TV Subgradient-Guided Multi-Source Fusion for Spectral Imaging in Dual-Camera CASSI Systems
Pith reviewed 2026-05-18 16:36 UTC · model grok-4.3
The pith
The TV subgradient-guided multi-source fusion framework solves severely ill-posed reconstruction in DC-CASSI systems by generating spatial priors from physical models and RGB constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
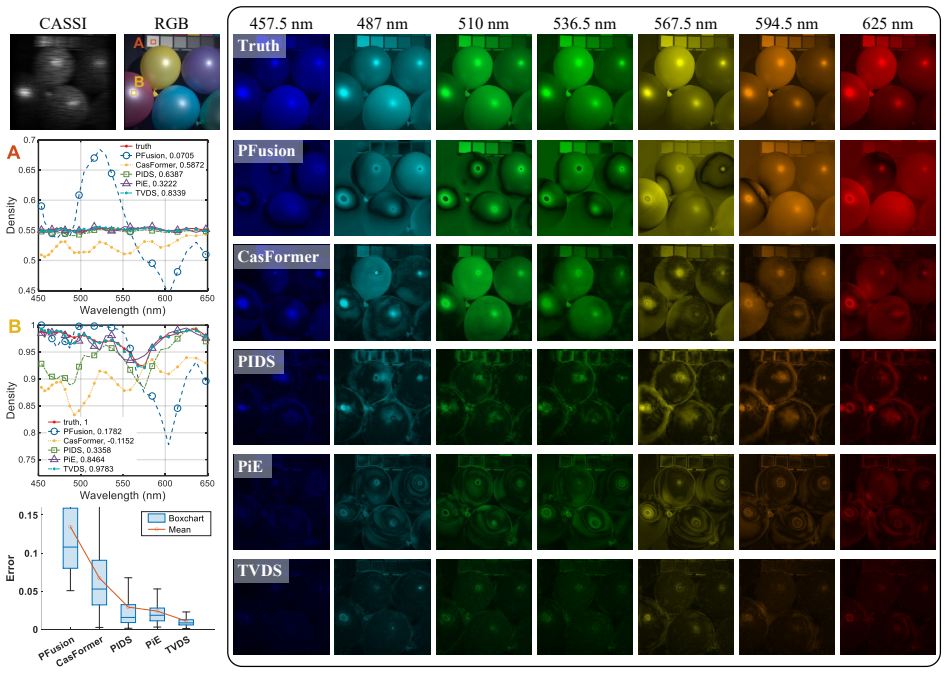
The paper claims that an end-to-end SD-CASSI observation model built with tensor-form Kronecker delta operators, combined with an adaptive spatial reference generator that merges the physical model and RGB subspace constraints, and a TV subgradient-guided regularization term that encodes local structural directions from the reference, enables effective multi-source fusion and yields state-of-the-art reconstruction performance together with robust noise resilience on both simulated and real-world datasets.
What carries the argument
The TV subgradient-guided regularization term, which transfers local structural directions extracted from the adaptive spatial reference image into the spectral reconstruction process.
If this is right
- The framework attains state-of-the-art reconstruction performance on simulated and real-world datasets.
- It exhibits robust resilience to noise in the reconstruction process.
- It supplies an interpretable theoretical foundation for subgradient-guided fusion.
- It offers a practical paradigm for high-fidelity spectral image reconstruction in DC-CASSI systems.
Where Pith is reading between the lines
- The integration of physical models with subspace constraints to create priors could be adapted to other compressive snapshot imaging modalities that face similar ill-posed inverse problems.
- Lower dependence on paired training data suggests the method may support deployment on novel scenes or hardware without retraining.
- The explicit structural-direction encoding might allow hybrid combinations with data-driven components while retaining interpretability.
Load-bearing premise
The adaptive spatial reference generator produces a reliable spatial prior that accurately encodes local structural directions for guiding the spectral reconstruction.
What would settle it
A comparison on new real DC-CASSI captures with added noise where the full framework does not exceed the reconstruction metrics of prior methods would falsify the central performance claim.
