FEDONet : Fourier-Embedded DeepONet for Spectrally Accurate Operator Learning
Pith reviewed 2026-05-18 15:57 UTC · model grok-4.3
The pith
Embedding random Fourier features into DeepONet trunks improves accuracy on PDE operator learning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
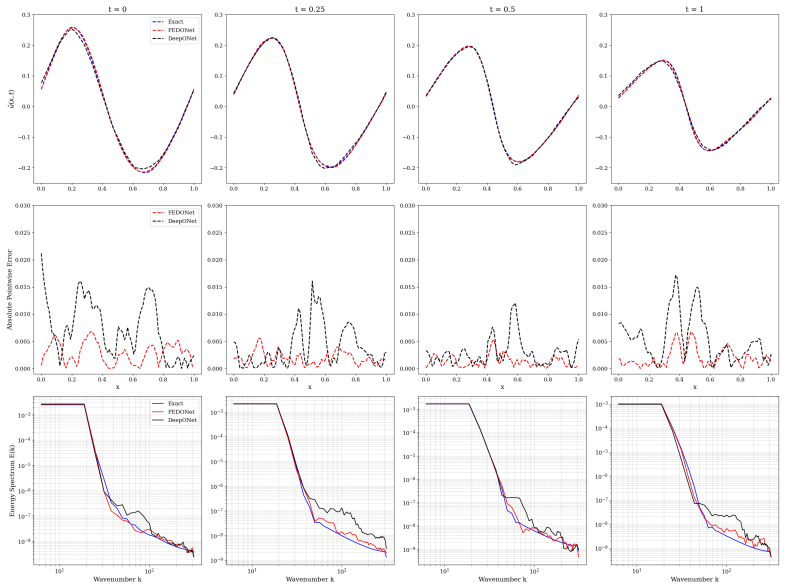
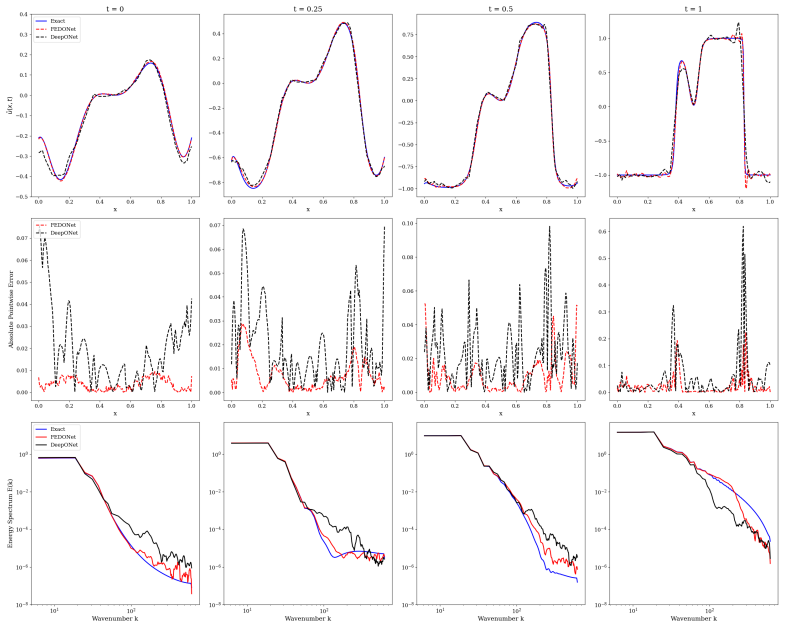
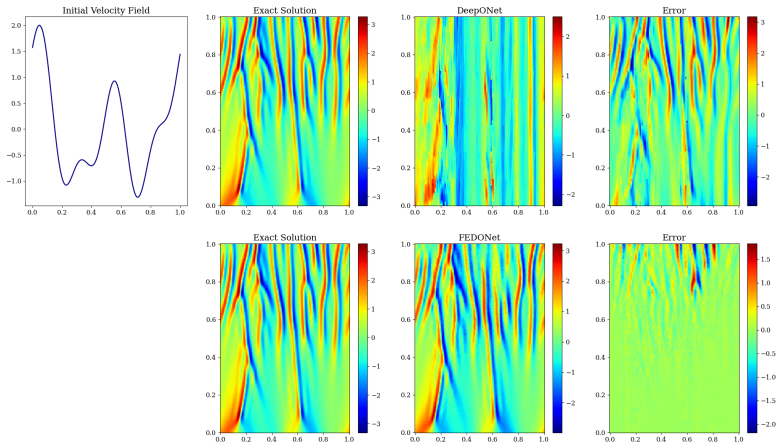
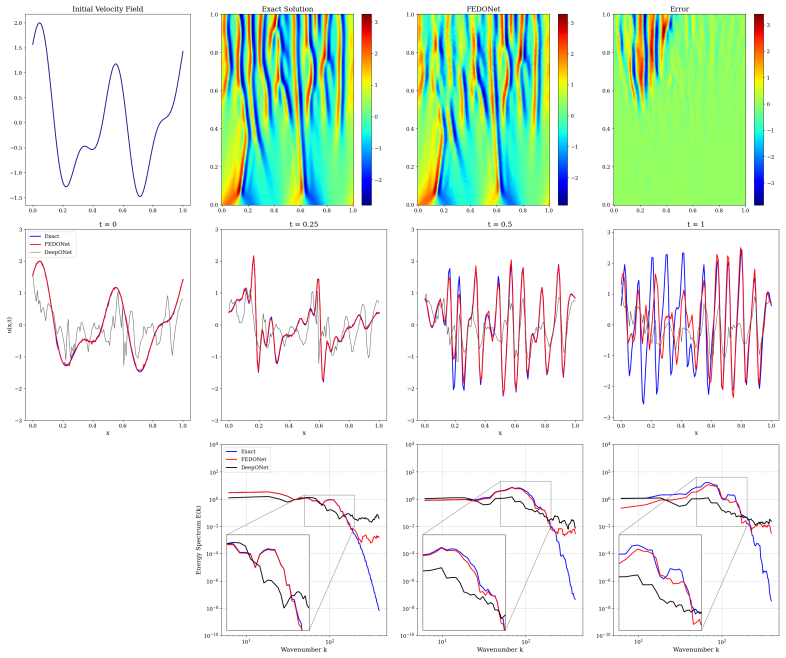
By leveraging random Fourier features to enrich spatial representation capabilities in the trunk network, the Fourier-Embedded DeepONet (FEDONet) demonstrates superior performance compared to the traditional DeepONet across a comprehensive suite of PDE-driven datasets, including Burgers', 2D Poisson, Eikonal, Allen-Cahn, and the Kuramoto-Sivashinsky equation.
What carries the argument
Fourier-Embedded trunk network that incorporates random Fourier features to enrich spatial representations within the DeepONet architecture.
If this is right
- Consistently superior reconstruction accuracy across all tested benchmark PDEs.
- Particularly large relative L2 error reductions in chaotic and stiff systems.
- Performance advantages hold across multiple training dataset sizes and input noise levels.
- Provides a broadly applicable methodology for building PDE surrogate models.
Where Pith is reading between the lines
- The same embedding trick might improve spatial fidelity in other branch-trunk operator architectures.
- Smaller training sets could become viable for some problems if the enriched trunk reduces data hunger.
- The spectral character of the embedding invites direct comparisons with traditional spectral numerical methods on the same tasks.
Load-bearing premise
Embedding random Fourier features into the DeepONet trunk network will reliably enrich spatial representations for a broad range of PDEs without requiring problem-specific hyperparameter tuning or introducing new instabilities.
What would settle it
A direct comparison on additional PDE problems or under different noise conditions in which FEDONet fails to reduce L2 error relative to standard DeepONet would challenge the claim of consistent superiority.
