Optimal hypersurface decision trees
Pith reviewed 2026-05-18 16:31 UTC · model grok-4.3
The pith
The first exact algorithm solves the optimal hypersurface decision tree problem in O(K! × N^{DG+G}) time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
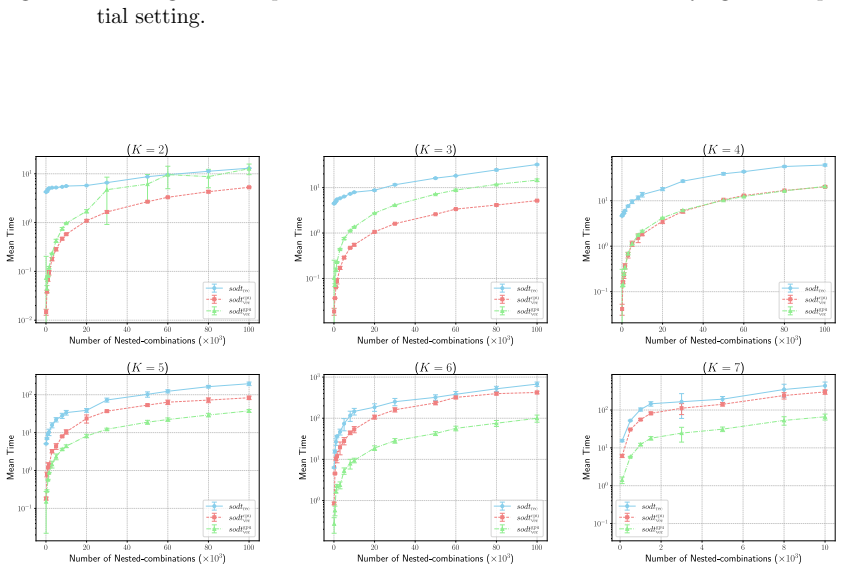
Building on the proper decision tree framework, the authors give the first algorithm that enumerates and evaluates all feasible hypersurface decision trees of size K, achieving time complexity O(K! × N^{DG+G}) where G depends on tree size K, polynomial degree M, and dimension D. The algorithm is designed to support vectorization for parallel execution and includes a pruning strategy together with an incremental procedure that lowers the cost of verifying each candidate split configuration.
What carries the argument
The hypersurface decision tree, in which each internal node partitions the feature space by a polynomial surface of degree M rather than an axis-parallel threshold.
If this is right
- Decision trees can be formed with splits that separate data along curved polynomial boundaries rather than axis-parallel cuts.
- The same algorithmic pattern can be reused to accelerate exact search for other optimal decision tree variants including axis-parallel trees.
- Vectorized evaluation of candidate configurations becomes feasible, supporting parallel hardware implementations.
- Pruning plus linear-time incremental checks make exact search practical for moderate values of K, M, and D.
Where Pith is reading between the lines
- The method could be extended to produce optimal trees under different objective functions such as fairness constraints or robustness to noise.
- Because the design is generic, it may serve as a template for exact search over other families of splitting rules beyond polynomials.
- For applications where interpretability matters, the resulting trees remain small yet more expressive, potentially reducing the accuracy gap between decision trees and black-box models.
Load-bearing premise
That effective pruning and incremental checks will keep the combinatorial enumeration tractable on the datasets of interest even though the worst-case bound remains exponential in tree size.
What would settle it
An implementation on a small synthetic dataset with known optimal hypersurface tree that either fails to recover that tree or exceeds the predicted running time by more than a small constant factor after pruning is applied.
Figures








read the original abstract
The study of optimal decision trees has gained increasing attention in recent years; however, despite substantial progress, it still suffers from two major challenges: First, trees constructed by existing optimal decision tree (ODT) algorithms have limited expressivity, as they are typically restricted to axis-parallel splits or binary features. Second, these algorithms generally do not scale well to large datasets. These two challenges are intertwined: decision trees with more expressive splitting rules incur significantly higher combinatorial complexity, making the ODT problem even more difficult to solve when using complex splits. Building on He and Little's proper decision tree framework, we propose the first algorithm for solving the optimal hypersurface decision tree problem with time complexity $O\left(K!\times N^{DG+G}\right)$, where $G$ is a variable depends on both $K$ (tree size), $M$ (polynomial degree of hypersurface) and $D$ (data dimension). To the best of our knowledge, no known algorithm is capable of producing decision trees with hypersurface splits. Moreover, the proposed algorithm is inherently amenable to vectorization, enabling efficient parallelization. Its generic design pattern also allows it to be used to accelerate other ODT variants, such as axis-parallel decision trees. Furthermore, we identify an effective pruning strategy for the optimal hypersurface decision tree problem, which enables our algorithm to run significantly faster than the worst-case upper bound, together with an incremental procedure that reduces the cost of checking the feasibility of a single configuration from quadratic to linear time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present the first algorithm for computing optimal decision trees with hypersurface splits given by degree-M polynomials. Building on He and Little's proper decision tree framework, the algorithm is stated to run in O(K! × N^{DG+G}) time (with G depending on K, M, and D), to admit effective pruning that improves practical performance over the worst-case bound, and to include an incremental procedure reducing feasibility checks from quadratic to linear time. The design is also claimed to be vectorizable and general enough to accelerate other optimal decision tree variants.
