Bayesian Ego-graph Inference for Networked Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-18 15:56 UTC · model grok-4.3
The pith
Decentralized agents learn dynamic interaction structures by sampling latent communication masks over ego-graphs using variational inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce BayesG, a decentralized actor-critic framework in which each agent operates over an ego-graph and samples a latent communication mask from a variational distribution to condition its message passing and policy. The variational distribution is trained jointly with the policy via the evidence lower bound, allowing agents to discover sparse, context-aware interaction structures without access to global states or centralized infrastructure.
What carries the argument
Ego-graph with sampled latent communication mask, which selects which neighbors participate in message passing for each decision.
If this is right
- Agents can adapt their effective neighborhoods to current context without global coordination.
- Communication remains sparse and local even as the number of agents grows to hundreds.
- Joint optimization of topology and policy becomes possible in fully decentralized settings.
- The approach scales to heterogeneous environments where static neighborhoods fail.
Where Pith is reading between the lines
- The same ego-graph sampling idea could apply to other domains with costly or unreliable links, such as sensor networks or robot teams.
- If the variational approximation remains accurate, the method might reduce total messages exchanged compared with full-neighborhood baselines.
- Testing on environments where the physical graph itself changes over time would reveal whether the current fixed-graph assumption limits generality.
Load-bearing premise
The variational distribution over latent masks can be trained end-to-end via ELBO using only local observations without introducing significant bias from the approximation or the fixed underlying graph.
What would settle it
A controlled run on the traffic benchmark where forcing the masks to be fixed or removing the ELBO term causes performance to drop to the level of standard graph-based MARL baselines.
Figures




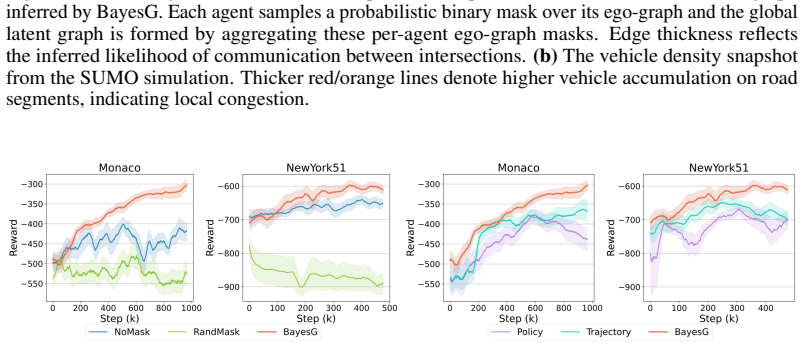







read the original abstract
In networked multi-agent reinforcement learning (Networked-MARL), decentralized agents must act under local observability and constrained communication over fixed physical graphs. Existing methods often assume static neighborhoods, limiting adaptability to dynamic or heterogeneous environments. While centralized frameworks can learn dynamic graphs, their reliance on global state access and centralized infrastructure is impractical in real-world decentralized systems. We propose a stochastic graph-based policy for Networked-MARL, where each agent conditions its decision on a sampled subgraph over its local physical neighborhood. Building on this formulation, we introduce BayesG, a decentralized actor-framework that learns sparse, context-aware interaction structures via Bayesian variational inference. Each agent operates over an ego-graph and samples a latent communication mask to guide message passing and policy computation. The variational distribution is trained end-to-end alongside the policy using an evidence lower bound (ELBO) objective, enabling agents to jointly learn both interaction topology and decision-making strategies. BayesG outperforms strong MARL baselines on large-scale traffic control tasks with up to 167 agents, demonstrating superior scalability, efficiency, and performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BayesG, a decentralized actor-critic framework for Networked-MARL. Each agent maintains an ego-graph over its local physical neighborhood and samples a latent communication mask from a variational distribution to form a stochastic subgraph for message passing. The variational distribution is trained jointly with the policy via an ELBO objective, enabling end-to-end learning of both interaction topology and control policies. The central empirical claim is that BayesG outperforms strong MARL baselines on large-scale traffic control tasks involving up to 167 agents, with gains in scalability, efficiency, and performance.
