Overcoming Output Dimension Collapse: When Sparsity Enables Zero-shot Brain-to-Image Reconstruction at Small Data Scales
Pith reviewed 2026-05-18 16:06 UTC · model grok-4.3
The pith
Sparse multivariate linear regression avoids output dimension collapse in brain-to-image reconstruction when training samples are few relative to feature dimensions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
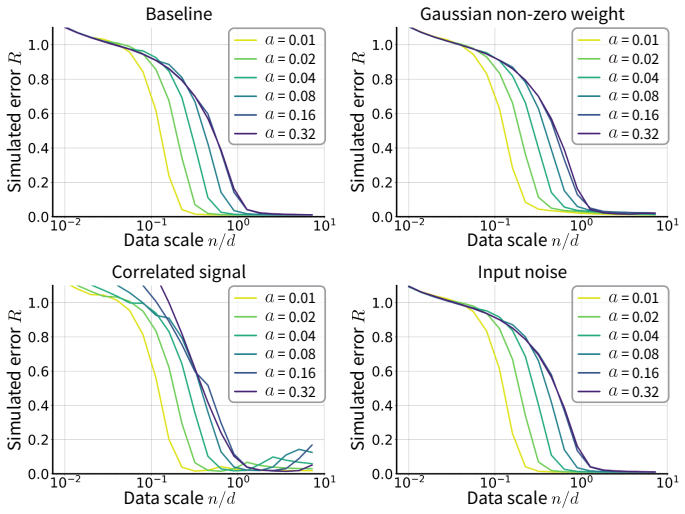
Naive multivariate linear regression suffers output dimension collapse as a structural property when the number of training samples is small compared to latent feature dimensionality, acting as a practical bottleneck in zero-shot brain-to-image reconstruction; sparse linear regression models in the student-teacher framework yield explicit prediction error formulas in terms of data scale and sparsity parameters, clarifying that variable selection reduces error at small data scales when the brain-to-feature mapping is sufficiently sparse.
What carries the argument
Output dimension collapse, the rank deficiency arising in naive multivariate linear regression predictions when samples fall below output dimensionality, which the paper shows becomes a generalization bottleneck quantifiable by the best prediction diagnostic.
If this is right
- The best prediction diagnostic can be computed from feature statistics alone to flag when output dimension collapse is harming reconstruction.
- Sparse regression supplies quantitative thresholds on data scale and sparsity parameters for when it outperforms naive methods.
- Feature spaces should be selected or engineered to make brain-to-feature mappings sparse enough to benefit from variable selection.
- Translators for zero-shot reconstruction at limited data scales should incorporate sparsity-aware variable selection rather than full multivariate regression.
Where Pith is reading between the lines
- The student-teacher error derivations could be tested directly on simulated brain responses to confirm the sparsity thresholds before real-data application.
- Similar dimension-collapse analysis might apply to other brain-decoding domains such as auditory or language reconstruction where output spaces are also high-dimensional.
- If sparsity holds across subjects, the approach could reduce the number of training stimuli needed for personalized reconstruction pipelines.
Load-bearing premise
The brain-to-feature mapping has enough sparsity for variable selection to improve prediction accuracy over naive regression at small data scales.
What would settle it
Measure whether sparse regression yields measurably lower prediction error than naive regression on held-out brain-to-image pairs precisely when the ratio of training samples to feature dimensionality is low, checking if the gap matches the derived student-teacher error expressions.
