Generative quantum eigensolver with constrained circuit-cutting overhead
Pith reviewed 2026-05-18 18:27 UTC · model grok-4.3
The pith
A generative model for quantum circuits can be trained to keep quantum circuit cutting overhead below a chosen limit while still approximating ground states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training a transformer decoder to generate quantum circuits whose quantum circuit cutting overhead is upper-bounded, the generative quantum eigensolver continues to produce circuits that approximate molecular ground states while enabling execution through circuit cutting on smaller devices.
What carries the argument
Transformer decoder trained with a penalty term on circuit-cutting overhead plus a hybrid online/offline training schedule to generate circuits that satisfy both the energy objective and the overhead bound.
If this is right
- Ground-state searches for molecules become possible on quantum processors whose qubit count is smaller than the circuit size.
- Quantum circuit cutting moves from a theoretical tool to one that can be paired directly with generative circuit design.
- The same overhead-constrained training can be applied to other variational quantum algorithms that produce circuits.
- Convergence speed and final accuracy improve when the new loss and hybrid training are used.
Where Pith is reading between the lines
- The constraint technique could be tested on larger molecules to check whether the overhead bound scales without eliminating all low-energy circuits.
- Similar bounds might be added for other resource costs such as gate count or depth in future generative models.
- Running the method on actual hardware with realistic noise would reveal whether the reduced overhead also reduces error accumulation.
Load-bearing premise
The model can still locate circuits that give good ground-state approximations even after the overhead bound removes some otherwise promising candidates.
What would settle it
Compare the lowest energies reached by the constrained model and the original unconstrained model on BeH2; if the constrained energies are markedly higher while the overhead bound is enforced, the claim that useful circuits remain available would be false.
Figures
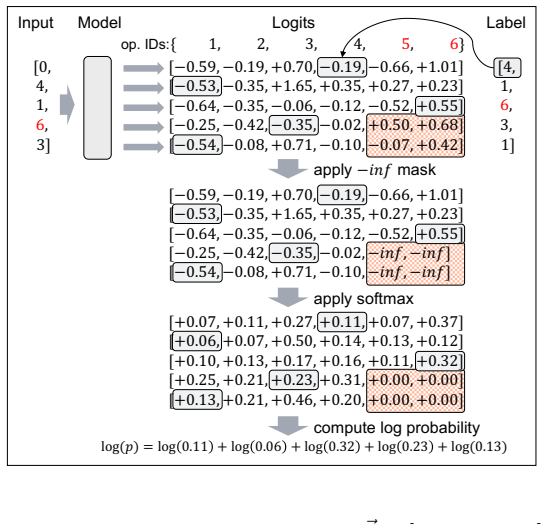







read the original abstract
Generative quantum eigensolver (GQE) is a hybrid quantum-classical algorithm that iteratively trains a classical generative machine learning model such that the model can generate quantum circuits with desired properties such as approximating molecular ground states. It offers as many potential applications and as much flexibility as variational quantum eigensolvers, while avoiding the problem of barren plateaus. Quantum circuit cutting (QCC) is a technique to perform quantum computations that require more qubits than available on single quantum devices. It comes with considerable sampling overhead depending on the structure of the circuit to be cut and how the circuit is cut. To make QCC practical, therefore, the circuits to be cut must be designed such that their execution is meaningful and QCC overhead is kept small. In this work, we extend GQE such that the generative model only produces circuits whose overhead by QCC is upper-bounded, while retaining the original purpose of GQE. Consequently, our proposal not only enhances the applicability of GQE through the use of QCC, but also provides a practical application for QCC. Using a transformer decoder implementation of GQE, we evaluate our method through simulated ground state search experiments on the BeH_2 molecule. A new loss function and a hybrid online/offline training strategy are also introduced and it is observed that these tools improve convergence and final energy values.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends the Generative Quantum Eigensolver (GQE) by constraining a transformer-decoder generative model to produce only circuits whose quantum circuit cutting (QCC) overhead is upper-bounded. It introduces a new loss term and a hybrid online/offline training strategy to enforce this bound while preserving the goal of generating circuits that approximate molecular ground states. The approach is evaluated via simulated ground-state searches on the BeH₂ molecule, with the abstract claiming improved convergence and final energies relative to prior GQE variants.
