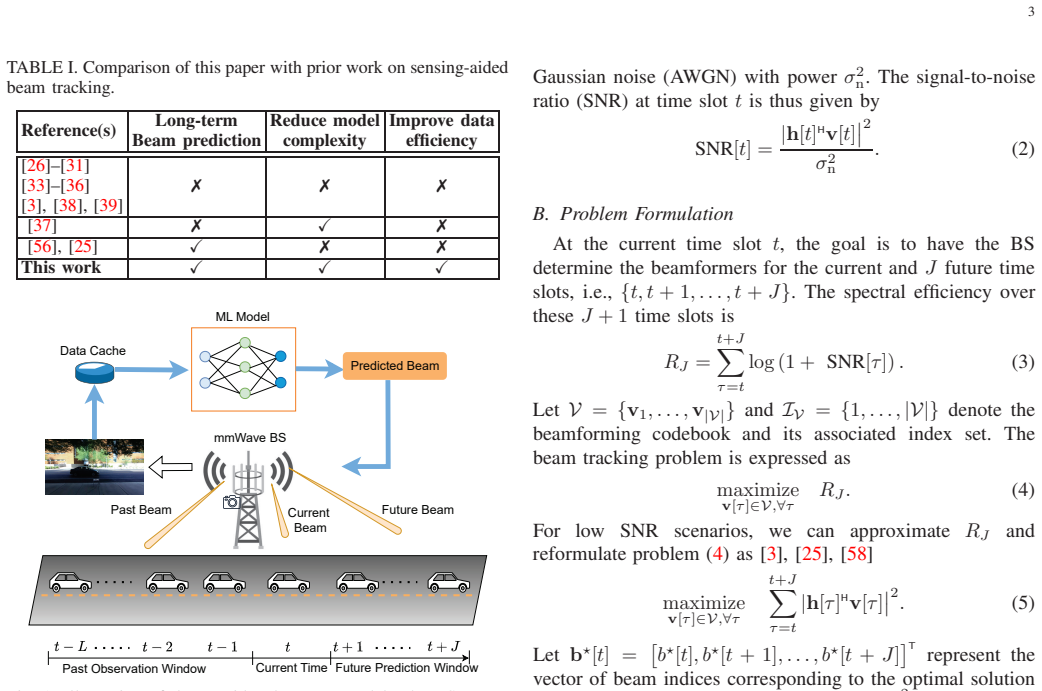
Knowledge Distillation for Sensing-Assisted Long-Term Beam Tracking in mmWave Communications
Pith reviewed 2026-05-21 22:23 UTC · model grok-4.3
The pith
A distilled lightweight student neural network matches a large teacher's accuracy in predicting current and future mmWave beams from visual sensor data while using over 1670 percent fewer parameters and 60 percent shorter sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
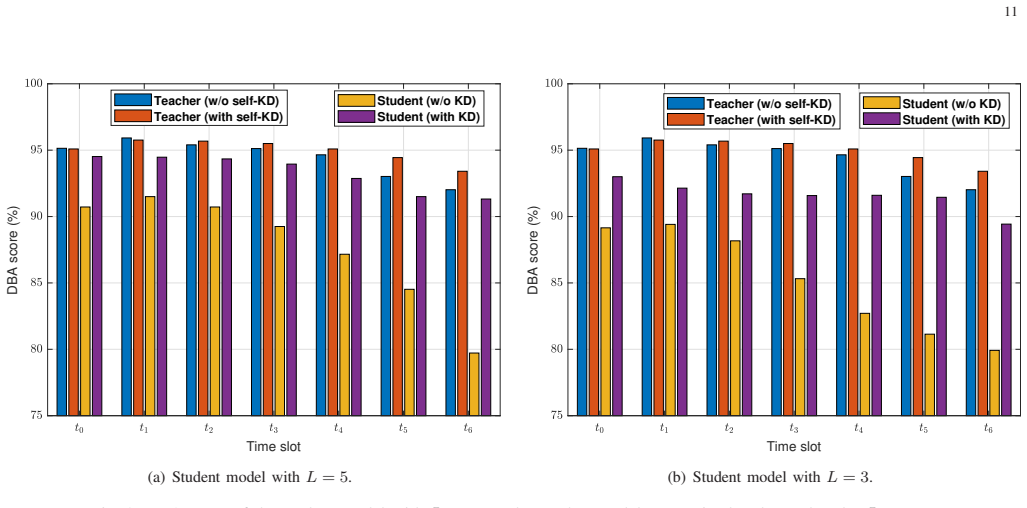
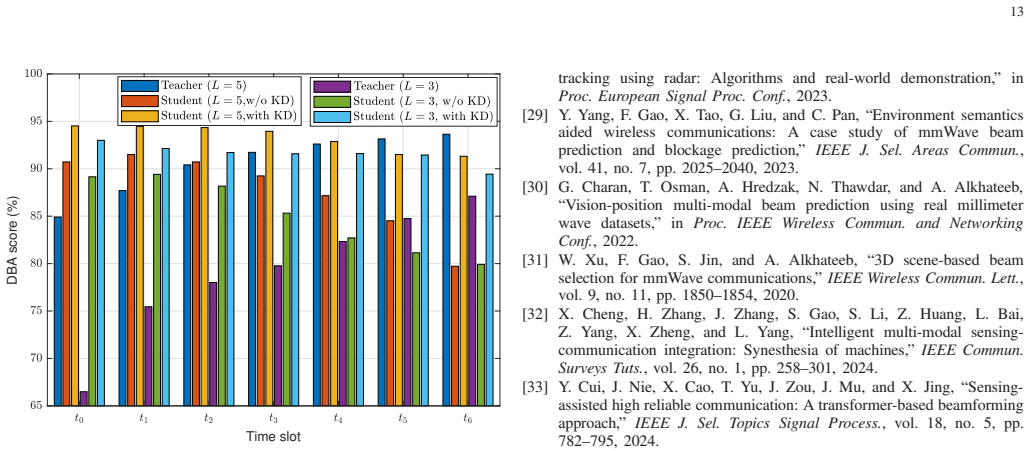
The central claim is that knowledge distillation from a large teacher network—which combines a convolutional neural network for compact image feature extraction with gated recurrent units and attention to model temporal dependencies in visual observation sequences—trains a lightweight student network that closely matches the teacher's top-5 beam prediction accuracies exceeding 93 percent for the current and six future time slots, while reducing model parameters by over 1670 percent, cutting complexity by over 450 percent, and operating on 60 percent shorter input sequences.
What carries the argument
Knowledge distillation in which a large attention-enhanced neural network teacher (convolutional feature extractor plus gated recurrent units with attention) guides training of a compact student network that preserves long-term beam prediction from shorter visual sequences.
If this is right
- The teacher network itself reaches state-of-the-art-level accuracy with a 90 percent reduction in parameters compared to prior models.
- The student retains long-term beam prediction capability despite the large cuts in size and input length.
- The overall framework improves data efficiency while lowering latency and power consumption for both sensing and processing stages.
Where Pith is reading between the lines
- The same distillation approach could be tested with alternative sensors such as radar to improve robustness when visual data is obstructed.
- Shorter input sequences open the door to real-time updates on edge hardware that cannot buffer long histories.
- The parameter savings suggest the method could scale to multi-user or rapidly changing scenarios without proportional increases in compute.
- Hardware measurements on actual mmWave testbeds would be needed to confirm that the complexity reductions translate into measurable power and latency gains.
Load-bearing premise
