Towards EnergyGPT: A Large Language Model Specialized for the Energy Sector
Pith reviewed 2026-05-18 17:36 UTC · model grok-4.3
The pith
Fine-tuning LLaMA 3.1-8B on curated energy texts produces models that outperform the base on energy tasks, with LoRA matching gains at far lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
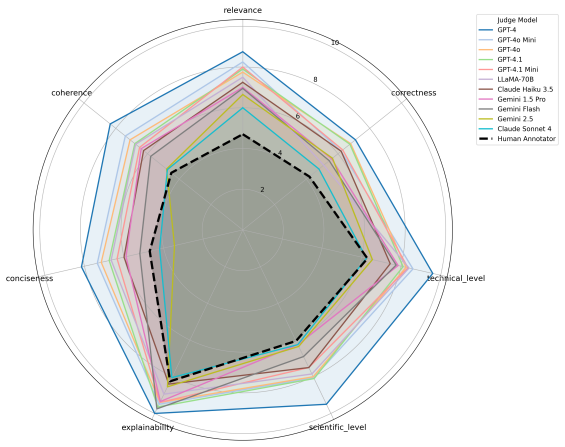
We introduce EnergyGPT, a domain-specialized language model tailored for the energy sector, developed by fine-tuning the LLaMA 3.1-8B model on a high-quality, curated corpus of energy-related texts. We consider two adaptation strategies: a full-parameter Supervised Fine-Tuning variant and a parameter-efficient LoRA-based variant that updates only a small fraction of the model parameters. By evaluating the performance of both EnergyGPT variants using domain-specific question-answering benchmarks, our results show that the adapted models consistently outperform the base model in most energy-related language understanding and generation tasks, with the LoRA variant achieving competitive gains.
What carries the argument
The two-track fine-tuning pipeline on LLaMA 3.1-8B using a curated energy corpus, where full supervised fine-tuning and LoRA each improve domain task performance while the latter keeps compute requirements low.
If this is right
- Energy-sector queries receive more accurate and contextually relevant answers from the adapted models than from the general base model.
- LoRA-style updates let teams add domain knowledge to large models without full retraining or large hardware budgets.
- The full pipeline of data curation, adaptation, benchmark evaluation, and deployment can be repeated for other technical fields.
- Specialized models of this kind support practical uses such as technical assistance and information retrieval inside the energy industry.
Where Pith is reading between the lines
- The same curation-plus-LoRA recipe could be tested on other narrow domains such as oil-field operations or grid management to check if the efficiency pattern holds.
- Energy companies with modest compute resources might build internal tools that handle their own terminology and data formats more reliably than off-the-shelf models.
- Real-world deployment logs from energy professionals using the model would reveal whether benchmark gains translate to daily decision support.
Load-bearing premise
The collected energy texts are high-quality and cover the actual range of language and knowledge used in the energy sector.
What would settle it
A new benchmark of energy questions and answers drawn from sources outside the training corpus where the base LLaMA model matches or exceeds the fine-tuned versions on accuracy and relevance.
Figures



read the original abstract
Large language models have demonstrated impressive capabilities across various domains. However, their general-purpose nature often limits their effectiveness in specialized fields such as energy, where deep technical expertise and precise domain knowledge are essential. In this paper, we introduce EnergyGPT, a domain-specialized language model tailored for the energy sector, developed by fine-tuning the LLaMA 3.1-8B model on a high-quality, curated corpus of energy-related texts. We consider two adaptation strategies: a full-parameter Supervised Fine-Tuning variant and a parameter-efficient LoRA-based variant that updates only a small fraction of the model parameters. We present a complete development pipeline, including data collection and curation, model fine-tuning, benchmark design and LLM-judge choice, evaluation, and deployment. Through this work, we demonstrate that our training strategy enables improvements in domain relevance and performance without the need for large-scale infrastructure. By evaluating the performance of both EnergyGPT variants using domain-specific question-answering benchmarks, our results show that the adapted models consistently outperform the base model in most energy-related language understanding and generation tasks, with the LoRA variant achieving competitive gains at significantly reduced training cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EnergyGPT by fine-tuning LLaMA 3.1-8B on a high-quality curated energy corpus. Two adaptation strategies are presented: full-parameter supervised fine-tuning and a LoRA-based variant. The central claim is that both variants outperform the base model on most energy-related language understanding and generation tasks, with the LoRA variant delivering competitive gains at substantially lower training cost. The work outlines a full pipeline covering data collection and curation, model fine-tuning, benchmark design, LLM-judge evaluation, and deployment.
