Improving Generative Methods for Causal Evaluation via Simulation-Based Inference
Pith reviewed 2026-05-18 18:56 UTC · model grok-4.3
The pith
SBICE uses simulation-based inference to infer distributions over generative methods and parameters from source data, creating synthetic datasets whose causal estimates align with the original.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SBICE is a framework that treats the choice of generative method and its parameters as uncertain quantities. It applies simulation-based inference techniques to infer the posterior distribution of these quantities given a source dataset. The resulting posterior enables generation of synthetic datasets whose causal estimates closely match those obtained from the source data, supporting more reliable comparisons among causal estimators.
What carries the argument
Simulation-based inference for causal evaluation (SBICE), which infers posteriors over generative methods and parameters to generate synthetic data aligned with source causal estimates.
If this is right
- Users can express and propagate uncertainty over both generative methods and parameter values instead of using fixed point estimates.
- Synthetic datasets vary in aspects such as treatment effect and confounding bias while remaining anchored to the observed data distribution.
- Estimator evaluations gain reliability because the generated data produces causal estimates that align with those from the source.
- Posterior inference over suitable generative configurations becomes feasible, avoiding reliance on single deterministic choices.
Where Pith is reading between the lines
- The same posterior-inference approach to generative selection could apply to simulation-based evaluation in other machine learning tasks beyond causal estimation.
- SBICE suggests a path toward automated, data-driven calibration of simulation parameters in causal studies where manual tuning is common.
- Extending the framework to sequential or multi-source observational data might allow more flexible matching across different real-world settings.
Load-bearing premise
That simulation-based inference applied to the source dataset can reliably identify generative methods and parameter distributions whose produced synthetic data match the source in causal structure and statistical properties.
What would settle it
An experiment in which causal estimates computed on SBICE-generated synthetic datasets systematically differ from those on the source dataset would falsify the alignment claim.
Figures
















































read the original abstract
Generating synthetic datasets that accurately reflect real-world observational data is critical for evaluating causal estimators, but it remains a challenging task. Existing generative methods offer a solution by producing synthetic datasets anchored in the observed data (source data) while allowing variation in key parameters such as the treatment effect and amount of confounding bias. However, it is often unclear which generative methods to use and which values of parameters to choose when generating synthetic datasets. Moreover, existing methods typically require users to provide fixed point estimates of such parameters. This denies users the ability to express uncertainty over both generative methods and parameter values and removes the potential for posterior inference, potentially leading to unreliable estimator comparisons. We introduce simulation-based inference for causal evaluation (SBICE), a framework that treats the generative method and its corresponding generative parameters as uncertain and infers their posterior distribution given a source dataset. Leveraging techniques in simulation-based inference, SBICE identifies suitable generative methods and infers distributions over its parameter configurations to produce synthetic datasets closely aligned with the source data distribution. Empirical results demonstrate that SBICE improves the reliability of estimator evaluations by generating realistic datasets whose causal estimates closely match the estimates of the source data, making it a robust and uncertainty-aware approach to selecting causal estimators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SBICE, a framework that applies simulation-based inference to infer posterior distributions over generative methods and their parameters (such as treatment effect and confounding bias) conditioned on a source observational dataset. This enables generation of synthetic datasets for causal estimator evaluation that incorporate uncertainty rather than relying on fixed point estimates, with the central empirical claim being that the resulting datasets produce causal estimates closely matching those from the source data.
Significance. If the empirical validation holds, SBICE offers a practical advance for benchmarking causal methods by making synthetic data generation uncertainty-aware and better aligned with real data distributions. It usefully extends established SBI techniques to the causal evaluation setting and provides a reproducible path for posterior inference over generative choices, which is a clear strength relative to prior fixed-parameter approaches.
major comments (2)
- [Experiments] Experimental evaluation: the claim that SBICE generates datasets 'whose causal estimates closely match the estimates of the source data' is central but requires explicit quantitative support (e.g., reported differences in ATE or CATE estimates, overlap metrics, or statistical tests between source and synthetic distributions). Without these numbers and ablations on the SBI components, the improvement in reliability cannot be fully assessed.
- [Method] Method section: the procedure for selecting summary statistics in the SBI step is load-bearing for the posterior inference to recover causal structure; the manuscript should specify and justify the chosen statistics (or demonstrate robustness) because poor choice could prevent the generated data from matching the source causal properties.
minor comments (2)
- [Introduction] Notation for the generative parameters (treatment effect, confounding bias) should be introduced with explicit symbols early in the methods to avoid ambiguity when describing the posterior.