Significance. If the decentralized variational inference produces interaction structures whose quality is not materially degraded by local observations or the fixed physical graph, the approach would offer a practical route to adaptive communication in fully decentralized settings where centralized graph learning is infeasible. The ego-graph formulation combined with stochastic policies is a natural extension of existing graph-based MARL methods and could improve robustness in heterogeneous or dynamic environments such as traffic networks.
major comments (2)
- [Experiments] Experiments section: the headline claim of outperformance on traffic tasks with up to 167 agents is load-bearing for the paper's contribution, yet the abstract (and by extension the experimental reporting) supplies no details on the specific baselines, metrics (e.g., average travel time, throughput), number of independent runs, variance, or statistical tests. Without these, it is impossible to assess whether the reported gains are attributable to the learned masks rather than simulator-specific artifacts or implementation choices.
- [§3 (Method)] §3 (Method) and ELBO derivation: the variational distribution q(z | local obs) is trained end-to-end in a fully decentralized manner over a static physical graph. The manuscript does not provide analysis or ablations demonstrating that the resulting masks remain consistent across agents or capture globally relevant edges rather than being biased by the mean-field approximation and local-only observations. This assumption is load-bearing for the claim that the inferred structures improve message passing without introducing significant bias into the policy gradients.
minor comments (2)
- [Notation] Clarify in the notation section how the sampled mask is exactly multiplied into the message-passing update and whether the physical neighborhood is strictly enforced or can be overridden.
- [Related Work] Add a short paragraph in Related Work contrasting BayesG with prior centralized graph-learning MARL methods and with other variational approaches in multi-agent RL.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment below and describe the revisions we will make to improve clarity and strengthen the empirical and methodological claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the headline claim of outperformance on traffic tasks with up to 167 agents is load-bearing for the paper's contribution, yet the abstract (and by extension the experimental reporting) supplies no details on the specific baselines, metrics (e.g., average travel time, throughput), number of independent runs, variance, or statistical tests. Without these, it is impossible to assess whether the reported gains are attributable to the learned masks rather than simulator-specific artifacts or implementation choices.
Authors: We agree that the abstract is too concise and does not convey the necessary experimental details. The full experimental section reports results on average travel time and throughput, using baselines including MADDPG, QMIX, and several graph-based MARL methods. All results are averaged over five independent random seeds with standard deviations shown, and statistical significance is assessed via paired t-tests. We will revise the abstract to explicitly mention the primary metrics, number of runs, and key baselines. We will also add a short paragraph in the experimental section summarizing the evaluation protocol to make these elements immediately accessible. revision: yes
-
Referee: [§3 (Method)] §3 (Method) and ELBO derivation: the variational distribution q(z | local obs) is trained end-to-end in a fully decentralized manner over a static physical graph. The manuscript does not provide analysis or ablations demonstrating that the resulting masks remain consistent across agents or capture globally relevant edges rather than being biased by the mean-field approximation and local-only observations. This assumption is load-bearing for the claim that the inferred structures improve message passing without introducing significant bias into the policy gradients.
Authors: We acknowledge that additional analysis of the learned masks would strengthen the paper. The current manuscript already contains ablation studies that isolate the contribution of the learned stochastic masks versus fixed neighborhoods, together with qualitative visualizations of sampled ego-graphs on the traffic network. Because the method is strictly decentralized, direct verification of global edge consistency is not possible without violating the problem setting. In the revision we will add a dedicated discussion subsection addressing potential biases arising from local observations and the mean-field variational approximation. We will also include new quantitative experiments on smaller synthetic networks where centralized ground-truth comparisons are feasible, to quantify any systematic deviation from globally optimal edges. revision: partial
Circularity Check
No significant circularity; standard ELBO applied to new ego-graph policy structure
full rationale
The paper's core derivation introduces a stochastic graph-based policy where agents sample latent communication masks from a variational distribution q(z | local obs) over their ego-graph neighborhood, then optimizes this jointly with the policy via the standard ELBO objective. This is a direct, non-circular application of variational inference to the decentralized MARL setting; the ELBO is not redefined in terms of the target performance metric, nor is any fitted parameter renamed as a prediction. No self-citation chains, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing. Empirical outperformance on traffic control tasks (up to 167 agents) is presented as an external validation rather than a quantity forced by construction from the inputs. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- variational distribution parameters
axioms (2)
- domain assumption Agents operate under local observability and constrained communication over fixed physical graphs.
