DreamAudio: Customized Text-to-Audio Generation with Diffusion Models
Pith reviewed 2026-05-18 18:22 UTC · model grok-4.3
The pith
DreamAudio generates new audio clips that include specific events from a few user reference samples while following text prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
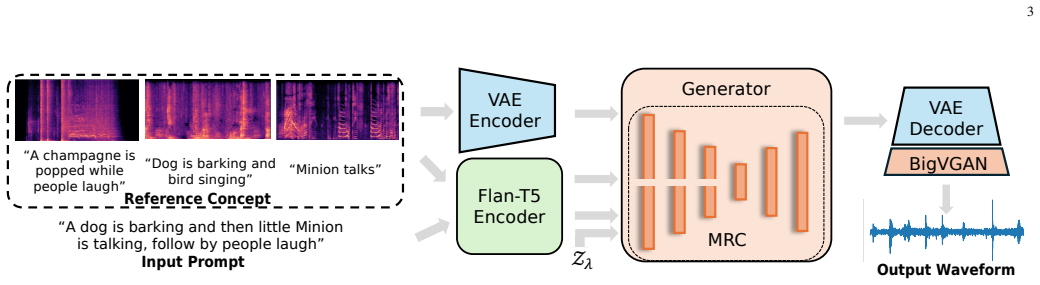
Given a few reference audio samples containing personalized audio events, the DreamAudio system can generate new audio samples that include these specific events and are aligned well with the input text prompts. The framework identifies auditory information from the references and recombines it during diffusion-based generation to produce customized results.
What carries the argument
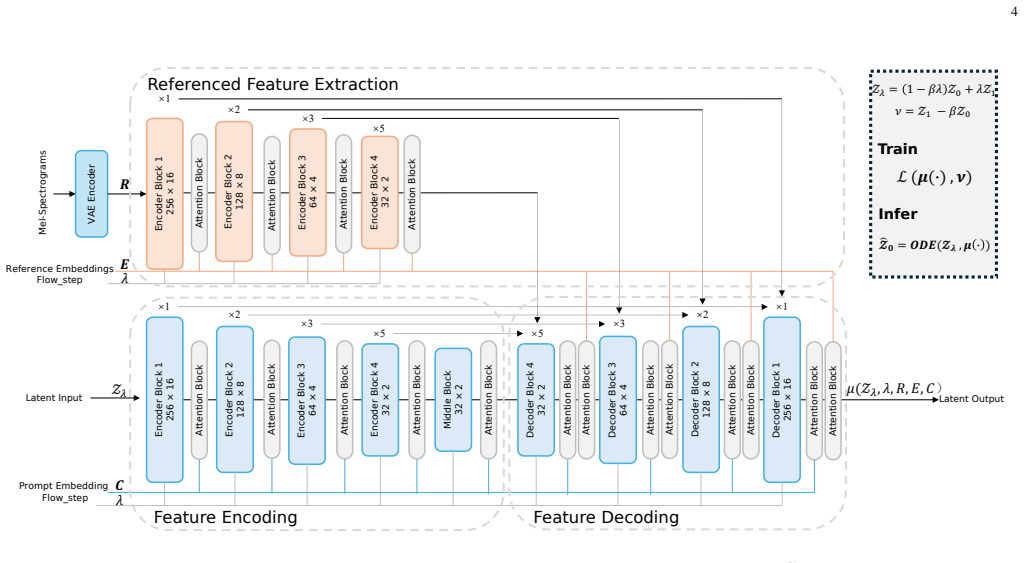
A framework that enables the diffusion model to identify and apply auditory information from user-provided reference audio concepts.
Load-bearing premise
Reference audio samples contain clean, identifiable, and transferable information about the personalized events that the model can extract and recombine without interference from noise or unrelated acoustic traits.
What would settle it
Generate outputs from held-out reference sets and test whether listeners can reliably detect the specific referenced acoustic events in the results at rates well above chance, or whether text-prompt alignment drops below that of standard diffusion text-to-audio models.