Significance. If the algorithm is correct and the complexity bound is achieved, the result would meaningfully advance optimal decision tree research by increasing split expressivity beyond axis-parallel or binary features while retaining a (worst-case) polynomial dependence on N. The pruning strategy and incremental feasibility check would be useful practical contributions, and the vectorization/generality aspects strengthen the work's applicability.
major comments (2)
- [Abstract and algorithm description] The central claim that the algorithm solves the optimal hypersurface decision tree problem rests on the proper decision tree framework generalizing without optimality gaps when axis-parallel splits are replaced by degree-M hypersurfaces. The abstract states the complexity and the existence of pruning/incremental procedures but does not supply the derivation showing that the enumerated configurations are complete with respect to the true optimum (i.e., that every optimal hypersurface is reachable via the finite enumeration and dynamic-programming structure). This is load-bearing for the optimality guarantee.
- [Complexity and pruning sections] The stated complexity O(K! × N^{DG+G}) implicitly counts feasible hypersurface configurations per node. If the feasibility check only considers a restricted subset (e.g., hypersurfaces defined by subsets of data points) rather than all degree-M polynomials that could be optimal, the algorithm could return a suboptimal tree while still terminating in the claimed time. The incremental linear-time check is mentioned but its completeness relative to the optimum is not verified.
minor comments (2)
- [Abstract] The dependence of G on K, M, and D is described only qualitatively; an explicit formula or recurrence for G would clarify the bound.
- [Background and notation] Notation for the hypersurface parameters and the exact definition of a 'configuration' should be introduced earlier to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive report and for identifying areas where the optimality guarantee and completeness arguments require clearer exposition. We address each major comment below and will revise the manuscript accordingly to strengthen these aspects without altering the core technical claims.
read point-by-point responses
-
Referee: [Abstract and algorithm description] The central claim that the algorithm solves the optimal hypersurface decision tree problem rests on the proper decision tree framework generalizing without optimality gaps when axis-parallel splits are replaced by degree-M hypersurfaces. The abstract states the complexity and the existence of pruning/incremental procedures but does not supply the derivation showing that the enumerated configurations are complete with respect to the true optimum (i.e., that every optimal hypersurface is reachable via the finite enumeration and dynamic-programming structure). This is load-bearing for the optimality guarantee.
Authors: We agree that the abstract is concise and omits the explicit completeness derivation. Section 3 of the manuscript extends He and Little's proper decision tree framework by showing that any optimal degree-M hypersurface separator can be realized by a configuration enumerated from subsets of data points satisfying the polynomial degree constraints; the dynamic-programming recurrence then selects the globally optimal tree without gaps. To address the referee's concern, we will revise the abstract to include a brief clause noting that the enumeration is complete with respect to the optimum under the proper framework generalization. revision: yes
-
Referee: [Complexity and pruning sections] The stated complexity O(K! × N^{DG+G}) implicitly counts feasible hypersurface configurations per node. If the feasibility check only considers a restricted subset (e.g., hypersurfaces defined by subsets of data points) rather than all degree-M polynomials that could be optimal, the algorithm could return a suboptimal tree while still terminating in the claimed time. The incremental linear-time check is mentioned but its completeness relative to the optimum is not verified.
