CodecSep: Prompt-Driven Universal Sound Separation on Neural Audio Codec Latents
Pith reviewed 2026-05-18 16:40 UTC · model grok-4.3
The pith
CodecSep separates sounds from text prompts directly in neural audio codec latents to match or exceed prior quality at 54 times lower compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
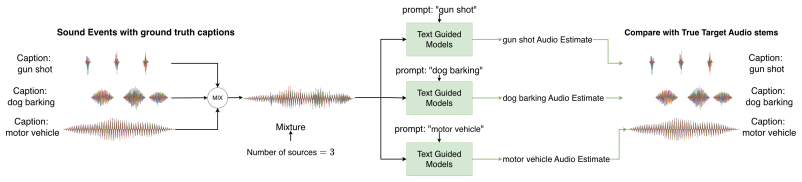
CodecSep extracts sources directly in neural audio codec latent space by combining a frozen DAC backbone with a lightweight FiLM-conditioned Transformer masker driven by CLAP text embeddings. Across dnr-v2 and five open-domain benchmarks it improves SI-SDR over AudioSep, remains competitive in ViSQOL, and shows clear gains in human MOS-LQS scores. Controlled tests confirm that fine-grained prompts outperform coarse labels and that explicit latent masking works better than decoder-style generation. When audio arrives as codec codes, the method maps them to embeddings, separates in latent space, and outputs waveforms or re-quantized codes at 1.35 GMACs end-to-end, roughly 54 times less compute
What carries the argument
Channel-wise source-conditioned modulation performed by a lightweight FiLM-conditioned Transformer masker on neural audio codec latents, guided by CLAP text embeddings.
If this is right
- Explicit latent masking outperforms decoder-style generation inside codec space on separation quality.
- Fine-grained text prompts produce measurably better results than coarse class labels.
- Code-stream deployment avoids the full decode-separate-re-encode loop and delivers 54 times lower end-to-end compute.
- The same codec-native path supports both waveform output and re-quantized code output with low latency and memory.
- The method supplies a practical blueprint for other downstream tasks that can run directly on codec representations.
Where Pith is reading between the lines
- The same latent-masking pattern could be applied to other codec-based tasks such as enhancement or remixing without leaving compressed domain.
- If codec latents already encode source identity, similar conditioning might allow efficient separation when multiple modalities share the same compressed stream.
- Deploying the separator only on the code stream could reduce power draw enough to enable always-on source extraction on battery devices.
- The efficiency numbers suggest the approach could scale to longer recordings or higher channel counts while staying under typical edge compute budgets.
Load-bearing premise
Neural audio codec latents retain enough source-dependent structure that a lightweight channel-wise masker conditioned on text embeddings can perform effective open-vocabulary separation.
What would settle it
Running the same masker on codec latents that have had source-specific information removed or scrambled and observing that separation metrics fall to the level of a non-conditioned baseline would falsify the claim that the latents preserve usable source structure.
Figures



read the original abstract
Text-guided sound separation enables flexible audio editing, assistive listening, and open-domain source extraction, but systems such as AudioSep remain too expensive for low-latency edge or codec-mediated deployment. Existing neural audio codec separators are efficient, yet largely restricted to fixed stems or closed taxonomies. We introduce CodecSep, a prompt-driven universal sound separation framework that extracts sources directly in neural audio codec latent space. CodecSep combines a frozen DAC backbone with a lightweight FiLM-conditioned Transformer masker driven by CLAP text embeddings, enabling open-vocabulary separation while preserving codec-native efficiency. Across dnr-v2 and five open-domain benchmarks, CodecSep consistently improves over AudioSep in SI-SDR, remains competitive in ViSQOL, and achieves clear gains in human MOS-LQS. Controlled analyses show that fine-grained prompts outperform coarse labels, and that explicit latent masking is substantially more effective than decoder-style latent generation in codec space. Qualitative diagnostics show that neural audio codec latents retain source-dependent structure, which CodecSep exploits mainly through channel-wise source-conditioned modulation. CodecSep also provides a practical code-stream deployment path. When audio is transmitted as neural audio codec codes, CodecSep maps codes to embeddings, separates directly in codec space, and outputs waveforms or re-quantized codes, avoiding the decode-separate-re-encode loop. In this regime, CodecSep requires only 1.35 GMACs end-to-end: about 54 times less compute than AudioSep in the same pipeline and 25 times lower separator-only compute, with much lower latency and memory. More broadly, CodecSep offers a blueprint for codec-native downstream audio processing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CodecSep, a prompt-driven universal sound separation framework that operates directly on latents from a frozen DAC neural audio codec. It employs a lightweight FiLM-conditioned Transformer masker driven by CLAP text embeddings to enable open-vocabulary separation. The paper reports consistent SI-SDR gains over AudioSep across dnr-v2 and five open-domain benchmarks, competitive ViSQOL scores, improved human MOS-LQS ratings, and substantial efficiency benefits (1.35 GMACs end-to-end, ~54× lower compute than AudioSep in the same pipeline) along with a code-stream deployment path that avoids decode-separate-re-encode loops.