Figures



read the original abstract
With the development of large-scale diffusion-based and language-modeling-based generative models, impressive progress has been achieved in text-to-audio generation. Despite producing high-quality outputs, existing text-to-audio models mainly aim to generate semantically aligned sound and fall short of controlling fine-grained acoustic characteristics of specific sounds. As a result, users who need specific sound content may find it difficult to generate the desired audio clips. In this paper, we present DreamAudio for customized text-to-audio generation (CTTA). Specifically, we introduce a new framework that is designed to enable the model to identify auditory information from user-provided reference concepts for audio generation. Given a few reference audio samples containing personalized audio events, our system can generate new audio samples that include these specific events. In addition, two types of datasets are developed for training and testing the proposed systems. The experiments show that DreamAudio generates audio samples that are highly consistent with the customized audio features and aligned well with the input text prompts. Furthermore, DreamAudio offers comparable performance in general text-to-audio tasks. We also provide a human-involved dataset containing audio events from real-world CTTA cases as the benchmark for customized generation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents DreamAudio, a diffusion-based framework for customized text-to-audio generation (CTTA). Given a few reference audio samples containing personalized audio events, the system generates new samples that incorporate these specific events while remaining aligned with input text prompts. The authors introduce two new datasets for training and testing, report experimental results indicating high consistency with the customized features and good prompt alignment, show comparable performance to standard text-to-audio tasks, and release a human-involved benchmark dataset drawn from real-world CTTA scenarios.
Significance. If the experimental claims hold under detailed scrutiny, the work would represent a meaningful step toward fine-grained, reference-driven control in audio generation, addressing the limitation of existing text-to-audio models that primarily achieve semantic alignment rather than event-specific customization. The accompanying datasets and benchmark would also supply useful resources for future research on personalized audio synthesis.
major comments (3)
- [Methods] Methods / conditioning subsection: The reference encoder (typically CLAP or WavLM embeddings) is fed into standard cross-attention or FiLM layers without an explicit event-disentanglement stage. This leaves open the possibility that the UNet satisfies the training objective by copying global acoustic statistics (timbre, background, recording artifacts) rather than isolating the target auditory event, directly undermining the central claim that a few references supply cleanly transferable, event-specific features.
- [Experiments] Experiments / results section: The reported positive outcomes on consistency and alignment lack accompanying quantitative metrics, ablation tables (e.g., performance on noisy vs. clean references or single- vs. multi-source clips), and error analysis. Without these, it is impossible to verify robustness against the weakest assumption that reference clips contain clean, identifiable events.
- [Datasets] Dataset construction: The two new datasets are introduced for CTTA training and testing, yet the selection and annotation protocol for ensuring that reference clips isolate the intended personalized events (rather than composite or noisy scenes) is not specified. This detail is load-bearing for the benchmark's validity and for the claim of real-world applicability.
minor comments (2)
- [Abstract] Abstract: Adding one or two key quantitative scores (e.g., consistency or alignment metrics) would make the summary of experimental outcomes more informative.
- Notation and terminology: The phrases 'customized audio features' and 'personalized audio events' are used interchangeably; a single consistent term would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important aspects for improving the clarity and robustness of our work on DreamAudio. We address each major comment below and outline the revisions we will incorporate.
read point-by-point responses
-
Referee: [Methods] Methods / conditioning subsection: The reference encoder (typically CLAP or WavLM embeddings) is fed into standard cross-attention or FiLM layers without an explicit event-disentanglement stage. This leaves open the possibility that the UNet satisfies the training objective by copying global acoustic statistics (timbre, background, recording artifacts) rather than isolating the target auditory event, directly undermining the central claim that a few references supply cleanly transferable, event-specific features.
Authors: We acknowledge the validity of this concern: without an explicit disentanglement module, it is possible in principle for the model to rely on global acoustic properties. Our design instead uses the joint training objective (reference consistency plus text alignment) and the iterative nature of the diffusion process to encourage focus on the target event. The cross-attention layers allow the UNet to attend selectively to reference features that match the prompt semantics. To strengthen this argument, we will revise the methods section with additional discussion of the implicit disentanglement mechanism and include a new ablation comparing conditioning with and without text prompts. revision: yes
-
Referee: [Experiments] Experiments / results section: The reported positive outcomes on consistency and alignment lack accompanying quantitative metrics, ablation tables (e.g., performance on noisy vs. clean references or single- vs. multi-source clips), and error analysis. Without these, it is impossible to verify robustness against the weakest assumption that reference clips contain clean, identifiable events.