Figures









read the original abstract
Advances in brain-to-image reconstruction are enabling us to externalize the subjective visual experiences encoded in the brain as images. A key challenge in this task is data scarcity: a translator that maps brain activity to latent image features is trained on a limited number of brain-image pairs, making the translator a bottleneck for zero-shot reconstruction beyond the training stimuli. In this paper, we mathematically analyze the behavior of two translators commonly used in recent reconstruction pipelines: naive multivariate linear regression and sparse multivariate linear regression. We define the data scale as the ratio of the number of training samples to the latent feature dimensionality and characterize the behavior of each model across data scales. Building on a standard structural property of naive multivariate regression, we first show that the resulting ``output dimension collapse'' can become a practical generalization bottleneck in brain-to-image reconstruction. We introduce the best prediction diagnostic, which is computable without brain activity, to quantify the practical impact of this collapse. We then analyze sparse linear regression models in a student--teacher framework and derive expressions for the prediction error in terms of data scale and other sparsity-related parameters. Our analysis clarifies when variable selection can reduce prediction error at small data scales by exploiting the sparsity of the brain-to-feature mapping. Our findings provide quantitative guidelines for diagnosing output dimension collapse and for designing effective translators and feature representations for zero-shot reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes naive and sparse multivariate linear regression translators for brain-to-image reconstruction under data scarcity. It identifies output dimension collapse in naive regression at small data scales (n/d << 1) as a generalization bottleneck and introduces a best prediction diagnostic computable without brain activity. In a student-teacher framework, it derives closed-form prediction error expressions for sparse regression in terms of data scale and sparsity parameters, clarifying when variable selection reduces error by exploiting brain-to-feature mapping sparsity and providing quantitative guidelines for translator and feature design.
Significance. If the derivations are sound and the sparsity assumption holds for real brain data, the work supplies theoretical tools to diagnose and mitigate a key bottleneck in zero-shot reconstruction pipelines. The best prediction diagnostic and explicit error expressions versus data scale offer practical value for designing translators at small scales, a common regime in neuroimaging. The student-teacher analysis enables parameter-free insights into sparsity benefits without requiring large-scale simulations.
major comments (2)
- [Student-teacher framework] Student-teacher framework section: The central claim that sparse regression reduces prediction error at small scales rests on the teacher mapping being sufficiently sparse; the paper should include an empirical estimate or sensitivity analysis of sparsity levels in actual brain-to-latent-feature mappings (e.g., from NSD or similar datasets) to confirm the assumed sparsity pattern transfers, as mismatch would invalidate the quantitative guidelines.
- [Naive multivariate linear regression analysis] Analysis of naive regression and output dimension collapse: While the structural property is standard, the manuscript must specify the precise data-scale threshold (with equation) at which collapse becomes the dominant error source versus other factors like noise, to make the 'practical generalization bottleneck' claim load-bearing rather than asymptotic.
minor comments (2)
- [Abstract] Abstract describes derivations but provides no equations; adding the key closed-form error expressions would improve accessibility.
- [Best prediction diagnostic] The 'best prediction diagnostic' is introduced without an explicit formula or pseudocode; a dedicated subsection or equation would clarify its computation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with point-by-point responses, indicating planned revisions where appropriate. Our goal is to strengthen the quantitative aspects of the analysis while preserving the theoretical focus of the work.
read point-by-point responses
-
Referee: [Student-teacher framework] Student-teacher framework section: The central claim that sparse regression reduces prediction error at small scales rests on the teacher mapping being sufficiently sparse; the paper should include an empirical estimate or sensitivity analysis of sparsity levels in actual brain-to-latent-feature mappings (e.g., from NSD or similar datasets) to confirm the assumed sparsity pattern transfers, as mismatch would invalidate the quantitative guidelines.
Authors: We agree that demonstrating robustness to the sparsity level would make the guidelines more actionable. The student-teacher derivations are parameterized by the sparsity level of the teacher mapping and explicitly show the conditions (in terms of data scale and sparsity) under which variable selection reduces error; the central claim is therefore conditional rather than absolute. To address the request, we will add a sensitivity analysis that varies the teacher sparsity parameter across a range of plausible values and reports the resulting prediction error curves at small data scales. Regarding empirical estimates from datasets such as NSD, our manuscript is primarily a theoretical analysis; we will include a short discussion of how effective sparsity could be estimated post hoc using the best-prediction diagnostic on real brain-to-feature pairs, but a full empirical study lies outside the current scope. revision: partial
-
Referee: [Naive multivariate linear regression analysis] Analysis of naive regression and output dimension collapse: While the structural property is standard, the manuscript must specify the precise data-scale threshold (with equation) at which collapse becomes the dominant error source versus other factors like noise, to make the 'practical generalization bottleneck' claim load-bearing rather than asymptotic.
