boldsymbol{λ}-Orthogonality Regularization for Compatible Representation Learning
Pith reviewed 2026-05-21 22:18 UTC · model grok-4.3
The pith
Imposing λ-orthogonality regularization on affine transformations allows distribution-specific adaptation while preserving original representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
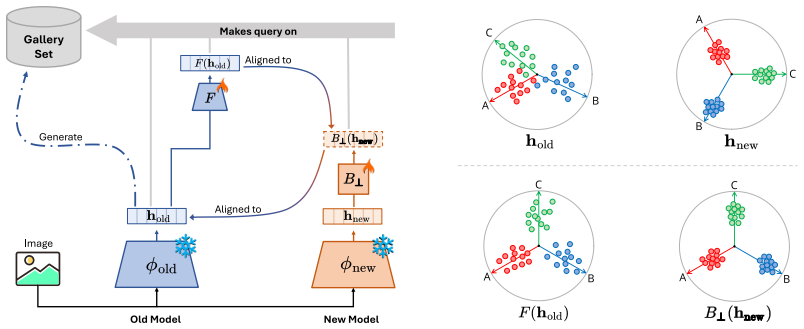
The central discovery is that a λ-orthogonality regularization, which relaxes the strict orthogonality constraint, when applied while learning an affine transformation, permits adaptation of the latent space to downstream distributions while keeping the original learned representations intact. This resolves the trade-off between adaptability and preservation in making updated models compatible with previous ones.
What carries the argument
The λ-orthogonality regularization, a parameterized relaxed orthogonality constraint on the transformation matrix, that controls how much the affine map deviates from orthogonality to achieve the desired adaptation-preservation trade-off.
Load-bearing premise
A single fixed scalar λ suffices to balance the adaptation and preservation for any downstream distribution and architecture without needing retuning per update.
What would settle it
A counterexample where, for a given model update and target distribution, varying λ either fails to achieve sufficient compatibility or causes a measurable drop in zero-shot accuracy compared to the original model.
Figures





read the original abstract
Retrieval systems rely on representations learned by increasingly powerful models. However, due to the high training cost and inconsistencies in learned representations, there is significant interest in facilitating communication between representations and ensuring compatibility across independently trained neural networks. In the literature, two primary approaches are commonly used to adapt different learned representations: affine transformations, which adapt well to specific distributions but can significantly alter the original representation, and orthogonal transformations, which preserve the original structure with strict geometric constraints but limit adaptability. A key challenge is adapting the latent spaces of updated models to align with those of previous models on downstream distributions while preserving the newly learned representation spaces. In this paper, we impose a relaxed orthogonality constraint, namely $\lambda$-Orthogonality regularization, while learning an affine transformation, to obtain distribution-specific adaptation while retaining the original learned representations. Extensive experiments across various architectures and datasets validate our approach, demonstrating that it preserves the model's zero-shot performance and ensures compatibility across model updates. Code available at: \href{https://github.com/miccunifi/lambda_orthogonality.git}{https://github.com/miccunifi/lambda\_orthogonality}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes λ-Orthogonality regularization, a relaxed form of orthogonality constraint imposed while learning an affine transformation, to adapt representations to downstream distributions for compatibility across model updates while preserving the original model's zero-shot performance and geometric structure. Experiments across architectures and datasets are reported to validate that the approach maintains compatibility without significant degradation in zero-shot capabilities.
Significance. If the central claim holds with a fixed or simply selectable λ, the method would offer a practical, low-overhead solution to the compatibility problem in evolving retrieval systems that rely on independently trained or updated models. This could reduce the need for full retraining or strict orthogonal constraints that limit adaptability, with potential impact on production pipelines where representation drift is common.
major comments (2)
- [Experiments] The central claim that a single scalar λ (or simple selection rule) suffices to balance adaptation and zero-shot preservation across arbitrary distribution shifts and architectures is load-bearing but only partially supported. The experiments section reports positive results but provides no details on the λ selection procedure, sensitivity analysis across shift magnitudes, or failure cases where the balance breaks.
