Stochastic versus Deterministic in Stochastic Gradient Descent
Pith reviewed 2026-05-18 20:10 UTC · model grok-4.3
The pith
Analyzing stochastic and deterministic gradient parts separately yields faster mini-batch SGD convergence and a smaller region radius.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
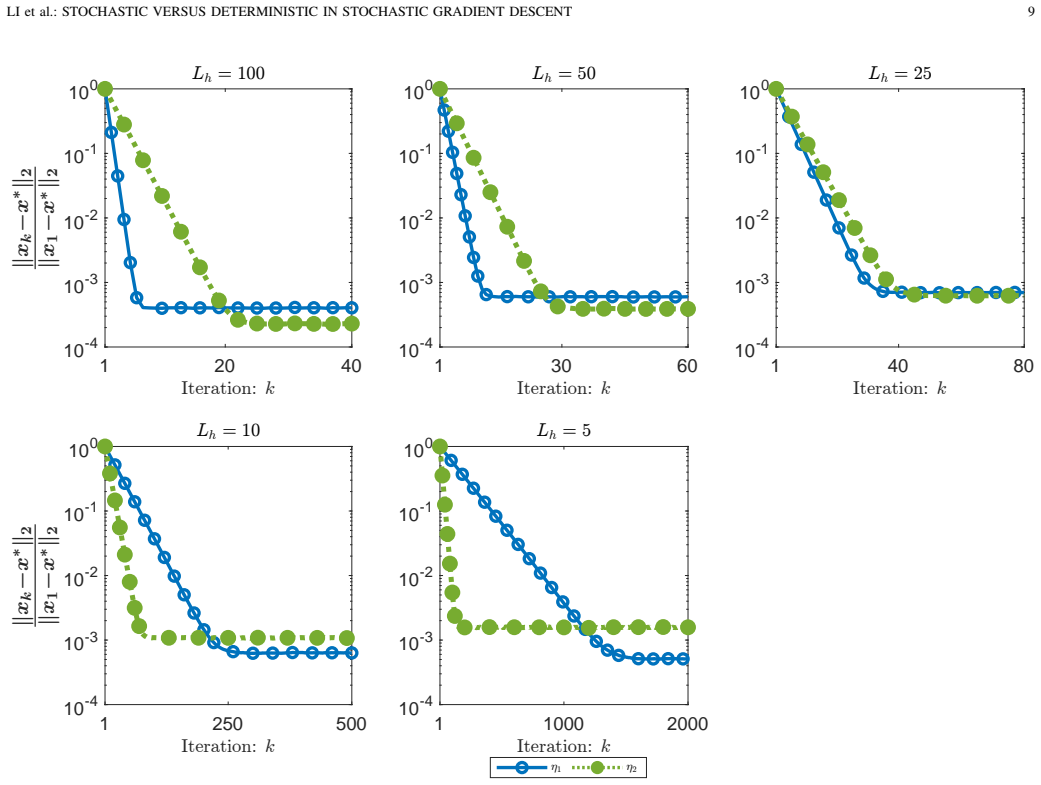
For an objective that consists of a finite-sum function with stochastically approximated gradient plus an independent term with deterministically computed gradient, the convergence parameters of mini-batch SGD depend asymmetrically on the stochastic and deterministic components. This separation produces a faster convergence rate and a smaller radius of the convergence region than are obtained by collapsing the problem into a standard finite-sum formulation. An even faster rate holds when the independent term endows the objective with sufficient strong convexity, and the expected convergence rate approaches that of classic gradient descent as the batch size increases.
What carries the argument
The maintained separation between the stochastically approximated finite-sum gradient and the deterministically computed independent-term gradient, which creates asymmetric dependence of step size, rate, and region radius on each component.
If this is right
- Step size can be selected using properties of the stochastic component and deterministic component independently rather than a single combined bound.
- The convergence rate improves because the deterministic computation is not penalized by stochastic variance.
- The radius of the region to which iterates converge shrinks relative to uniform analyses.
- When the independent term adds strong convexity the rate improves beyond the baseline separated bound.
- As mini-batch size grows the expected convergence rate approaches the classic gradient-descent rate.
Where Pith is reading between the lines
- The same separation could be applied to variance-reduced methods that already mix stochastic and deterministic computations.
- In practice, regularizers or other deterministic terms could be computed exactly at every step instead of inside the stochastic batch.
- The analysis suggests that identifying deterministic substructures in large-scale problems may improve SGD performance without changing the algorithm itself.
Load-bearing premise
The objective must preserve a fixed structural split between a stochastically approximated finite-sum part and a deterministically computed independent term so that the two gradient computations never collapse into a single uniform treatment.
