PRINCIPLES: Synthetic Strategy Memory for Proactive Dialogue Agents
Pith reviewed 2026-05-18 15:14 UTC · model grok-4.3
The pith
A memory of strategies from offline self-play simulations guides proactive dialogue planning at inference time without extra training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PRINCIPLES is derived through offline self-play simulations and serves as reusable knowledge that guides strategy planning during inference, eliminating the need for additional training and data annotation, while showing consistent improvements over strong baselines in emotional support and persuasion domains and maintaining robustness in extended settings.
What carries the argument
The synthetic strategy memory created from offline self-play, which stores reusable strategies to direct planning choices during actual user interactions.
If this is right
- Strategy planning becomes more comprehensive by accessing a wide range of simulated successful approaches.
- Development of proactive agents avoids the costs of additional training rounds and data labeling.
- Performance gains appear reliably across emotional support and persuasion tasks.
- The approach stays effective in longer and more diverse conversation settings.
Where Pith is reading between the lines
- Such memory-based methods might lower the barrier for creating capable agents in other interactive domains.
- Combining the fixed memory with occasional updates from real interactions could address any gaps in simulation fidelity.
- Verification in live user studies would confirm if the simulated strategies translate to satisfying real-world outcomes.
Load-bearing premise
Strategies produced in offline self-play simulations are of high quality, lack preference biases, and apply well to genuine user interactions without needing adjustments.
What would settle it
Observing that agents using the memory perform no better or worse than baselines when tested with actual human users in emotional support dialogues would challenge the claim of effective transfer.
Figures




























read the original abstract
Dialogue agents based on large language models (LLMs) have shown promising performance in proactive dialogue, which requires effective strategy planning. However, existing approaches to strategy planning for proactive dialogue face several limitations: limited strategy coverage, preference bias in planning, and reliance on costly additional training. To address these, we propose PRINCIPLES: a synthetic strategy memory for proactive dialogue agents. PRINCIPLES is derived through offline self-play simulations and serves as reusable knowledge that guides strategy planning during inference, eliminating the need for additional training and data annotation. We evaluate PRINCIPLES in both emotional support and persuasion domains, demonstrating consistent improvements over strong baselines. Furthermore, PRINCIPLES maintains its robustness across extended and more diverse evaluation settings. See our project page at https://huggingface.co/spaces/kimnamssya/Principles.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PRINCIPLES, a synthetic strategy memory for proactive dialogue agents derived via offline self-play simulations between LLMs. This memory serves as reusable knowledge to guide strategy planning at inference time without additional training or data annotation. The approach targets limitations in strategy coverage, preference bias, and training costs, with evaluations in emotional support and persuasion domains claiming consistent improvements over strong baselines and robustness in extended settings.
Significance. If the transfer from self-play to real interactions holds, the work offers a practical, low-cost method to enhance proactive dialogue capabilities in LLMs. It could reduce reliance on human-annotated data and enable more accessible strategy planning, with potential value for domains requiring careful turn-taking like emotional support.
major comments (3)
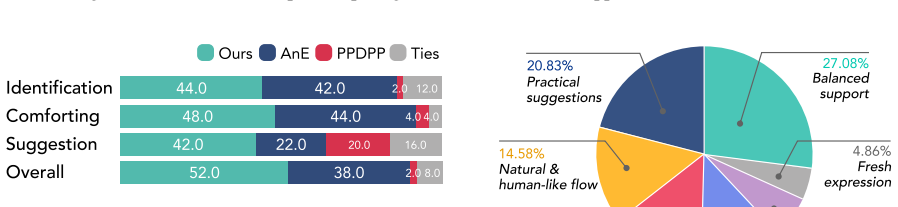
- [Abstract] Abstract: the claim of 'consistent improvements over strong baselines' and 'robustness across extended and more diverse evaluation settings' is stated without any metrics, baseline names, statistical tests, or controls for simulation bias, preventing assessment of whether the central claim is supported.
