeling and analyzing a wide range of scientific and engineering problems [1]. However, as engineering systems continue to increase in complexity, numerical methods have become indispensable for solving PDEs. Traditional model-based solvers, including the finite difference, fini...
-
[2]
Motivation and Research Objectives Despite the rapid advancements in neural network-based models for scientific and engineering applications, several critical challenges still hinder their widespread practical deployment. First, data acquisition and the associated computational cost remain major obstacles [20]. Generating high-fidelity simulation data req...
-
[3]
Minimal-Data Parametric Neural Operator Preconditioning (MD-PNOP) Framework In this section, the methodology of the MD-PNOP framework is discussed. We begin with the perturbation- theory-inspired equation recast, which reformulates parameter variations as additional source terms. This recast is the key to enabling systematic parametric generalization from...
-
[4]
Neural Operator Architectures An operator is a mathematical entity which, when applied to a function, produces another function [1]. Recently, neural operators have gained significant attention for solving PDEs and have demonstrated superior generalization performance compared to traditional neural networks [5]. Serving as surrogates for analytical soluti...
-
[5]
Case Study: Neutron Transport Equation In this section, the proposed MD-PNOP framework is demonstrated using the one-dimensional neutron transport equation (NTE). The NTE, as a specific form of the Boltzmann transport equation, plays a crucial role in various scientific and engineering applications, including nuclear reactor design, radiation shielding, a...
-
[6]
Conclusion In this work, we developed the Minimal-Data Parametric Neural Operator Preconditioning (MD-PNOP) framework to accelerate solvers for partial differential equations (PDEs). MD-PNOP offers a generalizable approach to integrate neural operators into traditional numerical solvers while maintaining full physics constraints and full-order accuracy. B...
-
[7]
L. C. Evans, Lawrence, Partial differential equations, Vol. 19, American mathematical society (2022)
work page 2022
-
[8]
Three ways to solve partial di fferential equa- tions with neural networks - A review,
J. Blechschmidt, and O. G. Ernst, Three ways to solve partial differential equations with neural networks — A review, GAMM-Mitteilungen, 4:e202100006 (2021). https://doi.org/10.1002/gamm.202100006
-
[9]
S. L. Brunton, and J. N. Kutz, Promising directions of machine learning for partial differential equations, Nat. Comput. Sci., 4, pp. 483-494 (2024). https://doi.org/10.1038/s43588-024-00643-2
-
[10]
M. Raissi, P. Perdikaris, and G.E. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, Journal of Computational Physics, 378, pp. 686-707 (2019). https://doi.org/10.1016/j.jcp.2018.10.045
-
[11]
K. Azizzadenesheli, N. Kovachki, Z. Li, M. Liu-Schiaffini, J. Kossaifi, and A. Anandkumar, Neural operators for accelerating scientific simulations and design, Nat. Rev. Phys, 6, pp. 320-328 (2024). https://doi.org/10.1038/s42254-024-00712-5
-
[12]
M. Raissi, A. Yazdani, and G. E. Karniadakis, Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations, Science, 367, pp. 1026-1030 (2020). https://10.1126/science.aaw4741
-
[13]
S. Cai, Z. Wang, S. Wang, P. Perdikaris, and G. E. Karniadakis, Physics-Informed Neural Networks for Heat Transfer Problems, ASME. J. Heat Transfer, 143(6): 060801 (2021). https://doi.org/10.1115/1.4050542
-
[14]
J. Wang, X. Peng, Z. Chen, B. Zhou, Y. Zhou, and N. Zhou, Surrogate modeling for neutron diffusion problems based on conservative physics-informed neural networks with boundary conditions enforcement, Annals of Nuclear Energy, 176, 109234 (2022) https://doi.org/10.1016/j.anucene.2022.109234