Visual observations from infrastructure sensors remain sufficiently informative and aligned with actual communication channel states in the tested scenarios and the reported accuracies will hold beyond the specific simulation or dataset.
What would settle it
Deploy the student model on a fresh dataset collected from a different physical environment or with real rather than simulated camera footage and check whether top-5 accuracy for the six future slots drops below 90 percent.
Figures








read the original abstract
Infrastructure-mounted sensors can capture rich environmental information to enhance communications and facilitate beamforming in millimeter-wave systems. This work presents an efficient sensing-assisted long-term beam tracking framework that selects optimal beams from a codebook for current and multiple future time slots. We first design a large attention-enhanced neural network (NN) to fully exploit past visual observations for beam tracking. A convolutional NN extracts compact image features, while gated recurrent units with attention capture the temporal dependencies within sequences. The large NN then acts as the teacher to guide the training of a lightweight student NN via knowledge distillation. The student requires shorter input sequences yet preserves long-term beam prediction ability. Numerical results demonstrate that the teacher achieves Top-5 accuracies exceeding 93% for current and six future time slots, approaching state-of-the-art performance with a 90% reduction of model parameters. The student closely matches the teacher's performance while reducing the number of model parameters by over 1670% and cutting complexity by over 450%, despite operating with 60% shorter input sequences. This improvement significantly enhances data efficiency, reduces latency, and reduces power consumption in sensing and processing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a knowledge-distillation framework for sensing-assisted long-term beam tracking in mmWave systems. A large teacher network combines a CNN for extracting features from infrastructure visual observations with attention-enhanced GRUs to predict optimal beams from a codebook for the current slot and six future slots. The teacher then distills knowledge to a lightweight student network that operates on 60% shorter input sequences while aiming to retain comparable long-term prediction performance. Numerical results report teacher Top-5 accuracies above 93% with 90% parameter reduction relative to prior work, and student performance that closely matches the teacher with over 1670% parameter reduction and over 450% complexity reduction.