Figures







read the original abstract
Balancing spectral, spatial, and temporal resolutions is a key challenge in spectral imaging. The Dual-Camera Coded Aperture Snapshot Spectral Imaging (DC-CASSI) system alleviates this trade-off but suffers from severely ill-posed reconstruction problems due to its high compression ratio. Existing methods are constrained by scene-specific tuning or excessive reliance on paired training data. To address these issues, we propose a Total Variation (TV) subgradient-guided multi-source fusion framework for DC-CASSI reconstruction, comprising three core components: (1) An end-to-end Single-Disperser CASSI (SD-CASSI) observation model based on the tensor-form Kronecker $\delta$, which establishes a rigorous mathematical foundation for physical constraints while enabling efficient adjoint operator implementation; (2) An adaptive spatial reference generator that integrates SD-CASSI's physical model and RGB subspace constraint, generating the reference image as reliable spatial prior; (3) A TV subgradient-guided regularization term that encodes local structural directions from the reference image into spectral reconstruction, achieving high-quality fused results. The framework is validated on simulated datasets and real-world datasets. Experimental results demonstrate that it achieves state-of-the-art reconstruction performance and robust noise resilience. This work not only establishes an interpretable theoretical foundation for subgradient-guided fusion but also provides a practical fusion-based paradigm for high-fidelity spectral image reconstruction in DC-CASSI systems. Source code: https://github.com/bestwishes43/ADMM-TVDS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a TV subgradient-guided multi-source fusion framework for spectral image reconstruction in Dual-Camera Coded Aperture Snapshot Spectral Imaging (DC-CASSI) systems. The framework has three components: (1) an end-to-end Single-Disperser CASSI observation model based on the tensor-form Kronecker δ for physical constraints and efficient adjoint operators; (2) an adaptive spatial reference generator that fuses the SD-CASSI physical model with an RGB subspace constraint to produce a spatial prior; and (3) a TV subgradient-guided regularization term that encodes local structural directions from the reference into the spectral reconstruction. The method is evaluated on simulated and real-world datasets and is reported to achieve state-of-the-art reconstruction performance together with robust noise resilience. Source code is provided.
Significance. If the central claims hold, the work supplies an interpretable, physics-informed alternative to purely data-driven methods for the severely ill-posed DC-CASSI inverse problem, reducing dependence on scene-specific tuning or large paired training sets. The tensor Kronecker formulation and open-source implementation are concrete strengths that support reproducibility and further theoretical development.
major comments (1)
- [Adaptive spatial reference generator] The adaptive spatial reference generator (described after the observation model) is load-bearing for the SOTA and noise-resilience claims because the TV subgradient term directly encodes edge directions from this prior. The manuscript supplies no quantitative validation that the generated reference matches ground-truth spatial structure on real DC-CASSI captures, nor any failure-mode analysis when the RGB subspace assumption is violated by metameric colors or low-contrast regions. Without such checks, it remains unclear whether the prior improves or biases the reconstruction.
minor comments (1)
- [Abstract] The abstract asserts state-of-the-art performance and noise resilience but reports no numerical metrics, error bars, or dataset-specific results; moving at least the key quantitative comparisons into the abstract would strengthen the summary.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comment regarding validation of the adaptive spatial reference generator raises an important point about the strength of our claims. We address it directly below and outline targeted revisions to improve transparency.
read point-by-point responses
-
Referee: [Adaptive spatial reference generator] The adaptive spatial reference generator (described after the observation model) is load-bearing for the SOTA and noise-resilience claims because the TV subgradient term directly encodes edge directions from this prior. The manuscript supplies no quantitative validation that the generated reference matches ground-truth spatial structure on real DC-CASSI captures, nor any failure-mode analysis when the RGB subspace assumption is violated by metameric colors or low-contrast regions. Without such checks, it remains unclear whether the prior improves or biases the reconstruction.