Authors: We accept this suggestion. The manuscript currently emphasizes the asymptotic regime n/d ≪ 1. In the revision we will insert an explicit threshold equation that identifies the data-scale value at which the output-dimension-collapse contribution to the prediction error exceeds the contribution from additive noise. The equation will be expressed in terms of the noise variance, the feature dimensionality, and the regression coefficients, thereby making the practical-bottleneck claim quantitative rather than purely asymptotic. revision: yes
Circularity Check
Derivation is self-contained theoretical analysis in student-teacher model
full rationale
The paper derives closed-form prediction error expressions for naive and sparse multivariate linear regression within an explicitly assumed student-teacher generative model, building on standard properties of linear regression (e.g., output dimension collapse when n/d << 1). These expressions are obtained directly from the model assumptions and parameters (data scale, sparsity level) without reducing to fitted quantities, self-citations, or tautological redefinitions. Sparsity is introduced as an input modeling choice rather than derived from the result itself. No load-bearing steps collapse by construction to the paper's own inputs or prior self-citations; the analysis remains externally falsifiable against the stated generative assumptions.
Axiom & Free-Parameter Ledger
free parameters (2)
- sparsity level
- data scale
axioms (2)
- domain assumption Brain-to-feature mapping is sparse
- standard math Standard structural property of naive multivariate regression leads to output dimension collapse
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We mathematically characterize the prediction error of the sparse linear regression model by deriving formulas linking prediction error with data scale, sparsity, and other parameters.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Sparse regression models can effectively exploit the sparse brain-to-feature mapping... rank(Ŵ) > n
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Allen, Ghislain St-Yves, Yihan Wu, Jesse L
author Allen, E.J. , author St-Yves, G. , author Wu, Y. , author Breedlove, J.L. , author Prince, J.S. , author Dowdle, L.T. , author Nau, M. , author Caron, B. , author Pestilli, F. , author Charest, I. , author Hutchinson, J.B. , author Naselaris, T. , author Kay, K. , year 2022 . title A massive 7t fmri dataset to bridge cognitive neuroscience and arti...
-
[2]
author Belloni, A. , author Chernozhukov, V. , year 2013 . title Least squares after model selection in high-dimensional sparse models . journal Bernoulli volume 19 , pages 521--547 . :10.3150/11-BEJ410
-
[3]
author Chen, Z. , author Qing, J. , author Xiang, T. , author Yue, W.L. , author Zhou, J.H. , year 2023 . title Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding , in: booktitle Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. pages 22710--22720 . :10.1109/CVPR52729....