Significance. If the empirical claims hold, the work shows that distillation can compress long-range temporal modeling from an attention-based teacher into a compact student, enabling lower-latency and lower-power beam tracking in practical mmWave deployments that use visual sensors. The reported scale of parameter and complexity savings, together with preservation of multi-slot accuracy, would be a concrete contribution to efficient sensing-assisted communications.
major comments (2)
- [Numerical Results / Experiments] The central claim that distillation successfully transfers long-term beam-tracking ability to the student despite 60% shorter sequences is load-bearing for the abstract and results. No ablation is presented that isolates the effect of the distillation loss from the convolutional feature extractor when both models are restricted to the shorter input length; without this comparison it remains unclear whether the student's future-slot accuracy stems from transferred temporal knowledge or from the CNN features alone.
- [System Model and Evaluation Setup] The evaluation assumes that visual observations remain sufficiently aligned with channel evolution across the tested mobility regimes. The manuscript does not report results under higher-mobility scenarios or quantify degradation of visual-channel correlation over the six future slots; such a test would directly address whether the student's compressed representation continues to encode future dynamics when attention mechanisms are removed.
minor comments (2)
- [Proposed Method] The description of the knowledge-distillation loss (temperature, weighting between soft and hard targets) is not fully specified; adding the exact formulation and hyper-parameter values would improve reproducibility.
- [Numerical Results] Figure captions and axis labels for the accuracy-versus-sequence-length plots should explicitly state the number of Monte-Carlo runs and whether error bars represent standard deviation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, proposing revisions where appropriate to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Numerical Results / Experiments] The central claim that distillation successfully transfers long-term beam-tracking ability to the student despite 60% shorter sequences is load-bearing for the abstract and results. No ablation is presented that isolates the effect of the distillation loss from the convolutional feature extractor when both models are restricted to the shorter input length; without this comparison it remains unclear whether the student's future-slot accuracy stems from transferred temporal knowledge or from the CNN features alone.
Authors: We agree that an ablation isolating the distillation loss would clarify whether the student's performance is due to transferred knowledge or the CNN features. We will add this ablation to the revised manuscript by training a baseline student without distillation on the short sequences and comparing its long-term prediction accuracy to the distilled student. This will provide direct evidence for the effectiveness of the knowledge distillation in transferring temporal modeling capabilities. revision: yes
-
Referee: [System Model and Evaluation Setup] The evaluation assumes that visual observations remain sufficiently aligned with channel evolution across the tested mobility regimes. The manuscript does not report results under higher-mobility scenarios or quantify degradation of visual-channel correlation over the six future slots; such a test would directly address whether the student's compressed representation continues to encode future dynamics when attention mechanisms are removed.
Authors: Our evaluation is conducted on the dataset reflecting realistic mobility regimes for the considered mmWave scenarios. We recognize that higher-mobility tests could further validate robustness. Since the current dataset does not encompass extreme mobility cases, we will include in the revision an analysis of the visual-channel correlation over the six future slots using the existing data to quantify degradation. This will help assess the student's ability to encode future dynamics without attention mechanisms. revision: partial
Circularity Check
No circularity: empirical performance claims rest on independent simulation measurements
full rationale
The paper presents a sensing-assisted beam tracking framework using a large attention-enhanced teacher NN (CNN + GRU with attention) distilled to a lightweight student NN that uses 60% shorter sequences. Central claims consist of reported Top-5 accuracies (>93% for teacher, closely matched by student) obtained from numerical experiments on simulated mmWave scenarios. No mathematical derivation chain exists that reduces predictions or uniqueness results to fitted parameters by construction, nor does any load-bearing premise rely on self-citations whose content is unverified. The performance numbers are measured directly against ground-truth beam selections in the test set and remain falsifiable outside the training procedure.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith.Foundation.RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A convolutional NN extracts compact image features, while gated recurrent units with attention capture the temporal dependencies... knowledge distillation... student requires shorter input sequences
-
IndisputableMonolith.Cost.FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Focal loss... KL divergence as the distillation loss... β trade-off parameter
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Knowledge Distillation for Lightweight Multimodal Sensing-Aided mmWave Beam Tracking
Knowledge distillation creates a lightweight student model that reaches over 96% top-5 beam prediction accuracy on real multimodal sensor data while using 27 times fewer parameters than the teacher.