Figures















read the original abstract
Deep Operator Networks (DeepONets) have recently emerged as powerful data-driven frameworks for learning nonlinear operators, particularly suited for approximating solutions to partial differential equations. Despite their promising capabilities, the standard implementation of DeepONets, which typically employs fully connected linear layers in the trunk network, can encounter limitations in capturing complex spatial structures inherent to various PDEs. To address this limitation, we use Fourier-Embedded trunk networks within the DeepONet architecture, leveraging random Fourier features to enrich spatial representation capabilities. The Fourier-Embedded DeepONet (FEDONet) demonstrates superior performance compared to the traditional DeepONet across a comprehensive suite of PDE-driven datasets, including the Burgers', 2D Poisson, Eikonal, Allen-Cahn, and the Kuramoto-Sivashinsky equation. To systematically evaluate the effectiveness of the architectures, we perform comparisons across multiple training dataset sizes and input noise levels. FEDONet delivers consistently superior reconstruction accuracy across all benchmark PDEs, with particularly large relative $L^2$ error reductions observed in chaotic and stiff systems. This work demonstrates the effectiveness of Fourier embeddings in enhancing neural operator learning, offering a robust and broadly applicable methodology for PDE surrogate modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FEDONet, a DeepONet variant that replaces the standard fully-connected trunk with one augmented by random Fourier features to better capture spatial structures when learning nonlinear operators from PDE data. It reports consistent L² accuracy gains over baseline DeepONet on Burgers', 2D Poisson, Eikonal, Allen-Cahn, and Kuramoto-Sivashinsky benchmarks, with larger relative improvements on chaotic and stiff problems, and evaluates robustness across training-set sizes and input-noise levels.