-
[15]
W. Ji, W. Qiu, Z. Shi, S. Pan, and S. Deng, Stiff-PINN: Physics-Informed Neural Network for Stiff Chemical Kinetics, The Journal of Physical Chemistry A, 125 (36), pp. 8098-8106 (2021). https://10.1021/acs.jpca.1c05102
-
[16]
T. Grossmann, U. Komorowska, J. Latz, and C. Schönlieb, Can physics-informed neural networks beat the finite element method?, IMA Journal of Applied Mathematics, 89(1), pp. 143-174 (2024). https://doi.org/10.1093/imamat/hxae011
-
[17]
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, and K. Bhattacharya, A. Stuart, and A. Anandkumar, Fourier Neural Operator for Parametric Partial Differential Equations, International Conference on Learning Representations (2021). https://arxiv.org/abs/2010.08895v3
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
L. Lu, P. Jin, G. Pang, Z. Zhang, and G. E. Karniadakis, Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators, Nature Machine Intelligence, 3, pp. 218- 229 (2021). https://doi.org/10.1038/s42256-021-00302-5
-
[19]
G. Wen, Z. Li, K. Azizzadenesheli, A. Anandkumar, and S, M. Benson, U-FNO—An enhanced Fourier neural operator-based deep-learning model for multiphase flow, Advances in Water Resources, 163, 104180 (2022). https://doi.org/10.1016/j.advwatres.2022.104180
-
[20]
V. Gopakumar, S. Pamela, L. Zanisi, and et. al., Plasma surrogate modelling using Fourier neural operators, Nuclear Fusion, 64, 056025 (2024). https://10.1088/1741-4326/ad313a
-
[21]
H. You, Q. Zhang, C. J. Ross, C. Lee, and Y. Yu, Learning deep Implicit Fourier Neural Operators (IFNOs) with applications to heterogeneous material modeling, Computer Methods in Applied Mechanics and Engineering, 398, 115296 (2022). https://doi.org/10.1016/j.cma.2022.115296
-
[22]
S. Goswami, M. Yin, Y. Yu, and G. E. Karniadakis, A physics-informed variational DeepONet for predicting crack path in quasi-brittle materials, Computer Methods in Applied Mechanics and Engineering, 391, 114587 (2022). https://doi.org/10.1016/j.cma.2022.114587
-
[23]
Q. Cheng, M. H. Sahadath, H. Yang, S. Pan, and W. Ji, Surrogate Modeling of Heat Transfer under Flow Fluctuation Conditions using Fourier Basis-Deep Operator Network with Uncertainty Quantification, Progress in Nuclear Energy, 188, 105895 (2025). https://doi.org/10.1016/j.pnucene.2025.105895
-
[24]
M. H. Sahadath, Q. Cheng, S. Pan, and W. Ji, Deep Operator Network Based Surrogate Model for Neutron Transport Computation, Proceedings of International Conference on Mathematics and Computational Methods Applied to Nuclear Science & Engineering (M&C2025), Denver CO, USA, April 27-30, 2025
work page 2025
-
[25]
K. Kobayashi, and S. B. Alam, Deep neural operator-driven real-time inference to enable digital twin solutions for nuclear energy systems, Scientific Reports, 14, 2101 (2024). https://doi.org/10.1038/s41598-024-51984-x
-
[26]
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, and L. Yang, Physics-informed machine learning, Nat. Rev. Phys., 3, pp. 422-440 (2021). https://doi.org/10.1038/s42254-021-00314-5
-
[27]
Z. Jiang, J. Jiang, Q. Yao, and G. Yang, A neural network-based PDE solving algorithm with high precision, Sci. Rep., 13, 4479 (2023). https://doi.org/10.1038/s41598-023-31236-0
-
[28]
C. He, M. Ma, and P. Wang, Extract interpretability-accuracy balanced rules from artificial neural networks: A review, Neurocomputing, 387, pp. 346-358 (2020). https://doi.org/10.1016/j.neucom.2020.01.036
-
[29]
L. Lu, X. Meng, S. Cai, Z. Mao, S. Goswami, Z. Zhang, and G. E. Karniadakis, A comprehensive and fair comparison of two neural operators (with practical extensions) based on FAIR data, Computer Methods in Applied Mechanics and Engineering, 393, 114778 (2022). https://doi.org/10.1016/j.cma.2022.114778
