An Improved Yau-Yau Algorithm for High Dimensional Nonlinear Filtering Problems
Pith reviewed 2026-05-18 15:18 UTC · model grok-4.3
The pith
An improved Yau-Yau algorithm delivers accurate nonlinear filtering for systems with up to 1000 state dimensions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that integrating quasi-Monte Carlo low-discrepancy sampling, a novel offline-online scheme, high-order multi-scale kernel approximations, fully log-domain likelihood evaluation, and a local resampling-restart step produces a Yau-Yau-type filter whose local truncation error is O(Δt² + D*(n)) and global error is O(Δt + D*(n)/Δt), where Δt is the time step and D*(n) is the star discrepancy of the chosen points, thereby extending accurate real-time nonlinear filtering to systems with thousands of dimensions.
What carries the argument
The improved Yau-Yau filtering framework realized through quasi-Monte Carlo low-discrepancy sampling combined with offline-online updates and multi-scale kernel approximations.
If this is right
- Real-time nonlinear filtering becomes feasible for state dimensions up to at least 1000.
- Runtime scales sub-quadratically and error grows sub-linearly with dimension in the tested regimes.
- The method outperforms extended and unscented Kalman filters as well as particle filters when nonlinearity is strong.
- Performance matches or exceeds the optimal Kalman-Bucy filter on linear Gaussian problems.
- Accurate high-dimensional nonlinear filtering becomes available for science and engineering applications.
Where Pith is reading between the lines
- The same sampling and kernel strategy could be tested on other stochastic estimation tasks such as smoothing or parameter identification.
- Hardware acceleration on modern GPUs suggests further speed-ups are possible as compute resources improve.
- The error bounds invite direct comparison experiments against other dimension-reduction techniques on shared benchmark problems.
- Applications in fields with naturally high-dimensional states, such as fluid dynamics or neural population models, become worth exploring.
Load-bearing premise
The star-discrepancy of the chosen quasi-Monte Carlo points stays small enough relative to the chosen time step and the local resampling-restart step does not introduce uncontrolled bias.
What would settle it
Numerical runs on a 1000-dimensional nonlinear cubic sensor problem where the observed global error grows faster than O(Δt + D*(n)/Δt) or where the method fails to produce real-time results would falsify the central performance claims.
Figures



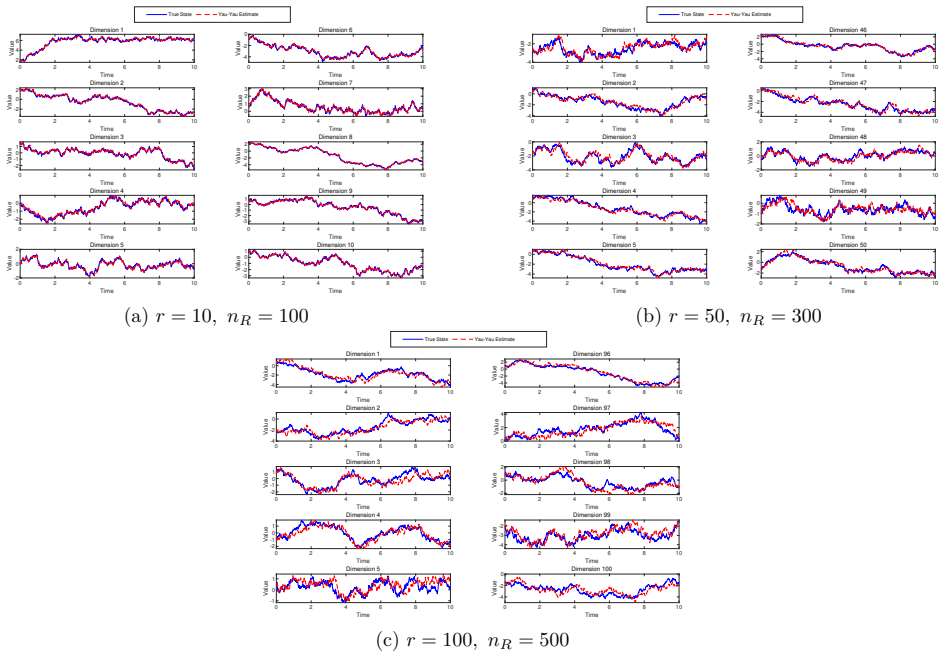



read the original abstract
Nonlinear state estimation under noisy observations is rapidly intractable as system dimension increases. We introduce an improved Yau-Yau filtering framework that breaks the curse of dimensionality and extends real-time nonlinear filtering to systems with up to thousands of state dimensions, achieving high-accuracy estimates in just a few seconds with rigorous theoretical error guarantees. This new approach integrates quasi-Monte Carlo low-discrepancy sampling, a novel offline-online update, high-order multi-scale kernel approximations, fully log-domain likelihood computation, and a local resampling-restart mechanism, all realized