Significance. If the empirical gains prove robust, the work would supply a lightweight, architecture-level improvement that leverages established Fourier embeddings to raise the effective spectral fidelity of operator networks, offering a practical route to more accurate surrogates for a range of PDEs without substantially increasing model complexity.
major comments (2)
- [§3.2] §3.2 (Fourier embedding description): the scale hyperparameter σ of the random Fourier features is not stated to be held fixed across all five PDEs or chosen once for the entire study. Because the optimal σ is known to be PDE-dependent (high-frequency content in KS versus smoother fields in Poisson), this detail is load-bearing for the central claim of broad applicability “without requiring problem-specific hyperparameter tuning.”
- [§4] §4 (Experimental results): no standard deviations, multiple random seeds, or statistical significance tests accompany the reported L² error reductions. Without these, it is impossible to determine whether the observed improvements, especially the large relative gains on chaotic/stiff systems, are reliable or could be explained by initialization variance.
minor comments (2)
- [Title] The title’s phrase “spectrally accurate” is not supported by any explicit spectral-norm or Fourier-coefficient error analysis in the results; either add such quantification or revise the title wording.
- [§2.1] §2.1: the precise concatenation of random Fourier features with the trunk input coordinates is described only at a high level; an explicit equation would remove ambiguity about the embedding dimension and activation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on hyperparameter specification and statistical reporting. These points strengthen the manuscript's clarity and rigor. We address each major comment below and outline the corresponding revisions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Fourier embedding description): the scale hyperparameter σ of the random Fourier features is not stated to be held fixed across all five PDEs or chosen once for the entire study. Because the optimal σ is known to be PDE-dependent (high-frequency content in KS versus smoother fields in Poisson), this detail is load-bearing for the central claim of broad applicability “without requiring problem-specific hyperparameter tuning.”
Authors: We agree that explicit documentation of σ is necessary to substantiate the claim of broad applicability. The original experiments employed a single fixed value of σ across all five PDE benchmarks, selected to provide a practical balance for the range of frequency content encountered without per-problem retuning. We will revise §3.2 to state this choice explicitly, including the specific value and a brief justification, thereby directly addressing the referee's concern. revision: yes
-
Referee: [§4] §4 (Experimental results): no standard deviations, multiple random seeds, or statistical significance tests accompany the reported L² error reductions. Without these, it is impossible to determine whether the observed improvements, especially the large relative gains on chaotic/stiff systems, are reliable or could be explained by initialization variance.
Authors: We concur that reporting variability across runs is essential for assessing the reliability of the observed gains. We will revise §4 to include results aggregated over multiple independent random seeds (reporting means and standard deviations) and will add a short discussion of statistical significance for the key comparisons, particularly on the chaotic and stiff equations. revision: yes
Circularity Check
No circularity: FEDONet is an empirical architectural proposal validated on external benchmarks
full rationale
The paper introduces FEDONet by replacing the trunk network in DeepONet with a Fourier-embedded version using random Fourier features, then reports empirical L2 error reductions versus baseline DeepONet on Burgers', 2D Poisson, Eikonal, Allen-Cahn, and Kuramoto-Sivashinsky datasets across varying training sizes and noise levels. No derivation chain exists that reduces a claimed prediction or uniqueness result to a fitted parameter or self-citation by construction. Performance claims rest on direct, independent experimental comparisons rather than any self-referential definition or ansatz smuggled through prior work. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Random Fourier features can be directly embedded into the trunk network of DeepONet to improve capture of complex spatial structures in PDE solutions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose injecting fixed Fourier Embeddings into the trunk network input … ϕ(ζ)=[sin(2πZζ),cos(2πZζ)], Z_ij∼N(0,σ²)
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FEDONet delivers consistently superior reconstruction accuracy … particularly large relative L² error reductions observed in chaotic and stiff systems
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
UFO: A Domain-Unification-Free Operator Framework for Generalized Operator Learning
UFO is a cross-domain neural operator framework that achieves discretization decoupling via adaptive jointly-conditioned interactions among distinct domain representations.
