Prototype-Guided Robust Learning against Backdoor Attacks
Pith reviewed 2026-05-18 19:28 UTC · model grok-4.3
The pith
Prototype-Guided Robust Learning defends neural networks from backdoor attacks using only a small set of verified benign samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
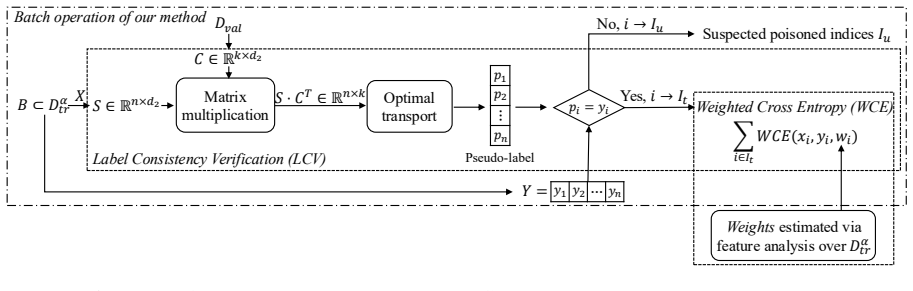
By anchoring fine-tuning to prototypes drawn from a small verified benign set, Label Consistency Verification removes poisoned samples while Feature Distance Estimation drives unlearning of trigger-related features, yielding models that resist backdoor attacks even when the defender lacks knowledge of the poisoning strategy or ratio.
What carries the argument
Prototype-Guided Robust Learning, which uses verified benign samples as reference points to guide detection of poisoned data and removal of backdoor representations during fine-tuning.
If this is right
- Backdoor defense becomes feasible in settings where only limited clean data can be obtained or verified.
- The same prototype mechanism applies across different model architectures and data domains without retraining from scratch.
- Defense performance holds even against attacks that vary in trigger design or poisoning fraction.
- Fine-tuning with these two components produces models whose clean accuracy remains high while backdoor success drops sharply.
Where Pith is reading between the lines
- Organizations could maintain a small, periodically refreshed verified sample pool as a standing defense resource rather than relying on full clean datasets.
- The prototype idea might extend to detecting other forms of data poisoning where triggers are less explicit than backdoor patterns.
- If prototypes can be approximated from public clean data sources, the method could reduce the need for private verified samples.
Load-bearing premise
A small collection of verified benign samples must be available and representative enough to serve as reliable prototypes for spotting poisoned inputs and unlearning backdoor effects.
What would settle it
PGRL would be falsified if it shows no robustness gain over baselines when the verified benign set is reduced below the size used in the experiments or when evaluated on attack variants outside those tested.
Figures






read the original abstract
Backdoor attacks poison the training data, causing the model to behave normally on clean inputs but predict attacker-chosen labels when trigger patterns are embedded into the input samples. Defending against such attacks is highly challenging, especially when the defender has limited access to clean data. Existing defense methods often rely on restrictive assumptions-such as high poisoning ratios or poisoning strategies-limiting their practicality and generalization. To overcome these limitations, we propose Prototype-Guided Robust Learning (PGRL), a defense that only requires a small set of verified benign samples, and integrates two complementary components during fine-tuning: Label Consistency Verification (LCV), which detects and removes suspicious samples from the potentially poisoned dataset; and Feature Distance Estimation (FDE), which enforces the unlearning of backdoor-related representations. Extensive experiments against eight existing defenses show that PGRL achieves superior robustness across diverse architectures, datasets, and advanced attack scenarios, establishing a new standard for practical and generalizable backdoor defense.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Prototype-Guided Robust Learning (PGRL) as a backdoor defense that requires only a small set of verified benign samples. These samples generate prototypes used in two components during fine-tuning: Label Consistency Verification (LCV) to detect and filter poisoned samples from the training set, and Feature Distance Estimation (FDE) to unlearn backdoor-related feature representations. The central claim is that extensive experiments demonstrate PGRL's superior robustness compared to eight existing defenses across diverse architectures, datasets, and advanced attack scenarios, without needing knowledge of the attack strategy or poisoning ratio.
