Knowledge-Driven Hallucination in Large Language Models: An Empirical Study on Process Modeling
Pith reviewed 2026-05-18 15:29 UTC · model grok-4.3
The pith
LLMs override explicit process descriptions with their pre-trained knowledge of standard business workflows
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLMs exhibit knowledge-driven hallucination in which their generated process models contradict explicit source evidence because the output is overridden by the model's generalized internal knowledge about standard business processes.
What carries the argument
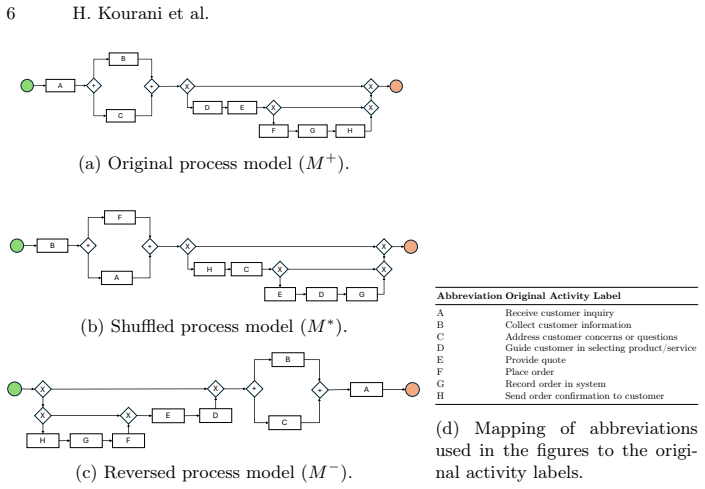
Controlled experiment that compares LLM outputs on standard process descriptions versus deliberately atypical process structures to measure fidelity to the supplied evidence.
Load-bearing premise
Deliberately atypical process structures in the input will create observable conflicts with the LLM's pre-trained knowledge without being masked by prompt phrasing or model-specific biases.
What would settle it
If the models produce process diagrams with equal fidelity to the source text for both standard and atypical descriptions, the claim of knowledge-driven overriding would be falsified.
Figures
read the original abstract
The utility of Large Language Models (LLMs) in analytical tasks is rooted in their vast pre-trained knowledge, which allows them to interpret ambiguous inputs and infer missing information. However, this same capability introduces a critical risk of what we term knowledge-driven hallucination: a phenomenon where the model's output contradicts explicit source evidence because it is overridden by the model's generalized internal knowledge. This paper investigates this phenomenon by evaluating LLMs on the task of automated process modeling, where the goal is to generate a formal business process model from a given source artifact. The domain of Business Process Management (BPM) provides an ideal context for this study, as many core business processes follow standardized patterns, making it likely that LLMs possess strong pre-trained schemas for them. We conduct a controlled experiment designed to create scenarios with deliberate conflict between provided evidence and the LLM's background knowledge. We use inputs describing both standard and deliberately atypical process structures to measure the LLM's fidelity to the provided evidence. Our work provides a methodology for assessing this critical reliability issue and raises awareness of the need for rigorous validation of AI-generated artifacts in any evidence-based domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs exhibit 'knowledge-driven hallucination' when generating formal business process models from source descriptions: the models contradict explicit but atypical input evidence because the LLM's pre-trained knowledge of standard processes overrides the provided source. The authors propose a controlled experiment contrasting standard versus deliberately atypical process structures to measure fidelity to the input evidence and provide a methodology for assessing this reliability issue in evidence-based domains such as BPM.
Significance. If the central empirical claim can be substantiated with reproducible measurements, the work would usefully document a concrete failure mode for LLM use in analytical tasks that require strict adherence to supplied evidence rather than generalization from training data. It raises awareness of validation needs for AI-generated artifacts in structured domains and could inform prompt-engineering or post-processing safeguards.
major comments (2)
- The central claim requires an observable, reproducible way to detect when a generated process model contradicts explicit source evidence. The experiment description contrasts standard and atypical inputs but supplies no formal, automatable criterion (e.g., violation of specific BPMN constraints, missing mandatory elements, or a graph-edit-distance threshold) for classifying outputs as contradicting the input; human judgment or post-hoc inspection is implied but not operationalized. This is load-bearing for the empirical measurement.
- No quantitative results, model details (e.g., which LLMs, temperature settings, prompt templates), dataset descriptions, or statistical analysis appear in the abstract or experiment outline, preventing verification that observed differences arise from knowledge override rather than prompt sensitivity or decoding stochasticity.
minor comments (2)
- Clarify the exact definition of 'atypical' structures and how they were constructed to ensure they remain valid process descriptions while conflicting with common schemas.