Reference graph
Works this paper leans on
-
[1]
The roa d towards 6G: A comprehensive survey,
W. Jiang, B. Han, M. A. Habibi, and H. D. Schotten, “The roa d towards 6G: A comprehensive survey,” IEEE Open J. Commun. Soc. , vol. 2, pp. 334–366, 2021
work page 2021
-
[2]
Beam training and trac king in mmwave communication: A survey,
W. Yi, W. Zhiqing, and F. Zhiyong, “Beam training and trac king in mmwave communication: A survey,” China Commun. , vol. 21, no. 6, pp. 1–22, 2024
work page 2024
-
[3]
Environment sema ntic communication: Enabling distributed sensing aided networ ks,
S. Imran, G. Charan, and A. Alkhateeb, “Environment sema ntic communication: Enabling distributed sensing aided networ ks,” IEEE Open J. Commun. Soc. , vol. 5, pp. 7767–7786, 2024
work page 2024
-
[4]
Integrated sensin g and communications (ISAC) for vehicular communication networ ks (VCN),
X. Cheng, D. Duan, S. Gao, and L. Y ang, “Integrated sensin g and communications (ISAC) for vehicular communication networ ks (VCN),” IEEE Internet Things J. , vol. 9, no. 23, pp. 23 441–23 451, 2022
work page 2022
-
[5]
N. Shlezinger, M. Ma, O. Lavi, N. T. Nguyen, Y . C. Eldar, an d M. Juntti, “Artificial intelligence-empowered hybrid multiple-inpu t/multiple- output beamforming: Learning to optimize for high-through put scalable MIMO,” IEEE V eh. Technol. Mag., vol. 19, no. 3, pp. 58–67, 2024
work page 2024
-
[6]
Model-based machine learning for Max-Min fairn ess beamforming design in JCAS systems,
M. Ma, T. Fang, N. Shlezinger, A. Swindlehurst, M. Juntti , and N. Nguyen, “Model-based machine learning for Max-Min fairn ess beamforming design in JCAS systems,” in Proc. IEEE Int. Conf. Acoust., Speech, and Signal Process. , 2025
work page 2025
-
[7]
Hierarchical codeb ook design for beamforming training in millimeter-wave communicatio n,
Z. Xiao, T. He, P . Xia, and X.-G. Xia, “Hierarchical codeb ook design for beamforming training in millimeter-wave communicatio n,” IEEE Trans. Wireless Commun. , vol. 15, no. 5, pp. 3380–3392, 2016
work page 2016
-
[8]
Explore and eliminate: Optimized two-stage search for millimeter- wave beam alignment,
M. Li, C. Liu, S. V . Hanly, I. B. Collings, and P . Whiting, “ Explore and eliminate: Optimized two-stage search for millimeter- wave beam alignment,” IEEE Trans. Wireless Commun. , vol. 18, no. 9, pp. 4379–4393, 2019
work page 2019
-
[9]
Hierarchical cod ebook- based multiuser beam training for millimeter wave massive M IMO,
C. Qi, K. Chen, O. A. Dobre, and G. Y . Li, “Hierarchical cod ebook- based multiuser beam training for millimeter wave massive M IMO,” IEEE Trans. Wireless Commun. , vol. 19, no. 12, pp. 8142–8152, 2020
work page 2020
-
[10]
Robust be am- tracking for mmWave mobile communications,
S. Jayaprakasam, X. Ma, J. W. Choi, and S. Kim, “Robust be am- tracking for mmWave mobile communications,” IEEE Commun. Lett. , vol. 21, no. 12, pp. 2654–2657, 2017
work page 2017
-
[11]
Beam tracking under hig hly nonlinear mobile millimeter-wave channel,
J. Lim, H.-M. Park, and D. Hong, “Beam tracking under hig hly nonlinear mobile millimeter-wave channel,” IEEE Commun. Lett. , vol. 23, no. 3, pp. 450–453, 2019
work page 2019
-
[12]
Robust adaptive beam tracking for mobile millimet re wave communications,
C. Liu, M. Li, L. Zhao, P . Whiting, S. V . Hanly, I. B. Colli ngs, and M. Zhao, “Robust adaptive beam tracking for mobile millimet re wave communications,” IEEE Trans. Wireless Commun. , vol. 20, no. 3, pp. 1918–1934, 2020
work page 1918
-
[13]
D. Zhang, A. Li, M. Shirvanimoghaddam, P . Cheng, Y . Li, a nd B. Vucetic, “Codebook-based training beam sequence design for 13 Time slot DBA score (%) Fig. 11. Generalization performance of the teacher model (w ith self-KD). The teacher model is trained for L = 8 and tested for L = 5, 3. In contrast, the student models for comparison are trained and test...