Authors: The algorithm enumerates hypersurface configurations precisely by considering all subsets of points that can define a valid degree-M polynomial separator in D dimensions; this is complete because any optimal hypersurface can be perturbed to pass through a sufficient number of data points without decreasing the objective, consistent with the proper decision tree properties. The incremental feasibility procedure reuses prior matrix computations while preserving the same set of candidate configurations, thereby maintaining completeness. We will add an explicit lemma and short proof in the revised complexity section verifying that the incremental check introduces no optimality gaps. revision: yes
Circularity Check
Minor self-citation to prior framework; central algorithmic claim remains independent
specific steps
-
self citation load bearing
[Abstract]
"Building on He and Little's proper decision tree framework, we propose the first algorithm for solving the optimal hypersurface decision tree problem with time complexity O(K!×N^{DG+G})"
The central claim of the first optimal hypersurface algorithm and its complexity bound is introduced by direct reference to the prior framework whose authors overlap with the present paper. While the paper adds pruning and linear-time checks, the optimality guarantee and configuration counting (via G depending on K, M, D) inherit their validity from the self-cited base without an independent external check shown in the provided text.
full rationale
The paper extends a cited prior framework (He and Little) to hypersurface splits and states a new complexity bound plus pruning strategy. No derivation reduces a claimed result to a fitted parameter or self-defined quantity by construction. The self-citation provides the base structure but the hypersurface enumeration, incremental feasibility check, and vectorization are presented as novel additions without equations that equate the output to the input by definition. This qualifies as a minor self-citation that is not load-bearing for the core result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption He and Little's proper decision tree framework applies to hypersurface splits of polynomial degree M
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery; embed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hodtM K = min E0-1 ◦ concatMap sodt(xs) ◦ nestedCombs(K, G) ◦ embed M … ancestry relation matrix K … crossed hyperplanes … prefix-closed property
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking; SphereAdmitsCircleLinking D ↔ D=3 unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2: if two hyperplanes cross … convex hulls intersect … cannot form a proper decision tree
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Dimitris Bertsimas and Jack Dunn. Optimal classification trees. Machine Learning, 106: 0 1039--1082, 2017
work page 2017
-
[2]
L. Breiman, J. Friedman, C.J. Stone, and R.A. Olshen. Classification and Regression Trees. Taylor & Francis, 1984. ISBN 9780412048418. URL https://books.google.co.uk/books?id=JwQx-WOmSyQC
work page 1984
- [3]
-
[4]
C a t a lin E Brița, Jacobus GM van der Linden, and Emir Demirovi \'c . Optimal classification trees for continuous feature data using dynamic programming with branch-and-bound. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 11131--11139, 2025
work page 2025
-
[5]
Optimal trees for prediction and prescription
Jack William Dunn. Optimal trees for prediction and prescription. PhD thesis, Massachusetts Institute of Technology, 2018
work page 2018
-
[6]
L \'e o Grinsztajn, Edouard Oyallon, and Ga \"e l Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data? Advances in Neural Information Processing Systems, 35: 0 507--520, 2022
work page 2022
- [7]
-
[8]
Xi He, Yi Miao, and Max A. Little. Deep-ice: The first globally optimal algorithm for empirical risk minimization of two-layer maxout and relu networks, 2025. URL https://arxiv.org/abs/2505.05740
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Xiyang Hu, Cynthia Rudin, and Margo Seltzer. Optimal sparse decision trees. Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[10]
Generalized and scalable optimal sparse decision trees
Jimmy Lin, Chudi Zhong, Diane Hu, Cynthia Rudin, and Margo Seltzer. Generalized and scalable optimal sparse decision trees. pages 6150--6160. Proceedings of Machine Learning Research, 2020
work page 2020
-
[11]
Quant-bnb: A scalable branch-and-bound method for optimal decision trees with continuous features
Rahul Mazumder, Xiang Meng, and Haoyue Wang. Quant-bnb: A scalable branch-and-bound method for optimal decision trees with continuous features. In International Conference on Machine Learning, pages 15255--15277. PMLR, 2022
work page 2022
-
[12]
Decision tree induction: How effective is the greedy heuristic? In KDD, pages 222--227, 1995
Sreerama K Murthy and Steven Salzberg. Decision tree induction: How effective is the greedy heuristic? In KDD, pages 222--227, 1995
work page 1995
-
[13]
A system for induction of oblique decision trees
Sreerama K Murthy, Simon Kasif, and Steven Salzberg. A system for induction of oblique decision trees. Journal of Artificial Intelligence Research, 2: 0 1--32, 1994
work page 1994
-
[14]
J Ross Quinlan. C4. 5: programs for machine learning. Elsevier, 2014
work page 2014
-
[15]
Tabular data: Deep learning is not all you need
Ravid Shwartz-Ziv and Amitai Armon. Tabular data: Deep learning is not all you need. Information Fusion, 81: 0 84--90, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.