- Add a dedicated section or appendix detailing the full experimental protocol, including input artifacts, output parsing method, and any inter-annotator agreement if human evaluation is used.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which help strengthen the clarity and rigor of our empirical study on knowledge-driven hallucination in LLMs for process modeling. We address each major comment point by point below.
read point-by-point responses
-
Referee: The central claim requires an observable, reproducible way to detect when a generated process model contradicts explicit source evidence. The experiment description contrasts standard and atypical inputs but supplies no formal, automatable criterion (e.g., violation of specific BPMN constraints, missing mandatory elements, or a graph-edit-distance threshold) for classifying outputs as contradicting the input; human judgment or post-hoc inspection is implied but not operationalized. This is load-bearing for the empirical measurement.
Authors: We agree that an explicit, automatable criterion is necessary to substantiate the central claim and enable reproducibility. The manuscript describes the controlled contrast between standard and atypical process inputs to measure fidelity to source evidence, but does not yet formalize the detection rule. In the revised version, we will add a precise operational definition: a model exhibits knowledge-driven hallucination if its parsed structure deviates from the input-specified atypical elements (e.g., replacing a described parallel gateway with a standard sequential flow or inserting unmentioned standard activities). This will be implemented via automated graph parsing of the output BPMN and computation of a normalized graph-edit distance to an input-derived reference model, with a fixed threshold for classification. Pseudocode and validation examples will be included in the methodology section. revision: yes
-
Referee: No quantitative results, model details (e.g., which LLMs, temperature settings, prompt templates), dataset descriptions, or statistical analysis appear in the abstract or experiment outline, preventing verification that observed differences arise from knowledge override rather than prompt sensitivity or decoding stochasticity.
Authors: The full manuscript reports these elements in the Experiments and Results sections, including the LLMs evaluated, temperature settings chosen for reduced stochasticity, prompt templates, dataset construction (standard vs. atypical descriptions), and statistical comparisons of fidelity metrics. However, we acknowledge that the abstract and high-level experiment outline do not preview them adequately. We will revise by expanding the experiment outline to list all models, parameters, dataset sizes, and analysis methods upfront, and will add a concise summary of key quantitative findings to the abstract within length constraints. revision: partial
Circularity Check
Empirical measurement study with no derivation chain
full rationale
The paper frames its contribution as a controlled empirical experiment that contrasts LLM outputs on standard versus deliberately atypical process descriptions to observe fidelity to input evidence. No equations, first-principles derivations, or quantitative predictions appear in the abstract or described methodology. The central claim rests on experimental observations rather than any reduction of results to fitted parameters, self-definitions, or self-citation chains. The work is therefore self-contained as an empirical measurement study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs possess strong pre-trained schemas for standard business processes.
invented entities (1)
-
knowledge-driven hallucination
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We conduct a controlled experiment designed to create scenarios with deliberate conflict between provided evidence and the LLM's background knowledge. We use inputs describing both standard and deliberately atypical process structures to measure the LLM's fidelity to the provided evidence.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our findings strongly support our central hypothesis: LLMs exhibit a significant tendency for knowledge-driven hallucination when faced with atypical process structures.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
de A. R. Gonçalves, J.C., Santoro, F.M., Baião, F.A.: Let me tell you a story - on how to build process models. J. Univers. Comput. Sci.17(2), 276–295 (2011)
work page 2011
-
[2]
van der Aa, H., Carmona, J., Leopold, H., Mendling, J., Padró, L.: Challenges and opportunities of applying natural language processing in business process manage- ment. In: COLING 2018. pp. 2791–2801 (2018)
work page 2018
-
[3]