Reference graph
Works this paper leans on
-
[1]
J. P. Boyd, Chebyshev and Fourier spectral methods, Courier Corpora- tion, 2001
work page 2001
-
[2]
D. Gottlieb, S. A. Orszag, Numerical Analysis of Spectral Methods: Theory and Applications, CBMS–NSF Regional Conference Series in Applied Mathematics, SIAM, 1977. doi:10.1137/1.9781611970425
-
[3]
W. H. Press, S. A. Teukolsky, W. T. Vetterling, B. P. Flannery, Numer- ical Recipes: The Art of Scientific Computing, Cambridge University Press, 1986
work page 1986
-
[4]
G. Cybenko, Approximation by superpositions of a sigmoidal function, Mathematics of control, signals and systems 2 (4) (1989) 303–314
work page 1989
- [5]
-
[6]
T. Poggio, F. Girosi, Networks for approximation and learning, Proceed- ings of the IEEE 78 (9) (1990) 1481–1497. doi:10.1109/5.58326
-
[7]
T. Chen, H. Chen, Universal approximation to nonlinear operators by neuralnetworkswitharbitraryactivationfunctionsanditsapplicationto dynamical systems, IEEE transactions on neural networks 6 (4) (1995) 911–917
work page 1995
-
[8]
Sirovich, Turbulence and the dynamics of coherent structures
L. Sirovich, Turbulence and the dynamics of coherent structures. i. co- herent structures, Quarterly of applied mathematics 45 (3) (1987) 561– 571
work page 1987
-
[9]
G. Berkooz, P. Holmes, J. L. Lumley, The proper orthogonal decomposi- tion in the analysis of turbulent flows, Annual review of fluid mechanics 25 (1) (1993) 539–575. 29
work page 1993
-
[10]
C. E. Rasmussen, C. K. I. Williams, Gaussian Processes for Machine Learning, The MIT Press, 2005. arXiv:https://direct.mit.edu/book- pdf/2514321/book_9780262256834.pdf, doi:10.7551/mitpress/3206.001.0001. URLhttps://doi.org/10.7551/mitpress/3206.001.0001
-
[11]
E. Kansa, Multiquadrics—a scattered data approximation scheme with applications to computational fluid-dynamics—i surface approxima- tions and partial derivative estimates, Computers & Mathematics with Applications 19 (8) (1990) 127–145. doi:https://doi.org/10.1016/0898- 1221(90)90270-T. URLhttps://www.sciencedirect.com/science/article/pii/089812219090270T
-
[12]
D. Lowe, D. Broomhead, Multivariable functional interpolation and adaptive networks, Complex systems 2 (3) (1988) 321–355
work page 1988
-
[13]
T. Qin, K. Wu, D. Xiu, Data driven governing equations approxima- tion using deep neural networks, Journal of Computational Physics 395 (2019) 620–635
work page 2019
-
[14]
L. Lu, P. Jin, G. Pang, Z. Zhang, G. E. Karniadakis, Learning nonlin- ear operators via deeponet based on the universal approximation the- orem of operators, Nature Machine Intelligence 3 (3) (2021) 218–229. doi:10.1038/s42256-021-00302-5. URLhttps://doi.org/10.1038/s42256-021-00302-5
-
[15]
N. Kovachki, Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, A. Stu- art, A. Anandkumar, Neural operator: learning maps between function spaceswithapplicationstopdes, J.Mach.Learn.Res.24(1)(Jan.2023)
work page 2023
-
[16]
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stu- art, A. Anandkumar, Neural operator: Graph kernel network for partial differential equations (2020). arXiv:2003.03485. URLhttps://arxiv.org/abs/2003.03485
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [17]
-
[18]
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stu- art, A. Anandkumar, Fourier neural operator for parametric partial dif- ferential equations (2021). arXiv:2010.08895. URLhttps://arxiv.org/abs/2010.08895
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
K. Wu, D. Xiu, Data-driven deep learning of partial differential equa- tions in modal space, Journal of Computational Physics 408 (2020) 109307
work page 2020
-
[20]
T. Tripura, S. Chakraborty, Wavelet neural operator for solving parametric partial differential equations in computational mechanics problems, Computer Methods in Applied Mechanics and Engineering 404 (2023) 115783. doi:https://doi.org/10.1016/j.cma.2022.115783. URLhttps://www.sciencedirect.com/science/article/pii/S0045782522007393
- [21]
- [22]
-
[23]
J. Kossaifi, N. Kovachki, K. Azizzadenesheli, A. Anandkumar, Multi- grid tensorized fourier neural operator for high-resolution pdes, arXiv preprint arXiv:2310.00120 (2023)