-
[30]
Svd perspectives for augmenting deeponet flexibility and interpretability
S. Venturi, and T. Casey, SVD perspectives for augmenting DeepONet flexibility and interpretability, Computer Methods in Applied Mechanics and Engineering, 403, 115718 (2023). https://doi.org/10.1016/j.cma.2022.115718
-
[31]
F. Lehmann, F. Gatti, M. Bertin, and D. Clouteau, 3D elastic wave propagation with a Factorized Fourier Neural Operator (F-FNO), Computer Methods in Applied Mechanics and Engineering, 420, 116718 (2024). https://doi.org/10.1016/j.cma.2023.116718
-
[32]
S. Qin, D. Zhan, D. Geng, W. Peng, G. Tian, Y. Shi, N. Gao, X. Liu, and L. Wang, Modeling multivariable high-resolution 3D urban microclimate using localized Fourier neural operator, Building and Environment, 273, 112668 (2025). https://doi.org/10.1016/j.buildenv.2025.112668
-
[33]
K. Li, and W. Ye, D-FNO: A decomposed Fourier neural operator for large-scale parametric partial differential equations, Computer Methods in Applied Mechanics and Engineering, 436, 117732 (2025). https://doi.org/10.1016/j.cma.2025.117732
-
[34]
Z. Zhong, and Y. Gohar, Shielding design and analyses of KIPT neutron source facility, Progress in Nuclear Energy, 53(1), pp. 92-99 (2011). https://doi.org/10.1016/j.pnucene.2010.08.002
-
[35]
J. P. Franz and N. F. Simcic, Nuclear Reactor Start-Up Simulation, in IRE Transactions on Nuclear Science, 4(1), pp. 11-14 (1957). https://10.1109/TNS2.1957.4315572
-
[36]
Goertzel, The Method of Discrete Ordinates, Nuclear Science and Engineering, 4(4), pp
G. Goertzel, The Method of Discrete Ordinates, Nuclear Science and Engineering, 4(4), pp. 581-587 (1958). https://doi.org/10.13182/NSE58-A28835
-
[37]
D.C. Sahni, and N.G. Sjöstrand, Criticality and time eigenvalues in one-speed neutron transport, Progress in Nuclear Energy, 23(3), pp. 241-289 (1990). https://doi.org/10.1016/0149-1970(90)90004-O
-
[38]
Nuclear Power: A Sustainable Resource
B. Nease, F. Brown, and T. Ueki, Dominance ratio calculations with MCNP, International Conference on the Physics of Reactors “Nuclear Power: A Sustainable Resource” (PHYSOR-2008), Interlaken, Switzerland, September 14-19 (2008)
work page 2008
-
[39]
K.A. Dominesey, and W. Ji, Reduced-order modeling of neutron transport separated in energy by Proper Generalized Decomposition with applications to reactor physics, Journal of Computational Physics, 449, 110744 (2022). https://doi.org/10.1016/j.jcp.2021.110744
-
[40]
Y. Li, and W. Ji, Pebble Flow and Coolant Flow Analysis Based on a Fully Coupled Multiphysics Model, Nuclear Engineering and Science, 173, 150-162 (2013). https://doi.org/10.13182/NSE12-13
-
[41]
J. P. Senecal, and W. Ji, Development of an efficient tightly coupled method for multiphysics reactor transient analysis, Progress in Nuclear Energy, 103, pp. 33-44 (2018). https://doi.org/10.1016/j.pnucene.2017.10.012
-
[42]
H. Yang, Q. Cheng, L. Zou, R. Hu, and W. Ji, Multiphase Species Transport Modeling for Molten Salt Reactors in the System Analysis Module: Generation, Decay, Deposition, and Extraction of Insoluble Fission Products, Nuclear Technology, 211, pp. 1960-1985 (2025). https://doi.org/10.1080/00295450.2024.2421678
-
[43]
A. Paszke, et al., PyTorch: An Imperative Style, High-Performance Deep Learning Library, Advances in Neural Information Processing Systems 32, Curran Associates, Inc., pp. 8024-8035 (2019)
work page 2019
-
[44]
D. P. Kingma, and J. Ba, Adam: A Method for Stochastic Optimization, in Proceeding of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, California, USA, May 7-9 (2015)
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.