Authors: We agree that more granular quantitative support and ablations would strengthen the experimental claims. The current results include consistency and alignment scores, yet we did not provide the requested breakdowns or error analysis. In the revised manuscript we will add ablation tables for noisy versus clean references and single- versus multi-source clips, together with a quantitative error analysis section that reports failure cases and robustness metrics. revision: yes
-
Referee: [Datasets] Dataset construction: The two new datasets are introduced for CTTA training and testing, yet the selection and annotation protocol for ensuring that reference clips isolate the intended personalized events (rather than composite or noisy scenes) is not specified. This detail is load-bearing for the benchmark's validity and for the claim of real-world applicability.
Authors: We recognize that a clear description of the annotation protocol is necessary for reproducibility and to support claims of real-world applicability. The reference clips were chosen and verified by human annotators to contain isolated target events; however, this process was only summarized briefly. We will expand the datasets section to detail the selection criteria, annotation guidelines, quality-control steps, and inter-annotator agreement used to ensure references isolate the intended personalized events. revision: yes
Circularity Check
No circularity: empirical framework with new datasets and experiments
full rationale
The paper introduces DreamAudio as a new conditioning framework for reference-based audio event transfer in diffusion models, trained and evaluated on two newly developed datasets plus a human-involved real-world benchmark. No equations, derivations, or self-citations are presented that reduce claimed performance or event isolation to quantities fitted from the same data by construction. The central claims rest on experimental consistency with text prompts and reference features rather than any tautological renaming or load-bearing self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models can be effectively conditioned on both text prompts and reference audio features for controllable generation.
Reference graph
Works this paper leans on
-
[1]
A comprehensive survey of AI-generated content: A history of generative AI from GAN to ChatGPT,
Y . Cao, S. Li, Y . Liu, Z. Yan, Y . Dai, P. S. Yu, and L. Sun, “A comprehensive survey of AI-generated content: A history of generative AI from GAN to ChatGPT,”arXiv:2303.04226, 2023
-
[2]
AudioLDM: Text-to-Audio generation with latent diffusion models,
H. Liu, Z. Chen, Y . Yuan, X. Mei, X. Liu, D. Mandic, W. Wang, and M. D. Plumbley, “AudioLDM: Text-to-Audio generation with latent diffusion models,” inProceedings of the International Conference on Machine Learning, 2023, pp. 21 450–21 474
work page 2023
-
[3]
Sound to visual scene generation by audio-to-visual latent alignment,
K. Sung-Bin, A. Senocak, H. Ha, A. Owens, and T.-H. Oh, “Sound to visual scene generation by audio-to-visual latent alignment,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6430–6440
work page 2023
-
[4]
I hear your true colors: Image guided audio gen- eration,
R. Sheffer and Y . Adi, “I hear your true colors: Image guided audio gen- eration,” inProceedings of IEEE International Conference on Acoustics, Speech and Signal Processing, 2023
work page 2023
-
[5]
FoleyGen: Visually-guided audio generation,
X. Mei, V . Nagaraja, G. Le Lan, Z. Ni, E. Chang, Y . Shi, and V . Chandra, “FoleyGen: Visually-guided audio generation,” inProceedings of IEEE International Workshop on Machine Learning for Signal Processing, 2024
work page 2024
-
[6]
Taming visually guided sound generation,
V . Iashin and E. Rahtu, “Taming visually guided sound generation,” in Proceedings of British Machine Vision Conference, 2021
work page 2021
-
[7]
AudioGen: Textually guided audio generation,