Significance. If the performance and efficiency claims hold under rigorous validation, CodecSep would provide a practical blueprint for codec-native, low-latency audio processing on edge devices and in transmission pipelines. The approach leverages pre-trained components (DAC, CLAP) to achieve open-vocabulary separation with minimal added capacity, which could impact assistive listening, audio editing, and real-time applications. The explicit comparison of latent masking versus decoder-style generation and the code-stream path are concrete strengths.
major comments (3)
- [§4] §4 (Experimental Evaluation): The headline claims of consistent SI-SDR improvements, competitive ViSQOL, and clear MOS-LQS gains over AudioSep are presented without reported error bars, number of runs, statistical significance tests, or exact baseline implementation details (e.g., whether AudioSep was re-trained or used off-the-shelf weights). These omissions are load-bearing for the central performance and efficiency arguments.
- [§3] §3 (Method) and qualitative diagnostics paragraph: The core assumption that frozen DAC latents retain sufficient source-dependent structure for effective channel-wise source-conditioned modulation by a small Transformer masker is supported primarily by qualitative diagnostics. A quantitative ablation (e.g., source-disentanglement metrics, comparison against unconditioned masking, or analysis of latent statistics per source) is required to substantiate this load-bearing premise for both quality and the 54× compute reduction.
- [§5] Efficiency claims (abstract and §5): The 1.35 GMAC end-to-end figure and 54× / 25× compute reductions versus AudioSep require an explicit per-component breakdown (codec encoding, masker, decoding) and confirmation that comparisons occur under identical conditions, including the same pipeline and hardware. Without this, the practical deployment advantage cannot be fully assessed.
minor comments (2)
- [§3] Clarify the precise architecture of the lightweight Transformer masker (layer count, hidden dimension, attention heads) and the exact FiLM conditioning implementation to support reproducibility.
- [Abstract] The abstract states 'five open-domain benchmarks' without naming them; listing the specific datasets in the main text would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. Their comments identify important areas for strengthening the presentation of results, methodological justification, and efficiency analysis. We address each major comment below and will incorporate revisions where they improve the paper.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Evaluation): The headline claims of consistent SI-SDR improvements, competitive ViSQOL, and clear MOS-LQS gains over AudioSep are presented without reported error bars, number of runs, statistical significance tests, or exact baseline implementation details (e.g., whether AudioSep was re-trained or used off-the-shelf weights). These omissions are load-bearing for the central performance and efficiency arguments.
Authors: We agree that statistical rigor and baseline transparency are essential for the central claims. In the revised manuscript we will report all metrics as means with standard deviations over five independent runs using different random seeds. We will also include paired t-test p-values comparing CodecSep against AudioSep. AudioSep was evaluated using the official pre-trained weights released by its authors without re-training on our data; this detail will be stated explicitly in §4. These additions directly address the load-bearing omissions. revision: yes
-
Referee: [§3] §3 (Method) and qualitative diagnostics paragraph: The core assumption that frozen DAC latents retain sufficient source-dependent structure for effective channel-wise source-conditioned modulation by a small Transformer masker is supported primarily by qualitative diagnostics. A quantitative ablation (e.g., source-disentanglement metrics, comparison against unconditioned masking, or analysis of latent statistics per source) is required to substantiate this load-bearing premise for both quality and the 54× compute reduction.
