TeRA: Vector-based Random Tensor Network for High-Rank Adaptation of Large Language Models
Pith reviewed 2026-05-18 19:14 UTC · model grok-4.3
The pith
TeRA enables high-rank weight updates in LLMs while training only as many parameters as vector-based adapters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TeRA parametrizes the tensorized weight update matrix as a Tucker-like tensor network, whereby large randomly initialized factors are frozen and shared across layers, while only small layer-specific scaling vectors, corresponding to diagonal entries of factor matrices, are trained. This achieves high-rank weight updates while retaining the parameter efficiency of vector-based PEFT adapters, matching or even outperforming existing high-rank adapters.
What carries the argument
Tucker-like tensor network that decomposes the weight update, keeping large random factors frozen and shared while training only per-layer scaling vectors.
If this is right
- High-rank updates become feasible without increasing the trainable parameter budget beyond vector-based methods.
- Adapter performance equals or exceeds prior high-rank techniques on language-model fine-tuning benchmarks.
- The separation of shared random structure from per-layer scalings reduces redundancy across model layers.
- Theoretical guarantees and ablation results support that the random tensor factors encode sufficient high-rank directions.
Where Pith is reading between the lines
- The shared random factors may implicitly align adaptation directions across layers without explicit coordination.
- The same random-tensor pattern could be tested on other parameter-efficient methods such as prompt tuning.
- Scaling the approach to models with thousands of layers would test whether the fixed factors remain effective without retraining.
Load-bearing premise
Randomly initialized and frozen large factors in the tensor network, when paired with only layer-specific scaling vectors, suffice to capture the high-rank information required for effective adaptation.
What would settle it
An ablation or benchmark run in which replacing the frozen random factors with learned ones yields no gain, or where TeRA falls measurably behind a comparable high-rank adapter on a task known to need high-rank capacity.
Figures





read the original abstract
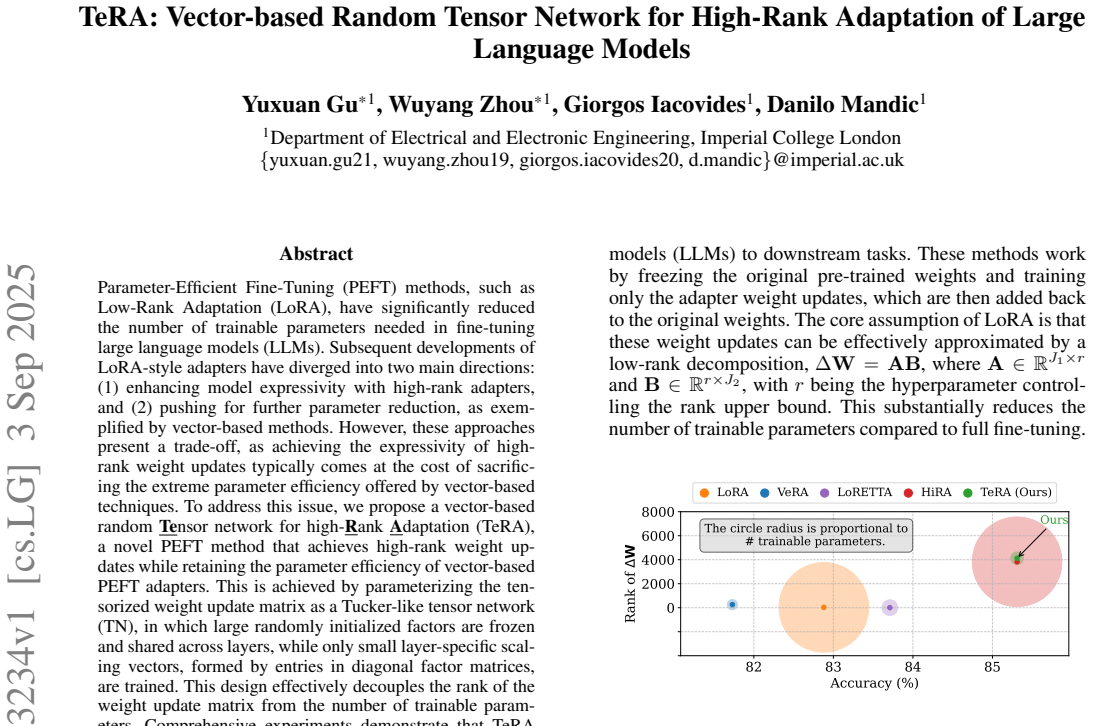
Parameter-Efficient Fine-Tuning (PEFT) methods, such as Low-Rank Adaptation (LoRA), have significantly reduced the number of trainable parameters needed in fine-tuning large language models (LLMs). The developments of LoRA-style adapters have considered two main directions: (1) enhancing model expressivity with high-rank adapters, and (2) aiming for further parameter reduction, as exemplified by vector-based methods. However, these approaches come with a trade-off, as achieving the expressivity of high-rank weight updates typically comes at the cost of sacrificing the extreme parameter efficiency offered by vector-based techniques. To address this issue, we propose a vector-based random Tensor network for high-Rank Adaptation (TeRA), a novel PEFT method that achieves high-rank weight updates while retaining the parameter efficiency of vector-based PEFT adapters. This is achieved by parametrizing the tensorized weight update matrix as a Tucker-like tensor network (TN), whereby large randomly initialized factors are frozen and shared across layers, while only small layer-specific scaling vectors, corresponding to diagonal entries of factor matrices, are trained. Comprehensive experiments demonstrate that TeRA matches or even outperforms existing high-rank adapters, while requiring as few trainable parameters as vector-based methods. Theoretical analysis and ablation studies validate the effectiveness of the proposed TeRA method. The code is available at https://github.com/guyuxuan9/TeRA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TeRA, a PEFT method for LLMs that parametrizes weight updates via a Tucker-like tensor network. Large randomly initialized factors are frozen and shared across layers, while only small per-layer scaling vectors (corresponding to diagonal entries) are trained. This is claimed to deliver high-rank adaptation updates at the parameter cost of vector-based methods. Comprehensive experiments, theoretical analysis, and ablations are reported to show that TeRA matches or outperforms existing high-rank adapters while using as few trainable parameters as vector-based PEFT.
