Correlates of Image Memorability in Vision Encoders: Activations, Attention Entropy, Patch Uniformity and Autoencoder Losses
Pith reviewed 2026-05-18 19:52 UTC · model grok-4.3
The pith
Reconstruction loss from sparse autoencoders on vision encoder representations strongly correlates with human image memorability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
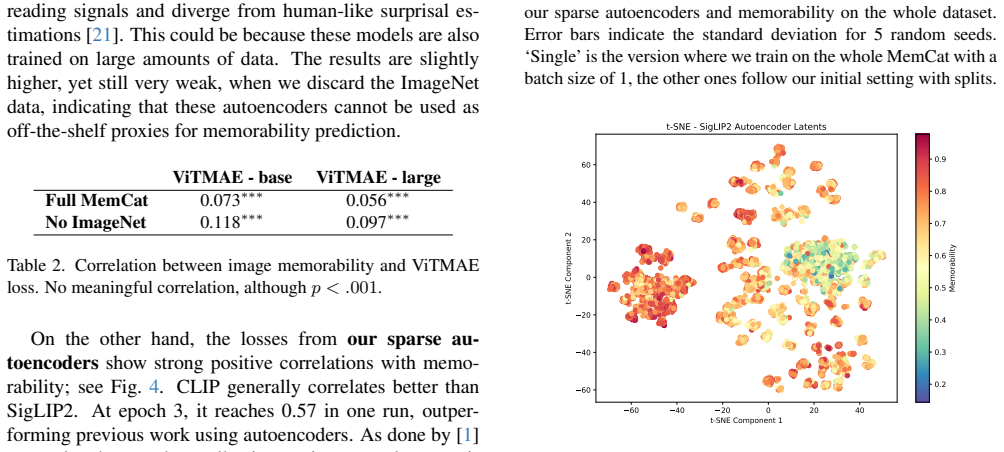
The central claim is that sparse autoencoder reconstruction loss, when applied to the feature representations of pretrained transformer-based vision encoders, functions as a stronger correlate of image memorability than prior methods that relied on convolutional neural network representations. Activations, attention distributions, and patch uniformity also show some correlation, but the autoencoder loss is presented as the most informative predictor among the features examined.
What carries the argument
Sparse autoencoder reconstruction loss computed over the latent representations of vision transformers, serving as a proxy that measures how faithfully the input features can be recovered from a compressed code.
If this is right
- Vision encoder features can be used to estimate memorability without additional human annotation for each new image.
- Reconstruction difficulty in sparse autoencoders captures memorability signals better than earlier convolutional approaches.
- Attention entropy and patch uniformity provide secondary but weaker signals about what makes an image memorable.
- Model-internal reconstruction losses may generalize across different pretrained vision transformers.
Where Pith is reading between the lines
- Designers could use this loss to filter or prioritize training images that are likely to be remembered by downstream models or users.
- Similar autoencoder losses might be tested as proxies for other human judgments such as visual saliency or aesthetic preference.
- If the correlation holds across domains, it could inform data curation pipelines that aim to maximize retention of visual information.
Load-bearing premise
The sparse autoencoder loss on vision encoder representations acts as a valid and generalizable proxy for human memorability without direct validation against memorability labels during training.
What would settle it
Gather fresh human memorability ratings for a held-out image set and test whether the autoencoder loss ranks those images in the same order as the human scores, with higher accuracy than CNN-based baselines.
Figures






read the original abstract
Images vary in how memorable they are to humans. Inspired by findings from cognitive science and computer vision, we explore correlates of image memorability in pretrained transformer-based vision encoders for the first time. Focusing initially on activations, attention distributions, and the uniformity of image patches, we find that these features correlate with memorability to some extent. Additionally, we explore sparse autoencoder loss over the representations of vision encoders as a proxy for memorability, which yields results outperforming past methods using convolutional neural network representations. Our results shed light on the relationship between model-internal features and memorability. They show that some features are informative predictors of what makes images memorable to humans; revealing that, in particular, the reconstruction loss from our autoencoders is a strong correlate of image memorability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper explores correlates of human image memorability in pretrained vision transformer encoders. It examines activations, attention entropy, and patch uniformity as initial features that show moderate correlations, then introduces sparse autoencoder reconstruction loss computed on the encoder representations as a stronger proxy that outperforms prior CNN-based methods. The central claim is that this reconstruction loss serves as a particularly effective, label-independent correlate of memorability.
Significance. If the reported correlations hold under proper controls, the work would provide a useful bridge between model-internal representations and human memory, with the SAE loss offering a potentially more generalizable and outperforming alternative to earlier feature-based predictors. The approach could inform both cognitive modeling and applications such as image selection or data curation, especially if the method generalizes across datasets without requiring memorability labels during training.
major comments (2)
- [Methods (autoencoder training)] Methods section on sparse autoencoders: the manuscript does not specify whether the SAE training set is disjoint from the memorability-labeled images used for correlation analysis. If the SAE is fit on the same source distribution, the per-image reconstruction loss may simply measure dataset typicality rather than a genuine link to memorability mechanisms, undermining the claim that it functions as a generalizable proxy.