- [24]
-
[25]
Z. Li, D. Z. Huang, B. Liu, A. Anandkumar, Fourier neural operator with learned deformations for pdes on general geometries, Journal of Machine Learning Research 24 (388) (2023) 1–26
work page 2023
-
[26]
S. Lanthaler, R. Molinaro, P. Hadorn, S. Mishra, Nonlinear recon- struction for operator learning of pdes with discontinuities (2022). 31 arXiv:2210.01074. URLhttps://arxiv.org/abs/2210.01074
- [27]
- [28]
- [29]
- [30]
- [31]
-
[32]
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, L. Yang, Physics-informed machine learning, Nature Reviews Physics 3 (2021) 422–440. doi:10.1038/s42254-021-00314-5. URLhttps://doi.org/10.1038/s42254-021-00314-5
- [33]
-
[34]
S. Goswami, A. Bora, Y. Yu, G. E. Karniadakis, Physics-informed deep neural operator networks (2022). arXiv:2207.05748. URLhttps://arxiv.org/abs/2207.05748 32
- [35]
- [36]
-
[37]
K. Chen, Y. Li, D. Long, W. W. XING, J. Hochhalter, S. Zhe, Pseudo physics-informed neural operators (2025). URLhttps://openreview.net/forum?id=CrmUKllBKs
work page 2025
- [38]
- [39]
- [40]
- [41]
-
[42]
Z. Hao, Z. Wang, H. Su, C. Ying, Y. Dong, S. Liu, Z. Cheng, J. Song, J. Zhu, Gnot: A general neural operator transformer for operator learn- ing, in: International Conference on Machine Learning, PMLR, 2023, pp. 12556–12569
work page 2023
- [43]
-
[44]
Z.Li, D.Shu, A.BaratiFarimani, Scalabletransformerforpdesurrogate modeling, Advances in Neural Information Processing Systems 36 (2023) 28010–28039
work page 2023
- [45]
-
[46]
A. Bryutkin, J. Huang, Z. Deng, G. Yang, C.-B. Schönlieb, A. Aviles- Rivero, Hamlet: Graph transformer neural operator for partial differen- tial equations, arXiv preprint arXiv:2402.03541 (2024)
-
[47]
Z. Li, N. Kovachki, C. Choy, B. Li, J. Kossaifi, S. Otta, M. A. Nabian, M. Stadler, C. Hundt, K. Azizzadenesheli, et al., Geometry-informed neural operator for large-scale 3d pdes, Advances in Neural Information Processing Systems 36 (2023) 35836–35854
work page 2023
-
[48]
J. Pathak, S. Subramanian, P. Harrington, S. Raja, A. Chattopadhyay, M. Mardani, T. Kurth, D. Hall, Z. Li, K. Azizzadenesheli, et al., Four- castnet: A global data-driven high-resolution weather model using adap- tive fourier neural operators, arXiv preprint arXiv:2202.11214 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[49]
Z. Xiao, S. Kou, H. Zhongkai, B. Lin, Z. Deng, Amortized fourier neural operators, AdvancesinNeuralInformationProcessingSystems37(2024) 115001–115020
work page 2024
-
[50]
M. Tancik, P. P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Ragha- van, U. Singhal, R. Ramamoorthi, J. T. Barron, R. Ng, Fourier features let networks learn high frequency functions in low dimensional domains (2020). arXiv:2006.10739. URLhttps://arxiv.org/abs/2006.10739
-
[51]
On the Spectral Bias of Neural Networks
N.Rahaman, A.Baratin, D.Arpit, F.Draxler, M.Lin, F.A.Hamprecht, Y. Bengio, A. Courville, On the spectral bias of neural networks (2019). arXiv:1806.08734. URLhttps://arxiv.org/abs/1806.08734
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [52]
-
[53]
S. Wang, H. Wang, P. Perdikaris, Learning the solution operator of para- metric partial differential equations with physics-informed deeponets, Science advances 7 (40) (2021) eabi8605. Appendix A. Whitening Effect of Fourier Feature Embeddings Letϕ(ζ) = √ 2 [sin(2πZζ),cos(2πZζ)]∈R 2M be the Fourier feature em- bedding of an inputζ∈R d, where each row of t...
work page 2021
-
[54]
Fourier-Embedded DeepONets naturally align with the dominant spec- tral modes of the target operator, facilitating more efficient approxima- tion of high-frequency content
-
[55]
The learned basis can adapt to complex patterns in the data, unlike fixed basis expansions
-
[56]
The operator learning framework parallels well-established numerical discretization techniques, such as Petrov-Galerkin and spectral meth- ods, but operates in a fully data-driven regime. In summary, Fourier Embeddings serve as a principled mechanism for spec- tral lifting, enabling DeepONet to perform a learned Galerkin-style decom- position of operators...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.