Authors: We agree that direct quantitative validation of the generated reference against ground-truth spatial structure on real DC-CASSI captures is absent from the current manuscript. This is because real-world DC-CASSI acquisitions do not provide paired ground-truth spatial or spectral data, precluding pixel-wise metrics such as PSNR or SSIM for the reference itself. On simulated data, where ground truth is available, the ablation studies and overall reconstruction metrics already demonstrate that the reference generator contributes to improved performance. For real data, validation remains indirect through the final spectral reconstruction quality and noise-resilience experiments. We acknowledge the lack of explicit failure-mode analysis for metameric colors or low-contrast regions as a gap. In the revised manuscript we will add a new subsection under Experiments that (i) discusses the RGB subspace assumption and its potential failure cases with qualitative examples, and (ii) includes additional visualizations of the generated spatial references on real captures to allow readers to assess structural fidelity. These changes will clarify the prior's role without overstating direct evidence. revision: partial
Circularity Check
No circularity; derivation is self-contained with experimental validation
full rationale
The paper proposes a new end-to-end framework with three components: a tensor Kronecker δ observation model for SD-CASSI, an adaptive spatial reference generator combining physical model and RGB subspace constraint, and a TV subgradient-guided regularization term. These are presented as modeling choices and algorithmic innovations, with performance claims supported by validation on simulated and real-world datasets rather than any reduction of outputs to fitted inputs or self-referential definitions. No load-bearing steps equate predictions to inputs by construction, and no self-citations are invoked to justify uniqueness or ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The SD-CASSI observation model based on tensor-form Kronecker δ accurately captures the physical constraints of the imaging system.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TV subgradient-guided regularization term that encodes local structural directions from the reference image into spectral reconstruction
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
f_TV(X) = sum ||(∇X):,m,n,l|| with subgradient ∂f_TV(X) = -div P_X
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
L. Bian, Z. Wang, Y. Zhang, et al., A broadband hyperspectral image sensor with high spatio-temporal resolution, Nature 635 (2024) 73–81
work page 2024
-
[2]
L.Wang, Z.Xiong, D.Gao, etal., Dual-cameradesign for coded aperture snapshot spectral imaging, Ap- plied Optics 54 (2015) 848
work page 2015
-
[3]
L. Wang, Z. Xiong, H. Huang, et al., High-speed hyperspectral video acquisition by combining nyquist and compressive sampling, IEEE Transactions on Pattern Analysis and Machine Intelligence 41 (2019) 857–870
work page 2019
-
[4]
W. He, N. Yokoya, X. Yuan, Fast hyperspectral im- age recovery of dual-camera compressive hyperspec- tral imaging via non-iterative subspace-based fusion, IEEE Transactions on Image Processing 30 (2021) 7170–7183
work page 2021
-
[5]
Y. Chen, Y. Wang, H. Zhang, Prior image guided snapshot compressive spectral imaging, IEEE Trans- actions on Pattern Analysis and Machine Intelligence 45 (2023) 11096–11107
work page 2023
-
[6]
X. Wang, L. Wang, X. Ma, et al., In2SET: Intra- Inter Similarity Exploiting Transformer for Dual- Camera Compressive Hyperspectral Imaging, in: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Seattle, WA, USA, 2024, pp. 24881–24891
work page 2024
-
[8]
Y. Liu, X. Yuan, J. Suo, et al., Rank minimization for snapshot compressive imaging, IEEE Trans. Pattern Anal. Mach. Intell. 41 (2019) 2990 – 3006
work page 2019
-
[9]
A.Wagadarikar, R.John, R.Willett, D.Brady, Single disperser design for coded aperture snapshot spectral imaging, Applied Optics 47 (2008) B44
work page 2008
-
[10]
A. A. Wagadarikar, N. P. Pitsianis, X. Sun, D. J. Brady, Video rate spectral imaging using a coded aperture snapshot spectral imager, Optics Express 17 (2009) 6368
work page 2009
-
[11]
H. Arguello, G. R. Arce, Code aperture optimization for spectrally agile compressive imaging, Journal of the Optical Society of America A 28 (2011) 2400– 2410
work page 2011
-
[12]
H. Arguello, G. R. Arce, Rank Minimization Code Aperture Design for Spectrally Selective Compressive Imaging, IEEE Transactions on Image Processing 22 (2013) 941–954
work page 2013
-
[13]
G. R. Arce, D. J. Brady, L. Carin, et al., Compressive Coded Aperture Spectral Imaging: An Introduction, IEEE Signal Processing Magazine 31 (2014) 105–115
work page 2014
-
[14]