- [Abstract and Results] Results and abstract: no statistical details, sample sizes, error bars, p-values, or cross-validation procedures are provided to support the claim that autoencoder loss 'outperforms past methods.' Without these, it is impossible to assess whether the reported superiority is robust or merely descriptive.
minor comments (2)
- [Methods] Notation for attention entropy and patch uniformity should be defined explicitly with equations in the methods section to allow replication.
- [Figures] Figure captions for correlation plots should include the exact number of images and the memorability dataset source.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment below, indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Methods (autoencoder training)] Methods section on sparse autoencoders: the manuscript does not specify whether the SAE training set is disjoint from the memorability-labeled images used for correlation analysis. If the SAE is fit on the same source distribution, the per-image reconstruction loss may simply measure dataset typicality rather than a genuine link to memorability mechanisms, undermining the claim that it functions as a generalizable proxy.
Authors: We agree that explicit specification of the training data is necessary to rule out typicality confounds. The SAE was trained on a large, publicly available dataset (a disjoint subset of ImageNet) separate from all memorability-labeled evaluation images. We will revise the Methods section to describe the SAE architecture, training objective, data sources, and explicit confirmation of the disjoint split, thereby strengthening the interpretation of the reconstruction loss as a generalizable proxy. revision: yes
-
Referee: [Abstract and Results] Results and abstract: no statistical details, sample sizes, error bars, p-values, or cross-validation procedures are provided to support the claim that autoencoder loss 'outperforms past methods.' Without these, it is impossible to assess whether the reported superiority is robust or merely descriptive.
Authors: The referee is correct that the current manuscript version omits these details in the abstract and main results. We will add the relevant sample sizes (number of images and participants), error bars on correlation figures, p-values for all reported correlations, and descriptions of the statistical tests and cross-validation procedures used to compare the SAE loss against prior CNN-based predictors. These additions will appear in the revised Results section and updated abstract. revision: yes
Circularity Check
No significant circularity in derivation of autoencoder loss as memorability correlate
full rationale
The paper computes sparse autoencoder reconstruction losses directly from pretrained vision-encoder activations as an independent feature, then measures post-hoc correlation against external human memorability labels. No equation or step reduces the reported loss to a memorability parameter by construction, nor does any self-citation chain or ansatz smuggle in the target result. The derivation is self-contained feature extraction followed by correlation analysis against an independent benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained transformer vision encoders capture features that relate to human image memorability
Reference graph
Works this paper leans on
-
[1]
Elham Bagheri and Yalda Mohsenzadeh. Modeling visual memorability assessment with autoencoders reveals charac- teristics of memorable images, 2025. 1, 2, 3, 4
work page 2025
-
[2]
Wilma A. Bainbridge. Chapter one - memorability: How what we see influences what we remember. In Knowledge and Vision, pages 1–27. Academic Press, 2019. 1
work page 2019
-
[3]
Timothy F. Brady, Talia Konkle, George A. Alvarez, and Aude Oliva. Visual long-term memory has a massive stor- age capacity for object details. Proceedings of the National Academy of Sciences, 105(38):14325–14329, 2008. 1
work page 2008
-
[4]
Intrinsic and extrinsic ef- fects on image memorability.Vision Research, 116:165–178,
Zoya Bylinskii, Phillip Isola, Constance Bainbridge, Anto- nio Torralba, and Aude Oliva. Intrinsic and extrinsic ef- fects on image memorability.Vision Research, 116:165–178,
-
[5]
Computational Models of Visual Attention. 1
-
[6]
Memorability: An Image-Computable Mea- sure of Information Utility , pages 207–239
Zoya Bylinskii, Lore Goetschalckx, Anelise Newman, and Aude Oliva. Memorability: An Image-Computable Mea- sure of Information Utility , pages 207–239. Springer Inter- national Publishing, Cham, 2022. 1
work page 2022
-
[7]
Visual attention-driven spatial pooling for image memorability
Bora Celikkale, Aykut Erdem, and Erkut Erdem. Visual attention-driven spatial pooling for image memorability. In 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 976–983, 2013. 1, 2
work page 2013
-
[8]
Fergus I.M. Craik and Robert S. Lockhart. Levels of process- ing: A framework for memory research. Journal of Verbal Learning and Verbal Behavior, 11(6):671–684, 1972. 1, 2
work page 1972
-
[9]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 2
work page 2009
-
[10]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representa- tions, 2021. 1, 2
work page 2021
-
[11]
Memcat: a new category-based image set quantified on memorability.PeerJ, 7:e8169, 2019
Lore Goetschalckx and Johan Wagemans. Memcat: a new category-based image set quantified on memorability.PeerJ, 7:e8169, 2019. 1, 2
work page 2019
-
[12]
Image memorability prediction with vision transformers, 2023
Thomas Hagen and Thomas Espeseth. Image memorability prediction with vision transformers, 2023. 1
work page 2023
-
[13]
Masked autoencoders are scal- able vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollar, and Ross Girshick. Masked autoencoders are scal- able vision learners. In Proceedings - 2022 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, CVPR 2022, pages 15979–15988. IEEE Computer Society, 2022. Publisher Copyright: © 2022 IEEE.; 2022 IEEE/CVF Con- ference on Computer V...