Significance. If the central claims are substantiated, TeRA would usefully bridge the expressivity-efficiency trade-off in PEFT by showing that a shared random tensor basis plus per-layer scalings can suffice for effective high-rank updates. The availability of code and the inclusion of both theoretical analysis and ablations are positive features that aid reproducibility and verification.
major comments (2)
- [§3] §3 (Method), Tucker-like TN parametrization: The central claim that frozen, shared random factors plus per-layer scaling vectors produce effective high-rank updates rests on the untested assumption that a single random subspace already contains the principal adaptation directions across layers. If the random basis is misaligned with layer-wise gradient structure, scaling alone cannot recover the missing expressivity; the paper must demonstrate stability under different random seeds for the frozen factors.
- [§4.3] §4.3 (Ablations) and experimental tables: The reported performance gains over high-rank baselines are load-bearing for the claim, yet the manuscript provides insufficient detail on whether ablations include replacement of the shared random factors by an independent draw or by a learned basis; without such controls the results cannot rule out that success depends on a fortunate random initialization rather than the architecture itself.
minor comments (2)
- [§3] Notation for the scaling vectors and the precise definition of the Tucker contraction should be clarified with an explicit equation showing which modes are contracted and which remain diagonal.
- [§4] Figure captions and table headers should explicitly state the number of trainable parameters for each compared method to make the efficiency claim immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to address these points. We agree that additional empirical verification of stability and clearer ablation controls will strengthen the manuscript. We outline our responses below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [§3] §3 (Method), Tucker-like TN parametrization: The central claim that frozen, shared random factors plus per-layer scaling vectors produce effective high-rank updates rests on the untested assumption that a single random subspace already contains the principal adaptation directions across layers. If the random basis is misaligned with layer-wise gradient structure, scaling alone cannot recover the missing expressivity; the paper must demonstrate stability under different random seeds for the frozen factors.
Authors: We acknowledge that demonstrating robustness to the choice of random seed for the shared frozen factors is valuable for substantiating the central claim. Section 3.2 provides a theoretical argument that a random Tucker-like basis can span the necessary high-rank space with high probability, but we agree this should be complemented by empirical checks. In the revised version we will add a new table (or subsection in §4) reporting mean and standard deviation of performance across at least five independent random seeds for the frozen factors on the main benchmarks, thereby directly addressing the concern about potential misalignment. revision: yes
-
Referee: [§4.3] §4.3 (Ablations) and experimental tables: The reported performance gains over high-rank baselines are load-bearing for the claim, yet the manuscript provides insufficient detail on whether ablations include replacement of the shared random factors by an independent draw or by a learned basis; without such controls the results cannot rule out that success depends on a fortunate random initialization rather than the architecture itself.