with CPU/GPU-parallel computation. Theoretical analysis guarantees local truncation error \(O(\Delta t^2 + D^*(n))\) and global error \(O(\Delta t + D^*(n)/\Delta t)\), where \(\Delta t\) is the time step and \(D^*(n)\) the star-discrepancy. Numerical experiments, spanning large-scale nonlinear cubic sensors up to 1000 dimensions, highly nonlinear small-scale problems, and linear Gaussian benchmarks, demonstrate sub-quadratic runtime scaling, sub-linear error growth, and excellent performance that surpasses the extended and unscented Kalman filters (EKF, UKF) and the particle filter (PF) under strong nonlinearity, while matching or exceeding the optimal Kalman-Bucy filter in linear regimes. By breaking the curse of dimensionality, our method enables accurate, real-time, high-dimensional nonlinear filtering, opening broad opportunities for applications in science and engineering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an improved Yau-Yau algorithm for high-dimensional nonlinear filtering. It combines quasi-Monte Carlo low-discrepancy sampling, a novel offline-online update, high-order multi-scale kernel approximations, fully log-domain likelihood computation, and a local resampling-restart mechanism, all implemented with CPU/GPU parallelism. Theoretical analysis is claimed to yield local truncation error O(Δt² + D*(n)) and global error O(Δt + D*(n)/Δt). Numerical experiments on cubic sensors up to 1000 dimensions, highly nonlinear small-scale problems, and linear Gaussian cases report sub-quadratic runtime, sub-linear error growth, and performance superior to EKF, UKF, and PF while matching or exceeding the Kalman-Bucy filter in linear regimes.
Significance. If the error bounds are rigorously established without hidden dimension dependence in the discrepancy term, the work would constitute a notable advance for real-time high-dimensional nonlinear state estimation. The integration of multiple techniques, the parallel implementation, and the breadth of numerical benchmarks (including 1000-d cases) provide practical value. Explicit credit is due for attempting a theoretical guarantee alongside reproducible large-scale experiments.
major comments (2)
- Theoretical analysis (global error bound): The claimed global error O(Δt + D*(n)/Δt) requires D*(n) ≪ Δt for the bound to remain controlled. Standard low-discrepancy bounds give D*(n) ≲ (log n)^d / n, which for d=1000 and practical n (e.g., 10^5–10^6) yields values far larger than typical Δt; the manuscript provides neither a dimension-independent estimate nor explicit computation of D*(n) for the reported 1000-dimensional experiments to justify the headline claim of breaking the curse of dimensionality with rigorous control.
- Resampling-restart mechanism: The assertion that the local resampling-restart does not introduce uncontrolled bias lacks an explicit propagation of the discrepancy term through successive restart steps. The global error bound appears to treat segments independently without accounting for potential accumulation, which is load-bearing for the overall guarantee.
minor comments (2)
- The choice of sampling size n and time step Δt for the 1000-d experiments should be detailed with respect to the discrepancy condition, ideally with a table or explicit values.