F. Kreuk, G. Synnaeve, A. Polyak, U. Singer, A. D ´efossez, J. Copet, D. Parikh, Y . Taigman, and Y . Adi, “AudioGen: Textually guided audio generation,”International Conference on Learning Representations, 2022
work page 2022
-
[8]
Riffusion: Stable diffusion for real-time music generation,
S. Forsgren and H. Martiros, “Riffusion: Stable diffusion for real-time music generation,” 2022.[Online]. Available: https://riffusion.com/about
work page 2022
-
[9]
WavJourney: Compositional audio creation with large language models,
X. Liu, Z. Zhu, H. Liu, Y . Yuan, M. Cui, Q. Huang, J. Liang, Y . Cao, Q. Kong, M. D. Plumbleyet al., “WavJourney: Compositional audio creation with large language models,”arXiv:2307.14335, 2023. 11
-
[10]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inProceedings of International Conference on Learning Representa- tions, 2020
work page 2020
-
[11]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 6840–6851
work page 2020
-
[12]
AudioSet: An ontology and human-labeled dataset for audio events,
J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “AudioSet: An ontology and human-labeled dataset for audio events,” inProceedings of IEEE International Conference on Acoustics, Speech and Signal Processing, 2017, pp. 776–780
work page 2017
-
[13]
X. Mei, C. Meng, H. Liu, Q. Kong, T. Ko, C. Zhao, M. D. Plumbley, Y . Zou, and W. Wang, “WavCaps: A ChatGPT-assisted weakly-labelled audio captioning dataset for audio-language multimodal research,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 3339–3354, 2024
work page 2024
-
[14]
A large-scale dataset for audio- language representation learning,
L. Sun, X. Xu, M. Wu, and W. Xie, “A large-scale dataset for audio- language representation learning,”arXiv:2309.11500, 2023
-
[15]
Sound-VECaps: Improving audio generation with visual enhanced captions,
Y . Yuan, D. Jia, X. Zhuang, Y . Chen, Z. Liu, Z. Chen, Y . Wang, Y . Wang, X. Liu, X. Kanget al., “Sound-VECaps: Improving audio generation with visual enhanced captions,” inAudio Imagination: NeurIPS 2024 Workshop AI-Driven Speech, Music, and Sound Generation
work page 2024
-
[16]
AudioGen: textually guided audio generation,
F. Kreuk, G. Synnaeve, A. Polyak, U. Singer, A. D ´efossez, J. Copet, D. Parikh, Y . Taigman, and Y . Adi, “AudioGen: textually guided audio generation,” inProceedings of International Conference on Learning Representations, 2023
work page 2023
-
[17]
Diffsound: Discrete diffusion model for text-to-sound generation,
D. Yang, J. Yu, H. Wang, W. Wang, C. Weng, Y . Zou, and D. Yu, “Diffsound: Discrete diffusion model for text-to-sound generation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023
work page 2023
-
[19]
Make-An-Audio 2: Temporal-enhanced text-to- audio generation,
J. Huang, Y . Ren, R. Huang, D. Yang, Z. Ye, C. Zhang, J. Liu, X. Yin, Z. Ma, and Z. Zhao, “Make-An-Audio 2: Temporal-enhanced text-to- audio generation,”arXiv:2305.18474, 2023
-
[20]
Retrieval-augmented text-to-audio generation,
Y . Yuan, H. Liu, X. Liu, Q. Huang, M. D. Plumbley, and W. Wang, “Retrieval-augmented text-to-audio generation,” inProceedings of IEEE International Conference on Acoustics, Speech and Signal, 2024, pp. 581–585
work page 2024
-
[21]
Audioldm 2: Learning holistic audio generation with self-supervised pretraining,
H. Liu, Y . Yuan, X. Liu, X. Mei, Q. Kong, Q. Tian, Y . Wang, W. Wang, Y . Wang, and M. D. Plumbley, “Audioldm 2: Learning holistic audio generation with self-supervised pretraining,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024
work page 2024
-
[22]
DreamBooth: Fine tuning text-to-image diffusion models for subject- driven generation,
N. Ruiz, Y . Li, V . Jampani, Y . Pritch, M. Rubinstein, and K. Aberman, “DreamBooth: Fine tuning text-to-image diffusion models for subject- driven generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 500–22 510
work page 2023
-
[23]