-
[4]
author Cheng, F.L. , author Horikawa, T. , author Majima, K. , author Tanaka, M. , author Abdelhack, M. , author Aoki, S.C. , author Hirano, J. , author Kamitani, Y. , year 2023 . title Reconstructing visual illusory experiences from human brain activity . journal Science Advances volume 9 . :10.1126/sciadv.adj3906
-
[5]
author De Valois, R.L. , author Albrecht, D.G. , author Thorell, L.G. , year 1982 . title Spatial frequency selectivity of cells in macaque visual cortex . journal Vision Research volume 22 , pages 545--559 . :10.1016/0042-6989(82)90113-4
-
[6]
author Deng, J. , author Dong, W. , author Socher, R. , author Li, L.J. , author Li, K. , author Fei-Fei, L. , year 2009 . title Imagenet: A large-scale hierarchical image database , in: booktitle Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. pages 248--255 . :10.1109/CVPR.2009.5206848
-
[7]
author Dicker, L.H. , year 2016 . title Ridge regression and asymptotic minimax estimation over spheres of growing dimension . journal Bernoulli volume 22 , pages 1--37 . :10.3150/14-BEJ609
-
[8]
author Donoho, D.L. , year 2006 . title Compressed sensing . journal IEEE Transactions on Information Theory volume 52 , pages 1289--1306 . :10.1109/TIT.2006.871582
-
[9]
author Fan, J. , author Lv, J. , year 2008 . title Sure independence screening for ultrahigh dimensional feature space . journal Journal of the Royal Statistical Society: Series B (Statistical Methodology) volume 70 , pages 849--911 . :10.1111/j.1467-9868.2008.00674.x
-
[10]
author Guyon, I. , author Elisseeff, A. , year 2003 . title An introduction to variable and feature selection . journal Journal of Machine Learning Research volume 3 , pages 1157--1182 . :10.1162/153244303322753616
-
[11]
author Hall, M.A. , year 2000 . title Correlation-based feature selection of discrete and numeric class machine learning , in: booktitle Proceedings of the Seventeenth International Conference on Machine Learning , address Stanford, CA, USA . pp. pages 359--366
work page 2000
-
[12]
Hebart, Oliver Contier, Lina Teichmann, Adam H
author Hebart, M.N. , author Contier, O. , author Teichmann, L. , author Rockter, A.H. , author Zheng, C.Y. , author Kidder, A. , author Corriveau, A. , author Vaziri-Pashkam, M. , author Baker, C.I. , year 2023 . title Things-data, a multimodal collection of large-scale datasets for investigating object representations in human brain and behavior . journ...
-
[13]
author Hubel, D.H. , author Wiesel, T.N. , year 1962 . title Receptive fields, binocular interaction and functional architecture in the cat's visual cortex . journal The Journal of Physiology volume 160 , pages 106--154 . :10.1113/jphysiol.1962.sp006837
-
[14]
author Jacot, A. , author Gabriel, F. , author Hongler, C. , year 2018 . title Neural tangent kernel: Convergence and generalization in neural networks , in: booktitle Advances in Neural Information Processing Systems , publisher Curran Associates, Inc
work page 2018
-
[15]
author Kohavi, R. , author John, G.H. , year 1997 . title Wrappers for feature subset selection . journal Artificial Intelligence volume 97 , pages 273--324 . :10.1016/S0004-3702(97)00043-X
-
[16]
author MacKay, D.J.C. , year 1992 . title Bayesian interpolation . journal Neural Computation volume 4 , pages 415--447 . :10.1162/neco.1992.4.3.415
-
[17]
author Miyawaki, Y. , author Uchida, H. , author Yamashita, O. , author Sato, M. , author Morito, Y. , author Tanabe, H.C. , author Sadato, N. , author Kamitani, Y. , year 2008 . title Visual image reconstruction from human brain activity using a combination of multiscale local image decoders . journal Neuron volume 60 , pages 915--929 . :10.1016/j.neuron...
-
[18]
author Nonaka, S. , author Majima, K. , author Aoki, S.C. , author Kamitani, Y. , year 2021 . title Brain hierarchy score: Which deep neural networks are hierarchically brain-like? journal iScience volume 24 . :10.1016/j.isci.2021.103013
-
[19]
Natural scene reconstruction from fmri signals using generative latent diffusion
author Ozcelik, F. , author VanRullen, R. , year 2023 . title Natural scene reconstruction from fmri signals using generative latent diffusion . journal Scientific Reports volume 13 . :10.1038/s41598-023-42891-8
-
[20]
author Schrimpf, M. , author Kubilius, J. , author Lee, M.J. , author Ratan Murty, N.A. , author Ajemian, R. , author DiCarlo, J.J. , year 2020 . title Integrative benchmarking to advance neurally mechanistic models of human intelligence . journal Neuron volume 108 , pages 413--423 . :10.1016/j.neuron.2020.07.040
-
[21]
author Scotti, P.S. , author Banerjee, A. , author Goode, J. , author Shabalin, S. , author Nguyen, A. , author Cohen, E. , author Dempster, A.J. , author Verlinde, N. , author Yundler, E. , author Weisberg, D. , author Norman, K.A. , author Abraham, T.M. , year 2023 . title Reconstructing the mind’s eye: fmri-to-image with contrastive learning and diffus...