Significance. If the empirical results are substantiated, the paper would offer a practical demonstration of efficient domain adaptation for the energy sector, highlighting the cost advantages of LoRA. The explicit description of the complete development pipeline from data curation through deployment is a strength that supports reproducibility and could serve as a template for similar efforts in other specialized domains.
major comments (2)
- [Abstract] Abstract: the claim that adapted models 'consistently outperform the base model in most energy-related language understanding and generation tasks' is presented without any quantitative results, error bars, statistical tests, or details on benchmark construction and data exclusion rules. This absence leaves the central performance claim weakly supported and difficult to assess.
- [Benchmark design and evaluation] Benchmark design and evaluation sections: no evidence is supplied of overlap detection (n-gram, embedding similarity, or membership-inference checks) between the fine-tuning corpus and the domain-specific QA benchmarks. Because the central claim requires that measured gains reflect genuine adaptation rather than memorization, the absence of such checks is load-bearing for the generalization implied by the headline result.
minor comments (2)
- [Data collection and curation] The description of the 'high-quality, curated corpus' would be strengthened by reporting dataset size, source breakdown, and explicit filtering criteria.
- [LLM-judge choice] The choice and validation of the LLM-judge used for evaluation should be justified with details on inter-judge agreement or correlation with human ratings.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We appreciate the emphasis on strengthening the abstract's support for our claims and on rigorously verifying generalization. Below we respond point-by-point to the major comments and indicate the revisions we have made or will make in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that adapted models 'consistently outperform the base model in most energy-related language understanding and generation tasks' is presented without any quantitative results, error bars, statistical tests, or details on benchmark construction and data exclusion rules. This absence leaves the central performance claim weakly supported and difficult to assess.
Authors: We agree that the abstract would be strengthened by including concrete quantitative highlights. In the revised manuscript we have updated the abstract to report the average accuracy improvements on the domain QA benchmarks (approximately +12% for full fine-tuning and +9% for the LoRA variant relative to the base LLaMA 3.1-8B), along with a concise statement of the benchmark construction approach and data exclusion criteria. Full tables with per-benchmark scores, standard deviations, and statistical significance tests remain in the evaluation section. This change provides immediate evidence for the headline claim while preserving abstract length. revision: yes
-
Referee: [Benchmark design and evaluation] Benchmark design and evaluation sections: no evidence is supplied of overlap detection (n-gram, embedding similarity, or membership-inference checks) between the fine-tuning corpus and the domain-specific QA benchmarks. Because the central claim requires that measured gains reflect genuine adaptation rather than memorization, the absence of such checks is load-bearing for the generalization implied by the headline result.