- [§3] §3 (Method, self-play procedure): the generation of synthetic strategies via LLM self-play lacks any described filtering, bias-correction step, or external validation against human dialogue corpora, leaving the assumption that these strategies are high-quality and free of preference bias untested and load-bearing for the no-training claim.
- [§5] §5 (Evaluation): both strategy generation and performance measurement appear to rely on simulated interactions; without reported comparisons to human-human dialogue data or live-user trials, the generalizability and elimination-of-annotation claims rest on an unverified transfer step.
minor comments (2)
- [Figure 1] Figure 1 or equivalent diagram: the flow from self-play to memory to inference could include an explicit example of a stored strategy to improve clarity.
- [Related Work] Related work section: add citations to recent self-play and memory-augmented dialogue papers for better context.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, indicating revisions where the manuscript will be updated to improve clarity and address concerns about evidence and assumptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent improvements over strong baselines' and 'robustness across extended and more diverse evaluation settings' is stated without any metrics, baseline names, statistical tests, or controls for simulation bias, preventing assessment of whether the central claim is supported.
Authors: We agree that the abstract, being concise by design, omits specific quantitative details that appear in the body of the paper. Section 5 reports concrete metrics, names the baselines (including vanilla LLM prompting and other proactive dialogue methods), includes statistical significance tests, and describes controls such as multiple simulation runs to mitigate bias. In the revised manuscript we will update the abstract to reference key improvement figures, primary baseline names, and the use of statistical testing while preserving its brevity. revision: yes
-
Referee: [§3] §3 (Method, self-play procedure): the generation of synthetic strategies via LLM self-play lacks any described filtering, bias-correction step, or external validation against human dialogue corpora, leaving the assumption that these strategies are high-quality and free of preference bias untested and load-bearing for the no-training claim.
Authors: The self-play procedure relies on diverse multi-turn interactions across different LLM instances to generate a broad strategy distribution and thereby reduce single-model preference bias. We acknowledge that the original description did not explicitly detail post-generation filtering or external human-corpus validation. We will revise §3 to add a description of the simulation parameters chosen to promote diversity, any implicit quality heuristics applied during collection, and an explicit discussion of the assumption that synthetic strategies are sufficiently high-quality for the no-training setting. External validation against human corpora is outside the current scope because the method is intentionally annotation-free; we will note this design choice and its implications. revision: partial
-
Referee: [§5] §5 (Evaluation): both strategy generation and performance measurement appear to rely on simulated interactions; without reported comparisons to human-human dialogue data or live-user trials, the generalizability and elimination-of-annotation claims rest on an unverified transfer step.
Authors: Evaluations are performed in controlled simulated environments to isolate the contribution of the synthetic memory while avoiding additional human annotation, which is central to the paper's contribution. We recognize that this leaves the transfer to real human interactions as an assumption. In the revision we will expand §5 with a dedicated limitations paragraph that (a) states the reliance on simulation, (b) summarizes the robustness results across extended settings as supporting evidence, and (c) outlines future work on human validation. This addition clarifies rather than removes the claim while remaining faithful to the experiments conducted. revision: yes
Circularity Check
No circularity: derivation chain is independent of its outputs
full rationale
The paper generates PRINCIPLES via offline self-play simulations to produce reusable strategy memory, then applies it at inference for proactive planning in emotional support and persuasion domains. This generation step is separate from evaluation, with reported gains measured against external baselines rather than reducing to fitted parameters or self-referential definitions. No equations or steps equate a claimed prediction back to its inputs by construction, and no uniqueness theorems or ansatzes are imported via self-citation in a load-bearing way. The approach remains externally falsifiable through the described experiments and robustness checks across extended settings.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Offline self-play simulations generate representative strategies without preference bias that generalize to real user dialogues.
invented entities (1)
-
Synthetic strategy memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The faiss library. Amy C Edmondson. 2011. Strategies for learning from failure.Harvard business review, 89(4):48–55. Yao Fu, Hao Peng, Tushar Khot, and Mirella Lapata
work page 2011
-
[2]
Improving language model negotiation with self-play and in-context learning from ai feedback. CoRR. Igor Grossmann. 2017. Wisdom in context.Perspec- tives on psychological science, 12(2):233–257. He He, Derek Chen, Anusha Balakrishnan, and Percy Liang. 2018. Decoupling strategy and generation in negotiation dialogues. InProceedings of the 2018 Conference ...
