When TableQA Meets Noise: A Dual Denoising Framework for Complex Questions and Large-scale Tables
Pith reviewed 2026-05-21 21:33 UTC · model grok-4.3
The pith
A dual denoising framework improves TableQA by cleaning complex questions and pruning large noisy tables.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
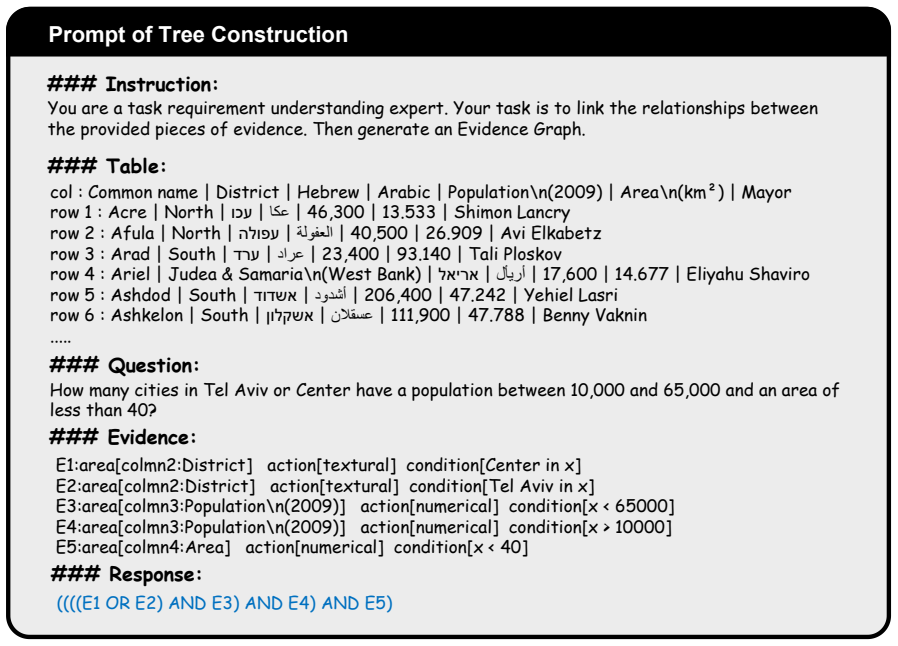
EnoTab performs evidence-based question denoising by breaking the input question into minimal semantic units and retaining only those that meet consistency and usability criteria for answer reasoning, then applies evidence tree-guided table denoising that constructs an explicit pruning path, observes each intermediate table state, and invokes a post-order node rollback mechanism whenever an abnormal state appears, ultimately yielding a compact reliable sub-table for final reasoning.
What carries the argument
Evidence Tree-guided Table Denoising with post-order node rollback, which builds an explicit pruning path and corrects abnormal intermediate table states step by step.
If this is right
- Question decomposition into semantic units can isolate and discard only the parts that do not contribute to answer reasoning.
- An evidence tree supplies a transparent, step-wise path for removing irrelevant rows and columns while preserving essential content.
- Rollback on abnormal intermediate table states prevents error propagation during pruning.
- The resulting compact sub-table allows the LLM to reason more reliably without being distracted by noise.
Where Pith is reading between the lines
- The same dual-denoising pattern could be tested on other structured-data tasks such as knowledge-base question answering or spreadsheet formula generation.
- Rollback could be generalized to other tree-guided search procedures that risk entering invalid states.
- If the semantic-unit decomposition proves robust, it might serve as a lightweight pre-processing step for any LLM pipeline that receives long or noisy inputs.
Load-bearing premise
Decomposing questions into minimal semantic units and filtering them with consistency and usability criteria will keep every piece of information needed for correct reasoning while removing noise.
What would settle it
Run the method on a benchmark dataset of complex questions over large tables and check whether the final answers are less accurate than those produced by the same LLM on the original un-denoised inputs.