Alberto Blanco-Justicia et al.: Digital forgetting in large language models: a survey of unlearning methods. Artif. Intell. Rev.58(3), 90 (2025) 12 H. Kourani et al
work page 2025
-
[4]
Berti,A.,vanZelst,S.J.,Schuster,D.:PM4Py:Aprocessmininglibraryforpython. Softw. Impacts17, 100556 (2023)
work page 2023
-
[5]
Brown, T.B., Mann, B., Ryder, N., et al., M.S.: Language models are few-shot learners. In: NeurIPS 2020 (2020)
work page 2020
-
[6]
Busch, K., Leopold, H.: Towards a benchmark for large language models for busi- ness process management tasks. CoRRabs/2410.03255(2024)
-
[7]
Domain specialization as the key to make large language models disruptive: A comprehensive survey
Chen Ling et al.: Beyond one-model-fits-all: A survey of domain specialization for large language models. CoRRabs/2305.18703(2023)
-
[8]
Chen Qian et al.: An approach for process model extraction by multi-grained text classification. In: CAiSE 2020. LNCS, vol. 12127, pp. 268–282. Springer (2020)
work page 2020
-
[9]
Chunting Zhou et al.: LIMA: less is more for alignment. In: NeurIPS 2023 (2023)
work page 2023
-
[10]
Dumas, M., Rosa, M.L., Mendling, J., Reijers, H.A.: Fundamentals of Business Process Management, Second Edition. Springer (2018)
work page 2018
-
[11]
Forster, S., Pinggera, J., Weber, B.: Toward an understanding of the collaborative process of process modeling. In: CAiSE’13 Forum. pp. 98–105 (2013)
work page 2013
-
[12]
Friedrich, F., Mendling, J., Puhlmann, F.: Process model generation from natural language text. In: CAiSE 2011. pp. 482–496 (2011)
work page 2011
-
[13]
Grohs, M., Abb, L., Elsayed, N., Rehse, J.: Large language models can accomplish business process management tasks. In: BPM 2023 Workshops. LNBIP, vol. 492, pp. 453–465. Springer (2023)
work page 2023
-
[14]
Hosking, T., Blunsom, P., Bartolo, M.: Human feedback is not gold standard. In: ICLR 2024. OpenReview.net (2024)
work page 2024
-
[15]
Klievtsova, N., Benzin, J., Kampik, T., Mangler, J., Rinderle-Ma, S.: Conversa- tionalprocessmodelling:Stateoftheart,applications,andimplicationsinpractice. In: BPM 2023 Forum. pp. 319–336 (2023)
work page 2023
-
[16]
Kourani, H., Berti, A., Schuster, D., van der Aalst, W.M.P.: Evaluating large language models on business process modeling: Framework, benchmark, and self- improvement analysis. CoRRabs/2412.00023(2024)
-
[17]
Kourani, H., Berti, A., Schuster, D., van der Aalst, W.M.P.: Process modeling with large language models. In: Enterprise, Business-Process and Information Systems Modeling - BPMDS 2024 and EMMSAD 2024, Limassol, Cyprus, June 3-4, 2024, Proceedings. pp. 229–244 (2024)
work page 2024
-
[18]
In: IJCAI 2024, Jeju, South Korea, August 3-9, 2024
Kourani, H., Berti, A., Schuster, D., van der Aalst, W.M.P.: ProMoAI: Process modeling with generative AI. In: IJCAI 2024, Jeju, South Korea, August 3-9, 2024. pp. 8708–8712 (2024)
work page 2024
-
[19]
Kourani, H., van Zelst, S.J.: POWL: partially ordered workflow language. In: BPM
- [20]
-
[21]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao et al.: The pile: An 800gb dataset of diverse text for language modeling. CoRRabs/2101.00027(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
LongzeChenetal.:Longcontextisnotlongatall:Aprospectoroflong-dependency data for large language models. In: ACL 2024. pp. 8222–8234. Association for Computational Linguistics (2024)
work page 2024
-
[23]
Lukas Berglund et al.: The reversal curse: Llms trained on "a is b" fail to learn "b is a". In: ICLR 2024. OpenReview.net (2024)
work page 2024
-
[24]
Mrinank Sharma et al.: Towards understanding sycophancy in language models. In: ICLR 2024. OpenReview.net (2024)
work page 2024
-
[25]
Roberts, M., Anderson, J., Delgado, W., Johnson, R., Spencer, L.: Extending con- textual length and world knowledge generalization in large language models (2024) Knowledge-Driven Hallucination in Large Language Models 13
work page 2024
-
[26]
Sholiq, S., Sarno, R., Astuti, E.S.: Generating BPMN diagram from textual re- quirements. J. King Saud Univ. Comput. Inf. Sci.34(10 Part B), 10079–10093 (2022)
work page 2022
-
[27]
Sintoris, K., Vergidis, K.: Extracting business process models using natural lan- guage processing (NLP) techniques. In: CBI 2017. pp. 135–139 (2017)
work page 2017
-
[28]
Woensel, W.V., Motie, S.: NLP4PBM: a systematic review on process extraction using natural language processing with rule-based, machine and deep learning methods. Enterp. Inf. Syst.18(11) (2024)
work page 2024
-
[29]
Aligning large language models with human: A survey.arXiv preprint arXiv:2307.12966, 2023
Yufei Wang et al.: Aligning large language models with human: A survey. CoRR abs/2307.12966(2023)
-
[30]
Ziwei Ji et al.: Survey of hallucination in natural language generation. ACM Com- put. Surv.55(12), 248:1–248:38 (2023)
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.