BIR-Adapter: A parameter-efficient diffusion adapter for blind image restoration
Pith reviewed 2026-05-18 17:44 UTC · model grok-4.3
The pith
BIR-Adapter shows that a lightweight attention adapter can turn pretrained diffusion models into competitive blind image restorers while using up to 36 times fewer trained parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
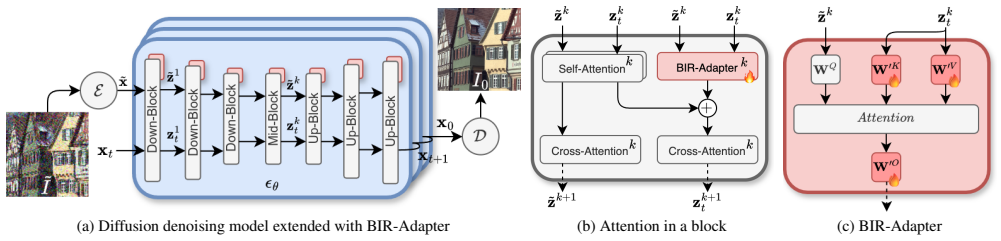
BIR-Adapter is a parameter-efficient diffusion adapter that introduces a plug-and-play attention mechanism into pretrained diffusion models. By leveraging the informative representations retained by these models under image degradations and adapting a sampling guidance mechanism, it achieves competitive or superior performance on blind image restoration tasks with significantly fewer trained parameters, up to 36 times less than state-of-the-art methods. The adapter design further allows seamless integration into existing models to handle additional unknown degradations.
What carries the argument
The BIR-Adapter, a lightweight plug-and-play attention module that extracts and applies retained representations from pretrained diffusion models to guide the restoration process.
Load-bearing premise
Large pretrained diffusion models keep sufficiently useful internal representations of degraded images that a small attention adapter can access and use effectively without full retraining or extra feature extractors.
What would settle it
A test on a novel degradation combination, such as heavy motion blur plus heavy compression artifacts absent from the training data, where the adapter's performance falls substantially below fully fine-tuned diffusion models would indicate the retained-representation premise does not hold broadly.
Figures













read the original abstract
We introduce the BIR-Adapter, a parameter-efficient diffusion adapter for blind image restoration. Diffusion-based restoration methods have demonstrated promising performance in addressing this fundamental problem in computer vision, typically relying on auxiliary feature extractors or extensive fine-tuning of pre-trained models. Building on the observation that large-scale pretrained diffusion models can retain informative representations under image degradations, BIR-Adapter introduces a parameter-efficient, plug-and-play attention mechanism that substantially reduces the number of trained parameters. To further improve reliability, we adapt a sampling guidance mechanism that mitigates hallucinations during restoration. Experiments on synthetic and real-world degradations demonstrate that BIR-Adapter achieves competitive, and in several settings superior, performance compared to state-of-the-art methods while requiring up to 36x fewer trained parameters. Moreover, the adapter-based design enables integration into existing models. We validate this generality by extending a super-resolution-only diffusion model to handle additional unknown degradations, highlighting the adaptability of our approach for broader image restoration tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BIR-Adapter, a parameter-efficient, plug-and-play attention adapter for blind image restoration that operates on frozen large-scale pretrained diffusion models. Building on the premise that such models retain informative representations under degradations, the method adds a lightweight attention mechanism, incorporates sampling guidance to reduce hallucinations, and reports competitive or superior performance on synthetic and real-world degradations with up to 36x fewer trained parameters. It further demonstrates generality by extending a super-resolution-only diffusion model to additional unknown degradations.
Significance. If the empirical claims hold under rigorous controls, the work offers a practical route to efficient adaptation of diffusion models for restoration tasks, lowering the barrier to using large pretrained backbones without full fine-tuning or auxiliary extractors. The adapter design and generality experiment could influence parameter-efficient transfer in other vision domains.
major comments (2)
- Abstract and §4 (Experiments): the claim of 'up to 36x fewer trained parameters' and competitive/superior performance is central but lacks explicit reporting of baseline parameter counts, exact measurement protocol (e.g., trainable vs. total parameters), and statistical significance across runs. Without these, the efficiency advantage cannot be verified as load-bearing for the main contribution.
- §4.1 and Table 2 (synthetic degradations): the experimental controls for blind restoration (e.g., whether test degradations match training distributions, choice of baselines, and handling of unknown degradations) are not described in sufficient detail to support the 'competitive and in several settings superior' claim; this directly affects the reliability of the performance results.
minor comments (2)
- §3 (Method): clarify the exact architecture of the attention adapter (e.g., query/key/value dimensions, insertion points in the diffusion U-Net) and whether any components are frozen vs. trained.