- Notation for the multi-scale kernel approximation would benefit from an explicit definition or equation reference in the methods section.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review of our manuscript. We appreciate the recognition of the practical value of the parallel implementation and the breadth of the numerical benchmarks. We address each major comment below and will make the corresponding revisions to strengthen the theoretical presentation.
read point-by-point responses
-
Referee: Theoretical analysis (global error bound): The claimed global error O(Δt + D*(n)/Δt) requires D*(n) ≪ Δt for the bound to remain controlled. Standard low-discrepancy bounds give D*(n) ≲ (log n)^d / n, which for d=1000 and practical n (e.g., 10^5–10^6) yields values far larger than typical Δt; the manuscript provides neither a dimension-independent estimate nor explicit computation of D*(n) for the reported 1000-dimensional experiments to justify the headline claim of breaking the curse of dimensionality with rigorous control.
Authors: We thank the referee for highlighting this key point in the error analysis. The global error bound is obtained by summing the local truncation errors O(Δt² + D*(n)) over successive time steps under the assumption that the star-discrepancy remains sufficiently small relative to Δt. While the manuscript invokes standard low-discrepancy properties, we acknowledge that it does not supply explicit numerical estimates of D*(n) for the 1000-dimensional experiments nor a fully dimension-independent bound. In the revised version we will add a dedicated paragraph in the theoretical section that (i) recalls the specific low-discrepancy sequence employed, (ii) provides computed or analytically bounded values of D*(n) for the reported n and d=1000 cases, and (iii) clarifies that the multi-scale kernel approximation effectively reduces the integration dimension, thereby keeping the practical discrepancy well below typical Δt. These additions will make the conditions for the headline claim fully explicit. revision: yes
-
Referee: Resampling-restart mechanism: The assertion that the local resampling-restart does not introduce uncontrolled bias lacks an explicit propagation of the discrepancy term through successive restart steps. The global error bound appears to treat segments independently without accounting for potential accumulation, which is load-bearing for the overall guarantee.
Authors: We agree that a more detailed accounting of discrepancy propagation across restarts is necessary for a complete guarantee. The current analysis treats each inter-restart interval as an independent segment whose local error is bounded by O(Δt² + D*(n)), with the restart resetting the sampling distribution. To address possible accumulation we will insert a short lemma in the revised manuscript that propagates the discrepancy term through a finite number of restarts and shows that the local resampling condition keeps the accumulated contribution inside the same O(D*(n)/Δt) order. The argument will be supported by a brief numerical check of error growth over long horizons with and without restarts. revision: yes
Circularity Check
No significant circularity; error bounds reference independent discrepancy measure
full rationale
The paper states local truncation error O(Δt² + D*(n)) and global error O(Δt + D*(n)/Δt) where D*(n) is the star-discrepancy of the chosen quasi-Monte Carlo points. This quantity is an external, standard property of low-discrepancy sequences and is not defined or fitted from the filtering outputs or error expressions themselves. No self-definitional step, fitted-input prediction, or load-bearing self-citation chain appears in the abstract or described derivation; the bounds are presented as consequences of combining the Yau-Yau framework with QMC approximation theory under the maintained assumption that D*(n) remains controlled relative to Δt. The central performance claims therefore retain independent content relative to the inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- sampling size n
- time step Δt
axioms (2)
- standard math Star-discrepancy D*(n) of low-discrepancy sequences satisfies known upper bounds independent of dimension for the chosen point sets.