Significance. If the empirical results hold under quantitative scrutiny, the work would provide a concrete mechanism for making GQE compatible with limited-qubit hardware via QCC while keeping overhead controlled, thereby increasing the practical reach of generative quantum algorithms. The hybrid training strategy and constrained loss could also serve as a template for other generative models in quantum circuit design.
major comments (2)
- [Abstract and §4] Abstract and §4 (BeH₂ experiments): the claim of improved convergence and final energies is stated without quantitative baseline comparisons to unconstrained GQE, without reported error bars or success rates across runs, and without statistics on the fraction of generated circuits rejected by the overhead bound or how the bound is enforced (hard mask versus soft penalty). These omissions leave the central claim that the constraint retains competitive ground-state approximations only partially supported.
- [§3.2] §3.2 (training strategy): the hybrid online/offline procedure and the precise form of the new loss term that incorporates the overhead upper bound are described at a high level, but the manuscript does not specify how the bound is sampled during generation or whether the constraint is applied as a hard filter or a differentiable penalty; this detail is load-bearing for assessing whether the method avoids pruning high-performing regions of circuit space.
minor comments (2)
- [§2] Notation for the overhead bound and the QCC cost function should be introduced with an explicit equation early in §2 to avoid ambiguity when the loss term is defined later.
- [Figures in §4] Figure captions for the BeH₂ energy convergence plots should include the exact overhead bound value used and the number of independent training runs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to strengthen the empirical support and methodological clarity.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (BeH₂ experiments): the claim of improved convergence and final energies is stated without quantitative baseline comparisons to unconstrained GQE, without reported error bars or success rates across runs, and without statistics on the fraction of generated circuits rejected by the overhead bound or how the bound is enforced (hard mask versus soft penalty). These omissions leave the central claim that the constraint retains competitive ground-state approximations only partially supported.
Authors: We agree that the current presentation would benefit from stronger quantitative support. In the revised manuscript we will add direct numerical comparisons to the unconstrained GQE baseline (including energy values and convergence curves), report standard deviations and success rates over multiple independent runs, and include statistics on the fraction of generated circuits that satisfy the overhead bound. We will also clarify that the bound is enforced primarily through a differentiable soft penalty in the loss (with a tunable coefficient) supplemented by a hard rejection step only in the final selection phase of the hybrid strategy; this combination preserves gradient flow to high-performing circuits while respecting the overhead limit. revision: yes
-
Referee: [§3.2] §3.2 (training strategy): the hybrid online/offline procedure and the precise form of the new loss term that incorporates the overhead upper bound are described at a high level, but the manuscript does not specify how the bound is sampled during generation or whether the constraint is applied as a hard filter or a differentiable penalty; this detail is load-bearing for assessing whether the method avoids pruning high-performing regions of circuit space.
Authors: We thank the referee for identifying this important clarification. The overhead bound is incorporated as a differentiable soft-penalty term added to the original GQE loss; the penalty is computed on-the-fly for each sampled circuit during the online phase of training. Circuits are generated autoregressively by the transformer decoder, their QCC overhead is evaluated exactly, and the penalty is applied proportionally to the excess overhead. The offline phase then fine-tunes on a curated set of low-overhead circuits. Because the penalty is differentiable, gradients continue to flow toward promising circuit regions even when the bound is temporarily violated. We will expand §3.2 with the explicit loss formula, the sampling procedure, and a short algorithmic outline to make these mechanics fully reproducible. revision: yes
Circularity Check
No significant circularity; new constraint, loss, and training strategy are independently introduced
full rationale
The paper extends the existing GQE framework by defining a new overhead bound on QCC, a custom loss function that penalizes violations of this bound, and a hybrid online/offline training procedure for the transformer decoder. These elements are presented as novel additions rather than re-derivations of prior fitted parameters or self-cited uniqueness results. The central claims rest on empirical observations from simulated BeH2 ground-state searches, which are described as verifiable through the reported experiments and not forced by construction from the inputs. No load-bearing step reduces to a self-definition, renamed known result, or self-citation chain that would make the outcome tautological.