-
[3]
Divide, conquer, and combine: Mixture of semantic-independent experts for zero-shot dialogue state tracking. InProceedings of the 61st Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 2048–2061, Toronto, Canada. Association for Computational Lin- guistics. Xuewei Wang, Weiyan Shi, Richard Kim, Yoojung Oh, Si...
work page 2048
-
[4]
I’ll consider making a donation
Ask an expert: Leveraging language models to improve strategic reasoning in goal-oriented dialogue models. InFindings of the Association for Compu- tational Linguistics: ACL 2023, pages 6665–6694, Toronto, Canada. Association for Computational Lin- guistics. Tong Zhang, Chen Huang, Yang Deng, Hongru Liang, Jia Liu, Zujie Wen, Wenqiang Lei, and Tat-Seng Ch...
-
[6]
Focus on the last {user_role} turn and the {assistant_role} strategies that resulted in a successful outcome
-
[7]
Explain, in one-two sentences, why those strategies succeeded to advance the task goal
-
[8]
When the patient opens up about a painful memory but seems hesitant to elaborate further
Express the insight as a reusable principle using the following format. FORMAT REQUIREMENTS - The principle must describe what the {assistant_role} should do, not advice for the {user_role}. - The [When] clause must explicitly reference the {user_role}’s last utterance in the [Dialogue History] section (e.g., “When the patient opens up about a painful mem...
-
[9]
Review the task goal and dialogue history to understand the overall context
-
[10]
Compare the final successful trial with the previous failed trials
-
[11]
Explain, in one-two sentences, why the successful strategy was more effective than the failed ones in advancing the task goal
-
[12]
When the patient opens up about a painful memory but seems hesitant to elaborate further
Express the insight as a reusable principle using the following format. FORMAT REQUIREMENTS - The principle must describe what the {assistant_role} should do, not advice for the {user_role}. - The [When] clause must explicitly reference the {user_role}’s last utterance in the [Dialogue History] section. (e.g., “When the patient opens up about a painful me...
-
[13]
Carefully read the original principle and the current dialogue context
-
[14]
Identify what kind of {user_role} behavior or situation the principle addresses, and how it instructs the {assistant_role} to respond
-
[15]
Rewrite it so that it applies to the current dialogue context
-
[16]
To reach this goal, the most appropriate strategy is []
Follow the exact same format as the original principle. INPUT [Current Dialogue]: {conversation} [Original Principle]: {principle} OUTPUT [Reinterpreted Principle]: (Rewrite the principle using the same structure.) Reinterpretation Figure 18: Prompt for reinterpreting retrieved principles in the current dialogue context. [System] Now enter the role-playin...
work page 2023
-
[17]
The given occupation
-
[18]
One or two personality traits
-
[19]
A lifestyle or behavioral element (e.g., values structure, avoids confrontation, works late hours)
-
[20]
A hobby or regular interest (e.g., hiking, baking, reading thrillers) - The tone should sound natural and human, written in the third person. Avoid any mention of: - Donation, volunteering, or charity - Age, religion, or political beliefs Return only the persona description without any additional formatting. Persona Generation Figure 29: Prompt for genera...
-
[21]
\"dialogue_context\": One sentence describing a natural, socially plausible situation in which the persuader and persuadee might be having a casual conversation. The setting should allow a smooth shift into a discussion about donation. It must NOT occur in the persuadee’s workplace or during a professional duty
-
[22]
\"first_two_turns\": A list of the first four dialogue turns in JSON format, as follows: - Turn 1 (Persuader): Open with light small talk or topic related to the context. Do NOT mention the charity yet. - Turn 2 (Persuadee): Friendly or neutral reply that reflects the persona. - Turn 3 (Persuader): Briefly introduce the organization and what it does. You ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.