- [Method] §3 (Method): the formulation of the λ-Orthogonality regularization term applied to the learned affine matrix must be shown to avoid implicit per-update hyperparameter search; otherwise the compatibility-without-retuning promise reduces to standard affine adaptation plus tuning.
minor comments (2)
- [Method] Clarify notation for the affine matrix and the exact loss combining the regularization with any adaptation objective; current description in the abstract and method is high-level.
- [Experiments] Add statistical significance or variance across runs in the results tables to strengthen the cross-architecture claims.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential practical impact of λ-Orthogonality regularization. We address each major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [Experiments] The central claim that a single scalar λ (or simple selection rule) suffices to balance adaptation and zero-shot preservation across arbitrary distribution shifts and architectures is load-bearing but only partially supported. The experiments section reports positive results but provides no details on the λ selection procedure, sensitivity analysis across shift magnitudes, or failure cases where the balance breaks.
Authors: We acknowledge that the experiments would benefit from explicit details on λ selection and broader analysis. In the revised manuscript we will add a dedicated paragraph describing the λ selection procedure (a fixed scalar chosen once via a small validation set to achieve a target trade-off between adaptation and zero-shot retention). We will also include sensitivity plots across a range of λ values and shift magnitudes, together with a brief discussion of observed robustness limits. These additions directly address the load-bearing claim while remaining consistent with the existing experimental results. revision: yes
-
Referee: [Method] §3 (Method): the formulation of the λ-Orthogonality regularization term applied to the learned affine matrix must be shown to avoid implicit per-update hyperparameter search; otherwise the compatibility-without-retuning promise reduces to standard affine adaptation plus tuning.
Authors: The λ-Orthogonality term is defined with λ as a single fixed scalar that is chosen once for a given adaptation scenario and then held constant during optimization of the affine matrix. No per-update search is performed; the regularization is applied in a single optimization pass. We will revise §3 to state this explicitly, include the precise mathematical expression of the regularizer, and clarify that λ is not re-tuned for subsequent model updates, thereby preserving the claimed compatibility-without-retuning property. revision: yes
Circularity Check
λ-Orthogonality is a newly defined regularization term with no reduction to fitted inputs or self-citation loops
full rationale
The paper introduces λ-Orthogonality regularization as a relaxed constraint on an affine transformation matrix, explicitly parameterized by a scalar λ to trade off distribution-specific adaptation against preservation of the original representation. This definition stands as an independent proposal rather than deriving from or collapsing into previously fitted parameters, prior results, or self-citations by construction. Experiments across architectures and datasets provide external validation instead of relying on internal reduction. A minor self-citation may exist in the literature review but is not load-bearing for the central claim, keeping overall circularity low.