Figures




















read the original abstract
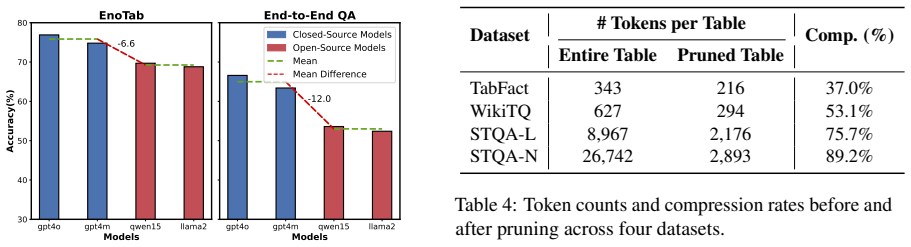
Table question answering (TableQA) is a fundamental task in natural language processing (NLP). The strong reasoning capabilities of large language models (LLMs) have brought significant advances in this field. However, as real-world applications involve increasingly complex questions and larger tables, substantial noisy data is introduced, which severely degrades reasoning performance. To address this challenge, we focus on improving two core capabilities: Relevance Filtering, which identifies and retains information truly relevant to reasoning, and Table Pruning, which reduces table size while preserving essential content. Based on these principles, we propose EnoTab, a dual denoising framework for complex questions and large-scale tables. Specifically, we first perform Evidence-based Question Denoising by decomposing the question into minimal semantic units and filtering out those irrelevant to answer reasoning based on consistency and usability criteria. Then, we propose Evidence Tree-guided Table Denoising, which constructs an explicit and transparent table pruning path to remove irrelevant data step by step. At each pruning step, we observe the intermediate state of the table and apply a post-order node rollback mechanism to handle abnormal table states, ultimately producing a highly reliable sub-table for final answer reasoning. Finally, extensive experiments show that EnoTab achieves outstanding performance on TableQA tasks with complex questions and large-scale tables, confirming its effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EnoTab, a dual denoising framework for TableQA on complex questions and large-scale tables. It first applies Evidence-based Question Denoising by decomposing the input question into minimal semantic units and filtering those deemed irrelevant via consistency and usability criteria. It then performs Evidence Tree-guided Table Denoising, constructing an explicit pruning path and applying a post-order node rollback mechanism to recover from abnormal intermediate table states, ultimately yielding a pruned sub-table for final LLM reasoning. The authors claim that this yields outstanding performance on TableQA tasks.
Significance. If the empirical claims hold, the work addresses a practically important gap in robust TableQA by explicitly targeting relevance filtering and table pruning under noise. The transparent evidence-tree construction and rollback mechanism constitute a concrete, interpretable contribution that could aid debugging and extension in LLM-based reasoning pipelines.
major comments (2)
- [§3.1] §3.1 (Evidence-based Question Denoising): The load-bearing assumption that decomposing questions into minimal semantic units and then dropping units via consistency/usability filters will retain every piece of information required for correct downstream reasoning is not obviously true for complex questions. Interdependent clauses that appear unusable in isolation can still be essential when combined; discarding them leaves the evidence tree with an incomplete set that later rollback or final reasoning cannot recover. This needs targeted validation (e.g., ablation on questions with known interdependencies or error analysis of cases where filtering removes critical context).
- [§4] §4 (Experiments and Results): The abstract asserts 'outstanding performance' and 'extensive experiments,' yet the strength of the central claim depends on showing that the dual-denoising pipeline, rather than other factors, drives the gains. The manuscript should report concrete metrics, strong baselines (including recent TableQA and denoising methods), dataset statistics, and an error analysis that isolates the contribution of each denoising stage and the rollback mechanism.
minor comments (2)
- Define acronyms (TableQA, LLM) on first use and ensure consistent notation for 'evidence tree' versus 'evidence-based' throughout.