Significance. If the empirical results hold, the work would be significant for practical backdoor defense by relaxing restrictive assumptions common in prior methods (e.g., known high poisoning ratios). The prototype-guided approach with minimal clean data could improve generalizability in real-world settings where verified benign samples are scarce but available. The strength lies in the dual-component design addressing both detection and unlearning, supported by broad experimental comparisons.
major comments (3)
- [§3.2] §3.2 (Prototype Computation): The claim that a small verified benign set yields reliable prototypes for both LCV and FDE is load-bearing for the practicality and superiority assertions, yet the manuscript provides no sensitivity analysis or ablation on the minimum number or representativeness of these samples (e.g., varying from 50 to 500 samples); if the set is unrepresentative, both false-negative rates in LCV and gradient signals in FDE would degrade, undermining robustness gains across unknown attacks.
- [§4.1] §4.1 and Table 3 (Experimental Setup): The superiority over eight defenses is reported without explicit confirmation that baseline methods received equivalent hyperparameter tuning or the same fine-tuning protocol as PGRL; this is critical because any advantage in optimization could inflate the reported gains on advanced attacks like those in the BadNet and Blend families.
- [§4.4] §4.4 (Ablation Studies): No results are shown for the case where the verified benign set size is reduced below the reported value or drawn from a shifted distribution; such an ablation is necessary to substantiate the central claim that PGRL remains effective with zero knowledge of poisoning ratio or trigger type.
minor comments (2)
- [§3.3] The notation distinguishing prototype vectors from feature embeddings in the FDE loss could be clarified with an explicit example computation.
- [Figure 2] Figure 2 caption should explicitly state the poisoning ratio and attack type used for the visualized feature distributions.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help strengthen the presentation of PGRL. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3.2] The claim that a small verified benign set yields reliable prototypes for both LCV and FDE is load-bearing, yet the manuscript provides no sensitivity analysis or ablation on the minimum number or representativeness of these samples (e.g., varying from 50 to 500 samples).
Authors: We agree that sensitivity to the size and representativeness of the verified benign set is important for the practicality claim. In the current experiments we fixed the set at 100 samples per class, selected uniformly at random from the clean validation split. To directly address the concern we will add a new ablation subsection (Section 4.5) that varies the clean-set size from 10 to 200 samples and also tests non-uniform sampling (e.g., class-imbalanced or domain-shifted subsets). Results will be reported for the main attack families to quantify any degradation in LCV false-negative rate and FDE unlearning effectiveness. revision: yes
-
Referee: [§4.1] and Table 3: The superiority over eight defenses is reported without explicit confirmation that baseline methods received equivalent hyperparameter tuning or the same fine-tuning protocol as PGRL.
Authors: We used the exact hyperparameter values and training schedules reported in the original papers for each baseline (including optimizer, learning-rate schedule, and number of fine-tuning epochs). PGRL was trained with the same optimizer and epoch budget to keep the comparison fair. We will insert a new paragraph in Section 4.1 that explicitly lists the hyperparameter sources for every baseline and states that the fine-tuning protocol (batch size, optimizer, epochs) is identical across all methods. revision: yes
-
Referee: [§4.4] No results are shown for the case where the verified benign set size is reduced below the reported value or drawn from a shifted distribution.
Authors: We acknowledge that the current ablation section does not include these edge cases. As noted in our response to the first comment, we will expand Section 4.4 (now becoming 4.5) with experiments that (i) reduce the clean set to 10–50 samples and (ii) draw the clean samples from a distribution shifted relative to the training data (e.g., a different camera or lighting condition). These additions will directly support the claim that PGRL remains effective with minimal clean data and no knowledge of the poisoning ratio or trigger type. revision: yes
Circularity Check
No significant circularity in empirical defense method
full rationale
The paper proposes an empirical defense (PGRL) that integrates LCV and FDE components using a small verified benign set for prototypes, with all central claims validated through experiments against eight external defenses on diverse architectures, datasets, and attacks. No mathematical derivation chain, fitted-parameter predictions, or self-citation load-bearing steps are present that reduce to inputs by construction; the approach is self-contained via experimental benchmarks rather than definitional or self-referential reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A small set of verified benign samples is available and representative of clean data.
