MAE-SAM2: Mask Autoencoder-Enhanced SAM2 for Clinical Retinal Vascular Leakage Segmentation
Pith reviewed 2026-05-18 17:49 UTC · model grok-4.3
The pith
Mask autoencoder pretraining with SAM2 improves segmentation of small dense retinal vascular leakages by 5% over the base model on fluorescein angiography images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
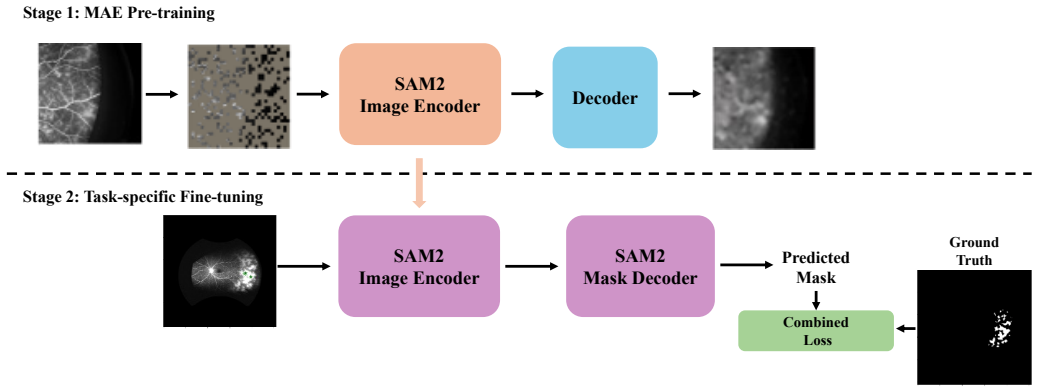
We propose MAE-SAM2, a foundation model that integrates a Masked Autoencoder self-supervised learning strategy with SAM2 for retinal vascular leakage segmentation on fluorescein angiography images. Due to the small size and dense distribution of leakage areas plus limited labeled clinical data, this integration explores different loss functions and settles on a task-specific combined loss. Extensive experiments demonstrate that MAE-SAM2 outperforms several state-of-the-art models, achieving the highest Dice score and IoU with a 5% improvement over the original SAM2.
What carries the argument
The integration of Masked Autoencoder (MAE) self-supervised pretraining with the SAM2 model, optimized via a task-specific combined loss function.
If this is right
- The model delivers higher accuracy specifically on small and densely packed leakage regions that are hard to annotate.
- Self-supervised pretraining reduces reliance on large amounts of labeled clinical data for this segmentation task.
- A task-specific combined loss outperforms standard loss choices in this setting.
- The same MAE-SAM2 recipe outperforms multiple existing state-of-the-art segmentation models on the reported metrics.
Where Pith is reading between the lines
- The same pretraining-plus-foundation-model pattern may transfer to other medical imaging domains that also have scarce labeled examples of small, distributed targets.
- Testing alternative masking ratios or pretraining on larger unlabeled retinal image collections could reveal further gains.
- The approach could be combined with other promptable segmentation models beyond SAM2 to check whether the benefit is model-specific.
Load-bearing premise
Self-supervised MAE pretraining on unlabeled data will meaningfully improve SAM2's ability to segment small, densely distributed leakage areas when only limited labeled clinical fluorescein angiography data is available.
What would settle it
A controlled experiment on the same clinical dataset in which MAE-SAM2 fails to exceed the original SAM2's Dice score and IoU on the held-out test set.
Figures





read the original abstract
We propose MAE-SAM2, a novel foundation model for retinal vascular leakage segmentation on fluorescein angiography images. Due to the small size and dense distribution of the leakage areas, along with the limited availability of labeled clinical data, this presents a significant challenge for segmentation tasks. Our approach integrates a Self-Supervised learning (SSL) strategy, Masked Autoencoder (MAE), with SAM2. In our implementation, we explore different loss functions and conclude a task-specific combined loss. Extensive experiments and ablation studies demonstrate that MAE-SAM2 outperforms several state-of-the-art models, achieving the highest Dice score and Intersection-over-Union (IoU). Compared to the original SAM2, our model achieves a $5\%$ performance improvement, highlighting the promise of foundation models with self-supervised pretraining in clinical imaging tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MAE-SAM2, which augments the SAM2 foundation model with Masked Autoencoder (MAE) self-supervised pretraining and a task-specific combined loss for segmenting small, densely distributed retinal vascular leakage regions in fluorescein angiography images. The central claim is that this yields the highest Dice and IoU scores among compared models, including a 5% improvement over the unmodified SAM2, as demonstrated by extensive experiments and ablation studies.