- [Figure 1] Figure captions and the evidence-tree diagram should explicitly annotate the rollback operation and the intermediate table states being observed.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have reviewed each major comment carefully and outline our responses and planned revisions below.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Evidence-based Question Denoising): The load-bearing assumption that decomposing questions into minimal semantic units and then dropping units via consistency/usability filters will retain every piece of information required for correct downstream reasoning is not obviously true for complex questions. Interdependent clauses that appear unusable in isolation can still be essential when combined; discarding them leaves the evidence tree with an incomplete set that later rollback or final reasoning cannot recover. This needs targeted validation (e.g., ablation on questions with known interdependencies or error analysis of cases where filtering removes critical context).
Authors: We appreciate this observation on the risks of information loss from interdependencies in complex questions. Our consistency and usability filters are designed to retain evidence necessary for reasoning while removing noise, and the subsequent evidence tree with rollback provides a recovery path. Nevertheless, we agree that explicit validation is warranted. In the revision we will add a targeted ablation on questions containing known interdependent clauses together with an error analysis of filtering cases that remove critical context. revision: yes
-
Referee: [§4] §4 (Experiments and Results): The abstract asserts 'outstanding performance' and 'extensive experiments,' yet the strength of the central claim depends on showing that the dual-denoising pipeline, rather than other factors, drives the gains. The manuscript should report concrete metrics, strong baselines (including recent TableQA and denoising methods), dataset statistics, and an error analysis that isolates the contribution of each denoising stage and the rollback mechanism.
Authors: We agree that stronger isolation of the dual-denoising contributions is needed to support the central claims. The current experiments compare against several TableQA baselines on standard benchmarks, yet we will expand §4 in the revision to include additional concrete metrics, more recent TableQA and denoising baselines, fuller dataset statistics, and a dedicated error analysis that quantifies the incremental effect of question denoising, table pruning, and the rollback mechanism. revision: yes
Circularity Check
No circularity detected in EnoTab dual-denoising derivation
full rationale
The paper presents EnoTab as an algorithmic framework: question decomposition into semantic units followed by consistency/usability filtering, then evidence-tree table pruning with rollback. These steps are defined procedurally and evaluated empirically on TableQA benchmarks. No equations or claims reduce a 'prediction' to a fitted input by construction, no self-citation is invoked as a uniqueness theorem, and no ansatz is smuggled. The performance results are reported from experiments rather than derived tautologically from the method definition itself. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Decomposing questions into minimal semantic units and filtering by consistency and usability criteria preserves all necessary information for reasoning.
- domain assumption Step-by-step table pruning guided by an evidence tree with rollback will produce a reliable sub-table without losing essential content.
Forward citations
Cited by 1 Pith paper
-
One Refiner to Unlock Them All: Inference-Time Reasoning Elicitation via Reinforcement Query Refinement
ReQueR trains a single RL-based query refiner with an adaptive curriculum to decompose raw queries into structured logic, delivering 1.7-7.2% absolute gains on reasoning tasks across diverse LLMs and generalizing to u...
Reference graph
Works this paper leans on
-
[1]
Nikhil Abhyankar, Vivek Gupta, Dan Roth, and Chandan K Reddy. 2025. H-star: Llm-driven hybrid sql-text adaptive reasoning on tables. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8841--8863
work page 2025
-
[2]
Michael J Cafarella, Alon Halevy, Daisy Zhe Wang, Eugene Wu, and Yang Zhang. 2008. Webtables: exploring the power of tables on the web. Proceedings of the VLDB Endowment, 1(1):538--549
work page 2008
-
[3]