work page 2019
-
[14]
Beam allocation for millimeter-wave MIMO tracking system s,
D. Zhang, A. Li, H. Chen, N. Wei, M. Ding, Y . Li, and B. Vuce tic, “Beam allocation for millimeter-wave MIMO tracking system s,” IEEE Trans. V eh. Technol., vol. 69, no. 2, pp. 1595–1611, 2020
work page 2020
-
[15]
M. Ma, N. T. Nguyen, and M. Juntti, “Closed-form hybrid b eamforming solution for spectral efficiency upper bound maximization i n mmWave MIMO-OFDM systems,” in Proc. IEEE V eh. Technol. Conf. , 2021
work page 2021
-
[16]
Deep learning coordinated beamforming for highly-mobile milli meter wave systems,
A. Alkhateeb, S. Alex, P . V arkey, Y . Li, Q. Qu, and D. Tujk ovic, “Deep learning coordinated beamforming for highly-mobile milli meter wave systems,” IEEE Access , vol. 6, pp. 37 328–37 348, 2018
work page 2018
-
[17]
L.-H. Shen, T.-W. Chang, K.-T. Feng, and P .-T. Huang, “D esign and implementation for deep learning based adjustable beam forming training for millimeter wave communication systems,” IEEE Trans. V eh. Technol., vol. 70, no. 3, pp. 2413–2427, 2021
work page 2021
-
[18]
Model-driven dee p learning assisted beam tracking for millimeter-wave systems,
J. Liu, X. Li, T. Fan, S. Lv, and M. Shi, “Model-driven dee p learning assisted beam tracking for millimeter-wave systems,” IEEE Commun. Lett., vol. 26, no. 10, pp. 2345–2349, 2022
work page 2022
-
[19]
Fast MIMO beamfo rming via deep reinforcement learning for high mobility mmWave conne ctivity,
M. Fozi, A. R. Sharafat, and M. Bennis, “Fast MIMO beamfo rming via deep reinforcement learning for high mobility mmWave conne ctivity,” IEEE J. Sel. Areas Commun. , vol. 40, no. 1, pp. 127–142, 2022
work page 2022
-
[20]
Continuous-time m mWave beam prediction with ODE-LSTM learning architecture,
K. Ma, F. Zhang, W. Tian, and Z. Wang, “Continuous-time m mWave beam prediction with ODE-LSTM learning architecture,” IEEE Wireless Commun. Lett. , vol. 12, no. 1, pp. 187–191, 2023
work page 2023
-
[21]
Deep unfolding hybrid beamfo rming designs for THz massive MIMO systems,
N. T. Nguyen, M. Ma, O. Lavi, N. Shlezinger, Y . C. Eldar, A . L. Swindlehurst, and M. Juntti, “Deep unfolding hybrid beamfo rming designs for THz massive MIMO systems,” IEEE Trans. Signal Process. , vol. 71, pp. 3788–3804, 2023
work page 2023
-
[22]
Multimodal fusio n assisted mmwave beam training in dual-model networks,
J. Liu, X. Li, T. Fan, S. Lv, and M. Shi, “Multimodal fusio n assisted mmwave beam training in dual-model networks,” IEEE Trans. V eh. Technol., vol. 73, no. 1, pp. 995–1011, 2024
work page 2024
-
[23]
J. Mu, Y . Gong, F. Zhang, Y . Cui, F. Zheng, and X. Jing, “In tegrated sensing and communication-enabled predictive beamformin g with deep learning in vehicular networks,” IEEE Commun. Lett. , vol. 25, no. 10, pp. 3301–3304, 2021
work page 2021
-
[24]
C. Liu, W. Y uan, S. Li, X. Liu, H. Li, D. W. K. Ng, and Y . Li, “Learning-based predictive beamforming for integrated se nsing and communication in vehicular networks,” IEEE J. Sel. Areas Commun. , vol. 40, no. 8, pp. 2317–2334, 2022
work page 2022
-
[25]
LiDAR aided futu re beam prediction in real-world millimeter wave V2I communicatio ns,
S. Jiang, G. Charan, and A. Alkhateeb, “LiDAR aided futu re beam prediction in real-world millimeter wave V2I communicatio ns,” IEEE Wireless Commun. Lett. , vol. 12, no. 2, pp. 212–216, 2023
work page 2023
-
[26]
LID AR data for deep learning-based mmWave beam-selection,
A. Klautau, N. Gonz´ alez-Prelcic, and R. W. Heath, “LID AR data for deep learning-based mmWave beam-selection,” IEEE Wireless Commun. Lett. , vol. 8, no. 3, pp. 909–912, 2019
work page 2019
-
[27]
Radar aided 6G beam predi ction: Deep learning algorithms and real-world demonstration,