What would settle it
Apply both the separated analysis and a standard uniform finite-sum analysis to the same structured problem, run mini-batch SGD, and measure the observed convergence rate and radius; if the measured quantities match the uniform analysis rather than the improved separated predictions, the claim is falsified.
Figures

read the original abstract
This paper theoretically reanalyzes the convergence of the mini-batch stochastic gradient descent (SGD) for a structured minimization problem involving a finite-sum function with its gradient being stochastically approximated, and an independent term with its gradient being deterministically computed. Rather than collapsing this problem into a standard finite-sum formulation and treating all components uniformly, we study it from a stochastic versus deterministic viewpoint and focus on how these two gradient computations affect mini-batch SGD differently. The step size, the convergence rate, and the radius of the convergence region depend asymmetrically on the characteristics of the two components, which shows the distinct impacts of stochastic approximation versus deterministic computation in the mini-batch SGD. Based on this, we show that our analysis yields a faster convergence rate and a smaller radius of the convergence region. Moreover, an even better convergence rate can be obtained when the independent term endows the objective function with sufficient strong convexity. Also, the convergence rate of our algorithm in expectation approaches that of the classic gradient descent when the batch size increases. Numerical experiments are conducted to support the theoretical analysis as well.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reanalyzes mini-batch SGD convergence for a structured objective consisting of a finite-sum term (with stochastic gradient) plus an independent term (with deterministic gradient). Rather than collapsing the problem into a uniform finite-sum formulation, the authors maintain the stochastic-versus-deterministic distinction and derive step-size, rate, and radius expressions that depend asymmetrically on the two components. They claim this yields a faster rate and smaller convergence radius than standard analysis, with further improvement when the independent term supplies strong convexity, and with the expected rate approaching deterministic gradient descent as batch size grows. Numerical experiments are presented in support.
Significance. If the derived bounds are strictly tighter than those from conventional mini-batch SGD analysis with zero variance assigned to the deterministic component, the work could supply more precise guarantees for hybrid stochastic-deterministic problems. The explicit batch-size scaling and the strong-convexity extension are potentially useful. The manuscript combines theory with experiments, which strengthens the contribution.
major comments (2)
- [Section 3] Main convergence theorem (Section 3): the claimed faster rate and smaller radius follow from bounding variance only on the stochastic finite-sum component while treating the independent term exactly. This construction is mathematically equivalent to a standard mini-batch SGD analysis in which the variance bound for the independent term is set to zero. A direct side-by-side comparison of the new rate/radius expressions against the adjusted standard bound (under identical smoothness, convexity, and batch-size parameters) is required to establish that the improvement is a genuine consequence of the asymmetric viewpoint rather than a reparameterization already available in the literature.
- [Section 4] Strong-convexity extension (Section 4): the further-improved rate when the independent term supplies strong convexity is presented as a benefit of the stochastic-deterministic separation. It is unclear whether this rate differs from the standard strong-convexity bound applied selectively to the deterministic component. Explicit comparison to the conventional analysis under the same strong-convexity parameter is needed to substantiate the claim.
minor comments (2)
- Notation for the independent term and its gradient should be introduced with a clear distinction from the finite-sum components to prevent readers from conflating the two.
- [Numerical experiments] Numerical experiments section: full dataset descriptions, exact hyper-parameter values, and code or pseudocode for the compared methods would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We agree that explicit side-by-side comparisons with standard analyses will strengthen the presentation and clarify the contribution of the asymmetric viewpoint. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Section 3] Main convergence theorem (Section 3): the claimed faster rate and smaller radius follow from bounding variance only on the stochastic finite-sum component while treating the independent term exactly. This construction is mathematically equivalent to a standard mini-batch SGD analysis in which the variance bound for the independent term is set to zero. A direct side-by-side comparison of the new rate/radius expressions against the adjusted standard bound (under identical smoothness, convexity, and batch-size parameters) is required to establish that the improvement is a genuine consequence of the asymmetric viewpoint rather than a reparameterization already available in the literature.
Authors: We acknowledge that setting the variance bound of the deterministic component to zero recovers similar algebraic forms. However, the asymmetric treatment in our analysis produces step-size rules, convergence rates, and radii that depend separately on the stochastic variance and the deterministic smoothness/convexity parameters. This separation is not merely notational; it permits component-specific tuning (e.g., larger steps when the deterministic term dominates) that is not directly suggested by a uniform finite-sum formulation. To substantiate the distinction, we will insert a new subsection in the revised manuscript that presents the standard bound (with zero variance on the deterministic term) alongside our expressions under identical assumptions on smoothness, strong convexity, and batch size, highlighting where the asymmetric rates and radii differ. revision: yes
-
Referee: [Section 4] Strong-convexity extension (Section 4): the further-improved rate when the independent term supplies strong convexity is presented as a benefit of the stochastic-deterministic separation. It is unclear whether this rate differs from the standard strong-convexity bound applied selectively to the deterministic component. Explicit comparison to the conventional analysis under the same strong-convexity parameter is needed to substantiate the claim.