- standard math The evidence lower bound provides a tractable objective for joint optimization of topology and policy.
invented entities (1)
-
latent communication mask
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate latent graph learning as Bayesian variational inference, treating edge masks as posterior distributions... q(Zi;ϕi) = ∏j∈Ni Bern(zij;σ(ϕij))... LELBO = Eq[−Lθ,φ + log p(Zi) − log q(Zi;ϕi)]
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Each agent operates over an ego-graph and samples a latent communication mask to guide message passing
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zhou, M., J. Luo, J. Villela, et al. SMARTS: an open-source scalable multi-agent RL training school for autonomous driving. In4th Conference on Robot Learning, CoRL 2020, 16-18 November 2020, Virtual Event / Cambridge, MA, USA, vol. 155 ofProceedings of Machine Learning Research, pages 264–285. PMLR, 2020
work page 2020
-
[2]
Yeh, J., V . Soo. Toward socially friendly autonomous driving using multi-agent deep reinforce- ment learning. InProceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, (AAMAS 2024), Auckland, New Zealand, May 6-10, pages 2573–2575. 2024
work page 2024
-
[3]
Naderializadeh, N., J. J. Sydir, M. Simsek, et al. Resource management in wireless networks via multi-agent deep reinforcement learning.IEEE Trans. Wirel. Commun., 20(6):3507–3523, 2021
work page 2021
-
[4]
Lv, Z., L. Xiao, Y . Du, et al. Efficient communications in multi-agent reinforcement learning for mobile applications.IEEE Trans. Wirel. Commun., 23(9):12440–12454, 2024
work page 2024
- [5]
-
[6]
Shao, J., Z. Lou, H. Zhang, et al. Self-organized group for cooperative multi-agent reinforcement learning. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems, (NIPS 2022), November 28 - December 9, New Orleans, LA, USA. 2022
work page 2022
-
[7]
Chu, T., S. Chinchali, S. Katti. Multi-agent reinforcement learning for networked system control. In8th International Conference on Learning Representations, (ICLR 2020), Addis Ababa, Ethiopia, April 26-30. 2020
work page 2020
-
[8]
Zhang, Y ., Y . Zhou, H. Fujita. Distributed multi-agent reinforcement learning for cooperative low-carbon control of traffic network flow using cloud-based parallel optimization.IEEE Trans. Intell. Transp. Syst., 25(12):20715–20728, 2024
work page 2024
-
[9]
Rashid, T., M. Samvelyan, C. S. de Witt, et al. QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning. InProceedings of the 35th International Conference on Machine Learning (ICML 2018), Stockholmsmässan, Stockholm, Sweden, vol. 80, pages 4292–4301. 2018
work page 2018
-
[10]
Wang, T., H. Dong, V . R. Lesser, et al. ROMA: multi-agent reinforcement learning with emergent roles. InProceedings of the 37th International Conference on Machine Learning (ICML 2020), Virtual Event, vol. 119 ofProceedings of Machine Learning Research, pages 9876–9886. 2020
work page 2020
-
[11]
Wang, J., Z. Ren, T. Liu, et al. QPLEX: duplex dueling multi-agent q-learning. In9th International Conference on Learning Representations (ICLR 2021), Virtual Event, Austria. 2021
work page 2021
-
[12]
Lowe, R., Y . Wu, A. Tamar, et al. Multi-agent actor-critic for mixed cooperative-competitive environments. InAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, pages 6379–6390. 2017
work page 2017
-
[13]
Liu, Y ., W. Wang, Y . Hu, et al. Multi-agent game abstraction via graph attention neural network. InThe Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI 2020), New York, NY, USA,, pages 7211–7218. AAAI Press, 2020. 11
work page 2020
-
[14]
Wang, T., L. Zeng, W. Dong, et al. Context-aware sparse deep coordination graphs. In The Tenth International Conference on Learning Representations (ICLR 2022), Virtual Event. OpenReview.net, 2022
work page 2022
-
[15]
Zhang, K., Z. Yang, H. Liu, et al. Fully decentralized multi-agent reinforcement learning with networked agents. InProceedings of the 35th International Conference on Machine Learn- ing,(ICML 2018), Stockholmsmässan, Stockholm, Sweden, July 10-15, vol. 80 ofProceedings of Machine Learning Research, pages 5867–5876. PMLR, 2018