Authors: The referee is correct that the current support is primarily qualitative. We will add a quantitative ablation in the revision: a direct comparison of the conditioned masker against an unconditioned (no-CLAP) variant, reporting the resulting SI-SDR drop. We will also include per-channel latent variance statistics conditioned on source category. These new results will be placed in §3 to better substantiate the premise that source-dependent structure is retained and exploited by channel-wise modulation. revision: yes
-
Referee: [§5] Efficiency claims (abstract and §5): The 1.35 GMAC end-to-end figure and 54× / 25× compute reductions versus AudioSep require an explicit per-component breakdown (codec encoding, masker, decoding) and confirmation that comparisons occur under identical conditions, including the same pipeline and hardware. Without this, the practical deployment advantage cannot be fully assessed.
Authors: We agree that a component-wise breakdown and explicit confirmation of experimental conditions are necessary. In the revised §5 we will add a table listing GMACs for DAC encoding, the FiLM-Transformer masker, and DAC decoding separately, summing to the reported 1.35 GMACs. All comparisons were performed on identical hardware (NVIDIA A100) with the same end-to-end pipeline, batch size, and audio length; this will be stated clearly in the text. These clarifications will allow readers to fully assess the deployment advantage. revision: yes
Circularity Check
No circularity: empirical gains and efficiency claims follow from external pre-trained models and standard benchmarks
full rationale
The paper presents CodecSep as an engineering framework that applies a lightweight FiLM-conditioned Transformer masker to frozen DAC latents conditioned on CLAP embeddings. All headline metrics (SI-SDR gains, ViSQOL competitiveness, MOS-LQS improvements) and the 54× compute reduction are obtained by direct experimental comparison against AudioSep on dnr-v2 and open-domain test sets. No equations, fitted parameters, or self-citations are invoked to derive the separation performance from quantities internal to the present study; the qualitative observation that codec latents retain source-dependent structure is reported as an empirical diagnostic rather than a definitional premise. The method is therefore self-contained against external benchmarks and pre-trained weights.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural audio codec latents retain source-dependent structure exploitable by channel-wise modulation
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CodecSep combines a frozen DAC backbone with a lightweight FiLM-conditioned Transformer masker driven by CLAP text embeddings, enabling open-vocabulary separation while preserving codec-native efficiency.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Operating on compact codec features cuts memory traffic and MACs compared to spectrogram-domain pipelines
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Learning source disentanglement in neural audio codec
Xiaoyu Bie, Xubo Liu, and Ga \"e l Richard. Learning source disentanglement in neural audio codec. arXiv preprint arXiv:2409.11228, 2024
-
[2]
Audiolm: a language modeling approach to audio generation, 2023
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, and Neil Zeghidour. Audiolm: a language modeling approach to audio generation, 2023. URL https://arxiv.org/abs/2209.03143
-
[3]
Vggsound: A large-scale audio-visual dataset
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. Vggsound: A large-scale audio-visual dataset. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 721--725. IEEE, 2020 a
work page 2020
-
[4]
Jingjing Chen, Qirong Mao, and Dong Liu. Dual-path transformer network: Direct context-aware modeling for end-to-end monaural speech separation. arXiv preprint arXiv:2007.13975, 2020 b
- [5]
-
[6]
FMA: A Dataset For Music Analysis
Michaël Defferrard, Kirell Benzi, Pierre Vandergheynst, and Xavier Bresson. Fma: A dataset for music analysis, 2017. URL https://arxiv.org/abs/1612.01840
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding, 2019. URL https://arxiv.org/abs/1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[9]
Clotho: An audio captioning dataset
Konstantinos Drossos, Samuel Lipping, and Tuomas Virtanen. Clotho: An audio captioning dataset. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 736--740. IEEE, 2020
work page 2020
-