work page 2022
-
[14]
Understanding the intrinsic memorability of images
Phillip Isola, Devi Parikh, Antonio Torralba, and Aude Oliva. Understanding the intrinsic memorability of images. In Ad- vances in Neural Information Processing Systems . Curran Associates, Inc., 2011. 1
work page 2011
-
[15]
What makes an image memorable? In CVPR 2011, pages 145–152, 2011
Phillip Isola, Jianxiong Xiao, Antonio Torralba, and Aude Oliva. What makes an image memorable? In CVPR 2011, pages 145–152, 2011. 1
work page 2011
-
[16]
Phillip Isola, Jianxiong Xiao, Devi Parikh, Antonio Torralba, and Aude Oliva. What makes a photograph memorable? IEEE Transactions on Pattern Analysis and Machine Intel- ligence, 36(7):1469–1482, 2014. 1
work page 2014
-
[17]
Population re- sponse magnitude variation in inferotemporal cortex predicts image memorability
Andrew Jaegle, Vahid Mehrpour, Yalda Mohsenzadeh, Travis Meyer, Aude Oliva, and Nicole Rust. Population re- sponse magnitude variation in inferotemporal cortex predicts image memorability. eLife, 8:e47596, 2019. 1
work page 2019
-
[18]
Raju, Antonio Torralba, and Aude Oliva
Aditya Khosla, Akhil S. Raju, Antonio Torralba, and Aude Oliva. Understanding and predicting image memorability at a large scale. In International Conference on Computer Vi- sion (ICCV), 2015. 1, 2, 3
work page 2015
-
[19]
Im- ages with harder-to-reconstruct visual representations leave stronger memory traces
Qi Lin, Zifan Li, John Lafferty, and Ilker Yildirim. Im- ages with harder-to-reconstruct visual representations leave stronger memory traces. Nature Human Behaviour, 8:1–12,
-
[20]
Memorability of natural scenes: The role of attention
Matei Mancas and Olivier Le Meur. Memorability of natural scenes: The role of attention. In 2013 IEEE International Conference on Image Processing, pages 196–200, 2013. 1, 2
work page 2013
-
[21]
Embracing new tech- niques in deep learning for estimating image memorability
Coen Needell and Wilma Bainbridge. Embracing new tech- niques in deep learning for estimating image memorability. Computational Brain & Behavior, 5, 2022. 1
work page 2022
-
[22]
Byung-Doh Oh and William Schuler. Why does surprisal from larger transformer-based language models provide a poorer fit to human reading times? Transactions of the As- sociation for Computational Linguistics, 11:336–350, 2023. 4
work page 2023
-
[23]
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Je- gou, Julien Mairal, Patr...
work page 2024
-
[24]
Shay Perera, Ayellet Tal, and Lihi Zelnik-Manor. Is im- age memorability prediction solved? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2019. 1
work page 2019
-
[25]
Resmem-net: memory based deep cnn for image memorability estimation
Arockia Praveen, Abdulfattah Noorwali, Duraimurugan Samiayya, Mohammad Khan, Durai Vincent, Ali Bashir, and Vinoth Alagupandi. Resmem-net: memory based deep cnn for image memorability estimation. PeerJ Computer Sci- ence, 2021. 1
work page 2021
-
[26]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning , pages 8748–8763. PMLR, 2021. 2
work page 2021
-
[27]
Nicole C. Rust and Vahid Mehrpour. Understanding image memorability. Trends in Cognitive Sciences, 24(7):557–568,
-
[28]
Ananya Sadana, Nikita Thakur, Nikita Poria, Astika Anand, and K. R. Seeja. Comprehensive literature survey on deep learning used in image memorability prediction and modifi- cation. In International Conference on Innovative Comput- ing and Communications, pages 113–123, Singapore, 2024. Springer Nature Singapore. 1
work page 2024
-
[29]
Hammad Squalli-Houssaini, Ngoc Q. K. Duong, Marquant Gwenaelle, and Claire-Helene Demarty. Deep learning for predicting image memorability. In 2018 IEEE Interna- tional Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 2371–2375, 2018. 1
work page 2018
-
[30]
Lionel Standing. Learning 10000 pictures. Quarterly Jour- nal of Experimental Psychology, 25(2):207–222, 1973. 1
work page 1973
-
[31]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier H ´enaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. Siglip 2: Multilingual vision- language encoders with improved semantic understanding, localization, and dense feature...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.