work page 2018
-
[16]
Qu, G., A. Wierman, N. Li. Scalable reinforcement learning of localized policies for multi-agent networked systems. InProceedings of the 2nd Annual Conference on Learning for Dynamics and Control (L4DC 2020), Online Event, Berkeley, CA, USA, 11-12 June, vol. 120, pages 256–266. PMLR, 2020
work page 2020
-
[17]
Chu, T., J. Wang, L. Codecà, et al. Multi-agent deep reinforcement learning for large-scale traffic signal control.IEEE Trans. Intell. Transp. Syst., 21(3):1086–1095, 2020
work page 2020
-
[18]
Yi, Y ., G. Li, Y . Wang, et al. Learning to share in networked multi-agent reinforcement learning. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems, ( NIPS 2022), New Orleans, LA, USA, November 28 - December 9. 2022
work page 2022
-
[19]
Du, Y ., B. Liu, V . Moens, et al. Learning correlated communication topology in multi-agent reinforcement learning. In20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2021), May 3-7„ Virtual Event, United Kingdom, pages 456–464. 2021
work page 2021
-
[20]
Duan, W., J. Lu, J. Xuan. Inferring latent temporal sparse coordination graph for multiagent reinforcement learning.IEEE Trans. Neural Networks Learn. Syst., pages 1–13, 2024
work page 2024
-
[21]
Duan, W., J. Lu, J. Xuan. Group-aware coordination graph for multi-agent reinforcement learning. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, (IJCAI 2024), Jeju, South Korea, August 3-9, 2024, pages 3926–3934. 2024
work page 2024
-
[22]
Lin, Y ., G. Qu, L. Huang, et al. Multi-agent reinforcement learning in stochastic networked systems. InAdvances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems (NeurIPS 2021), December 6-14, virtual, pages 7825–7837. 2021
work page 2021
-
[23]
Du, Y ., C. Ma, Y . Liu, et al. Scalable model-based policy optimization for decentralized networked systems. InIEEE/RSJ International Conference on Intelligent Robots and Systems, (IROS 2022), Kyoto, Japan, October 23-27, pages 9019–9026. IEEE, 2022
work page 2022
-
[24]
Ma, C., A. Li, Y . Du, et al. Efficient and scalable reinforcement learning for large-scale network control.Nature Machine Intelligence, 6(9):1006–1020, 2024
work page 2024
-
[25]
Qu, G., Y . Lin, A. Wierman, et al. Scalable multi-agent reinforcement learning for networked systems with average reward. InAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual. 2020
work page 2020
- [26]
-
[27]
Jiang, J., C. Dun, T. Huang, et al. Graph convolutional reinforcement learning. In8th Interna- tional Conference on Learning Representations, (ICLR 2020), Addis Ababa, Ethiopia, April 26-30. OpenReview.net, 2020
work page 2020
-
[28]
Li, S., J. K. Gupta, P. Morales, et al. Deep implicit coordination graphs for multi-agent reinforcement learning. InAAMAS ’21: 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2021), Virtual Event, United Kingdom, pages 764–772. ACM, 2021. 12
work page 2021
-
[29]
Lin, B., C. Lee. HGAP: boosting permutation invariant and permutation equivariant in multi- agent reinforcement learning via graph attention network. InForty-first International Conference on Machine Learning (ICML 2024), Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024
work page 2024
-
[30]
Duan, W., J. Xuan, M. Qiao, et al. Graph convolutional neural networks with diverse negative samples via decomposed determinant point processes.IEEE Transactions on Neural Networks and Learning Systems, 35(12):18160–18171, 2024
work page 2024
-
[31]
Duan, W., J. Lu, Y . G. Wang, et al. Layer-diverse negative sampling for graph neural networks. Trans. Mach. Learn. Res., 2024, 2024
work page 2024
- [32]
-
[33]
Yang, Q., W. Dong, Z. Ren, et al. Self-organized polynomial-time coordination graphs. In International Conference on Machine Learning (ICML 2022), Baltimore, Maryland, USA, vol. 162, pages 24963–24979. 2022
work page 2022
-
[34]
Jang, E., S. Gu, B. Poole. Categorical reparameterization with gumbel-softmax. Inthe 5th International Conference on Learning Representations (ICLR 2017), Toulon, France. 2017
work page 2017
-
[35]