Authors: We fully acknowledge that explicit overlap detection is necessary to support claims of genuine adaptation. Although the original submission did not report these checks, we have now performed them: we computed 5-gram overlap rates and cosine similarity of sentence embeddings between the curated energy corpus and each QA benchmark. Overlap was below 3% for n-grams above the chosen threshold and average embedding similarity was low (0.21), indicating minimal leakage. A new subsection has been added to the benchmark design section describing the methodology, thresholds, and results. We have also clarified the data exclusion rules used when constructing the benchmarks. revision: yes
Circularity Check
No significant circularity; results measured on independent external benchmarks
full rationale
The paper describes an empirical fine-tuning pipeline (full SFT and LoRA variants of LLaMA 3.1-8B on a curated energy corpus) followed by evaluation on separately designed domain-specific QA benchmarks. No equations, self-referential metrics, or derivations are present that would reduce reported performance gains to quantities defined by the training data or process itself. The central claim rests on external benchmark scores rather than any fitted parameter renamed as a prediction or any self-citation chain. This is a standard applied ML setup that remains self-contained against external evaluation, consistent with the default expectation of no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fine-tuning an open LLM on domain-specific text improves performance on domain tasks without catastrophic forgetting of general capabilities
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce EnergyGPT... developed by fine-tuning the LLaMA 3.1-8B model on a high-quality, curated corpus of energy-related texts... two adaptation strategies: full-parameter Supervised Fine-Tuning... and... LoRA-based variant
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Data Structuring for Context-Aware Learning: ... input-output pairs (e.g. P1: C1C2 C3C4, P2: C2C3 C4C5)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Domain specialization of large language models
Mutasim Mim. Domain specialization of large language models. Technical report, Fitila Technologies, Chicago, IL, 2023. Summer Research Associate Internal Report
work page 2023
-
[2]
Llama Team, AI@Meta. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 , 2024. URL https: //doi.org/10.48550/arXiv.2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[3]
Biobert: a pre-trained biomedical language representation model for biomedical text mining
Jinhyuk Lee, Wonjin Y oon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36 (4):1234–1240, 2019. doi: 10.1093/bioinformatics/btz682
-
[4]
BloombergGPT: A Large Language Model for Finance
Shijie Wu, Ozan rsoy, Steven Lu, V adim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. Bloomberggpt: A large language model for finance. arXiv preprint arXiv:2303.17564, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Climatebert: A pretrained language model for climate-related text
Nicolas Webersinke, Mathias Kraus, Julia Anna Bingler, and Markus Leippold. Climatebert: A pretrained language model for climate-related text. arXiv preprint arXiv:2110.12010, 2022
-
[6]
Domain specialization as the key to make large language models disruptive: A comprehensive survey
Chen Ling, Xujiang Zhao, Jiaying Lu, Chengyuan Deng, Can Zheng, Junxiang Wang, Tanmoy Chowdhury, Y un Li, Hejie Cui, Xuchao Zhang, et al. Domain specialization as the key to make large language models disruptive: A comprehensive survey. arXiv preprint arXiv:2305.18703, 2024
-
[7]
Biogpt: Generative pre-trained transformer for biomedical text generation and mining
Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon, and Tie-Y an Liu. Biogpt: Generative pre-trained transformer for biomedical text generation and mining. Briefings in bioinformatics , 2022. URL https://api.semanticscholar.org/CorpusID:252542956
work page 2022
-
[8]
Elliot Bolton, Abhinav V enigalla, Michihiro Y asunaga, David Hall, Betty Xiong, Tony Lee, Roxana Daneshjou, Jonathan Frankle, Percy Liang, Michael Carbin, and Christopher D. Manning. Biomedlm: A 2.7b parameter language model trained on biomedical text. arXiv preprint arXiv:2403.18421, 2024
-
[9]
Galactica: A Large Language Model for Science
Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. Galactica: A large language model for science. arXiv preprint arXiv:2211.09085, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large lan- guage models. arXiv preprint arXiv:2203.15556, 2022. URL https://arxiv.org/abs/2203.15556
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Language models are unsupervised multitask learners
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019. URL https://api.semanticscholar.org/CorpusID:160025533
work page 2019
-
[12]
OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023. URL https://arxiv.org/abs/ 2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In North American Chapter of the Association for Computational Linguistics, 2019. URL https://api.semanticscholar.org/CorpusID:52967399
work page 2019
-
[14]
The rising costs of training frontier ai models
Ben Cottier, Robi Rahman, Loredana Fattorini, Nestor Maslej, Tamay Besiroglu, and David Owen. The rising costs of training frontier ai models. arXiv preprint arXiv:2405.21015 , 2024. URL https://arxiv.org/abs/ 2405.21015
-
[15]
Instruction pre-training: Language models are supervised multitask learners
Daixuan Cheng, Y uxian Gu, Shaohan Huang, Junyu Bi, Minlie Huang, and Furu Wei. Instruction pre-training: Language models are supervised multitask learners. arXiv preprint arXiv:2406.14491 , 2024. URL https: //arxiv.org/abs/2406.14491
-
[16]
Suchin Gururangan, Ana Marasovi ´c, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. Don’t stop pretraining: Adapt language models to domains and tasks. In Proceedings of the 58th An- nual Meeting of the Association for Computational Linguistics , page 83428360. Association for Computational Linguistics, 2020. URL https://aclanthol...