Axiom & Free-Parameter Ledger
free parameters (1)
- overhead upper bound
axioms (1)
- domain assumption Quantum circuit cutting overhead is determined by the number and type of cuts and can be computed from circuit structure
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We extend GQE such that the generative model only produces circuits whose overhead by QCC is upper-bounded... new loss function and a hybrid online/offline training strategy
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
imposing upper constraints on the occurrences of certain gates... suitable for computations that utilize quantum circuit cutting
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The generative quantum eigensolver (GQE) and its application for ground state search
Kouhei Nakaji, Lasse Bjørn Kristensen, Jorge A Campos-Gonzalez-Angulo, Moham- mad Ghazi Vakili, Haozhe Huang, Mohsen Bagherimehrab, Christoph Gorgulla, FuTe Wong, Alex McCaskey, Jin-Sung Kim, et al. The generative quantum eigensolver (gqe) and its application for ground state search. arXiv preprint arXiv:2401.09253 , 2024
-
[2]
Variational quantum algorithms
Marco Cerezo, Andrew Arrasmith, Ryan Babbush, Simon C Benjamin, Suguru Endo, Keisuke Fujii, Jarrod R McClean, Kosuke Mitarai, Xiao Yuan, Lukasz Cincio, et al. Variational quantum algorithms. Nature Reviews Physics, 3(9):625–644, 2021
work page 2021
-
[3]
From transistor to trapped-ion computers for quan- tum chemistry
M-H Yung, Jorge Casanova, Antonio Mezzacapo, Jarrod Mcclean, Lucas Lamata, Alan Aspuru-Guzik, and Enrique Solano. From transistor to trapped-ion computers for quan- tum chemistry. Scientific reports, 4(1):3589, 2014
work page 2014
-
[4]
A variational eigenvalue solver on a photonic quantum processor
Alberto Peruzzo, Jarrod McClean, Peter Shadbolt, Man-Hong Yung, Xiao-Qi Zhou, Peter J Love, Al´ an Aspuru-Guzik, and Jeremy L O’brien. A variational eigenvalue solver on a photonic quantum processor. Nature communications, 5(1):4213, 2014
work page 2014
-
[5]
A Quantum Approximate Optimization Algorithm
Edward Farhi, Jeffrey Goldstone, and Sam Gutmann. A quantum approximate opti- mization algorithm. arXiv preprint arXiv:1411.4028 , 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[6]
Kosuke Mitarai, Makoto Negoro, Masahiro Kitagawa, and Keisuke Fujii. Quantum circuit learning. Physical Review A, 98(3):032309, 2018
work page 2018
-
[7]
Quantum computing in the nisq era and beyond
John Preskill. Quantum computing in the nisq era and beyond. Quantum, 2:79, 2018
work page 2018
-
[8]
Yasunari Suzuki, Suguru Endo, Keisuke Fujii, and Yuuki Tokunaga. Quantum error mitigation as a universal error reduction technique: Applications from the nisq to the fault-tolerant quantum computing eras. PRX Quantum, 3(1):010345, 2022
work page 2022
-
[9]
Barren plateaus in quantum neural network training landscapes
Jarrod R McClean, Sergio Boixo, Vadim N Smelyanskiy, Ryan Babbush, and Hart- mut Neven. Barren plateaus in quantum neural network training landscapes. Nature communications, 9(1):4812, 2018
work page 2018
-
[10]
Noise-induced barren plateaus in variational quantum algorithms
Samson Wang, Enrico Fontana, Marco Cerezo, Kunal Sharma, Akira Sone, Lukasz Cincio, and Patrick J Coles. Noise-induced barren plateaus in variational quantum algorithms. Nature communications, 12(1):6961, 2021. 16
work page 2021
-
[11]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
work page 2017
-
[12]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI, 2019. Accessed: 2024- 11-15
work page 2019
-
[13]
An image is worth 16x16 words: Trans- formers for image recognition at scale, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Trans- formers for image recognition at scale, 2021
work page 2021
-
[14]
Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip Torr, and Vladlen Koltun. Point trans- former, 2021
work page 2021
-
[15]
Quantum circuit generation for amplitude encoding using a transformer decoder
Shunsuke Daimon and Yu-ichiro Matsushita. Quantum circuit generation for amplitude encoding using a transformer decoder. Physical Review Applied, 22(4):L041001, 2024
work page 2024
- [16]
-
[17]
Ilya Tyagin, Marwa H Farag, Kyle Sherbert, Karunya Shirali, Yuri Alexeev, and Ilya Safro. Qaoa-gpt: Efficient generation of adaptive and regular quantum approximate optimization algorithm circuits. arXiv preprint arXiv:2504.16350 , 2025
-
[18]
Optimizing ansatz design in quantum generative adversarial networks using large language models
Kento Ueda and Atsushi Matsuo. Optimizing ansatz design in quantum generative adversarial networks using large language models. arXiv preprint arXiv:2503.12884 , 2025
-
[19]
Linus Jern, Valter Uotila, Cong Yu, and Bo Zhao. Fine-tuning large language models on quantum optimization problems for circuit generation.arXiv preprint arXiv:2504.11109, 2025
-
[20]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model, 2024
work page 2024
-
[21]
Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Murray, and Young Jin Kim. Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation, 2024
work page 2024
-
[22]
Harrow, Maris Ozols, and Xiaodi Wu
Tianyi Peng, Aram W. Harrow, Maris Ozols, and Xiaodi Wu. Simulating large quantum circuits on a small quantum computer. Physical Review Letters, 125(15), oct 2020
work page 2020
-
[23]
Constructing a virtual two-qubit gate by sampling single-qubit operations
Kosuke Mitarai and Keisuke Fujii. Constructing a virtual two-qubit gate by sampling single-qubit operations. New Journal of Physics , 23(2):023021, feb 2021. 17
work page 2021
-
[24]
Simpo: Simple preference optimization with a reference-free reward, 2024
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward, 2024
work page 2024
-
[25]
Reinforcement Learning for Robots Using Neural Networks
Long-Ji Lin. Reinforcement Learning for Robots Using Neural Networks . PhD thesis, School of Computer Science, Carnegie Mellon University, Pittsburg, USA, 1993
work page 1993
-
[26]
Human-level control through deep reinforcement learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. nature, 518(7540):529–533, 2015
work page 2015
-
[27]
Pytorch: An imperative style, high-performance deep learning library, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmai- son, Andreas K¨ opf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-perf...