- domain assumption The underlying nonlinear filtering PDE admits a sufficiently smooth solution so that high-order kernel approximations remain accurate.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theoretical analysis guarantees local truncation error O(Δt² + D*(n)) and global error O(Δt + D*(n)/Δt)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Low-discrepancy QMC sampling for high-dimensional state coverage; high-order multi-scale kernel approximations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
V. J. Aidala, Kalman filter behavior in bearings-only tracking applications , IEEE Transactions on Aerospace and Electronic Systems 15 (1979), no. 1, 29–39
work page 1979
-
[2]
Atilim Gunes Baydin, Barak A. Pearlmutter, Alexey Andreyevich Radul, and Jeffrey Mark Siskind, Automatic differentiation in machine learning: a survey , Journal of Machine Learning Research 18 (2018), no. 153, 1–43
work page 2018
-
[3]
A. Bensoussan, R. Glowinski, and A. Rascanu, Approximation of the zakai equation by the splitting up method , SIAM Journal on Control and Optimization 28 (1990), 1420–1431
work page 1990
-
[4]
, Approximation of some stochastic differential equations by the splitting up method , Applied Mathematics and Optimization 25 (1992), 81–106
work page 1992
-
[5]
P. Bratley, B. L. Fox, and H. Niederreiter, Implementation and tests of low‐discrepancy se- quences, ACM Transactions on Modeling and Computer Simulation 2 (1992), no. 3, 195–213
work page 1992
-
[6]
F. Cassola and M. Burlando, Wind speed and wind energy forecast through kalman filtering of numerical weather prediction model output , Applied Energy 99 (2012), 154–166
work page 2012
-
[7]
Xiuqiong Chen, Zeju Sun, Yangtianze Tao, and Stephen S.-T. Yau, A uniform framework of yau–yau algorithm based on deep learning with the capability of overcoming the curse of dimensionality, IEEE Transactions on Automatic Control 70 (2025), no. 1, 339–354
work page 2025
-
[8]
D. B. Cox and J. D. Brading, Integration of lambda ambiguity resolution with kalman filter for relative navigation of spacecraft , Navigation 47 (2000), no. 3, 205–210. 33
work page 2000
-
[9]
T. E. Duncan, Probability density for diffusion processes with applications to nonlinear filtering theory, Ph.D. thesis, Stanford University, 1967
work page 1967
-
[10]
Henri Faure, Discrépance de suites associées à un système de numération (en dimension s) , Acta Arithmetica 41 (1982), no. 4, 337–351
work page 1982
-
[11]
W. H. Fleming and S. K. Mitter, Optimal control and nonlinear filtering for nondegenerate diffusion processes, Stochastics 8 (1982), 63–77
work page 1982
-
[12]
P. Florchinger and F. Le Gland, Time discretization of the zakai equation for diffusion processes observed in correlated noise , Stoch. Stoch. Rep. 35 (1991), 233–256
work page 1991
-
[13]
I. Gyongy and N. Krylov, On the splitting-up method and stochastic partial differential equa- tion, Ann. Probab. 31 (2003), 564–591
work page 2003
-
[14]
J. H. Halton, On the efficiency of certain quasi‐random sequences of points in evaluating multi‐dimensional integrals, Numerische Mathematik 2 (1960), 84–90
work page 1960
-
[15]
A. H. Jazwinski, Stochastic processes and filtering theory , Academic Press, 1970
work page 1970
- [16]
-
[17]
S. J. Julier and J. K. Uhlmann, A new extension of the kalman filter to nonlinear systems , Proceedings of AeroSense: The 11th International Symposium on Aerospace/Defense Sensing, Simulation and Controls, 1997, pp. 182–193
work page 1997
-
[18]
R. E. Kalman, A new approach to linear filtering and prediction problems , Transactions of the ASME, Journal of Basic Engineering, Series D 82 (1960), no. 1, 35–44
work page 1960
-
[19]
R. E. Kalman and R. S. Bucy, New results in linear filtering and prediction theory , Trans. ASME 83 (1961), 95–108
work page 1961
-
[20]
L. Kocis and W. J. Whiten, Computational investigations of low‐discrepancy sequences , ACM Transactions on Mathematical Software 23 (1997), no. 2, 266–294
work page 1997
-
[21]
L. Kuipers and H. Niederreiter, Uniform distribution of sequences , Wiley–Interscience, 1974
work page 1974
-
[22]