Significance. If the reported gains prove reproducible, the work would illustrate a practical route for adapting large foundation models to low-label medical imaging regimes involving fine-grained, clinically important structures. The combination of MAE pretraining with a domain-adapted loss is a plausible direction, but the absence of quantitative experimental scaffolding currently prevents assessment of whether the approach delivers a reliable advance over existing SAM2 fine-tuning strategies.
major comments (2)
- [§4 (Experiments)] §4 (Experiments) and abstract: the central claim of a 5% Dice/IoU improvement over SAM2 and superiority to other SOTA models rests on empirical comparisons, yet the manuscript provides no dataset sizes, train/validation/test split counts, number of FA images, cross-validation folds, or implementation details for the baselines. This information is load-bearing because variance is typically high in small, dense-lesion medical segmentation tasks.
- [Results] Results section: no standard deviations, error bars across random seeds, or statistical significance tests (e.g., paired t-tests or Wilcoxon) are reported for the Dice/IoU metrics. Without these controls it is impossible to determine whether the observed lift from MAE pretraining plus the combined loss exceeds noise on the target leakage structures.
minor comments (2)
- [Methods] The definition and weighting of the task-specific combined loss would benefit from an explicit equation and hyperparameter values in the Methods section to allow exact reproduction.
- Consider including a qualitative figure panel that highlights segmentation differences on small, isolated leakage spots to complement the quantitative tables.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The points raised regarding experimental details and statistical reporting are important for strengthening the reproducibility and interpretability of our results. We address each major comment below and will incorporate the necessary revisions.
read point-by-point responses
-
Referee: §4 (Experiments) and abstract: the central claim of a 5% Dice/IoU improvement over SAM2 and superiority to other SOTA models rests on empirical comparisons, yet the manuscript provides no dataset sizes, train/validation/test split counts, number of FA images, cross-validation folds, or implementation details for the baselines. This information is load-bearing because variance is typically high in small, dense-lesion medical segmentation tasks.
Authors: We agree that the current manuscript lacks sufficient detail on the dataset and experimental protocol, which limits assessment of the reported gains. In the revised version, we will add a new subsection to §4 that explicitly states the total number of fluorescein angiography images in the dataset, the exact train/validation/test split counts or ratios, the number of cross-validation folds if used, and comprehensive implementation details for all baseline models (including training hyperparameters, optimizer settings, and any domain-specific adaptations). These additions will directly support evaluation of the 5% improvement over SAM2. revision: yes
-
Referee: Results section: no standard deviations, error bars across random seeds, or statistical significance tests (e.g., paired t-tests or Wilcoxon) are reported for the Dice/IoU metrics. Without these controls it is impossible to determine whether the observed lift from MAE pretraining plus the combined loss exceeds noise on the target leakage structures.
Authors: We concur that variability measures and statistical tests are necessary to establish that the performance lift is reliable rather than attributable to random fluctuations. In the revision, we will update the Results section and associated tables/figures to report standard deviations for Dice and IoU scores (computed over multiple random seeds or cross-validation runs), include error bars, and add results from statistical significance tests such as paired t-tests or Wilcoxon signed-rank tests comparing MAE-SAM2 against SAM2 and the other baselines. revision: yes
Circularity Check
No circularity: empirical model comparisons rest on external benchmarks
full rationale
The paper proposes an architectural integration of MAE pretraining with SAM2 plus a combined loss for retinal leakage segmentation. All load-bearing claims are empirical performance numbers (Dice/IoU gains) obtained by training and evaluating on clinical FA data against independent baselines. No derivation, equation, or uniqueness theorem is presented that reduces to the paper's own fitted parameters or prior self-citations. The experimental section supplies ablation studies and comparisons that are falsifiable outside the fitted values, satisfying the criterion for independent content.