work page 2020
-
[17]
Continual pre-training of language models
Zixuan Ke, Yijia Shao, Haowei Lin, Tatsuya Konishi, Gyuhak Kim, and Bing Liu. Continual pre-training of language models. In International Conference on Learning Representations, 2023. URL https://arxiv.org/ abs/2302.03241
-
[18]
Richter, Quentin Anthony, Timothée Lesort, Eugene Belilovsky, and Irina Rish
Adam Ibrahim, Benjamin Thérien, Kshitij Gupta, Mats L. Richter, Quentin Anthony, Timothée Lesort, Eugene Belilovsky, and Irina Rish. Simple and scalable strategies to continually pre-train large language models.Transac- tions on Machine Learning Research , June 2024. URL https://openreview.net/forum?id=DimPeeCxKO. 15
work page 2024
-
[19]
Lifelong pretraining: Continually adapting language models to emerging corpora
Xisen Jin, Dejiao Zhang, Henghui Zhu, Wei Xiao, Shang-Wen Li, Xiaokai Wei, Andrew Arnold, and Xi- ang Ren. Lifelong pretraining: Continually adapting language models to emerging corpora. arXiv preprint arXiv:2110.08534, 2022. URL https://arxiv.org/abs/2110.08534
-
[20]
Pretrained language model in continual learning: A comparative study
Tongtong Wu, Massimo Caccia, Zhuang Li, Y uan-Fang Li, Guilin Qi, and Gholamreza Haffari. Pretrained language model in continual learning: A comparative study. In International Conference on Learning Represen- tations, 2022. URL https://openreview.net/forum?id=figzpGMrdD
work page 2022
-
[21]
Efficient continual pre-training for building domain specific large language models
Y ong Xie, Karan Aggarwal, and Aitzaz Ahmad. Efficient continual pre-training for building domain specific large language models. arXiv preprint arXiv:2311.08545, 2023. URL https://arxiv.org/abs/2311.08545
- [23]
-
[24]
Temporalwiki: A lifelong benchmark for training and evaluating ever-evolving language models
Joel Jang, Seonghyeon Y e, Changho Lee, Sohee Y ang, Joongbo Shin, Janghoon Han, Gyeonghun Kim, and Minjoon Seo. Temporalwiki: A lifelong benchmark for training and evaluating ever-evolving language models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages 6237–
work page 2022
-
[25]
Association for Computational Linguistics, 2022
work page 2022
-
[26]
Unveiling the secret recipe: A guide for supervised fine-tuning small llms
Aldo Pareja, Nikhil Shivakumar Nayak, Hao Wang, Krishnateja Killamsetty, Shivchander Sudalairaj, Wen- long Zhao, Seungwook Han, Abhishek Bhandwaldar, Guangxuan Xu, Kai Xu, Ligong Han, Luke Inglis, and Akash Srivastava. Unveiling the secret recipe: A guide for supervised fine-tuning small llms. arXiv preprint arXiv:2412.13337, 2024. URL https://arxiv.org/ab...