Authors: We appreciate the referee highlighting the need for explicit controls that isolate the benefit of sharing a single random tensor basis. The existing ablations in §4.3 vary the scaling-vector dimension and core rank but do not yet include the requested variants. We will expand §4.3 with two new controls: (i) per-layer independent random draws of the factor matrices (instead of a shared draw), and (ii) a learned (non-frozen) basis version. These additions will be presented alongside the original results so readers can assess whether performance depends on a fortunate initialization or on the shared-random architecture itself. revision: yes
Circularity Check
Explicit architectural parametrization with no load-bearing self-definition or fitted-input prediction
full rationale
The paper defines TeRA directly as a Tucker-like tensor network in which large random factors are frozen and shared while only per-layer scaling vectors are trained. This is presented as an engineering choice that trades off expressivity and parameter count, not as a quantity derived from or equivalent to the fitted scaling vectors themselves. No equations reduce the claimed high-rank adaptation performance to the trainable parameters by construction, and no self-citation chain is invoked to justify uniqueness or to rename an existing result. The central claim therefore remains an independent architectural proposal whose validity is tested empirically rather than presupposed by the method's own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- layer-specific scaling vectors
axioms (1)
- domain assumption Randomly initialized frozen factors in the tensor network suffice to represent the necessary high-rank structure when scaled per layer.
invented entities (1)
-
TeRA tensor network parametrization
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
large randomly initialized factors are frozen and shared across layers, while only small layer-specific scaling vectors... are trained
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1... rank(ΔW[N;k]) ≤ min(∏_{i=1}^k Ri, ∏_{i=k+1}^N Ri)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F. L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. 2023. GPT-4 Technical Report . arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Banerjee, S.; and Lavie, A. 2005. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments . In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, 65--72
work page 2005
- [5]
-
[6]
Bisk, Y.; Zellers, R.; Gao, J.; Choi, Y.; et al. 2020. PIQA: Reasoning about Physical Commonsense in Natural Language . In Proceedings of the AAAI conference on artificial intelligence, volume 34, 7432--7439
work page 2020
-
[7]
D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al
Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J. D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877--1901
work page 2020
-
[8]
Cichocki, A.; Mandic, D.; De Lathauwer, L.; Zhou, G.; Zhao, Q.; Caiafa, C.; and PHAN, H. A. 2015. Tensor Decompositions for Signal Processing Applications: From two-way to multiway component analysis. IEEE Signal Processing Magazine, 32(2): 145--163
work page 2015
-
[9]
Clark, C.; Lee, K.; Chang, M.-W.; Kwiatkowski, T.; Collins, M.; and Toutanova, K. 2019. BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions . In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2924--2936
work page 2019
-
[10]
Clark, P.; Cowhey, I.; Etzioni, O.; Khot, T.; Sabharwal, A.; Schoenick, C.; and Tafjord, O. 2018. Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge . arXiv preprint arXiv:1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Cobbe, K.; Kosaraju, V.; Bavarian, M.; Chen, M.; Jun, H.; Kaiser, L.; Plappert, M.; Tworek, J.; Hilton, J.; Nakano, R.; et al. 2021. Training Verifiers to Solve Math Word Problems . arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
De Lathauwer, L.; De Moor, B.; and Vandewalle, J. 2000 a . A multilinear singular value decomposition. SIAM journal on Matrix Analysis and Applications, 21(4): 1253--1278
work page 2000
-
[13]
De Lathauwer, L.; De Moor, B.; and Vandewalle, J. 2000 b . On the best rank-1 and rank-(r1, r2,..., rn) approximation of higher-order tensors. SIAM journal on Matrix Analysis and Applications, 21(4): 1324--1342
work page 2000
-
[14]
Dinan, E.; Logacheva, V.; Malykh, V.; Miller, A.; Shuster, K.; Urbanek, J.; Kiela, D.; Szlam, A.; Serban, I.; Lowe, R.; et al. 2019. The Second Conversational Intelligence Challenge (ConvAI2) . In The NeurIPS'18 Competition: From Machine Learning to Intelligent Conversations, 187--208. Springer
work page 2019
-