Axiom & Free-Parameter Ledger
free parameters (1)
- combined loss weights
axioms (1)
- domain assumption MAE self-supervised pretraining improves downstream performance on limited-label medical segmentation tasks
Reference graph
Works this paper leans on
-
[1]
Harold R. Novotny and David L. Alvis. A method of photographing fluorescence in circulating blood in the human retina.Circulation, 24(1):82–86, 1961. Lippincott Williams & Wilkins
work page 1961
-
[2]
Irmak Karaca, et al. Efficacy and safety of biologics in pediatric non- infectious retinal vasculitis.American Journal of Ophthalmology, 2025. Elsevier
work page 2025
-
[3]
Irmak Karaca, et al. Importance of baseline fluorescein angiography for patients presenting to tertiary uveitis clinic.American Journal of Ophthalmology, 265:296–302, 2024. Elsevier
work page 2024
-
[4]
Irmak Karaca, et al. Six-month outcomes of infliximab and tocilizumab therapy in non-infectious retinal vasculitis.Eye, 37(11):2197–2203,
-
[5]
Nature Publishing Group UK London
-
[6]
Menze, Andras Jakab, Stefan Bauer, Jayashree Kalpathy- Cramer, Keyvan Farahani, Justin Kirby, et al
Bjoern H. Menze, Andras Jakab, Stefan Bauer, Jayashree Kalpathy- Cramer, Keyvan Farahani, Justin Kirby, et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS).IEEE Transactions on Medical Imaging, 34(10):1993–2024, 2015
work page 1993
-
[7]
Josien M. Staal, Michael D. Abr `amoff, Meindert Niemeijer, Max A. Viergever, and Bram van Ginneken. Ridge-based vessel segmentation in color images of the retina.IEEE Transactions on Medical Imaging, 23(4):501–509, 2004. (DRIVE dataset)
work page 2004
-
[8]
Christ, Eugene V orontsov, Gabriel Chlebus, Holger Chen, Qi Dou, et al
Patrick Bilic, Patrick F. Christ, Eugene V orontsov, Gabriel Chlebus, Holger Chen, Qi Dou, et al. The Liver Tumor Segmentation Benchmark (LiTS).arXiv preprint arXiv:1901.04056, 2019
-
[9]
Dhanach Dhirachaikulpanich, Savita Madhusudhan, David Parry, Salma Babiker, Yalin Zheng, and Nicholas A. V . Beare. Retinal vasculitis sever- ity assessment: intra- and inter-observer reliability of a new scheme for grading wide-field fluorescein angiograms in retinal vasculitis.Retina, pages 10–1097, 2022. LWW
work page 2022
-
[10]
U-net: Convo- lutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convo- lutional networks for biomedical image segmentation. InInternational Conference on Medical Image Computing and Computer-Assisted Inter- vention, pages 234–241. Springer, 2015
work page 2015
-
[11]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. InProceedings of the European Conference on Computer Vision (ECCV), pages 801–818, 2018
work page 2018
-
[12]
Unet++: A nested u-net architecture for medical image segmentation
Zongwei Zhou, Md Mahfuzur Rahman Siddiquee, Nima Tajbakhsh, and Jianming Liang. Unet++: A nested u-net architecture for medical image segmentation. InInternational Workshop on Deep Learning in Medical Image Analysis, pages 3–11. Springer, 2018
work page 2018
-
[13]
nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation
Fabian Isensee, Jens Petersen, Andre Klein, David Zimmerer, Paul F. Jaeger, Simon Kohl, Jakob Wasserthal, Gregor Koehler, Tobias Noraji- tra, Sebastian Wirkert, et al. nnu-net: Self-adapting framework for u-net- based medical image segmentation.arXiv preprint arXiv:1809.10486, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Swin-unet: Unet-like pure transformer for medical image segmentation
Hu Cao, Yueyue Wang, Joy Chen, Dongsheng Jiang, Xiaopeng Zhang, Qi Tian, and Manning Wang. Swin-unet: Unet-like pure transformer for medical image segmentation. InEuropean Conference on Computer Vision, pages 205–218. Springer, 2022
work page 2022
-
[15]
Connor Shorten and Taghi M. Khoshgoftaar. A survey on image data augmentation for deep learning.Journal of Big Data, 6(1):60, 2019
work page 2019
-
[16]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
work page 1901
-
[17]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J ´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9650–9660, 2021
work page 2021
-
[18]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4015– 4026, 2023
work page 2023
-