Zero-shot text-to-image generation,
A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. V oss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” inProceedings of International Conference on Machine Learning, 2021, pp. 8821–8831
work page 2021
-
[24]
Hierarchical Text-Conditional Image Generation with CLIP Latents
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with CLIP latents,”arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Improving image generation with better captions,
J. Betker, G. Goh, L. Jing, T. Brooks, J. Wang, L. Li, L. Ouyang, J. Zhuang, J. Lee, Y . Guoet al., “Improving image generation with better captions,”Computer Science., vol. 2, no. 3, 2023
work page 2023
-
[26]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2022, pp. 10 684–10 695
work page 2022
-
[27]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boeselet al., “Scaling rectified flow transformers for high-resolution image synthesis,” inProceedings of International Conference on Machine Learning, 2024
work page 2024
-
[28]
SoundCTM: Uniting score-based and consistency models for text-to-sound generation,
K. Saito, D. Kim, T. Shibuya, C.-H. Lai, Z. Zhong, Y . Takida, and Y . Mitsufuji, “SoundCTM: Uniting score-based and consistency models for text-to-sound generation,”arXiv:2405.18503, 2024
-
[29]
M. Yang, B. Shi, M. Le, W.-N. Hsu, and A. Tjandra, “Audiobox TTA- RAG: Improving zero-shot and few-shot text-to-audio with retrieval- augmented generation,”arXiv:2411.05141, 2024
-
[30]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” inProceedings of IEEE International Conference on Computer Vision, 2023
work page 2023
-
[31]
AudioCaps: Generating captions for audios in the wild,
C. D. Kim, B. Kim, H. Lee, and G. Kim, “AudioCaps: Generating captions for audios in the wild,” inProceedings of Conference of the North American Chapter of the Association for Computational Linguistics, 2019, pp. 119–132
work page 2019
-
[32]
Score-based generative modeling through stochastic differen- tial equations,
Y . Song, J. Sohl-Dickstein, D. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differen- tial equations,” inProceedings of International Conference on Learning Representations, 2021
work page 2021
-
[33]
Diffusion models beat GANs on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat GANs on image synthesis,” inAdvances in Neural Information Processing Systems, 2021
work page 2021
-
[34]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. Denton, S. K. S. Ghasemipour, B. K. Ayan, S. S. Mahdavi, R. G. Lopes, T. Salimans, J. Ho, D. J. Fleet, and M. Norouzi, “Photorealistic text-to-image dif- fusion models with deep language understanding,”arXiv:2205.11487, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Image super-resolution via iterative refinement,
C. Saharia, J. Ho, W. Chan, T. Salimans, D. J. Fleet, and M. Norouzi, “Image super-resolution via iterative refinement,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 4, pp. 4713– 4726, 2022
work page 2022
-
[36]
Wave- Grad: Estimating gradients for waveform generation,
N. Chen, Y . Zhang, H. Zen, R. Weiss, M. Norouzi, and W. Chan, “Wave- Grad: Estimating gradients for waveform generation,” inProceedings of International Conference on Learning Representations, 2021
work page 2021
-
[37]
DiffWave: A versatile diffusion model for audio synthesis,
Z. Kong, W. Ping, J. Huang, K. Zhao, and B. Catanzaro, “DiffWave: A versatile diffusion model for audio synthesis,” inInternational Confer- ence on Learning Representations, 2021
work page 2021
-
[38]
Make-A-Video: Text-to-video generation without text-video data,
U. Singer, A. Polyak, T. Hayes, X. Yin, J. An, S. Zhang, Q. Hu, H. Yang, O. Ashual, O. Gafniet al., “Make-A-Video: Text-to-video generation without text-video data,” inProceedings of International Conference on Learning Representations, 2022
work page 2022
-
[39]
Imagen Video: High Definition Video Generation with Diffusion Models