work page 2023
-
[22]
author Scotti, P.S. , author Tripathy, M. , author Torrico, C.K. , author Kneeland, R. , author Chen, T. , author Narang, A. , author Santhirasegaran, C. , author Xu, J. , author Naselaris, T. , author Norman, K.A. , author Abraham, T.M. , year 2024 . title Mindeye2: Shared-subject models enable fmri-to-image with 1 hour of data , in: editor Salakhutdinov...
work page 2024
-
[23]
author Seeliger, K. , author Güçlü, U. , author Ambrogioni, L. , author Güçlütürk, Y. , author van Gerven, M.A.J. , year 2018 . title Generative adversarial networks for reconstructing natural images from brain activity . journal NeuroImage volume 181 , pages 775--785 . :10.1016/j.neuroimage.2018.07.043
-
[24]
doi: 10.1371/journal.pcbi.1006633
author Shen, G. , author Horikawa, T. , author Majima, K. , author Kamitani, Y. , year 2019 . title Deep image reconstruction from human brain activity . journal PLOS Computational Biology volume 15 . :10.1371/journal.pcbi.1006633
-
[25]
author Shirakawa, K. , author Nagano, Y. , author Tanaka, M. , author Aoki, S.C. , author Muraki, Y. , author Majima, K. , author Kamitani, Y. , year 2025 . title Spurious reconstruction from brain activity . journal Neural Networks volume 190 . :10.1016/j.neunet.2025.107515
-
[26]
author Takagi, Y. , author Nishimoto, S. , year 2023 . title High-resolution image reconstruction with latent diffusion models from human brain activity , in: booktitle Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. pages 14453--14463 . :10.1109/CVPR52729.2023.01389
-
[27]
Journal of the Royal Statistical Society Series B (Methodological) 58:509--523
author Tibshirani, R. , year 1996 . title Regression shrinkage and selection via the lasso . journal Journal of the Royal Statistical Society: Series B (Methodological) volume 58 , pages 267--288 . :10.1111/j.2517-6161.1996.tb02080.x
-
[28]
author Ulyanov, D. , author Vedaldi, A. , author Lempitsky, V. , year 2018 . title Deep image prior , in: booktitle Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pp. pages 9446--9454 . :10.1109/CVPR.2018.00984
-
[29]
author Vinje, W.E. , author Gallant, J.L. , year 2000 . title Sparse coding and decorrelation in primary visual cortex during natural vision . journal Science volume 287 , pages 1273--1276 . :10.1126/science.287.5456.1273
-
[30]
author Wainwright, M.J. , year 2009 a. title Information-theoretic limits on sparsity recovery in the high-dimensional and noisy setting . journal IEEE Transactions on Information Theory volume 55 , pages 5728--5741 . :10.1109/TIT.2009.2032816
-
[31]
author Wainwright, M.J. , year 2009 b. title Sharp thresholds for high-dimensional and noisy sparsity recovery using _1 -constrained quadratic programming (lasso) . journal IEEE Transactions on Information Theory volume 55 , pages 2183--2202 . :10.1109/TIT.2009.2016018
-
[32]
author Zhang, C. , author Qiao, K. , author Wang, L. , author Tong, L. , author Zeng, Y. , author Yan, B. , year 2018 . title Constraint-free natural image reconstruction from fmri signals based on convolutional neural network . journal Frontiers in Human Neuroscience volume 12 . :10.3389/fnhum.2018.00242
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.