- Figures comparing causal estimates should include error bars or credible intervals to visually support the matching claim.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and recommendation of minor revision. We address each major comment below, providing additional quantitative support and methodological clarifications where appropriate.
read point-by-point responses
-
Referee: [Experiments] Experimental evaluation: the claim that SBICE generates datasets 'whose causal estimates closely match the estimates of the source data' is central but requires explicit quantitative support (e.g., reported differences in ATE or CATE estimates, overlap metrics, or statistical tests between source and synthetic distributions). Without these numbers and ablations on the SBI components, the improvement in reliability cannot be fully assessed.
Authors: We agree that explicit quantitative metrics are needed to fully support the central empirical claim. In the revised manuscript we have added a dedicated experimental subsection containing a table that reports mean absolute differences in ATE and CATE estimates between the source data and SBICE-generated synthetic datasets, together with Wasserstein distances and two-sample Kolmogorov-Smirnov p-values assessing distributional overlap. We have also included ablations that isolate the contribution of the SBI posterior inference step versus simpler point-estimate baselines. revision: yes
-
Referee: [Method] Method section: the procedure for selecting summary statistics in the SBI step is load-bearing for the posterior inference to recover causal structure; the manuscript should specify and justify the chosen statistics (or demonstrate robustness) because poor choice could prevent the generated data from matching the source causal properties.
Authors: We have expanded the method section to explicitly enumerate the summary statistics used (first and second moments of the joint distribution of covariates, treatment, and outcome, plus the treatment-outcome correlation and selected conditional moments). Their selection is justified by their ability to capture both marginal and dependence structure relevant to causal identification. We further added a robustness subsection that perturbs the statistic set and shows that the recovered posteriors and downstream causal estimates remain stable. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper proposes SBICE by applying established simulation-based inference methods to an external source dataset in order to infer posteriors over generative models and parameters. The central empirical claim is that the resulting synthetic datasets produce causal estimates close to those of the source data. This validation step is independent of the fitting process itself and does not reduce any claimed prediction or result to a quantity defined by the fitted parameters or by self-referential construction. No load-bearing step in the derivation chain is shown to be equivalent to its inputs by the paper's own equations or citations.
Axiom & Free-Parameter Ledger
free parameters (1)
- generative parameters (treatment effect, confounding bias)
axioms (1)
- domain assumption Simulation-based inference can approximate the posterior over both discrete generative method choices and continuous parameters given only the source observational dataset.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce simulation-based inference for causal evaluation (SBICE), a framework that models generative parameters as uncertain and infers their posterior distribution given a source dataset. Leveraging techniques in simulation-based inference, SBICE identifies parameter configurations that produce synthetic datasets closely aligned with the source data distribution.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use four different generative methods: (1) Credence; (2) a modified version of Credence ... (3) Realcause; and (4) FrugalFlows.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define the mean BSE for the posterior-source datasets ... Mean BSEM;post = 1/N Σ [ (τ(i)M;post − τ∗(i)post) − (τM;source − τ∗) ]²
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
doi: 10.21105/joss.04304. URL https://doi.org/10.21105/joss.04304. Keith Battocchi, Eleanor Dillon, Maggie Hei, Greg Lewis, Paul Oka, Miruna Oprescu, and Vasilis Syrgkanis. EconML: A Python Package for ML-Based Heterogeneous Treatment Effects Estima- tion. https://github.com/py-why/EconML, 2019. Version 0.x. Vincent Dorie, Hugh Chipman, and Robert McCullo...
-
[2]
We used the implementation in the EconML [Battocchi et al., 2019] package
X-Learner [Künzel et al., 2019]: A meta-learner algorithm to estimate the average treatment effect using two different underlying function: Linear regression (referred to as X (Lin)) and Gradient Boosted Trees (referred to as X (GBT)). We used the implementation in the EconML [Battocchi et al., 2019] package
work page 2019
-
[3]
Double machine learning (DML) [Chernozhukov et al., 2019]: An algorithm that constructs a de-biased estimator of the causal parameter by using two models to estimate the residual errors. We used the implementation in the EconML python package, and used two learners: Linear regression (DML (Lin)) and Gradient Boosted Trees (DML (GBT))
work page 2019
-
[4]
Doubly robust (DR) [Dudík et al., 2014]: This estimator combines two models: one for outcome regression and another for the treatment (propensity score) to estimate the causal effect. The advantage of using this estimator is that the effect is unbiased if either model is correctly specified. We use the implementation in the EconML package and use a linear...