J. Ho, W. Chan, C. Saharia, J. Whang, R. Gao, A. Gritsenko, D. P. Kingma, B. Poole, M. Norouzi, D. J. Fleet, and T. Salimans, “Ima- gen Video: High definition video generation with diffusion models,” arXiv:2210.02303, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
Grad- TTS: A diffusion probabilistic model for text-to-speech,
V . Popov, I. V ovk, V . Gogoryan, T. Sadekova, and M. Kudinov, “Grad- TTS: A diffusion probabilistic model for text-to-speech,” inProceedings of International Conference on Machine Learning, 2021, pp. 8599–8608
work page 2021
-
[41]
ResGrad: Residual denoising diffusion probabilistic models for text to speech,
Z. Chen, Y . Wu, Y . Leng, J. Chen, H. Liu, X. Tan, Y . Cui, K. Wang, L. He, S. Zhao, J. Bian, and D. Mandic, “ResGrad: Residual denoising diffusion probabilistic models for text to speech,”arXiv preprint:2212.14518, 2022
-
[42]
Bilateral denoising diffusion models,
M. Lam, J. Wang, R. Huang, D. Su, and D. Yu, “Bilateral denoising diffusion models,” inInternational Conference on Learning Represen- tations, 2022
work page 2022
-
[43]
Priorgrad: Improving conditional denoising diffu- sion models with data-driven adaptive prior,
S. Lee, H. Kim, C. Shin, X. Tan, C. Liu, Q. Meng, T. Qin, W. Chen, S. Yoon, and T. Liu, “Priorgrad: Improving conditional denoising diffu- sion models with data-driven adaptive prior,” inInternational Conference on Learning Representations, 2022
work page 2022
-
[44]
InferGrad: Improving diffusion models for vocoder by considering inference in training,
Z. Chen, X. Tan, K. Wang, S. Pan, D. Mandic, L. He, and S. Zhao, “InferGrad: Improving diffusion models for vocoder by considering inference in training,” inProceedings of IEEE International Conference on Acoustics, Speech and Signal Processing, 2022
work page 2022
-
[45]
Acoustic scene generation with conditional SampleRNN,
Q. Kong, Y . Xu, T. Iqbal, Y . Cao, W. Wang, and M. D. Plumbley, “Acoustic scene generation with conditional SampleRNN,” inProceed- ings of IEEE International Conference on Acoustics, Speech and Signal Processing, 2019, pp. 925–929
work page 2019
-
[46]
Conditional sound generation using neural discrete time-frequency representation learning,
X. Liu, T. Iqbal, J. Zhao, Q. Huang, M. Plumbley, and W. Wang, “Conditional sound generation using neural discrete time-frequency representation learning,”Proceedings of IEEE International Workshop on Machine Learning for Signal Processing, 2021
work page 2021
-
[47]
Leveraging pre-trained AudioLDM for sound generation: A benchmark study,
Y . Yuan, H. Liu, J. Liang, X. Liu, M. D. Plumbley, and W. Wang, “Leveraging pre-trained AudioLDM for sound generation: A benchmark study,” inProceedings of European Association for Signal Processing, 2023
work page 2023
-
[48]
HiFi-GAN: generative adversarial networks for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “HiFi-GAN: generative adversarial networks for efficient and high fidelity speech synthesis,” inProceedings of the International Conference on Neural Information Processing Systems, 2020, pp. 17 022–17 033
work page 2020
-
[49]
MelGAN: Generative adversarial networks for conditional waveform synthesis,
K. Kumar, R. Kumar, T. De Boissiere, L. Gestin, W. Z. Teoh, J. Sotelo, A. De Brebisson, Y . Bengio, and A. C. Courville, “MelGAN: Generative adversarial networks for conditional waveform synthesis,”Advances in Neural Information Processing Systems, vol. 32, 2019
work page 2019
-
[50]
BigVGAN: A universal neural vocoder with large-scale training,
S.-g. Lee, W. Ping, B. Ginsburg, B. Catanzaro, and S. Yoon, “BigVGAN: A universal neural vocoder with large-scale training,” inProceedings of International Conference on Learning Representations, 2022
work page 2022
-
[51]
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” inProceedings of IEEE Inter- national Conference on Acoustics, Speech and Signal Processing, 2023. 12