Reference graph
Works this paper leans on
-
[1]
Evasion attacks against machine learning at test time
Battista Biggio, Igino Corona, Davide Maiorca, Blaine Nelson, Nedim Šrndić, Pavel Laskov, Giorgio Giacinto, and Fabio Roli. Evasion attacks against machine learning at test time. InECML PKDD 2013, pages 387–402. Springer, 2013
work page 2013
-
[2]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. In Yoshua Bengio and Yann LeCun, editors,ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. 9
work page 2015
-
[3]
LESSON: multi-label adversarial false data injection attack for deep learning locational detection
Jiwei Tian, Chao Shen, Buhong Wang, Xiaofang Xia, Meng Zhang, Chenhao Lin, and Qian Li. LESSON: multi-label adversarial false data injection attack for deep learning locational detection. IEEE Trans. Dependable Secur. Comput., 21(5):4418–4432, 2024
work page 2024
-
[4]
Poisoning attacks against support vector machines
Battista Biggio, Blaine Nelson, and Pavel Laskov. Poisoning attacks against support vector machines. In ICML 2012. icml.cc / Omnipress, 2012
work page 2012
-
[5]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Identifying vulnerabilities in the machine learning model supply chain.CoRR, abs/1708.06733, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Jiwei Tian, Buhong Wang, Zhen Wang, Kunrui Cao, Jing Li, and Mete Ozay. Joint adversarial example and false data injection attacks for state estimation in power systems.IEEE Transactions on Cybernetics, 52(12):13699–13713, 2022. doi: 10.1109/TCYB.2021.3125345
-
[7]
Jingxue Chen, Hang Yan, Zhiyuan Liu, Min Zhang, Hu Xiong, and Shui Yu. When federated learning meets privacy-preserving computation.ACM Computing Surveys, 56(12):1–36, 2024
work page 2024
-
[8]
Backdoor attacks and countermeasures on deep learning: A comprehensive review
Yansong Gao, Bao Gia Doan, Zhi Zhang, Siqi Ma, Jiliang Zhang, Anmin Fu, Surya Nepal, and Hyoungshick Kim. Backdoor attacks and countermeasures on deep learning: A comprehensive review. arXiv preprint arXiv:2007.10760, 2020
-
[9]
Antonio Emanuele Cinà, Kathrin Grosse, Ambra Demontis, Sebastiano Vascon, Werner Zellinger, Bernhard A Moser, Alina Oprea, Battista Biggio, Marcello Pelillo, and Fabio Roli. Wild patterns reloaded: A survey of machine learning security against training data poisoning.ACM Computing Surveys, 55(13s):1–39, 2023
work page 2023
-
[10]
Jiwei Tian, Chao Shen, Buhong Wang, Chao Ren, Xiaofang Xia, Runze Dong, and Tianhao Cheng. Evade: Targeted adversarial false data injection attacks for state estimation in smart grid.IEEE Transactions on Sustainable Computing, 2024. doi: 10.1109/TSUSC.2024.3492290
-
[11]
Wei Guo, Benedetta Tondi, and Mauro Barni. An overview of backdoor attacks against deep neural networks and possible defences.IEEE Open Journal of Signal Processing, 3:261–287, 2022
work page 2022
-
[12]
Bryant Chen, Wilka Carvalho, Nathalie Baracaldo, Heiko Ludwig, Benjamin Edwards, Taesung Lee, Ian M. Molloy, and Biplav Srivastava. Detecting backdoor attacks on deep neural networks by activation clustering. InAAAI 2019, volume 2301, 2019
work page 2019
-
[13]
Zhen Xiang, David J. Miller, and George Kesidis. A benchmark study of backdoor data poisoning defenses for deep neural network classifiers and A novel defense. InMLSP 2019, pages 1–6, 2019
work page 2019
-
[14]
Demon in the variant: Statistical analysis of dnns for robust backdoor contamination detection
Di Tang, XiaoFeng Wang, Haixu Tang, and Kehuan Zhang. Demon in the variant: Statistical analysis of dnns for robust backdoor contamination detection. InUSENIX 2021, pages 1541–1558, 2021
work page 2021
-
[15]
Training with more confidence: Mitigating injected and natural backdoors during training
Zhenting Wang, Hailun Ding, Juan Zhai, and Shiqing Ma. Training with more confidence: Mitigating injected and natural backdoors during training. InNeurIPS 2022, 2022
work page 2022
-
[16]
Wei Guo, Benedetta Tondi, and Mauro Barni. Universal detection of backdoor attacks via density- based clustering and centroids analysis.IEEE TIFS, 2023. doi: 10.1109/TIFS.2023.3329426
-
[17]
The "beatrix" resurrections: Robust backdoor detection via gram matrices
Wanlun Ma, Derui Wang, Ruoxi Sun, Minhui Xue, Sheng Wen, and Yang Xiang. The "beatrix" resurrections: Robust backdoor detection via gram matrices. InNDSS, 2023