[10]
Lauragpt: Listen, attend, understand, and regenerate audio with gpt, 2024
Zhihao Du, Jiaming Wang, Qian Chen, Yunfei Chu, Zhifu Gao, Zerui Li, Kai Hu, Xiaohuan Zhou, Jin Xu, Ziyang Ma, Wen Wang, Siqi Zheng, Chang Zhou, Zhijie Yan, and Shiliang Zhang. Lauragpt: Listen, attend, understand, and regenerate audio with gpt, 2024. URL https://arxiv.org/abs/2310.04673
-
[11]
Music source separation in the waveform domain, 2021
Alexandre Défossez, Nicolas Usunier, Léon Bottou, and Francis Bach. Music source separation in the waveform domain, 2021. URL https://arxiv.org/abs/1911.13254
-
[12]
High Fidelity Neural Audio Compression
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression, 2022. URL https://arxiv.org/abs/2210.13438
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Fsd50k: An open dataset of human-labeled sound events, 2022
Eduardo Fonseca, Xavier Favory, Jordi Pons, Frederic Font, and Xavier Serra. Fsd50k: An open dataset of human-labeled sound events, 2022. URL https://arxiv.org/abs/2010.00475
-
[14]
Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. Audio set: An ontology and human-labeled dataset for audio events. In Proc. IEEE ICASSP 2017, New Orleans, LA, 2017
work page 2017
-
[15]
Spleeter: a fast and efficient music source separation tool with pre-trained models
Romain Hennequin, Anis Khlif, Felix Voituret, and Manuel Moussallam. Spleeter: a fast and efficient music source separation tool with pre-trained models. Journal of Open Source Software, 5 0 (50): 0 2154, 2020
work page 2020
-
[16]
Perceptually-motivated spatial audio codec for higher-order ambisonics compression, 2024
Christoph Hold, Leo McCormack, Archontis Politis, and Ville Pulkki. Perceptually-motivated spatial audio codec for higher-order ambisonics compression, 2024. URL https://arxiv.org/abs/2401.13401
-
[17]
Yanxin Hu, Yun Liu, Shubo Lv, Mengtao Xing, Shimin Zhang, Yihui Fu, Jian Wu, Bihong Zhang, and Lei Xie. Dccrn: Deep complex convolution recurrent network for phase-aware speech enhancement. arXiv preprint arXiv:2008.00264, 2020
-
[18]
Ilya Kavalerov, Scott Wisdom, Hakan Erdogan, Brian Patton, Kevin Wilson, Jonathan Le Roux, and John R. Hershey. Universal sound separation. In 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), pages 175--179, 2019. doi:10.1109/WASPAA.2019.8937253
-
[19]
Audiocaps: Generating captions for audios in the wild
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. Audiocaps: Generating captions for audios in the wild. In NAACL-HLT, 2019
work page 2019
-
[20]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017. URL https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
High-fidelity audio compression with improved rvqgan
Rithesh Kumar, Prem Seetharaman, Alejandro Luebs, Ishaan Kumar, and Kundan Kumar. High-fidelity audio compression with improved rvqgan. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 27980--27993. Curran Associates, Inc., 2023. URL https://proceedings.neu...
work page 2023
-
[22]
Jonathan Le Roux, Scott Wisdom, Hakan Erdogan, and John R Hershey. Sdr--half-baked or well done? In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 626--630. IEEE, 2019
work page 2019
-
[23]
An efficient encoder-decoder architecture with top-down attention for speech separation, 2023
Kai Li, Runxuan Yang, and Xiaolin Hu. An efficient encoder-decoder architecture with top-down attention for speech separation, 2023. URL https://arxiv.org/abs/2209.15200
-
[24]
Xubo Liu, Qiuqiang Kong, Yan Zhao, Haohe Liu, Yi Yuan, Yuzhuo Liu, Rui Xia, Yuxuan Wang, Mark D. Plumbley, and Wenwu Wang. Separate anything you describe, 2024. URL https://arxiv.org/abs/2308.05037
-
[25]
Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation
Yi Luo and Nima Mesgarani. Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27 0 (8): 0 1256--1266, August 2019. ISSN 2329-9304. doi:10.1109/taslp.2019.2915167. URL http://dx.doi.org/10.1109/TASLP.2019.2915167
-
[26]
A simple dynamic learning rate tuning algorithm for automated training of dnns, 2019
Koyel Mukherjee, Alind Khare, and Ashish Verma. A simple dynamic learning rate tuning algorithm for automated training of dnns, 2019. URL https://arxiv.org/abs/1910.11605
-
[27]
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: An asr corpus based on public domain audio books. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5206--5210, 2015. doi:10.1109/ICASSP.2015.7178964
-