Axiom & Free-Parameter Ledger
free parameters (1)
- λ
axioms (1)
- domain assumption Orthogonal transformations preserve distances and angles in the representation space
invented entities (1)
-
λ-Orthogonality regularization
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Facenet: A unified embedding for face recognition and clustering
Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clustering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 815–823, 2015
work page 2015
-
[2]
Sphereface: Deep hypersphere embedding for face recognition
Weiyang Liu, Yandong Wen, Zhiding Yu, Ming Li, Bhiksha Raj, and Le Song. Sphereface: Deep hypersphere embedding for face recognition. In2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pages 6738–6746. IEEE Computer Society, 2017
work page 2017
-
[3]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4690–4699, 2019
work page 2019
-
[4]
Netvlad: Cnn architecture for weakly supervised place recognition
Relja Arandjelovic, Petr Gronat, Akihiko Torii, Tomas Pajdla, and Josef Sivic. Netvlad: Cnn architecture for weakly supervised place recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5297–5307, 2016
work page 2016
-
[5]
Unifying deep local and global features for image search
Bingyi Cao, Andre Araujo, and Jack Sim. Unifying deep local and global features for image search. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XX 16, pages 726–743. Springer, 2020
work page 2020
-
[6]
Patch-netvlad: Multi-scale fusion of locally-global descriptors for place recognition
Stephen Hausler, Sourav Garg, Ming Xu, Michael Milford, and Tobias Fischer. Patch-netvlad: Multi-scale fusion of locally-global descriptors for place recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14141–14152, 2021
work page 2021
-
[7]
Large-scale image retrieval with attentive deep local features
Hyeonwoo Noh, Andre Araujo, Jack Sim, Tobias Weyand, and Bohyung Han. Large-scale image retrieval with attentive deep local features. InProceedings of the IEEE international conference on computer vision, pages 3456–3465, 2017. 10
work page 2017
-
[8]
Instance-level image retrieval using reranking transform- ers
Fuwen Tan, Jiangbo Yuan, and Vicente Ordonez. Instance-level image retrieval using reranking transform- ers. Inproceedings of the IEEE/CVF international conference on computer vision, pages 12105–12115, 2021
work page 2021
-
[9]
Universal instance perception as object discovery and retrieval
Bin Yan, Yi Jiang, Jiannan Wu, Dong Wang, Ping Luo, Zehuan Yuan, and Huchuan Lu. Universal instance perception as object discovery and retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15325–15336, 2023
work page 2023
-
[10]
Building machine learning models like open source software.Commun
Colin Raffel. Building machine learning models like open source software.Commun. ACM, 66(2):38–40, jan 2023
work page 2023
-
[11]
Prateek Yadav, Colin Raffel, Mohammed Muqeeth, Lucas Caccia, Haokun Liu, Tianlong Chen, Mohit Bansal, Leshem Choshen, and Alessandro Sordoni. A survey on model moerging: Recycling and routing among specialized experts for collaborative learning.Trans. Mach. Learn. Res., 2025
work page 2025
-
[12]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Niccolò Biondi, Federico Pernici, Simone Ricci, and Alberto Del Bimbo. Stationary representations: Optimally approximating compatibility and implications for improved model replacements. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[14]
MUSCLE: A model update strategy for compatible LLM evolution
Jessica Maria Echterhoff, Fartash Faghri, Raviteja Vemulapalli, Ting-Yao Hu, Chun-Liang Li, Oncel Tuzel, and Hadi Pouransari. MUSCLE: A model update strategy for compatible LLM evolution. InEMNLP (Findings), pages 7320–7332. Association for Computational Linguistics, 2024
work page 2024
-
[15]
Towards backward-compatible representation learning
Yantao Shen, Yuanjun Xiong, Wei Xia, and Stefano Soatto. Towards backward-compatible representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6368–6377, 2020
work page 2020
-
[16]
Yixuan Li, Jason Yosinski, Jeff Clune, Hod Lipson, and John Hopcroft. Convergent learning: Do different neural networks learn the same representations? In Yoshua Bengio and Yann LeCun, editors,Feature Extraction: Modern Questions and Challenges, pages 196–212. PMLR, 2015
work page 2015
-
[17]
Positive-congruent training: Towards regression-free model updates
Sijie Yan, Yuanjun Xiong, Kaustav Kundu, Shuo Yang, Siqi Deng, Meng Wang, Wei Xia, and Stefano Soatto. Positive-congruent training: Towards regression-free model updates. InCVPR, pages 14299–14308. Computer Vision Foundation / IEEE, 2021
work page 2021
-
[18]
Niccolo Biondi, Federico Pernici, Matteo Bruni, and Alberto Del Bimbo. Cores: Compatible represen- tations via stationarity.IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–16, 2023
work page 2023
-
[19]
Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, et al. Model soups: aver- aging weights of multiple fine-tuned models improves accuracy without increasing inference time. In International conference on machine learning, pages 23965–23998...