[19]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Al- varez, and Ping Luo. SegFormer: Simple and efficient design for se- mantic segmentation with transformers.Advances in Neural Information Processing Systems, 34:12077–12090, 2021
work page 2021
-
[21]
Hanxue Gu, Haoyu Dong, Jichen Yang, and Maciej A. Mazurowski. How to build the best medical image segmentation algorithm using foundation models: a comprehensive empirical study with segment anything model.arXiv preprint arXiv:2404.09957, 2024
-
[22]
arXiv preprint arXiv:2308.16184 (2023)
Junlong Cheng, Jin Ye, Zhongying Deng, Jianpin Chen, Tianbin Li, Haoyu Wang, Yanzhou Su, Ziyan Huang, Jilong Chen, Lei Jiang, Hui Sun, Junjun He, Shaoting Zhang, Min Zhu, and Yu Qiao. SAM-Med2D. arXiv preprint arXiv:2308.16184, 2023
-
[23]
Ao Cheng, Guoqiang Zhao, Lirong Wang, and Ruobing Zhang. Axon- CallosumEM dataset: Axon semantic segmentation of whole corpus cal- losum cross section from EM images.arXiv preprint arXiv:2307.02464, 2023
-
[24]
Dongik Shin, Beomsuk Kim, and Seungjun Baek. Cemb-sam: Segment anything model with condition embedding for joint learning from heterogeneous datasets. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), pages 275–
-
[25]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll ´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16000–16009, 2022
work page 2022
-
[26]
Carl Doersch, Abhinav Gupta, and Alexei A. Efros. Unsupervised visual representation learning by context prediction. InProceedings of the IEEE International Conference on Computer Vision, pages 1422–1430, 2015
work page 2015
-
[27]
Unsupervised Representation Learning by Predicting Image Rotations
Spyros Gidaris, Praveer Singh, and Nikos Komodakis. Unsupervised representation learning by predicting image rotations.arXiv preprint arXiv:1803.07728, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Unsupervised learning of visual representations by solving jigsaw puzzles
Mehdi Noroozi and Paolo Favaro. Unsupervised learning of visual representations by solving jigsaw puzzles. InEuropean Conference on Computer Vision, pages 69–84. Springer, 2016
work page 2016
-
[29]
Extracting and composing robust features with denoising autoencoders
Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. Extracting and composing robust features with denoising autoencoders. InProceedings of the 25th International Conference on Machine Learning, pages 1096–1103, 2008
work page 2008
-
[30]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational Conference on Machine Learning, pages 1597–1607,
-
[31]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9729–9738, 2020
work page 2020
-
[32]
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. MIT Press, 2016. (Binary Cross-Entropy loss definition, Chapter 6)
work page 2016
-
[33]
V-Net: Fully convolutional neural networks for volumetric medical image segmenta- tion
Felix Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. V-Net: Fully convolutional neural networks for volumetric medical image segmenta- tion. InProceedings of the IEEE International Conference on 3D Vision (3DV), pages 565–571, 2016. (Dice Loss)
work page 2016
-
[34]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll ´ar. Focal loss for dense object detection. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2980–2988, 2017
work page 2017
-
[35]
Tversky loss function for image segmentation using 3D fully convolutional deep networks
Sadegh Salehi, Deniz Erdogmus, and Ali Gholipour. Tversky loss function for image segmentation using 3D fully convolutional deep networks. InProceedings of Machine Learning in Medical Imaging (MLMI), pages 379–387. Springer, 2017
work page 2017
-
[36]
A novel focal Tversky loss function with improved attention U-Net for lesion segmentation
Nabila Abraham and Naimul Mefraz Khan. A novel focal Tversky loss function with improved attention U-Net for lesion segmentation. InProceedings of the IEEE International Symposium on Biomedical Imaging (ISBI), pages 683–687, 2019
work page 2019
-
[37]
MOND and the dynamics of NGC 628
Jingwei Chen, Lequan Yu, Qian Wang, and Pheng-Ann Heng. Com- bining weighted cross entropy loss and Dice loss for medical image segmentation.arXiv preprint arXiv:1802.05140, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.