[28]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. Proceedings of the AAAI Conference on Artificial Intelligence, 32 0 (1), Apr. 2018. doi:10.1609/aaai.v32i1.11671. URL https://ojs.aaai.org/index.php/AAAI/article/view/11671
-
[29]
Passtrans: An Improved Password Reuse Model Based on Transformer,
Darius Petermann, Gordon Wichern, Zhong-Qiu Wang, and Jonathan Le Roux. The cocktail fork problem: Three-stem audio separation for real-world soundtracks. In ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 526--530, 2022. doi:10.1109/ICASSP43922.2022.9746005
-
[30]
Karol J. Piczak. ESC : Dataset for Environmental Sound Classification . In Proceedings of the 23rd Annual ACM Conference on Multimedia , pages 1015--1018. ACM Press . ISBN 978-1-4503-3459-4. doi:10.1145/2733373.2806390. URL http://dl.acm.org/citation.cfm?doid=2733373.2806390
-
[31]
Jordi Pons, Xiaoyu Liu, Santiago Pascual, and Joan Serrà. Gass: Generalizing audio source separation with large-scale data. In ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 546--550, 2024. doi:10.1109/ICASSP48485.2024.10446601
-
[32]
Wave-U-Net: A Multi-Scale Neural Network for End-to-End Audio Source Separation
Daniel Stoller, Sebastian Ewert, and Simon Dixon. Wave-u-net: A multi-scale neural network for end-to-end audio source separation. arXiv preprint arXiv:1806.03185, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Attention is all you need in speech separation
Cem Subakan, Mirco Ravanelli, Samuele Cornell, Mirko Bronzi, and Jianyuan Zhong. Attention is all you need in speech separation. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 21--25. IEEE, 2021
work page 2021
-
[34]
Naoya Takahashi, Nabarun Goswami, and Yuki Mitsufuji. Mmdenselstm: An efficient combination of convolutional and recurrent neural networks for audio source separation. In 2018 16th International workshop on acoustic signal enhancement (IWAENC), pages 106--110. IEEE, 2018
work page 2018
-
[35]
Audio source separation and speech enhancement
Emmanuel Vincent, Tuomas Virtanen, and Sharon Gannot. Audio source separation and speech enhancement. John Wiley & Sons, 2018
work page 2018
-
[36]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, Lei He, Sheng Zhao, and Furu Wei. Neural codec language models are zero-shot text to speech synthesizers, 2023. URL https://arxiv.org/abs/2301.02111
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Speechx: Neural codec language model as a versatile speech transformer, 2024
Xiaofei Wang, Manthan Thakker, Zhuo Chen, Naoyuki Kanda, Sefik Emre Eskimez, Sanyuan Chen, Min Tang, Shujie Liu, Jinyu Li, and Takuya Yoshioka. Speechx: Neural codec language model as a versatile speech transformer, 2024. URL https://arxiv.org/abs/2308.06873
-
[38]
Unsupervised sound separation using mixture invariant training
Scott Wisdom, Efthymios Tzinis, Hakan Erdogan, Ron Weiss, Kevin Wilson, and John Hershey. Unsupervised sound separation using mixture invariant training. Advances in neural information processing systems, 33: 0 3846--3857, 2020
work page 2020
-
[39]
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1--5, 2023. doi:10.1109/ICASSP49357.2023.10095969
-
[40]
Spatialcodec: Neural spatial speech coding, 2024
Zhongweiyang Xu, Yong Xu, Vinay Kothapally, Heming Wang, Muqiao Yang, and Dong Yu. Spatialcodec: Neural spatial speech coding, 2024. URL https://arxiv.org/abs/2309.07432
-
[41]
Speech separation using neural audio codecs with embedding loss, 2024 a
Jia Qi Yip, Chin Yuen Kwok, Bin Ma, and Eng Siong Chng. Speech separation using neural audio codecs with embedding loss, 2024 a . URL https://arxiv.org/abs/2411.17998
-
[42]
Towards audio codec-based speech separation, 2024 b
Jia Qi Yip, Shengkui Zhao, Dianwen Ng, Eng Siong Chng, and Bin Ma. Towards audio codec-based speech separation, 2024 b . URL https://arxiv.org/abs/2406.12434
-
[43]
Permutation invariant training of deep models for speaker-independent multi-talker speech separation
Dong Yu, Morten Kolb k, Zheng-Hua Tan, and Jesper Jensen. Permutation invariant training of deep models for speaker-independent multi-talker speech separation. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 241--245. IEEE, 2017
work page 2017
-
[44]
Soundstream: An end-to-end neural audio codec
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. Soundstream: An end-to-end neural audio codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30: 0 495--507, 2022. doi:10.1109/TASLP.2021.3129994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.