work page 2022
-
[20]
Towards universal backward-compatible representation learning
Binjie Zhang, Yixiao Ge, Yantao Shen, Shupeng Su, Fanzi Wu, Chun Yuan, Xuyuan Xu, Yexin Wang, and Ying Shan. Towards universal backward-compatible representation learning. InIJCAI, pages 1615–1621. ijcai.org, 2022
work page 2022
-
[21]
Learning compatible embeddings
Qiang Meng, Chixiang Zhang, Xiaoqiang Xu, and Feng Zhou. Learning compatible embeddings. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9939–9948, October 2021
work page 2021
-
[22]
Fastfill: Efficient compatible model update
Florian Jaeckle, Fartash Faghri, Ali Farhadi, Oncel Tuzel, and Hadi Pouransari. Fastfill: Efficient compatible model update. InInternational Conference on Learning Representations, 2023
work page 2023
-
[23]
Btˆ 2: Backward-compatible training with basis transformation
Yifei Zhou, Zilu Li, Abhinav Shrivastava, Hengshuang Zhao, Antonio Torralba, Taipeng Tian, and Ser-Nam Lim. Btˆ 2: Backward-compatible training with basis transformation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11229–11238, 2023
work page 2023
-
[24]
Backward-compatible aligned representations via an orthogonal transformation layer
Simone Ricci, Niccolò Biondi, Federico Pernici, and Alberto Del Bimbo. Backward-compatible aligned representations via an orthogonal transformation layer. InECCV Workshops (17), volume 15639 ofLecture Notes in Computer Science, pages 451–464. Springer, 2024. 11
work page 2024
-
[25]
For- ward compatible training for large-scale embedding retrieval systems
Vivek Ramanujan, Pavan Kumar Anasosalu Vasu, Ali Farhadi, Oncel Tuzel, and Hadi Pouransari. For- ward compatible training for large-scale embedding retrieval systems. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19386–19395, 2022
work page 2022
-
[26]
Testing the manifold hypothesis.Journal of the American Mathematical Society, 29(4):983–1049, 2016
Charles Fefferman, Sanjoy Mitter, and Hariharan Narayanan. Testing the manifold hypothesis.Journal of the American Mathematical Society, 29(4):983–1049, 2016
work page 2016
-
[27]
Position: The platonic representation hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. Position: The platonic representation hypothesis. InICML. OpenReview.net, 2024
work page 2024
-
[28]
Valentino Maiorca, Luca Moschella, Antonio Norelli, Marco Fumero, Francesco Locatello, and Emanuele Rodolà. Latent space translation via semantic alignment.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[29]
Latent functional maps: a spectral framework for representation alignment
Marco Fumero, Marco Pegoraro, Valentino Maiorca, Francesco Locatello, and Emanuele Rodolà. Latent functional maps: a spectral framework for representation alignment. InNeurIPS, 2024
work page 2024
-
[30]
Relative representations enable zero-shot latent space communication
Luca Moschella, Valentino Maiorca, Marco Fumero, Antonio Norelli, Francesco Locatello, and Emanuele Rodolà. Relative representations enable zero-shot latent space communication. InInternational Conference on Learning Representations, 2023
work page 2023
-
[31]
Latent space translation via inverse relative projection.arXiv preprint arXiv:2406.15057, 2024
Valentino Maiorca, Luca Moschella, Marco Fumero, Francesco Locatello, and Emanuele Rodolà. Latent space translation via inverse relative projection.arXiv preprint arXiv:2406.15057, 2024
-
[32]
Martial Mermillod, Aurélia Bugaiska, and Patrick Bonin. The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects, 2013
work page 2013
-
[33]
Towards better plasticity-stability trade-off in incremental learning: A simple linear connector
Guoliang Lin, Hanlu Chu, and Hanjiang Lai. Towards better plasticity-stability trade-off in incremental learning: A simple linear connector. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 89–98, 2022
work page 2022
-
[34]
On the stability-plasticity dilemma of class-incremental learning
Dongwan Kim and Bohyung Han. On the stability-plasticity dilemma of class-incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20196– 20204, 2023