work page 2014
-
[5]
We use its R implementation [Dorie et al., 2025] in our experiments
Causal BART [Hill, 2011]: This estimator leverages Bayesian Additive Regression Trees (BART) to estimate the causal effect. We use its R implementation [Dorie et al., 2025] in our experiments
work page 2011
-
[6]
Targeted Maximum Likelihood Estimator (TMLE) [Van Der Laan and Rubin, 2006]: We use the implementation of TMLE as described in the package zEpid Zivich et al. [2022]. 16 Algorithm 1: SBICE: Simulation-based inference for causal evaluation Input: Source dataset D = {X, T, Y }; Prior over knobs p(θ); Causal estimators M Output: Posterior datasets D; Causal ...
work page 2006
-
[7]
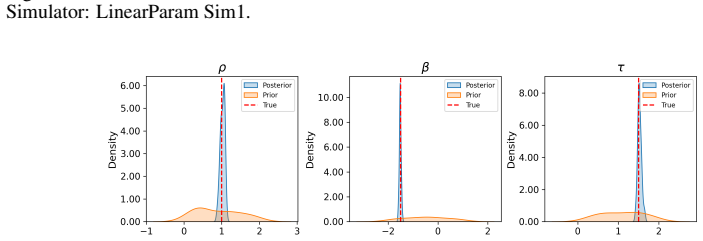
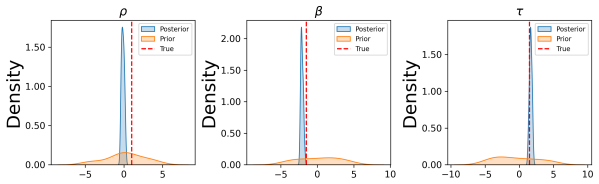
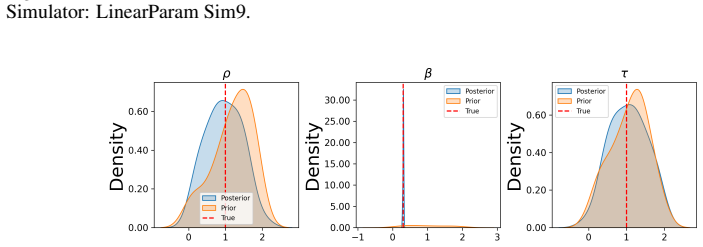
Source datasets from the true DGP: LinearParam DGP1,
-
[8]
Posterior datasets using parameter samples from the posterior distribution, and
-
[9]
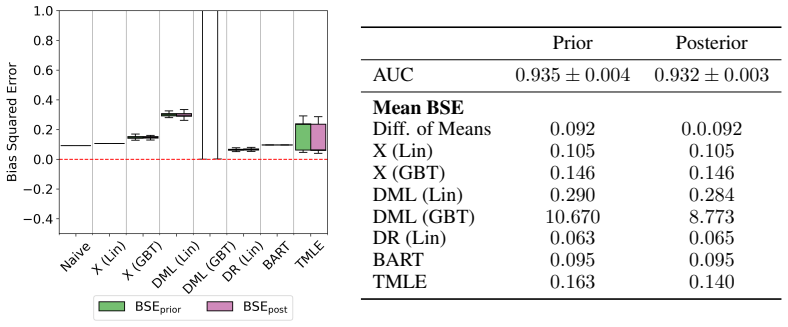
Evaluation We report the mean classifier AUCs for the posterior and prior datasets in Table 5
Prior datasets using parameter samples from the prior. Evaluation We report the mean classifier AUCs for the posterior and prior datasets in Table 5. We plot the bias of the causal estimators for the posterior, prior and source datasets in Figure 5. We also plot the posterior distribution for each of the DGP parameters in Figure 6. For this setting, we fi...
work page 2024
-
[10]
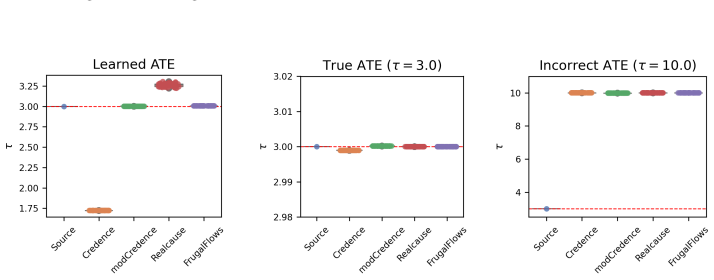
Learned ATE: We did not set any constraints to the generative method, and learned the distributions from the source data
-
[11]
True ATE: We set the constraint that the true ATEτ = 3.0 (obtained from the data generating process)
-
[12]
Incorrect ATE: We set the constraint that the ATEτ = 10.0 (a large, positive value compared to the ground-truth). To evaluate the differences across generative methods as well as the settings, we compared the generated datasets to the source dataset and computed the mean classifier AUC score across 50 generated datasets. The classifier AUC score for datas...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.