Authors: We agree that an explicit comparison is necessary. In the revised manuscript we will add a direct juxtaposition of our strong-convexity rate (which applies the strong-convexity parameter only to the deterministic term while retaining the stochastic variance bound on the finite-sum term) against the conventional strong-convexity bound applied to the same deterministic component. The comparison will use identical parameter values and will show that the asymmetric formulation yields a strictly faster rate when the deterministic term is strongly convex, because the stochastic variance does not pollute the strong-convexity contraction term. revision: yes
Circularity Check
No significant circularity; derivation starts from standard assumptions
full rationale
The paper separates the finite-sum stochastic component from the independent deterministic term and derives convergence bounds under conventional smoothness, bounded variance on the stochastic gradients, and strong-convexity assumptions. The claimed faster rate and smaller radius follow directly from applying the standard SGD analysis only to the stochastic part while treating the deterministic gradient as exact; this separation is an input modeling choice rather than a self-referential definition or fitted parameter. No equations reduce to prior results by construction, no load-bearing self-citations close the argument, and the limit as batch size grows recovers the classic deterministic gradient descent rate, which is an independent consistency check rather than circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The objective is a sum of a finite-sum stochastic term and an independent deterministic term whose gradients can be computed separately.
- standard math Standard smoothness and bounded variance assumptions hold for the stochastic component.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 establishes linear convergence E[||x_{K+1}-x^*||^2] ≤ (1-q)^K ||x_1-x^*||^2 + R with q and R depending on s_F, σ_F, λ, and the averaged Lipschitz constants of the f_i and h.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
S. Shalev-Shwartz and S. Ben-David, Understanding machine learning: From theory to algorithms. Cambridge,UK: Cambridge university press, 2014
work page 2014
-
[2]
Nesterov, Lectures on convex optimization
Y . Nesterov, Lectures on convex optimization. Berlin,Germany: Springer, 2018
work page 2018
-
[3]
X. Fan, B. Jiang, and Y .-F. Liu, “An adaptive proximal inexact gradient framework and its application to per-antenna constrained joint beam- forming and compression design,” 2025, arXiv:2504.01721
-
[4]
A stochastic approximation method,
H. Robbins and S. Monro, “A stochastic approximation method,” Ann. Math. Stat., pp. 400–407, Sep. 1951
work page 1951
-
[5]
A proximal stochastic gradient method with progressive variance reduction,
L. Xiao and T. Zhang, “A proximal stochastic gradient method with progressive variance reduction,” SIAM J. Optim. , vol. 24, no. 4, pp. 2057–2075, Dec. 2014
work page 2057
-
[6]
R. Xin, S. Das, U. A. Khan, and S. Kar, “A stochastic proximal gradient framework for decentralized non-convex composite optimiza- tion: Topology-independent sample complexity and communication ef- ficiency,” 2021, arXiv:2110.01594
-
[7]
S. Ghadimi and G. Lan, “Optimal stochastic approximation algorithms for strongly convex stochastic composite optimization I: A generic algorithmic framework,” SIAM J. Optim., vol. 22, no. 4, pp. 1469–1492, Nov. 2012
work page 2012
-
[8]
P. Richt ´arik and M. Tak ´aˇc, “Iteration complexity of randomized block- coordinate descent methods for minimizing a composite function,”Math. Program., vol. 144, no. 1, pp. 1–38, Dec. 2014
work page 2014
-
[9]
Stochastic dual coordinate ascent methods for regularized loss,
S. Shalev-Shwartz and T. Zhang, “Stochastic dual coordinate ascent methods for regularized loss,” J. Mach. Learn. Res. , vol. 14, no. 1, pp. 567–599, Feb. 2013
work page 2013
-
[10]
Stochastic primal-dual coordinate method for regularized empirical risk minimization,
Y . Zhang and L. Xiao, “Stochastic primal-dual coordinate method for regularized empirical risk minimization,” J. Mach. Learn. Res. , vol. 18, no. 84, pp. 1–42, Jun. 2017