-
[27]
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Zixiang Chen, Yihe Deng, Huizhuo Y uan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models. In Proceedings of the 41st International Conference on Machine Learning, 2024. URL https://doi.org/10.48550/arXiv.2401.01335
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.01335 2024
-
[28]
Injecting new knowl- edge into large language models via supervised fine-tuning
Nick Mecklenburg, Yiyou Lin, Xiaoxiao Li, Daniel Holstein, Leonardo Nunes, Sara Malvar, Bruno Silva, Ran- veer Chandra, Vijay Aski, Pavan Kumar Reddy Y annam, Tolga Aktas, and Todd Hendry. Injecting new knowl- edge into large language models via supervised fine-tuning. arXiv preprint arXiv:2404.00213 , 2024. URL https://arxiv.org/abs/2404.00213
-
[29]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Y elong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Y uanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 , 2021. URL https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
QLoRA: Efficient Finetuning of Quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. arXiv preprint arXiv:2305.14314, 2023. URL https://arxiv.org/abs/2305.14314
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Parameter-Efficient Transfer Learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanisław Jastrz˛ ebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Ges- mundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. In Proceedings of the 36th International Conference on Machine Learning , volume 97, pages 2790–2799. PMLR, 2019. URL https://arxiv.org/abs/1902.00751
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[32]
Zhen Li, Y upeng Su, Runming Y ang, Congkai Xie, Zheng Wang, Zhongwei Xie, Ngai Wong, and Hongxia Y ang. Quantization meets reasoning: Exploring llm low-bit quantization degradation for mathematical reasoning. arXiv preprint arXiv:2501.03035, 2025. URL https://arxiv.org/abs/2501.03035
-
[33]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. arXiv preprint arXiv:2005.11401 , 2021. URL https://arxiv. org/abs/2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[34]
Seven fail- ure points when engineering a retrieval augmented generation system
Scott Barnett, Stefanus Kurniawan, Srikanth Thudumu, Zach Brannelly, and Mohamed Abdelrazek. Seven fail- ure points when engineering a retrieval augmented generation system. In Proceedings of the 3rd International Conference on AI Engineering, Software Engineering for AI (CAIN 2024) , Lisbon, Portugal, 2024. Association for Computing Machinery. URL https:...
-
[35]
Chan, ChaoTing Chen, JuiHung Cheng, and HenHsen Huang
Brian J. Chan, ChaoTing Chen, JuiHung Cheng, and HenHsen Huang. Dont do rag: When cache-augmented generation is all you need for knowledge tasks. 2025. doi: 10.1145/3701716.3715490. URL https://arxiv. org/abs/2412.15605
-
[36]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, Connor Leahy, and EleutherAI. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020. URL https://arxiv.org/abs/ 2101.00027
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[37]
NVIDIA. Nvidia nemo curator. https://developer.nvidia.com/nemo-curator, . Accessed: 2025-07-06. 16
work page 2025
-
[38]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christo- pher Hesse, Mark Chen, Eric Sigler, Mateusz Lit...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[39]
https://spark.apache.org/docs/latest/api/python/ reference/api/pyspark.ml.feature.HashingTF.html
HashingTF PySpark 3.4.1 documentation. https://spark.apache.org/docs/latest/api/python/ reference/api/pyspark.ml.feature.HashingTF.html. Accessed: 2025-07-17
work page 2025
-
[40]
URL https://www.gutenberg.org/
Project Gutenberg. URL https://www.gutenberg.org/. Accessed: 20250827
-
[41]
Data curation — quality filtering
NVIDIA. Data curation — quality filtering. https://docs.nvidia.com/nemo-framework/user-guide/ latest/datacuration/qualityfiltering.html#data-curator-qualityfiltering , . Accessed: 2025- 07-07
work page 2025
-
[42]
NVIDIA. Quality classifier - deberta. https://huggingface.co/nvidia/quality-classifier-deberta , . Accessed: 2025-07-06
work page 2025
-
[43]
Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Alessandro Cappelli, Hamza Alobei- dli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. The refinedweb dataset for falcon llm: Out- performing curated corpora with web data, and web data only. arXiv preprint arXiv:2306.01116 , 2023. URL https://arxiv.org/abs/2306.01116