work page 2023
-
[18]
Anti-backdoor learning: Training clean models on poisoned data
Yige Li, Xixiang Lyu, Nodens Koren, Lingjuan Lyu, Bo Li, and Xingjun Ma. Anti-backdoor learning: Training clean models on poisoned data. InNeurIPS 2021, pages 14900–14912, 2021
work page 2021
-
[19]
Progressive poisoned data isolation for training-time backdoor defense
Yiming Chen, Haiwei Wu, and Jiantao Zhou. Progressive poisoned data isolation for training-time backdoor defense. In Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan, editors,AAAI 2024, February 20-27, 2024, Vancouver, Canada, pages 11425–11433. AAAI Press, 2024
work page 2024
-
[20]
Backdoor defense via adaptively splitting poisoned dataset
Kuofeng Gao, Yang Bai, Jindong Gu, Yong Yang, and Shu-Tao Xia. Backdoor defense via adaptively splitting poisoned dataset. In CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 4005–4014. IEEE, 2023
work page 2023
-
[21]
Backdoor defense via deconfounded representation learning
Zaixi Zhang, Qi Liu, Zhicai Wang, Zepu Lu, and Qingyong Hu. Backdoor defense via deconfounded representation learning. InCVPR 2023, pages 12228–12238. IEEE, 2023. 10
work page 2023
-
[22]
Backdoor defense via decoupling the training process
Kunzhe Huang, Yiming Li, Baoyuan Wu, Zhan Qin, and Kui Ren. Backdoor defense via decoupling the training process. InICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022
work page 2022
-
[23]
Effective backdoor defense by exploiting sensitivity of poisoned samples
Weixin Chen, Baoyuan Wu, and Haoqian Wang. Effective backdoor defense by exploiting sensitivity of poisoned samples. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022
work page 2022
-
[24]
Towards a proactive{ML} approach for detecting backdoor poison samples
Xiangyu Qi, Tinghao Xie, Jiachen T Wang, Tong Wu, Saeed Mahloujifar, and Prateek Mittal. Towards a proactive{ML} approach for detecting backdoor poison samples. InUSENIX 2023, pages 1685–1702, 2023
work page 2023
-
[25]
The victim and the beneficiary: Exploiting a poisoned model to train a clean model on poisoned data
Zixuan Zhu, Rui Wang, Cong Zou, and Lihua Jing. The victim and the beneficiary: Exploiting a poisoned model to train a clean model on poisoned data. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 155–164. IEEE, 2023
work page 2023
-
[26]
Bypassing backdoor detection algorithms in deep learning
Te Juin Lester Tan and Reza Shokri. Bypassing backdoor detection algorithms in deep learning. In IEEE European Symposium on Security and Privacy, EuroS&P 2020, Genoa, Italy, September 7-11, 2020, pages 175–183. IEEE, 2020
work page 2020
-
[27]
An embarrassingly simple backdoor attack on self-supervised learning
Changjiang Li, Ren Pang, Zhaohan Xi, Tianyu Du, Shouling Ji, Yuan Yao, and Ting Wang. An embarrassingly simple backdoor attack on self-supervised learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4367–4378, 2023
work page 2023
-
[28]
The perils of learning from unlabeled data: Backdoor attacks on semi-supervised learning
Virat Shejwalkar, Lingjuan Lyu, and Amir Houmansadr. The perils of learning from unlabeled data: Backdoor attacks on semi-supervised learning. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 4707–4717. IEEE, 2023
work page 2023
-
[29]
Revisiting the assumption of latent separability for backdoor defenses
Xiangyu Qi, Tinghao Xie, Yiming Li, Saeed Mahloujifar, and Prateek Mittal. Revisiting the assumption of latent separability for backdoor defenses. InICLR 2023. OpenReview.net, 2023
work page 2023
-
[30]
Sinkhorn distances: Lightspeed computation of optimal transport
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. In Christopher J. C. Burges, Léon Bottou, Zoubin Ghahramani, and Kilian Q. Weinberger, editors,NeurIPS 2013, Lake Tahoe, Nevada, United States, pages 2292–2300, 2013
work page 2013
-
[31]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes and John Healy. UMAP: uniform manifold approximation and projection for dimension reduction. CoRR, abs/1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR 2016, pages 770–778, 2016. doi: 10.1109/CVPR.2016.90
-
[33]
Unsupervised learning of visual features by contrasting cluster assignments
Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors,Advances in Neural Information Processing Systems 33: Annual Conference on Neura...