U. Demirhan and A. Alkhateeb, “Radar aided 6G beam predi ction: Deep learning algorithms and real-world demonstration,” i n Proc. IEEE Wireless Commun. and Networking Conf. , 2022
work page 2022
-
[28]
Millimeter wave V2V beam tracking using radar: Algorithms and real-world demonstra tion,
H. Luo, U. Demirhan, and A. Alkhateeb, “Millimeter wave V2V beam tracking using radar: Algorithms and real-world demonstra tion,” in Proc. European Signal Proc. Conf. , 2023
work page 2023
-
[29]
Y . Y ang, F. Gao, X. Tao, G. Liu, and C. Pan, “Environment s emantics aided wireless communications: A case study of mmWave beam prediction and blockage prediction,” IEEE J. Sel. Areas Commun. , vol. 41, no. 7, pp. 2025–2040, 2023
work page 2025
-
[30]
Vision-position multi-modal beam prediction using real m illimeter wave datasets,
G. Charan, T. Osman, A. Hredzak, N. Thawdar, and A. Alkha teeb, “Vision-position multi-modal beam prediction using real m illimeter wave datasets,” in Proc. IEEE Wireless Commun. and Networking Conf., 2022
work page 2022
-
[31]
3D scene-based b eam selection for mmWave communications,
W. Xu, F. Gao, S. Jin, and A. Alkhateeb, “3D scene-based b eam selection for mmWave communications,” IEEE Wireless Commun. Lett. , vol. 9, no. 11, pp. 1850–1854, 2020
work page 2020
-
[32]
Intelligent multi-modal sen sing- communication integration: Synesthesia of machines,
X. Cheng, H. Zhang, J. Zhang, S. Gao, S. Li, Z. Huang, L. Ba i, Z. Y ang, X. Zheng, and L. Y ang, “Intelligent multi-modal sen sing- communication integration: Synesthesia of machines,” IEEE Commun. Surveys Tuts., vol. 26, no. 1, pp. 258–301, 2024
work page 2024
-
[33]
Se nsing- assisted high reliable communication: A transformer-base d beamforming approach,
Y . Cui, J. Nie, X. Cao, T. Y u, J. Zou, J. Mu, and X. Jing, “Se nsing- assisted high reliable communication: A transformer-base d beamforming approach,” IEEE J. Sel. Topics Signal Process. , vol. 18, no. 5, pp. 782–795, 2024
work page 2024
-
[34]
Deep quantum-transformer networks for multimodal beam pr ediction in ISAC systems,
S. Tariq, B. E. Arfeto, U. Khalid, S. Kim, T. Q. Duong, and H. Shin, “Deep quantum-transformer networks for multimodal beam pr ediction in ISAC systems,” IEEE Internet Things J. , vol. 11, no. 18, pp. 29 387–29 401, 2024
work page 2024
-
[35]
Multimodal transformers for wireless communications: A case study in b eam prediction,
Y . Tian, Q. Zhao, F. Boukhalfa, K. Wu, F. Bader et al. , “Multimodal transformers for wireless communications: A case study in b eam prediction,” arXiv preprint arXiv:2309.11811 , 2023
-
[36]
Multimodal d eep learning empowered millimeter-wave beam prediction,
B. Shi, M. Li, M.-M. Zhao, M. Lei, and L. Li, “Multimodal d eep learning empowered millimeter-wave beam prediction,” in Proc. IEEE V eh. Technol. Conf., 2024
work page 2024
-
[37]
Y . M. Park, Y . K. Tun, W. Saad, and C. S. Hong, “Resource-e fficient beam prediction in mmwave communications with multimodal r ealistic simulation framework,” arXiv preprint arXiv:2504.05187 , 2025
-
[38]
Multimodal deep learning-empowered beam prediction in fu ture THz ISAC systems,
K. Zhang, W. Y u, H. He, S. Song, J. Zhang, and K. B. Letaief , “Multimodal deep learning-empowered beam prediction in fu ture THz ISAC systems,” arXiv preprint arXiv:2505.02381 , 2025
-
[39]
Q. Zhu, Y . Wang, W. Li, H. Huang, and G. Gui, “Advancing mu lti-modal beam prediction with cross-modal feature enhancement and d ynamic fusion mechanism,” IEEE Trans. Commun. , Early access, 2025
work page 2025
-
[40]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the know ledge in a neural network,” arXiv preprint arXiv:1503.02531 , 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[41]