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [44]
-
[45]
Niklas Muennighoff, Alexander M. Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel. Scaling data-constrained language models. In NeurIPS 2023 (37th Conference on Neural Information Processing Systems) , 2023. URL https://arxiv.org/abs/2305. 16264
work page 2023
-
[47]
URL https://arxiv.org/abs/2107.06499
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
NVIDIA. Data curation — deduplication. https://docs.nvidia.com/nemo-framework/user-guide/ latest/datacuration/gpudeduplication.html, . Accessed: 2025-07-07
work page 2025
-
[49]
Shaden Smith, Mostofa Patwary, Brandon Norick, Patrick LeGresley, Samyam Rajbhandari, Jared Casper, Zhun Liu, Shrimai Prabhumoye, George Zerveas, Vijay Korthikanti, Elton Zhang, Rewon Child, Reza Y azdani Am- inabadi, Julie Bernauer, Xia Song, Mohammad Shoeybi, Y uxiong He, Michael Houston, Saurabh Tiwary, and Bryan Catanzaro. Using deepspeed and megatron...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[50]
Eric Zhu. Datasketch - MinhashLSH. https://ekzhu.com/datasketch/lsh.html. Accessed: 2025-07-17
work page 2025
-
[51]
Jure Leskovec, Anand Rajaraman, and Jeffrey D. Ullman. Mining of Massive Datasets . Cambridge University Press, 3rd edition, 2020
work page 2020
-
[52]
Amro Abbas, Kushal Tirumala, Dániel Simig, Surya Ganguli, and Ari S. Morcos. Semdedup: Data-efficient learning at web-scale through semantic deduplication. arXiv preprint arXiv:2303.09540 , 2023. URL https: //arxiv.org/abs/2303.09540
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. In Pro- ceedings of the 2019 Conference on Empirical Methods in Natural Language Processing , pages 3982–3992. Association for Computational Linguistics, 2019. doi: 10.18653/v1/D19-1410. URL https://aclanthology. org/D19-1410
-
[54]
intfloat. e5-large-v2. https://huggingface.co/intfloat/e5-large-v2 . Accessed: 2025-07-07
work page 2025
-
[55]
Baai general embedding (bge) base english v1.5
Beijing Academy of Artificial Intelligence (BAAI). Baai general embedding (bge) base english v1.5. https: //huggingface.co/BAAI/bge-base-en-v1.5 . Accessed: 2025-07-07
work page 2025
-
[56]
Sentence Transformers. all-mpnet-base-v2. https://huggingface.co/sentence-transformers/ all-mpnet-base-v2 . Accessed: 2025-07-07
work page 2025
-
[57]
Zheng Zhang, Chen Zheng, Da Tang, Ke Sun, Y ukun Ma, Yingtong Bu, Xun Zhou, and Liang Zhao. Balancing specialized and general skills in llms: The impact of modern tuning and data strategy, 2023. URL https: //arxiv.org/abs/2310.04945. 17
-
[58]
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
Y un Luo, Zhen Y ang, Fandong Meng, Y afu Li, Jie Zhou, and Y ue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning, 2025. URL https://doi.org/10.48550/ arXiv.2308.08747
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019. URL https://arxiv.org/abs/1909.08053
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[60]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Korthikanti, Reza Aminabadi, Bryan Catanzaro, and Matei Zaharia. Efficient large-scale language model training on gpu clusters using megatron-lm. arXiv preprint arXiv:2104.04473 , 2021. URL https://arxiv.org/abs/2104. 04473
-
[61]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Y onghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685, 2023. URL https://doi.org/10.48550/arXiv.2306.05685
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.05685 2023
-
[62]
Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues
Ge Bai, Jie Liu, Xingyuan Bu, Y ancheng He, Jiaheng Liu, Zhanhui Zhou, et al. Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues. arXiv preprint arXiv:2402.14762, 2024. URL https://doi.org/10.48550/arXiv.2402.14762
-
[63]
API Management documentation , 2025
Microsoft Learn. API Management documentation , 2025. https://learn.microsoft.com/en-us/azure/ api-management/. Accessed: 2025-07-07
work page 2025
-
[64]
Azure API Management - Overview and key concepts , 2025
Microsoft Learn. Azure API Management - Overview and key concepts , 2025. https://learn.microsoft. com/azure/api-management/api-management-key-concepts . Accessed: 2025-07-07. 18 A Data Preprocessing A.1 Deduplication Jaccard Similarity The Jaccard Similarity between two sets S and T is defined as: J(S, T ) = jS \ T j jS [ T j This metric quantifies the deg...