work page 2023
-
[52]
Text-to-audio generation using instruction tuned LLM and latent diffusion model,
D. Ghosal, N. Majumder, A. Mehrish, and S. Poria, “Text-to-audio generation using instruction tuned LLM and latent diffusion model,” arXiv:2304.13731, 2023
-
[53]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”Journal of Machine Learning Research, vol. 21, no. 1, pp. 5485–5551, 2020
work page 2020
-
[54]
Using pre-training can improve model robustness and uncertainty,
D. Hendrycks, K. Lee, and M. Mazeika, “Using pre-training can improve model robustness and uncertainty,” inProceedings of International Conference on Machine Learning, vol. 97, 2019, pp. 2712–2721
work page 2019
-
[55]
Text-driven Foley sound generation with latent diffusion model,
Y . Yuan, H. Liu, X. Kang, P. Wu, M. D. Plumbley, and W. Wang, “Text-driven Foley sound generation with latent diffusion model,” in Proceedings of the Detection and Classification of Acoustic Scenes and Events Workshop, 2023, pp. 231–235
work page 2023
-
[56]
Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing,
M. Cao, X. Wang, Z. Qi, Y . Shan, X. Qie, and Y . Zheng, “Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 560–22 570
work page 2023
-
[57]
Anydoor: Zero-shot object-level image customization,
X. Chen, L. Huang, Y . Liu, Y . Shen, D. Zhao, and H. Zhao, “Anydoor: Zero-shot object-level image customization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 6593–6602
work page 2024
-
[58]
Encoder-based domain tuning for fast personalization of text-to- image models,
R. Gal, M. Arar, Y . Atzmon, A. H. Bermano, G. Chechik, and D. Cohen- Or, “Encoder-based domain tuning for fast personalization of text-to- image models,”ACM Transactions on Graphics, vol. 42, no. 4, 2023
work page 2023
-
[59]
Imagic: Text-based real image editing with diffusion models,
B. Kawar, S. Zada, O. Lang, O. Tov, H. Chang, T. Dekel, I. Mosseri, and M. Irani, “Imagic: Text-based real image editing with diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6007–6017
work page 2023
-
[60]
Key-locked rank one editing for text-to-image personalization,
Y . Tewel, R. Gal, G. Chechik, and Y . Atzmon, “Key-locked rank one editing for text-to-image personalization,” inProceedings of ACM SIGGRAPH, 2023, pp. 1–11
work page 2023
-
[61]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
R. Gal, Y . Alaluf, Y . Atzmon, O. Patashnik, A. H. Bermano, G. Chechik, and D. Cohen-Or, “An image is worth one word: Personalizing text-to- image generation using textual inversion,”arXiv:2208.01618, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[62]
arXiv preprint arXiv:2303.09522 (2023)
A. V oynov, Q. Chu, D. Cohen-Or, and K. Aberman, “P+: Extended textual conditioning in text-to-image generation,”arXiv:2303.09522, 2023
-
[63]
A neural space- time representation for text-to-image personalization,
Y . Alaluf, E. Richardson, G. Metzer, and D. Cohen-Or, “A neural space- time representation for text-to-image personalization,”ACM Transac- tions on Graphics, vol. 42, no. 6, 2023
work page 2023
-
[64]
Improving expressivity of GNNs with subgraph- specific factor embedded normalization,
K. Chen, S. Liu, T. Zhu, J. Qiao, Y . Su, Y . Tian, T. Zheng, H. Zhang, Z. Feng, J. Yeet al., “Improving expressivity of GNNs with subgraph- specific factor embedded normalization,” inProceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 237–249
work page 2023
-
[65]
D. Li, J. Li, and S. Hoi, “BLIP-Diffusion: Pre-trained subject represen- tation for controllable text-to-image generation and editing,”Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[66]
Cones: Concept neurons in diffusion models for customized generation,
Z. Liu, R. Feng, K. Zhu, Y . Zhang, K. Zheng, Y . Liu, D. Zhao, J. Zhou, and Y . Cao, “Cones: Concept neurons in diffusion models for customized generation,”arXiv:2303.05125, 2023
-
[67]