Compacting deep neural networks for Internet of Things: Me thods and applications,
K. Zhang, H. Ying, H.-N. Dai, L. Li, Y . Peng, K. Guo, and H. Y u, “Compacting deep neural networks for Internet of Things: Me thods and applications,” IEEE Internet Things J. , vol. 8, no. 15, pp. 11 935–11 959, 2021
work page 2021
-
[42]
Towards understanding knowl edge distillation,
M. Phuong and C. Lampert, “Towards understanding knowl edge distillation,” in Proc. International Conference on Machine Learning . PMLR, 2019, pp. 5142–5151
work page 2019
-
[43]
Understanding and improving knowledge distillation,
J. Tang, R. Shivanna, Z. Zhao, D. Lin, A. Singh, E. H. Chi, and S. Jain, “Understanding and improving knowledge distillation,” arXiv preprint arXiv:2002.03532, 2020
-
[44]
Self-disti llation amplifies regularization in Hilbert space,
H. Mobahi, M. Farajtabar, and P . Bartlett, “Self-disti llation amplifies regularization in Hilbert space,” Advances in Neural Information Processing Systems, vol. 33, pp. 3351–3361, 2020
work page 2020
-
[45]
C. Buciluˇ a, R. Caruana, and A. Niculescu-Mizil, “Mode l compression,” in Proc. 12th ACM SIGKDD International Conference on Knowledg e Discovery and Data Mining , 2006, pp. 535–541
work page 2006
-
[46]
Do deep nets really need to be deep?
J. Ba and R. Caruana, “Do deep nets really need to be deep? ” Advances in Neural Information Processing Systems , vol. 27, 2014
work page 2014
-
[47]
Model compression via distillation and quantization
A. Polino, R. Pascanu, and D. Alistarh, “Model compress ion via distillation and quantization,” arXiv preprint arXiv:1802.05668 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[48]
K. Kong, W.-J. Song, and M. Min, “Knowledge distillatio n-aided end-to-end learning for linear precoding in multiuser MIMO downlink systems with finite-rate feedback,” IEEE Trans. V eh. Technol., vol. 70, no. 10, pp. 11 095–11 100, 2021
work page 2021
-
[49]
Kno wledge- distillation-aided lightweight neural network for massiv e MIMO CSI feedback,
H. Tang, J. Guo, M. Matthaiou, C.-K. Wen, and S. Jin, “Kno wledge- distillation-aided lightweight neural network for massiv e MIMO CSI feedback,” in Proc. IEEE V eh. Technol. Conf. , 2021
work page 2021
-
[50]
F. O. Catak, M. Kuzlu, E. Catak, U. Cali, and O. Guler, “De fensive distillation-based adversarial attack mitigation method for channel estimation using deep learning models in next-generation w ireless networks,” IEEE Access , vol. 10, pp. 98 191–98 203, 2022
work page 2022
-
[51]
J. Guo, C.-K. Wen, M. Chen, and S. Jin, “Environment know ledge-aided massive MIMO feedback codebook enhancement using artificia l intelli- gence,” IEEE Trans. Commun. , vol. 70, no. 7, pp. 4527–4542, 2022. 14
work page 2022
-
[52]
Knowledge dist illation- based semantic communications for multiple users,
C. Liu, Y . Zhou, Y . Chen, and S.-H. Y ang, “Knowledge dist illation- based semantic communications for multiple users,” IEEE Trans. Wireless Commun., vol. 23, no. 7, pp. 7000–7012, 2023
work page 2023
-
[53]
A. Al-Ahmadi, “Knowledge distillation based deep lear ning model for user equipment positioning in massive MIMO systems usin g flying reconfigurable intelligent surfaces,” IEEE Access , vol. 12, pp. 20 679–20 691, 2024
work page 2024
-
[54]
Y . Zhang, Z. Y an, X. Sun, W. Diao, K. Fu, and L. Wang, “Lear ning efficient and accurate detectors with dynamic knowledge dis tillation in remote sensing imagery,” IEEE Trans. Geosci. Remote Sens. , vol. 60, pp. 1–19, 2021
work page 2021
-
[55]
Cross-m odal knowledge distillation for vision-to-sensor action recog nition,