work page 2020
-
[34]
Progressive poisoned data isolation for training-time backdoor defense
Yiming Chen, Haiwei Wu, and Jiantao Zhou. Progressive poisoned data isolation for training-time backdoor defense. AAAI 2024, 2024
work page 2024
-
[35]
Very deep convolutional networks for large-scale image recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In Yoshua Bengio and Yann LeCun, editors,3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015
work page 2015
-
[36]
Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q. Weinberger. Densely connected convolutional networks. In2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pages 2261–2269. IEEE Computer Society, 2017
work page 2017
-
[37]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. 11
work page 2021
-
[38]
Wanet - imperceptible warping-based backdoor attack
Tuan Anh Nguyen and Anh Tuan Tran. Wanet - imperceptible warping-based backdoor attack. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021
work page 2021
-
[39]
Can you hear it? backdoor attacks via ultrasonic triggers
Stefanos Koffas, Jing Xu, Mauro Conti, and Stjepan Picek. Can you hear it? backdoor attacks via ultrasonic triggers. In Proceedings of the 2022 ACM workshop on wireless security and machine learning, pages 57–62, 2022
work page 2022
-
[40]
COMBAT: alternated training for effective clean-label backdoor attacks
Tran Huynh, Dang Nguyen, Tung Pham, and Anh Tran. COMBAT: alternated training for effective clean-label backdoor attacks. In Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan, editors, Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Con- ference on Innovative Applications of Artificial Intelligence, IAAI 2024, ...
work page 2024
-
[41]
Lotus: Evasive and resilient backdoor attacks through sub-partitioning
Siyuan Cheng, Guanhong Tao, Yingqi Liu, Guangyu Shen, Shengwei An, Shiwei Feng, Xiangzhe Xu, Kaiyuan Zhang, Shiqing Ma, and Xiangyu Zhang. Lotus: Evasive and resilient backdoor attacks through sub-partitioning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 24798–24809. IEEE, 2024
work page 2024
-
[42]
Narcissus: A practical clean-label backdoor attack with limited information
Yi Zeng, Minzhou Pan, Hoang Anh Just, Lingjuan Lyu, Meikang Qiu, and Ruoxi Jia. Narcissus: A practical clean-label backdoor attack with limited information. In Weizhi Meng, Christian Damsgaard Jensen, Cas Cremers, and Engin Kirda, editors,Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, CCS 2023, Copenhagen, Denmark, ...
work page 2023
-
[43]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey E. Hinton. A simple framework for contrastive learning of visual representations. InICML 2020, 13-18 July 2020, Virtual Event, volume 119 ofProceedings of Machine Learning Research, pages 1597–1607. PMLR, 2020
work page 2020
-
[44]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
Pete Warden. Speech commands: A dataset for limited-vocabulary speech recognition.arXiv preprint arXiv:1804.03209, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[45]
Wei Guo, Benedetta Tondi, and Mauro Barni. A temporal chrominance trigger for clean-label backdoor attack against anti-spoof rebroadcast detection.IEEE TDSC, 20(6):4752–4762, 2023
work page 2023
-
[46]
Weiyu Sun, Xinyu Zhang, Hao Lu, Yingcong Chen, Ting Wang, Jinghui Chen, and Lu Lin. Backdoor contrastive learning via bi-level trigger optimization.arXiv preprint arXiv:2404.07863, 2024. 12 A Pseudocode of PGRL Algorithm 1:Our PGRL Input: Dα tr: poisoned training dataset;Dval: validation dataset;M: randomly initialized model Output: M ⋆: benign trained mo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.