work page 2025
-
[65]
To increase the total output from the combined unit
-
[66]
To make use of waste heat available at one stage for improving the performance of another component
-
[67]
To utilize the by-products generated during operation of any particular device. For example: A diesel engine is used alongwith an alternator which converts mechanical work into electrical energy. The exhaust gases are utilized in a steam generator where they provide thermal energy required for raising steam. This steam drives a turbo-alternator set that g...
-
[68]
What Is Thermoelectricity?
-
[69]
How Does A Thermocouple Work?
-
[70]
Types Of Thermocouples
-
[71]
Applications For Thermocouples
-
[72]
Advancements In Materials Used To Improve Efficiency And Scalability:
-
[73]
Limitations On Scaling Up Usage Due To Material Properties Or Other Factors Such As Cost Etc
-
[74]
Conclusion Query: How are nanostructured catalysts improving the efficiency of energy conversion processes like fuel cells and electrolyzers, and what are the challenges in their large-scale synthesis and stability? EnergyGPT Response: Nanostructured materials have been shown to improve catalytic activity for a variety of reactions. In particular, they can...
work page 2022
-
[75]
Provision the APIM Instance Deploy an APIM instance in Azure and configure HTTPS to secure all inbound traffic
-
[76]
This avoids hardcoding secrets directly in policies
Store Secure Named Values Save sensitive information, such as the AML endpoint URL and primary access keys, as secure named values in APIM. This avoids hardcoding secrets directly in policies
-
[77]
Register the EnergyGPT API Import the AML-managed online endpoint into APIM as an HTTP-based API, assign a descriptive display name, and configure a unique URL suffix
-
[78]
Define API Operations Expose relevant inference operations, such as /v1/completions and /v1/chat for an OpenAI-style infer- ence endpoints
-
[79]
• Authorization: Inject the AML primary key into the backend request header
Configure Security and Access Policies Use APIMs XML-based policy engine to secure and manage re- quests: • Authentication: V alidate subscription keys for all requests; block anonymous access. • Authorization: Inject the AML primary key into the backend request header. • Request Normalization: Enforce Content-Type: application/json . • HTTPS Enforcement: ...
-
[80]
Create the EnergyGPT Product Group the API into a dedicated product, e.g., EnergyGPT Access for lifecycle and permission management
-
[81]
Project owners can: • Retrieve and regenerate API keys
Enable Developer Self-Service Activate the APIM Developer Portal to streamline onboarding and testing. Project owners can: • Retrieve and regenerate API keys. • Access EnergyGPT API documentation. • Submit test inference requests interactively
-
[82]
Manage Users and Subscriptions Register users, projects, and organizations in APIM. Subscribe them to the EnergyGPT Access product to allow: • Self-onboarding through the developer portal. • Obtain and manage API keys. • Monitor usage metrics per project
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.