Maddison, C. J., A. Mnih, Y . W. Teh. The concrete distribution: A continuous relaxation of discrete random variables. Inthe 5th International Conference on Learning Representations (ICLR 2017),Toulon, France. 2017
work page 2017
-
[36]
Haarnoja, T., A. Zhou, P. Abbeel, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InProceedings of the 35th International Conference on Machine Learning, (ICML 2018), Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, vol. 80 ofProceedings of Machine Learning Research, pages 1856–1865
work page 2018
-
[37]
Lopez, P. A., M. Behrisch, L. Bieker-Walz, et al. Microscopic traffic simulation using sumo. In The 21st IEEE International Conference on Intelligent Transportation Systems. IEEE, 2018
work page 2018
-
[38]
Foerster, J. N., N. Nardelli, G. Farquhar, et al. Stabilising experience replay for deep multi- agent reinforcement learning. InProceedings of the 34th International Conference on Machine Learning, (ICML 2017), Sydney, NSW, Australia, 6-11 August, vol. 70, pages 1146–1155. PMLR, 2017
work page 2017
- [39]
-
[40]
Foerster, J. N., Y . M. Assael, N. de Freitas, et al. Learning to communicate with deep multi-agent reinforcement learning. InAdvances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, pages 2137–2145. 2016
work page 2016
-
[41]
Kipf, T. N., M. Welling. Semi-supervised classification with graph convolutional networks. In 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, April 24-26. 2017
work page 2017
- [42]
-
[43]
Yu, E., J. Lu, X. Yang, et al. Learning robust spectral dynamics for temporal domain gener- alization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS 2025). 2025
work page 2025
-
[44]
Yang, X., J. Lu, E. Yu. Walking the tightrope: Disentangling beneficial and detrimental drifts in non-stationary custom-tuning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. 2025. 13 Appendix A Detailed Derivation A.1 Derivation of Graph-based Policy We expand on Definition 3, which defines each agent's policy as a two-sta...
work page 2025
-
[45]
Likelihood Term:logp(D i |Z i) This is modeled using the graph-conditioned policy loss, i.e., logp(D i |Z i)≈ −L θ,φ,(27) whereL θ,φ is the actor loss under sampled subgraphZ i ⊙G env Vi
-
[46]
Prior Term:logp(Z i) We define the prior as an element-wise Bernoulli with retention biasλ: p(Zi) = Y j∈Ni λzij(1−λ) 1−zij .(28) 15 Then: logp(Z i) = X j∈Ni zij logλ+ (1−z ij) log(1−λ).(29) Taking expectation underq(Z i): Eq[logp(Z i)] = X j∈Ni [σ(ϕij) logλ+ (1−σ(ϕ ij)) log(1−λ)].(30)
-
[47]
Entropy Term:−logq(Z i;ϕ i) Sinceq(Z i)is a factorized Bernoulli: H(q(Z ij)) =−σ(ϕ ij) logσ(ϕ ij)−(1−σ(ϕ ij)) log(1−σ(ϕ ij)).(31) Then: Eq[logq(Z i)] =− X j∈Ni H(q(Z ij)).(32) Final Objective Combining all terms: LELBO =E q(Zi;ϕi) [−Lθ,φ] + X j∈Ni [λlogσ(ϕ ij) + (1−λ) log(1−σ(ϕ ij))]− X j∈Ni H(q(Z ij)) =E q(Zi;ϕi) [−Lθ,φ] + X j∈Ni [λlogσ(ϕ ij) + (1−λ) log...
-
[48]
Localized dynamics.Traffic flow is governed by physical proximity: upstream intersections release vehicles that propagate to downstream intersections. Each agent’s state evolution depends on its immediate neighbors’ actions, not the global joint action of all agents
-
[49]
Fixed physical topology.The road network structure is fixed and sparse, with agents (intersections) only interacting with directly connected neighbors via shared road segments
-
[50]
Decentralized execution requirement.In real-world deployments, traffic signals operate inde- pendently with limited communication bandwidth. Centralized control is impractical due to: • Scalability: City-scale networks have hundreds of intersections; centralized joint action spaces grow exponentially • Communication constraints: Real-time global state agg...
-
[51]
Local observability.Each intersection has sensors only for its incoming lanes, consistent with the partial observability assumption in Spatiotemporal-MDP. These properties make ATSC fundamentally different from cooperative benchmarks (e.g., Star- Craft) that assume global rewards, unrestricted communication, and arbitrary coordination graphs. Our method e...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.