[15]
Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. 2024. The Llama 3 Herd of Models . arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
-
[17]
J.; yelong shen; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; and Chen, W
Hu, E. J.; yelong shen; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; and Chen, W. 2022. Lo RA : Low-Rank Adaptation of Large Language Models. In International Conference on Learning Representations
work page 2022
-
[18]
Hu, Z.; Wang, L.; Lan, Y.; Xu, W.; Lim, E.-P.; Bing, L.; Xu, X.; Poria, S.; and Lee, R. 2023. LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 5254--5276
work page 2023
-
[19]
Huang, Q.; Ko, T.; Zhuang, Z.; Tang, L.; and Zhang, Y. 2025. Hi RA : Parameter-Efficient Hadamard High-Rank Adaptation for Large Language Models. In The Thirteenth International Conference on Learning Representations
work page 2025
- [20]
- [21]
- [22]
-
[23]
Koncel-Kedziorski, R.; Roy, S.; Amini, A.; Kushman, N.; and Hajishirzi, H. 2016. MAWPS : A Math Word Problem Repository. In Proceedings of the 2016 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies , 1152--1157. San Diego, California: Association for Computational Linguistics
work page 2016
-
[24]
J.; Blankevoort, T.; and Asano, Y
Kopiczko, D. J.; Blankevoort, T.; and Asano, Y. M. 2024. Ve RA : Vector-based Random Matrix Adaptation. In The Twelfth International Conference on Learning Representations
work page 2024
-
[25]
Lester, B.; Al-Rfou, R.; and Constant, N. 2021. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 3045--3059. Association for Computational Linguistics
work page 2021
-
[26]
Li, C.; Zeng, J.; Li, C.; Caiafa, C.; and Zhao, Q. 2023. Alternating local enumeration (TnALE): solving tensor network structure search with fewer evaluations . In Proceedings of the 40th International Conference on Machine Learning, ICML'23. JMLR.org
work page 2023
-
[27]
Lin, C.-Y. 2004. ROUGE : A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out, 74--81. Barcelona, Spain: Association for Computational Linguistics
work page 2004
-
[28]
Ling, W.; Yogatama, D.; Dyer, C.; and Blunsom, P. 2017. Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems . In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 158--167
work page 2017
-
[29]
Liu, X.; Ji, K.; Fu, Y.; Tam, W.; Du, Z.; Yang, Z.; and Tang, J. 2022. P -Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks. In Muresan, S.; Nakov, P.; and Villavicencio, A., eds., Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 61--68. Dublin, Ireland: Associat...
work page 2022
-
[30]
Loshchilov, I.; and Hutter, F. 2019. Decoupled Weight Decay Regularization . In International Conference on Learning Representations
work page 2019
-
[31]
Mihaylov, T.; Clark, P.; Khot, T.; and Sabharwal, A. 2018. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2381--2391
work page 2018
-
[32]
Oseledets, I. V. 2011. Tensor-train decomposition. SIAM Journal on Scientific Computing, 33(5): 2295--2317
work page 2011
-
[33]
Patel, A.; Bhattamishra, S.; and Goyal, N. 2021. Are NLP Models really able to Solve Simple Math Word Problems? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2080--2094. Association for Computational Linguistics
work page 2021
-
[34]
Sakaguchi, K.; Le Bras, R.; Bhagavatula, C.; and Choi, Y. 2020. WinoGrande: An adversarial winograd schema challenge at scale . In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, 8732--8740
work page 2020
-
[35]
Sap, M.; Rashkin, H.; Chen, D.; LeBras, R.; and Choi, Y. 2019. SocialIQA: Commonsense Reasoning about Social Interactions . In Conference on Empirical Methods in Natural Language Processing
work page 2019
-
[36]
Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [37]
-
[38]
Wang, M.; Duc, K. D.; Fischer, J.; and Song, Y. S. 2017. Operator norm inequalities between tensor unfoldings on the partition lattice. Linear algebra and its applications, 520: 44--66
work page 2017
-
[39]
Yang, Y.; Zhou, J.; Wong, N.; and Zhang, Z. 2024. LoRETTA: Low-Rank Economic Tensor-Train Adaptation for Ultra-Low-Parameter Fine-Tuning of Large Language Models . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 3161--3176
work page 2024
-
[40]
Zellers, R.; Holtzman, A.; Bisk, Y.; Farhadi, A.; and Choi, Y. 2019. HellaSwag: Can a Machine Really Finish Your Sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 4791--4800
work page 2019
-
[41]
Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K. Q.; and Artzi, Y. 2020. BERTScore: Evaluating Text Generation with BERT . In International Conference on Learning Representations
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.