work page 2017
-
[11]
N. Loizou and P. Richt ´arik, “Momentum and stochastic momentum for stochastic gradient, Newton, proximal point and subspace descent methods,” Comput. Optim. Appl., vol. 77, no. 3, pp. 653–710, Sep. 2020
work page 2020
-
[12]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” 2014, arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [13]
-
[14]
Stochastic approximation vis- `a-vis online learning for big data analytics,
K. Slavakis, S.-J. Kim, G. Mateos, and G. B. Giannakis, “Stochastic approximation vis- `a-vis online learning for big data analytics,” IEEE Signal Process Mag. , vol. 31, no. 6, pp. 124–129, Oct. 2014
work page 2014
-
[15]
RMSProp converges with proper hyper-parameter,
N. Shi, D. Li, M. Hong, and R. Sun, “RMSProp converges with proper hyper-parameter,” in Proc. Int. Conf. Learn. Represent. , 2021
work page 2021
-
[16]
Q. Zhang, Y . Zhou, and S. Zou, “Convergence guarantees for RMSProp and Adam in generalized-smooth non-convex optimization with affine noise variance,” 2024, arXiv:2404.01436
-
[17]
Tensorflow: a system for Large-Scale machine learn- ing,
M. Abadi et al., “Tensorflow: a system for Large-Scale machine learn- ing,” in Proc. USENIX Symp. Operating Syst. Design Implement. , 2016, pp. 265–283
work page 2016
-
[18]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A. Paszke, “Pytorch: An imperative style, high-performance deep learn- ing library,” 2019, arXiv:1912.01703
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[19]
Federated Learning: Strategies for Improving Communication Efficiency
J. Kone ˇcn`y, H. B. McMahan, F. X. Yu, P. Richt ´arik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communication efficiency,” 2016, arXiv:1610.05492
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Joint optimization of com- munications and federated learning over the air,
X. Fan, Y . Wang, Y . Huo, and Z. Tian, “Joint optimization of com- munications and federated learning over the air,” IEEE Trans. Wireless Commun., vol. 21, no. 6, pp. 4434–4449, Dec. 2021
work page 2021
-
[21]
Federated variance- reduced stochastic gradient descent with robustness to Byzantine at- tacks,
Z. Wu, Q. Ling, T. Chen, and G. B. Giannakis, “Federated variance- reduced stochastic gradient descent with robustness to Byzantine at- tacks,” IEEE Trans. Signal Process., vol. 68, pp. 4583–4596, Jul. 2020
work page 2020
-
[22]
Minimizing finite sums with the stochastic average gradient,
M. Schmidt, N. Le Roux, and F. Bach, “Minimizing finite sums with the stochastic average gradient,” Math. Program., vol. 162, pp. 83–112, Jun. 2016
work page 2016
-
[23]
SGD and Hogwild! convergence without the bounded gradients assumption,
L. Nguyen, P. H. Nguyen, M. Dijk, P. Richt ´arik, K. Scheinberg, and M. Tak ´ac, “SGD and Hogwild! convergence without the bounded gradients assumption,” inProc. Int. Conf. Mach. Learn., 2018, pp. 3750– 3758
work page 2018
-
[24]
Making Gradient Descent Optimal for Strongly Convex Stochastic Optimization
A. Rakhlin, O. Shamir, and K. Sridharan, “Making gradient de- scent optimal for strongly convex stochastic optimization,” 2011, arXiv:1109.5647
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[25]
Robust stochastic approximation approach to stochastic programming,
A. Nemirovski, A. Juditsky, G. Lan, and A. Shapiro, “Robust stochastic approximation approach to stochastic programming,” SIAM J. Optim. , vol. 19, no. 4, pp. 1574–1609, Jan. 2009
work page 2009
-
[26]
Lan, First-order and stochastic optimization methods for machine learning
G. Lan, First-order and stochastic optimization methods for machine learning. Berlin, Germany: Springer, 2020
work page 2020
-
[27]
Optimization methods for large- scale machine learning,
L. Bottou, F. E. Curtis, and J. Nocedal, “Optimization methods for large- scale machine learning,” SIAM Rev., vol. 60, no. 2, pp. 223–311, May 2018
work page 2018
-
[28]
Non- asymptotic analysis of biased stochastic approximation scheme,
B. Karimi, B. Miasojedow, E. Moulines, and H.-T. Wai, “Non- asymptotic analysis of biased stochastic approximation scheme,” inProc. Conf. on Learn. Theory , 2019, pp. 1944–1974
work page 2019
-
[29]