work page 2019
-
[28]
Build A Large Language Model (From Scratch)
Sebastian Raschka. Build A Large Language Model (From Scratch) . Manning, 2024
work page 2024
-
[29]
Pennylane quantum chemistry datasets
Utkarsh Azad and Stepan Fomichev. Pennylane quantum chemistry datasets. https: //pennylane.ai/datasets/beh2-molecule, 2023
work page 2023
-
[30]
Gian-Luca R Anselmetti, David Wierichs, Christian Gogolin, and Robert M Parrish. Local, expressive, quantum-number-preserving vqe ans¨ atze for fermionic systems.New Journal of Physics , 23(11):113010, November 2021
work page 2021
-
[31]
Sohaib Alam, Guillermo Alonso-Linaje, B
Ville Bergholm, Josh Izaac, Maria Schuld, Christian Gogolin, Shahnawaz Ahmed, Vishnu Ajith, M. Sohaib Alam, Guillermo Alonso-Linaje, B. AkashNarayanan, Ali Asadi, Juan Miguel Arrazola, Utkarsh Azad, Sam Banning, Carsten Blank, Thomas R Bromley, Benjamin A. Cordier, Jack Ceroni, Alain Delgado, Olivia Di Matteo, Amintor Dusko, Tanya Garg, Diego Guala, Antho...
work page 2022
-
[32]
Hybrid quantum programming with PennyLane Lightning on HPC platforms, 2024
Ali Asadi, Amintor Dusko, Chae-Yeun Park, Vincent Michaud-Rioux, Isidor Schoch, Shuli Shu, Trevor Vincent, and Lee James O’Riordan. Hybrid quantum programming with PennyLane Lightning on HPC platforms, 2024
work page 2024
-
[33]
Overhead for simulating a non-local channel with local channels by quasiprobability sampling
Kosuke Mitarai and Keisuke Fujii. Overhead for simulating a non-local channel with local channels by quasiprobability sampling. Quantum, 5:388, 2021. 18
work page 2021
-
[34]
Circuit knitting with classical communication
Christophe Piveteau and David Sutter. Circuit knitting with classical communication. IEEE Transactions on Information Theory , 70(4):2734–2745, April 2024
work page 2024
-
[35]
Scherer, Axel Plinge, and Christopher Mutschler
Christian Ufrecht, Maniraman Periyasamy, Sebastian Rietsch, Daniel D. Scherer, Axel Plinge, and Christopher Mutschler. Cutting multi-control quantum gates with zx cal- culus. Quantum, 7:1147, October 2023
work page 2023
-
[36]
Optimal joint cutting of two-qubit rotation gates
Christian Ufrecht, Laura S Herzog, Daniel D Scherer, Maniraman Periyasamy, Sebastian Rietsch, Axel Plinge, and Christopher Mutschler. Optimal joint cutting of two-qubit rotation gates. Physical Review A, 109(5):052440, 2024
work page 2024
-
[37]
Aram W. Harrow and Angus Lowe. Optimal quantum circuit cuts with application to clustered hamiltonian simulation. PRX Quantum, 6(1), January 2025
work page 2025
-
[38]
Cutting circuits with multiple two-qubit unitaries
Lukas Schmitt, Christophe Piveteau, and David Sutter. Cutting circuits with multiple two-qubit unitaries. Quantum, 9:1634, 2025
work page 2025
-
[39]
Improved sampling bounds and scalable partitioning for quantum circuit cutting beyond bipartitions
Junya Nakamura, Takahiko Satoh, and Shinichiro Sanji. Improved sampling bounds and scalable partitioning for quantum circuit cutting beyond bipartitions. Phys. Rev. A, 112(4):042422, 2025
work page 2025
-
[40]
Prioritized experience replay, 2016
Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay, 2016. 19
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.