work page 2023
-
[35]
Generalized clustering and multi-manifold learning with geometric structure preservation
Lirong Wu, Zicheng Liu, Jun Xia, Zelin Zang, Siyuan Li, and Stan Z Li. Generalized clustering and multi-manifold learning with geometric structure preservation. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 139–147, 2022
work page 2022
-
[36]
Nitin Bansal, Xiaohan Chen, and Zhangyang Wang. Can we gain more from orthogonality regularizations in training deep networks?Advances in Neural Information Processing Systems, 31, 2018
work page 2018
-
[37]
Hot-refresh model upgrades with regression-free compatible training in image retrieval
Binjie Zhang, Yixiao Ge, Yantao Shen, Yu Li, Chun Yuan, XUYUAN XU, Yexin Wang, and Ying Shan. Hot-refresh model upgrades with regression-free compatible training in image retrieval. InInternational Conference on Learning Representations, 2021
work page 2021
-
[38]
Boundary-aware backward-compatible representation via adversarial learning in image retrieval
Tan Pan, Furong Xu, Xudong Yang, Sifeng He, Chen Jiang, Qingpei Guo, Feng Qian, Xiaobo Zhang, Yuan Cheng, Lei Yang, et al. Boundary-aware backward-compatible representation via adversarial learning in image retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15201–15210, 2023
work page 2023
-
[39]
Asymmetric metric learning for knowledge transfer
Mateusz Budnik and Yannis Avrithis. Asymmetric metric learning for knowledge transfer. InCVPR, pages 8228–8238. Computer Vision Foundation / IEEE, 2021
work page 2021
-
[40]
Niccolo Biondi, Federico Pernici, Matteo Bruni, Daniele Mugnai, and Alberto Del Bimbo. Cl2r: Compati- ble lifelong learning representations.ACM Transactions on Multimedia Computing, Communications and Applications, 18(2s):1–22, 2023
work page 2023
-
[41]
Memory-efficient incremental learning through feature adaptation
Ahmet Iscen, Jeffrey Zhang, Svetlana Lazebnik, and Cordelia Schmid. Memory-efficient incremental learning through feature adaptation. InEuropean Conference on Computer Vision, pages 699–715. Springer, 2020
work page 2020
-
[42]
Unified representation learning for cross model compatibility
Chien-Yi Wang, Ya-Liang Chang, Shang-Ta Yang, Dong Chen, and Shang-Hong Lai. Unified representation learning for cross model compatibility. In31st British Machine Vision Conference 2020, BMVC 2020. BMV A Press, 2020
work page 2020
-
[43]
Shupeng Su, Binjie Zhang, Yixiao Ge, Xuyuan Xu, Yexin Wang, Chun Yuan, and Ying Shan. Privacy- preserving model upgrades with bidirectional compatible training in image retrieval.arXiv preprint arXiv:2204.13919, 2022. 12
-
[44]
Manifold alignment using procrustes analysis
Chang Wang and Sridhar Mahadevan. Manifold alignment using procrustes analysis. InProceedings of the 25th international conference on Machine learning, pages 1120–1127, 2008
work page 2008
-
[45]
Mario Lezcano-Casado and David Martınez-Rubio. Cheap orthogonal constraints in neural networks: A simple parametrization of the orthogonal and unitary group. InInternational Conference on Machine Learning, pages 3794–3803. PMLR, 2019
work page 2019
-
[46]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
work page 2017
-
[47]
Measuring catastrophic forgetting in neural networks
Ronald Kemker, Marc McClure, Angelina Abitino, Tyler Hayes, and Christopher Kanan. Measuring catastrophic forgetting in neural networks. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[48]
Generalized BackPropagation, \'{E}tude De Cas: Orthogonality
Mehrtash Harandi and Basura Fernando. Generalized backpropagation, etude de cas: Orthogonality.arXiv preprint arXiv:1611.05927, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[49]
Optimization on Submanifolds of Convolution Kernels in CNNs
Mete Ozay and Takayuki Okatani. Optimization on submanifolds of convolution kernels in cnns.arXiv preprint arXiv:1610.07008, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[50]
Lei Huang, Xianglong Liu, Bo Lang, Adams Yu, Yongliang Wang, and Bo Li. Orthogonal weight normalization: Solution to optimization over multiple dependent stiefel manifolds in deep neural networks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018