A. Khaled and P. Richt ´arik, “Better theory for SGD in the nonconvex world,” 2020, arXiv:2002.03329
-
[30]
Stochastic compositional gradient descent under compositional constraints,
S. T. Thomdapu, H. Vardhan, and K. Rajawat, “Stochastic compositional gradient descent under compositional constraints,” IEEE Trans. Signal Process., vol. 71, pp. 1115–1127, 2023
work page 2023
-
[31]
Solving large scale linear prediction problems using stochas- tic gradient descent algorithms,
T. Zhang, “Solving large scale linear prediction problems using stochas- tic gradient descent algorithms,” in Proc. Int. Conf. Mach. Learn., 2004, pp. 116–123
work page 2004
-
[32]
Pegasos: Primal estimated sub-gradient solver for SVM,
S. Shalev-Shwartz, Y . Singer, N. Srebro, and A. Cotter, “Pegasos: Primal estimated sub-gradient solver for SVM,”Math. Program., vol. 127, no. 1, pp. 3–30, Oct. 2011
work page 2011
-
[33]
Fast Convergence of Stochastic Gradient Descent under a Strong Growth Condition
M. Schmidt and N. L. Roux, “Fast convergence of stochastic gradient descent under a strong growth condition,” 2013, arXiv:1308.6370
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[34]
Non-asymptotic analysis of stochastic ap- proximation algorithms for machine learning,
F. Bach and E. Moulines, “Non-asymptotic analysis of stochastic ap- proximation algorithms for machine learning,” in Proc. Conf. Neural Inf. Process. Syst. , 2011, pp. 451–459
work page 2011
-
[35]
SGD: General analysis and improved rates,
R. M. Gower, N. Loizou, X. Qian, A. Sailanbayev, E. Shulgin, and P. Richt´arik, “SGD: General analysis and improved rates,” in Proc. Int. Conf. Mach. Learn. , 2019, pp. 5200–5209
work page 2019
-
[36]
G. Garrigos and R. M. Gower, “Handbook of convergence theorems for (stochastic) gradient methods,” 2023, arXiv:2301.11235
-
[37]
B. Sch ¨olkopf and A. J. Smola, Learning with kernels: Support vector machines, regularization, optimization, and beyond , Cambridge, MA, USA, 2002
work page 2002
-
[38]
Automatic robust adaptive beamforming via ridge regression,
Y . Sel ´en, R. Abrahamsson, and P. Stoica, “Automatic robust adaptive beamforming via ridge regression,” Signal Process., vol. 88, no. 1, pp. 33–49, 2008
work page 2008
-
[39]
H. H. Kim and N. R. Swanson, “Forecasting financial and macroeco- nomic variables using data reduction methods: New empirical evidence,” J. Econom., vol. 178, pp. 352–367, 2014
work page 2014
-
[40]
E.W., Clinical prediction models: A practical approach to develop- ment, validation, and updating
S. E.W., Clinical prediction models: A practical approach to develop- ment, validation, and updating . Berlin, Germany: Springer, 2009
work page 2009
-
[41]
Ad click prediction: a view from the trenches,
H. B. McMahan et al., “Ad click prediction: a view from the trenches,” in Proc. ACM SIGKDD Int. Conf. Knowl. Discovery Data Min. , 2013, pp. 1222–1230
work page 2013
-
[42]
Support vector machines for spam categorization,
H. Drucker, D. Wu, and V . N. Vapnik, “Support vector machines for spam categorization,” IEEE Trans. Neural Networks , vol. 10, no. 5, pp. 1048–1054, Sep. 1999
work page 1999
-
[43]
Thumbs up? Sentiment Classification using Machine Learning Techniques
B. Pang, L. Lee, and S. Vaithyanathan, “Thumbs up? Sentiment classi- fication using machine learning techniques,” 2002, arXiv:cs/0205070
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[44]
Liblinear: A library for large linear classification,
R.-E. Fan, K.-W. Chang, C.-J. Hsieh, X.-R. Wang, and C.-J. Lin, “Liblinear: A library for large linear classification,” J. Mach. Learn. Res., vol. 9, pp. 1871–1874, Aug. 2008
work page 2008
- [45]
-
[46]
N. Jean, S. M. Xie, and S. Ermon, “Semi-supervised deep kernel learning: Regression with unlabeled data by minimizing predictive variance,” in Proc. Conf. Neural Inf. Process. Syst. , 2018, pp. 5322– 5333
work page 2018
-
[47]
Lecture 6.5 RMSProp: Divide the gradient by a running average of its recent magnitude,
T. Tieleman and G. Hinton, “Lecture 6.5 RMSProp: Divide the gradient by a running average of its recent magnitude,” COURSERA: Neural networks for machine learning , vol. 4, no. 2, pp. 26–31, 2012
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.