HyperDreamBooth: Hypernetworks for fast personalization of text-to-image models,
N. Ruiz, Y . Li, V . Jampani, W. Wei, T. Hou, Y . Pritch, N. Wadhwa, M. Rubinstein, and K. Aberman, “HyperDreamBooth: Hypernetworks for fast personalization of text-to-image models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 6527–6536
work page 2024
-
[68]
Elite: Encoding visual concepts into textual embeddings for customized text-to-image generation,
Y . Wei, Y . Zhang, Z. Ji, J. Bai, L. Zhang, and W. Zuo, “Elite: Encoding visual concepts into textual embeddings for customized text-to-image generation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 15 943–15 953
work page 2023
-
[69]
FreeCustom: Tuning-free customized image generation for multi- concept composition,
G. Ding, C. Zhao, W. Wang, Z. Yang, Z. Liu, H. Chen, and C. Shen, “FreeCustom: Tuning-free customized image generation for multi- concept composition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9089–9098
work page 2024
-
[70]
KNN-Diffusion: Image generation via large-scale retrieval,
S. Sheynin, O. Ashual, A. Polyak, U. Singer, O. Gafni, E. Nachmani, and Y . Taigman, “KNN-Diffusion: Image generation via large-scale retrieval,” inProceedings of International Conference on Learning Representations, 2023
work page 2023
-
[71]
Re-Imagen: Retrieval- augmented text-to-image generator,
W. Chen, H. Hu, C. Saharia, and W. W. Cohen, “Re-Imagen: Retrieval- augmented text-to-image generator,” inProceedings of International Conference on Learning Representations, 2023
work page 2023
-
[72]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational Conference on Machine Learning, 2021, pp. 8748–8763
work page 2021
-
[73]
T-CLAP: Temporal-enhanced contrastive language- audio pretraining,
Y . Yuan, Z. Chen, X. Liu, H. Liu, X. Xu, D. Jia, Y . Chen, M. D. Plumb- ley, and W. Wang, “T-CLAP: Temporal-enhanced contrastive language- audio pretraining,” inProceedings of IEEE International Workshop on Machine Learning for Signal Processing, 2024
work page 2024
-
[74]
Flowsep: Language-queried sound separation with rectified flow matching,
Y . Yuan, X. Liu, H. Liu, M. D. Plumbley, and W. Wang, “Flowsep: Language-queried sound separation with rectified flow matching,”arXiv preprint arXiv:2409.07614, 2024
-
[75]
A. Vyas, B. Shi, M. Le, A. Tjandra, Y .-C. Wu, B. Guo, J. Zhang, X. Zhang, R. Adkins, W. Nganet al., “Audiobox: Unified audio generation with natural language prompts,”arXiv:2312.15821, 2023
-
[76]
F. Font, G. Roma, and X. Serra, “Freesound technical demo,” in Proceedings of the ACM International Conference on Multimedia, 2013, pp. 411–412
work page 2013
-
[77]
Deep convolutional neural networks and data augmentation for environmental sound classification,
J. Salamon and J. P. Bello, “Deep convolutional neural networks and data augmentation for environmental sound classification,”IEEE Signal Processing Letters, vol. 24, no. 3, pp. 279–283, 2017
work page 2017
-
[78]
ESC: dataset for environmental sound classification,
K. J. Piczak, “ESC: dataset for environmental sound classification,” in Proceedings of the ACM International Conference on Multimedia, 2015
work page 2015
-
[79]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image Recognition,”arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[80]
PANNs: Large-scale pretrained audio neural networks for audio pattern recognition,
Q. Kong, Y . Cao, T. Iqbal, Y . Wang, W. Wang, and M. D. Plumbley, “PANNs: Large-scale pretrained audio neural networks for audio pattern recognition,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2880–2894, 2020
work page 2020
-
[81]
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
A. Tjandra, Y .-C. Wu, B. Guo, J. Hoffman, B. Ellis, A. Vyas, B. Shi, S. Chen, M. Le, N. Zacharovet al., “Meta Audiobox Aesthetics: Unified automatic quality assessment for speech, music, and sound,” arXiv:2502.05139, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.