- Figure 3 or §4.3 (generality experiment): provide quantitative metrics for the extended super-resolution model on the additional degradations rather than qualitative examples alone.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that will strengthen the experimental reporting and clarity of the manuscript.
read point-by-point responses
-
Referee: Abstract and §4 (Experiments): the claim of 'up to 36x fewer trained parameters' and competitive/superior performance is central but lacks explicit reporting of baseline parameter counts, exact measurement protocol (e.g., trainable vs. total parameters), and statistical significance across runs. Without these, the efficiency advantage cannot be verified as load-bearing for the main contribution.
Authors: We agree that explicit documentation of parameter counts and measurement details is needed to make the efficiency claims fully verifiable. In the revised manuscript we will add a dedicated subsection and table in §4 that lists the exact number of trainable parameters for BIR-Adapter and every baseline, with a clear protocol stating that only parameters updated during adapter training are counted while the pretrained diffusion backbone remains frozen. We will also report mean performance and standard deviation over at least three independent runs for the key tables to address statistical significance. revision: yes
-
Referee: §4.1 and Table 2 (synthetic degradations): the experimental controls for blind restoration (e.g., whether test degradations match training distributions, choice of baselines, and handling of unknown degradations) are not described in sufficient detail to support the 'competitive and in several settings superior' claim; this directly affects the reliability of the performance results.
Authors: We accept that the current description of the blind-restoration protocol is insufficiently detailed. We will expand §4.1 with an explicit paragraph that (i) states how synthetic test degradations are generated to ensure they lie outside the training distribution, (ii) justifies the selection of baselines, and (iii) clarifies the evaluation procedure for truly unknown degradations. These additions will directly support the reliability of the reported performance comparisons. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical engineering contribution that introduces BIR-Adapter as a plug-and-play attention mechanism on frozen pretrained diffusion models, building directly on the stated observation that such models retain informative representations under degradations. No derivation chain, first-principles equations, or predictions are presented that reduce by construction to fitted parameters, self-citations, or renamed inputs. Performance claims rest on experimental comparisons to SOTA methods across synthetic and real degradations, with the efficiency and generality results following from the adapter design and sampling guidance without internal reduction to the inputs. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large-scale pretrained diffusion models retain informative representations under image degradations
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We extend the self-attention mechanism to include these degraded features, which are extracted by the model itself... We further introduce a sampling guidance mechanism that mitigates hallucinations.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BIR-Adapter achieves competitive... performance... while requiring up to 36x fewer trained parameters
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
A Causal Diffusion Model for Video Reconstruction from Ultra-Low-Bitrate Representations
A causal diffusion model reconstructs videos from ultra-low-bitrate semantics and compressed frames using temporal distillation from a bidirectional teacher, outperforming prior baselines.
Reference graph
Works this paper leans on
-
[1]
Ntire 2017 challenge on single image super-resolution: Dataset and study
Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. InPro- ceedings of the IEEE conference on computer vision and pat- tern recognition workshops, pages 126–135, 2017. 5, 11, 14, 15, 16
work page 2017
-
[2]
Toward real-world single image super-resolution: A new benchmark and a new model
Jianrui Cai, Hui Zeng, Hongwei Yong, Zisheng Cao, and Lei Zhang. Toward real-world single image super-resolution: A new benchmark and a new model. InProceedings of the IEEE/CVF international conference on computer vision, pages 3086–3095, 2019. 5, 17, 18
work page 2019
-
[3]
Transfer clip for gen- eralizable image denoising
Jun Cheng, Dong Liang, and Shan Tan. Transfer clip for gen- eralizable image denoising. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25974–25984, 2024. 2
work page 2024
-
[4]
Effective diffusion transformer architecture for image super- resolution
Kun Cheng, Lei Yu, Zhijun Tu, Xiao He, Liyu Chen, Yong Guo, Mingrui Zhu, Nannan Wang, Xinbo Gao, and Jie Hu. Effective diffusion transformer architecture for image super- resolution. InProceedings of the AAAI Conference on Arti- ficial Intelligence, pages 2455–2463, 2025. 3, 6, 20
work page 2025
-
[5]
Kostadin Dabov, Alessandro Foi, Vladimir Katkovnik, and Karen Egiazarian. Image denoising by sparse 3-d transform- domain collaborative filtering.IEEE Transactions on image processing, 16(8):2080–2095, 2007. 2
work page 2080
-
[6]
Vinicius Luis Trevisan De Souza, Bruno Augusto Dorta Mar- ques, Harlen Costa Batagelo, and Jo ˜ao Paulo Gois. A re- view on generative adversarial networks for image genera- tion.Computers & Graphics, 114:13–25, 2023. 2
work page 2023
-
[7]
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural informa- tion processing systems, 34:8780–8794, 2021. 2, 3
work page 2021
-
[8]
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Image super-resolution using deep convolutional net- works.IEEE transactions on pattern analysis and machine intelligence, 38(2):295–307, 2015. 2
work page 2015
-
[9]
Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020. 2
work page 2020
-
[10]
Div8k: Diverse 8k resolution image dataset
Shuhang Gu, Andreas Lugmayr, Martin Danelljan, Manuel Fritsche, Julien Lamour, and Radu Timofte. Div8k: Diverse 8k resolution image dataset. In2019 IEEE/CVF Interna- tional Conference on Computer Vision Workshop (ICCVW), pages 3512–3516. IEEE, 2019. 5
work page 2019
-
[11]
Chunming He, Yuqi Shen, Chengyu Fang, Fengyang Xiao, Longxiang Tang, Yulun Zhang, Wangmeng Zuo, Zhenhua Guo, and Xiu Li. Diffusion models in low-level vision: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 2
work page 2025
-
[12]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 6
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 2, 3
work page 2020
-
[14]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4401–4410, 2019. 5
work page 2019
-
[15]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021. 7
work page 2021
-
[16]
Diffusion restoration adapter for real-world image restoration.arXiv preprint arXiv:2502.20679, 2025
Hanbang Liang, Zhen Wang, and Weihui Deng. Diffusion restoration adapter for real-world image restoration.arXiv preprint arXiv:2502.20679, 2025. 3
-
[17]
Swinir: Image restoration us- ing swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration us- ing swin transformer. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1833–1844,
-
[18]
Enhanced deep residual networks for single image super-resolution
Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution. InThe IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR) Workshops,
-
[19]
Diff- bir: Toward blind image restoration with generative diffusion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diff- bir: Toward blind image restoration with generative diffusion prior. InEuropean Conference on Computer Vision, pages 430–448. Springer, 2024. 3, 5, 6, 19
work page 2024
-
[20]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Zhiyuan Ma, Yuzhu Zhang, Guoli Jia, Liangliang Zhao, Yichao Ma, Mingjie Ma, Gaofeng Liu, Kaiyan Zhang, Ning Ding, Jianjun Li, et al. Efficient diffusion models: A com- prehensive survey from principles to practices.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 2025. 3
work page 2025
-
[22]
Deep multi-scale convolutional neural network for dynamic scene deblurring
Seungjun Nah, Tae Hyun Kim, and Kyoung Mu Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3883–3891,
-
[23]
Semantic image synthesis with spatially-adaptive nor- malization
Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive nor- malization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2337–2346,
-
[24]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2
work page 2021
-
[25]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2, 3
work page 2022
-
[26]
A survey of deep learning approaches to image restoration.Neurocomputing, 487:46–65, 2022
Jingwen Su, Boyan Xu, and Hujun Yin. A survey of deep learning approaches to image restoration.Neurocomputing, 487:46–65, 2022. 2
work page 2022
-
[27]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia 9 Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 2, 3
work page 2017
-
[28]
Ex- ploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Ex- ploring clip for assessing the look and feel of images. In AAAI, 2023. 7
work page 2023
-
[29]
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin CK Chan, and Chen Change Loy. Exploiting diffusion prior for real-world image super-resolution.International Journal of Computer Vision, 132(12):5929–5949, 2024. 3, 5, 6, 20
work page 2024
-
[30]
Recovering realistic texture in image super-resolution by deep spatial feature transform
Xintao Wang, Ke Yu, Chao Dong, and Chen Change Loy. Recovering realistic texture in image super-resolution by deep spatial feature transform. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 606–615, 2018. 5
work page 2018
-
[31]
Real-esrgan: Training real-world blind super-resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1905–1914,
work page 1905
-
[32]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1191–1200, 2022. 7
work page 2022
-
[33]
Pixel-aware stable diffusion for realistic image super-resolution and personalized stylization
Tao Yang, Rongyuan Wu, Peiran Ren, Xuansong Xie, and Lei Zhang. Pixel-aware stable diffusion for realistic image super-resolution and personalized stylization. InEuropean Conference on Computer Vision, pages 74–91. Springer,
-
[34]
Fanghua Yu, Jinjin Gu, Zheyuan Li, Jinfan Hu, Xiangtao Kong, Xintao Wang, Jingwen He, Yu Qiao, and Chao Dong. Scaling up to excellence: Practicing model scaling for photo- realistic image restoration in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25669–25680, 2024. 3, 5, 6, 19, 20
work page 2024
-
[35]
Lujun Zhai, Yonghui Wang, Suxia Cui, and Yu Zhou. A com- prehensive review of deep learning-based real-world image restoration.IEEE Access, 11:21049–21067, 2023. 2
work page 2023
-
[36]
Learning deep cnn denoiser prior for image restoration
Kai Zhang, Wangmeng Zuo, Shuhang Gu, and Lei Zhang. Learning deep cnn denoiser prior for image restoration. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3929–3938, 2017. 2
work page 2017
-
[37]
Designing a practical degradation model for deep blind im- age super-resolution
Kai Zhang, Jingyun Liang, Luc Van Gool, and Radu Timofte. Designing a practical degradation model for deep blind im- age super-resolution. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4791–4800,
-
[38]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 3
work page 2023
-
[39]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018. 7
work page 2018
-
[40]
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle- consistent adversarial networks. InProceedings of the IEEE international conference on computer vision, pages 2223– 2232, 2017. 2 10 BIR-Adapter: A Low-Complexity Diffusion Model Adapter for Blind Image Restoration Supplementary Material Cem Etek...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.