work page 2018
-
[51]
US Government printing office, 1968
Milton Abramowitz and Irene A Stegun.Handbook of mathematical functions with formulas, graphs, and mathematical tables, volume 55. US Government printing office, 1968
work page 1968
-
[52]
Activation functions in neural networks.Towards Data Sci, 6(12):310–316, 2017
Sagar Sharma, Simone Sharma, and Anidhya Athaiya. Activation functions in neural networks.Towards Data Sci, 6(12):310–316, 2017
work page 2017
-
[53]
A Iliev, Nikolay Kyurkchiev, and Svetoslav Markov. On the approximation of the step function by some sigmoid functions.Mathematics and Computers in Simulation, 133:223–234, 2017
work page 2017
-
[54]
Yonglong Tian, Lijie Fan, Phillip Isola, Huiwen Chang, and Dilip Krishnan. Stablerep: Synthetic images from text-to-image models make strong visual representation learners.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[55]
Hierarchy-based image embeddings for semantic image retrieval
Björn Barz and Joachim Denzler. Hierarchy-based image embeddings for semantic image retrieval. In 2019 IEEE winter conference on applications of computer vision (WACV), pages 638–647. IEEE, 2019
work page 2019
-
[56]
On the unreasonable effectiveness of centroids in image retrieval
Mikolaj Wieczorek, Barbara Rychalska, and Jacek Dabrowski. On the unreasonable effectiveness of centroids in image retrieval. InNeural Information Processing: 28th International Conference, ICONIP 2021, Sanur, Bali, Indonesia, December 8–12, 2021, Proceedings, Part IV 28, pages 212–223. Springer, 2021
work page 2021
-
[57]
Imagenet large scale visual recognition challenge
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015
work page 2015
-
[58]
A. Krizhevsky. Learning Multiple Layers of Features from Tiny Images. Technical report, Univ. Toronto, 2009
work page 2009
-
[59]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011
work page 2011
-
[60]
Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017
work page 2017
-
[61]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In9th International Conference on Learning Representations, ICLR 2021, V...
work page 2021
-
[62]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 13
work page 2021
-
[63]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research
-
[64]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In2008 Sixth Indian conference on computer vision, graphics & image processing, pages 722–729. IEEE, 2008
work page 2008
-
[65]
Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3558–3568, 2021
work page 2021
-
[66]
Marco Mistretta, Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Andrew D. Bagdanov. Cross the gap: Exposing the intra-modal misalignment in CLIP via modality inversion. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. Open- Review.net, 2025
work page 2025
-
[67]
C-clip: Multimodal continual learning for vision- language model
Wenzhuo Liu, Fei Zhu, Longhui Wei, and Qi Tian. C-clip: Multimodal continual learning for vision- language model. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[68]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[69]
Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. Deep double descent: Where bigger models and more data hurt.Journal of Statistical Mechanics: Theory and Experiment, 2021(12):124003, 2021
work page 2021
-
[70]
Gabriele Prato, Simon Guiroy, Ethan Caballero, Irina Rish, and Sarath Chandar. Scaling laws for the out- of-distribution generalization of image classifiers.ICML 2021 Workshop on Uncertainty and Robustness in Deep Learning., 2021
work page 2021
-
[71]
Ethan Caballero, Kshitij Gupta, Irina Rish, and David Krueger. Broken neural scaling laws. InThe Eleventh International Conference on Learning Representations, 2023. 14 Table 5: Compatibility evaluation on Places365 under the Extending Classes setting. We use two independently trained ResNet-50 models: ϕold trained on the first 205 classes, and ϕnew train...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.