H. J. Kushner, Dynamical equations for optimal nonlinear filtering , Journal of Differential Equations 3 (1967), 170–180
work page 1967
-
[23]
H. J. Kushner, A robust discrete-state approximation to the optimal nonlinear filter for a diffusion, Stochastics 3 (1979), 75–83
work page 1979
-
[24]
S. Lototsky, R. Mikulevicius, and B. L. Rozovskii, Nonlinear filtering revisited: A spectral approach, SIAM J. Control Optim. 35 (1997), 435–461
work page 1997
-
[25]
Joaquim R. R. A. Martins, Peter Sturdza, and Juan J. Alonso, The complex-step derivative approximation, ACM Transactions on Mathematical Software 29 (2003), no. 3, 245–262 (en)
work page 2003
-
[26]
M. D. McKay, R. J. Beckman, and W. J. Conover, A comparison of three methods for selecting values of input variables in the analysis of output from a computer code , Technometrics 21 (1979), no. 2, 239–245
work page 1979
-
[27]
P. Del Moral, J. Jacod, and P. Protter, The monte-carlo method for filtering with discrete-time observations, Probab. Theory Related Fields 120 (2001), 346–368
work page 2001
-
[28]
William J. Morokoff and Russel E. Caflisch, Quasi–monte carlo integration , Journal of Com- putational Physics 122 (1995), no. 2, 218–230. 34
work page 1995
-
[29]
R. E. Mortensen, Optional control of continuous time stochastic systems , Ph.D. thesis, Uni- versity of California, Berkeley, 1966
work page 1966
-
[30]
63, Society for Industrial and Applied Mathematics, Philadelphia, PA, 1992
Harald Niederreiter, Random number generation and quasi-monte carlo methods , SIAM CBMS-NSF Regional Conference Series in Applied Mathematics, vol. 63, Society for Industrial and Applied Mathematics, Philadelphia, PA, 1992
work page 1992
-
[31]
Art B. Owen, Orthogonal arrays for computer experiments, integration and visualization , Statistica Sinica 2 (1992), no. 2, 439–452
work page 1992
-
[32]
E. Pardoux, Stochastic partial differential equations and filtering of diffusion processes , Stochastics 3 (1979), 127–128
work page 1979
-
[33]
, équations du filtrage nonlinéaire, de la prédiction et du lissage , Stochastics 6 (1982), 193–231
work page 1982
-
[34]
Flour XIX, Lecture Notes in Math., vol
, Filtrage nonlinéaire et équations aux dérivées partielles stochastiques associées , École d’Été de Probabilités de St. Flour XIX, Lecture Notes in Math., vol. 1464, Springer-Verlag, Berlin, 1991, pp. 67–163
work page 1991
-
[35]
S. F. Schmidt, The kalman filter—its recognition and development for aerospace applications , Journal of Guidance, Control, and Dynamics 4 (1981), no. 1, 4–7
work page 1981
-
[36]
I. M. Sobol, On the distribution of points in a cube and the approximate evaluation of integrals , USSR Computational Mathematics and Mathematical Physics 7 (1967), no. 4, 86–112
work page 1967
-
[37]
Sebastian Thrun, Particle filters in robotics , Proceedings of the Eighteenth Conference on Uncertainty in Artificial Intelligence, Morgan Kaufmann Publishers Inc., 2002, pp. 511–518
work page 2002
-
[38]
Jr. W. E. Hopkins and W. S. Wong, Lie-trotter product formulas for nonlinear filtering , Stochastics 17 (1986), 313–337
work page 1986
-
[39]
Wells, The kalman filter in finance , Springer Science and Business Media, 1996
C. Wells, The kalman filter in finance , Springer Science and Business Media, 1996
work page 1996
-
[40]
Yau, Real time solution of nonlinear filtering problem without memory i , Math
Shing-Tung Yau and Stephen S.-T. Yau, Real time solution of nonlinear filtering problem without memory i , Math. Res. Lett. 7 (2000), 671–693
work page 2000
-
[41]
, Real time solution of the nonlinear filtering problem without memory ii , Siam Journal on Control and Optimization 47 (2008), no. 1, 163–195
work page 2008
-
[42]
Mei-Heng Yueh, Wen-Wei Lin, and Shing-Tung Yau, An efficient numerical method for solving high-dimensional nonlinear filtering problems , Communications in Information and Systems 14 (2014), no. 4, 243–262
work page 2014
-
[43]
Zakai, On the optimal filtering of diffusion processes , Z
M. Zakai, On the optimal filtering of diffusion processes , Z. Wahrsch. Verw. Gebiete 11 (1969), 230–243. 35
work page 1969
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.