J. Ni, R. Sarbajna, Y . Liu, A. H. Ngu, and Y . Y an, “Cross-m odal knowledge distillation for vision-to-sensor action recog nition,” in Proc. IEEE Int. Conf. Acoust., Speech, and Signal Process. , 2022
work page 2022
-
[56]
Computer vision aided beam t racking in a real-world millimeter wave deployment,
S. Jiang and A. Alkhateeb, “Computer vision aided beam t racking in a real-world millimeter wave deployment,” in Proc. IEEE Global Commun. Conf. W orkshop, 2022
work page 2022
-
[57]
YOLOv4: Optimal Speed and Accuracy of Object Detection
A. Bochkovskiy, C.-Y . Wang, and H.-Y . M. Liao, “Y olov4: Optimal speed and accuracy of object detection,” arXiv preprint arXiv:2004.10934, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[58]
M. Thomas and A. T. Joy, Elements of Information Theory . Wiley- Interscience, 2006
work page 2006
-
[59]
Fundamentals of recurrent neural net work (RNN) and long short-term memory (LSTM) network,
A. Sherstinsky, “Fundamentals of recurrent neural net work (RNN) and long short-term memory (LSTM) network,” Physica D: Nonlinear Phenomena, vol. 404, p. 132306, 2020
work page 2020
-
[60]
A. V aswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jone s, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you ne ed,” Advances in Neural Information Processing Systems , vol. 30, 2017
work page 2017
-
[61]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L . Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al. , “GPT-4 Technical Report,” arXiv preprint arXiv:2303.08774 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. De ng, C. Zhang, C. Ruan et al. , “Deepseek-v3 Technical Report,” arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
Gate-variants of gated recurren t unit (GRU) neural networks,
R. Dey and F. M. Salem, “Gate-variants of gated recurren t unit (GRU) neural networks,” in Proc. IEEE International Midwest Symp. on Circuits and Systems (MWSCAS) , 2017, pp. 1597–1600
work page 2017
-
[64]
Rethinking the Value of Network Pruning
Z. Liu, M. Sun, T. Zhou, G. Huang, and T. Darrell, “Rethin king the value of network pruning,” arXiv preprint arXiv:1810.05270 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[65]
A compre hensive survey on model quantization for deep neural networks in ima ge classification,
B. Rokh, A. Azarpeyvand, and A. Khanteymoori, “A compre hensive survey on model quantization for deep neural networks in ima ge classification,” ACM Transactions on Intelligent Systems and Technology, vol. 14, no. 6, pp. 1–50, 2023
work page 2023
-
[66]
Does knowledge distillation really work?
S. Stanton, P . Izmailov, P . Kirichenko, A. A. Alemi, and A. G. Wilson, “Does knowledge distillation really work?” Advances in Neural Information Processing Systems , vol. 34, pp. 6906–6919, 2021
work page 2021
-
[67]
Focal loss for dense object detection,
T.-Y . Lin, P . Goyal, R. Girshick, K. He, and P . Doll´ ar, “ Focal loss for dense object detection,” in Proc. IEEE International Conf. on Computer Vision, 2017, pp. 2980–2988
work page 2017
-
[68]
Deepsense 6G: A large-scale real-world multi-modal sensing and communication dataset ,
A. Alkhateeb, G. Charan, T. Osman, A. Hredzak, J. Morais , U. Demirhan, and N. Srinivas, “Deepsense 6G: A large-scale real-world multi-modal sensing and communication dataset ,” IEEE Commun. Mag. , vol. 61, no. 9, pp. 122–128, 2023
work page 2023
-
[69]
Multi-modal beam prediction challenge 2022 : Towards generalization,
G. Charan, U. Demirhan, J. Morais, A. Behboodi, H. Pezes hki, and A. Alkhateeb, “Multi-modal beam prediction challenge 2022 : Towards generalization,” arXiv preprint arXiv:2209.07519 , 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.