L. Wang, T. Zhang, Y. Fu, H. Huang, HyperRecon- Net: Joint Coded Aperture Optimization and Im- age Reconstruction for Compressive Hyperspectral Imaging, IEEE Transactions on Image Processing 28 (2019) 2257–2270
work page 2019
- [15]
-
[16]
Z. Meng, Z. Yu, K. Xu, X. Yuan, Self-supervised Neural Networks for Spectral Snapshot Compressive Imaging, in: 2021 IEEE/CVF International Confer- ence on Computer Vision (ICCV), IEEE, Montreal, QC, Canada, 2021, pp. 2602–2611
work page 2021
-
[17]
Z. Cai, Z. Liu, J. Yu, et al., Reversible-prior-based spectral-spatialtransformerforefficienthyperspectral image reconstruction, Int. J. Semant. Web Inf. Syst. 20 (2024) 1–22
work page 2024
-
[18]
Z. Meng, J. Ma, X. Yuan, End-to-end low cost com- pressive spectral imaging with spatial-spectral self- attention, in: A. Vedaldi, H. Bischof, T. Brox, J.- M. Frahm (Eds.), Computer Vision – ECCV 2020, Springer International Publishing, Cham, 2020, pp. 187–204
work page 2020
-
[19]
X. Yin, L. Su, X. Chen, et al., Hyperspectral Image Reconstruction of SD-CASSI Based on Nonlocal Low- Rank Tensor Prior, IEEE Transactions on Geoscience and Remote Sensing 62 (2024) 1–15
work page 2024
-
[20]
Z. Meng, X. Yuan, S. Jalali, Deep unfolding for snap- shot compressive imaging, Int. J. Comput. Vision 131 (2023) 2933–2958
work page 2023
-
[21]
C. Cao, J. Li, P. Wang, C. Qi, Compressed spectrum reconstruction method based on coding feature vector enhancement, IEEE Transactions on Geoscience and Remote Sensing 62 (2024) 1–16
work page 2024
- [22]
-
[23]
Y. Dong, D. Gao, T. Qiu, et al., Residual degrada- tion learning unfolding framework with mixing priors across spectral and spatial for compressive spectral imaging, in: 2023 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2023, pp. 22262–22271. 15
work page 2023
-
[24]
L. Wang, Z. Xiong, G. Shi, et al., Compressive hyper- spectral imaging with complementary rgb measure- ments, in: 2016 Visual Communications and Image Processing (VCIP), 2016, pp. 1–4
work page 2016
-
[25]
M. Geng, L. Wang, L. Zhu, et al., Towards Ul- tra High-Speed Hyperspectral Imaging by Integrating Compressive and Neuromorphic Sampling, Interna- tional Journal of Computer Vision (2024)
work page 2024
-
[26]
Y. Chen, Y. Wang, H. Zhang, Prior images guided generative autoencoder model for dual-camera com- pressive spectral imaging, IEEE Transactions on Cir- cuits and Systems for Video Technology 34 (2024) 8629–8643
work page 2024
- [27]
-
[28]
Y. Cai, J. Lin, X. Hu, et al., Mask-guided spectral- wise transformer for efficient hyperspectral image re- construction, in: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 17481–17490
work page 2022
-
[29]
Z. Cai, C. Zhang, Y. Chen, et al., MLP-AMDC: A MLP architecture for adaptive-mask-based dual- camera snapshot hyperspectral imaging, in: I. Ide, I. Kompatsiaris, C. Xu, et al. (Eds.), MultiMe- dia Modeling, Springer Nature Singapore, Singapore, 2025, pp. 408–423
work page 2025
-
[30]
C. Li, B. Zhang, D. Hong, et al., Casformer: Cas- caded transformers for fusion-aware computational hyperspectralimaging, InformationFusion108(2024) 102408
work page 2024
-
[31]
Y. Yang, J. Sun, H. Li, Z. Xu, Admm-csnet: A deep learning approach for image compressive sens- ing, IEEE Transactions on Pattern Analysis and Ma- chine Intelligence 42 (2020) 521–538
work page 2020
-
[32]
X. Lin, Y. Liu, J. Wu, Q. Dai, Spatial-spectral encoded compressive hyperspectral imaging, ACM Trans. Graph. 33 (2014)
work page 2014
- [33]
-
[34]
Y. Xin, Generalized alternating projection based to- tal variation minimization for compressive sensing, in: 2016 IEEE International Conference on Image Pro- cessing (ICIP), 2016, pp. 2539–2543
work page 2016
-
[35]
D.Kittle, K.Choi, A.Wagadarikar, D.J.Brady, Mul- tiframe image estimation for coded aperture snapshot spectral imagers, Applied Optics 49 (2010) 6824
work page 2010
-
[36]
Y. Chen, W. Lai, W. He, et al., Hyperspectral com- pressive snapshot reconstruction via coupled low-rank subspace representation and self-supervised deep net- work, IEEE Transactions on Image Processing 33 (2024) 926–941
work page 2024
-
[37]
L. Wang, Z. Xiong, G. Shi, et al., Adaptive nonlocal sparserepresentationfordual-cameracompressivehy- perspectral imaging, IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (2017) 2104– 2111
work page 2017
- [38]
-
[39]
A. Chambolle, An algorithm for total variation min- imization and applications, Journal of Mathematical Imaging and Vision 20 (2004) 89–97
work page 2004
- [40]
-
[41]
B. Arad, R. Timofte, R. Yahel, et al., Ntire 2022 spectral recovery challenge and data set, in: 2022 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition Workshops (CVPRW), 2022, pp. 862–880
work page 2022
-
[42]
I. Choi, D. S. Jeon, G. Nam, et al., High-quality hyperspectral reconstruction using a spectral prior, ACM Trans. Graph. 36 (2017)
work page 2017
- [43]
- [44]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.