Si-An Chen, Lesly Miculicich, Julian Eisenschlos, Zifeng Wang, Zilong Wang, Yanfei Chen, Yasuhisa Fujii, Hsuan-Tien Lin, Chen-Yu Lee, and Tomas Pfister. 2024. Tablerag: Million-token table understanding with language models. Advances in Neural Information Processing Systems, 37:74899--74921
work page 2024
-
[4]
Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. 2020. Tabfact : A large-scale dataset for table-based fact verification. In International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia
work page 2020
-
[5]
Zhoujun Cheng, Tianbao Xie, Peng Shi, Chengzu Li, Rahul Nadkarni, Yushi Hu, Caiming Xiong, Dragomir Radev, Mari Ostendorf, Luke Zettlemoyer, Noah A. Smith, and Tao Yu. 2023. Binding language models in symbolic languages. ICLR, abs/2210.02875
-
[6]
Xiang Deng, Huan Sun, Alyssa Lees, You Wu, and Cong Yu. 2022. Turl: Table understanding through representation learning. ACM SIGMOD Record, 51(1):33--40
work page 2022
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [8]
- [9]
- [10]
-
[11]
Mike Lewis. 2019. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[12]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74--81
work page 2004
-
[13]
Xin Lin, Zhenya Huang, Zhiqiang Zhang, Jun Zhou, and Enhong Chen. 2025. Explore what llm does not know in complex question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24585--24594
work page 2025
- [14]
-
[15]
Qingyang Mao, Qi Liu, Zhi Li, Mingyue Cheng, Zheng Zhang, and Rui Li. 2024. Potable: Programming standardly on table-based reasoning like a human analyst. arXiv preprint arXiv:2412.04272
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Md Nahid and Davood Rafiei. 2024 a . Normtab: Improving symbolic reasoning in llms through tabular data normalization. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 3569--3585
work page 2024
-
[17]
Md Nahid and Davood Rafiei. 2024 b . Tabsqlify: Enhancing reasoning capabilities of llms through table decomposition. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 5725--5737
work page 2024
-
[18]
Linyong Nan, Chiachun Hsieh, Ziming Mao, Xi Victoria Lin, Neha Verma, Rui Zhang, Wojciech Kry \'s ci \'n ski, Hailey Schoelkopf, Riley Kong, Xiangru Tang, et al. 2022. Fetaqa: Free-form table question answering. Transactions of the Association for Computational Linguistics, 10:35--49
work page 2022
-
[19]
R OpenAI. 2023. Gpt-4 technical report. arxiv 2303.08774. View in Article, 2(5)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311--318
work page 2002
-
[21]
Panupong Pasupat and Percy Liang. 2015. Compositional semantic parsing on semi-structured tables. arXiv preprint arXiv:1508.00305
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[22]
Mohammadreza Pourreza, Hailong Li, Ruoxi Sun, Yeounoh Chung, Shayan Talaei, Gaurav Tarlok Kakkar, Yu Gan, Amin Saberi, Fatma Ozcan, and Sercan O Arik. 2024. Chase-sql: Multi-path reasoning and preference optimized candidate selection in text-to-sql. arXiv preprint arXiv:2410.01943
- [23]
-
[24]
Yuan Sui, Mengyu Zhou, Mingjie Zhou, Shi Han, and Dongmei Zhang. 2024. Table meets llm: Can large language models understand structured table data? a benchmark and empirical study. In Proceedings of the 17th ACM International Conference on Web Search and Data Mining, pages 645--654
work page 2024
-
[25]
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivi \`e re, Mihir Sanjay Kale, Juliette Love, et al. 2024. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Lihan Wang, Bowen Qin, Binyuan Hui, Bowen Li, Min Yang, Bailin Wang, Binhua Li, Jian Sun, Fei Huang, Luo Si, et al. 2022 a . Proton: Probing schema linking information from pre-trained language models for text-to-sql parsing. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 1889--1898
work page 2022
-
[27]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022 b . Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [28]
-
[29]
Yuxiang Wang, Jianzhong Qi, and Junhao Gan. 2025 b . Accurate and regret-aware numerical problem solver for tabular question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 12775--12783
work page 2025
-
[30]
Zilong Wang, Hao Zhang, Chun-Liang Li, Julian Martin Eisenschlos, Vincent Perot, Zifeng Wang, Lesly Miculicich, Yasuhisa Fujii, Jingbo Shang, Chen-Yu Lee, and Tomas Pfister. 2024. Chain-of-table: Evolving tables in the reasoning chain for table understanding. ICLR
work page 2024
-
[31]
Zirui Wu and Yansong Feng. 2024. Protrix: Building models for planning and reasoning over tables with sentence context. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 4378--4406
work page 2024
-
[32]
Yunhu Ye, Binyuan Hui, Min Yang, Binhua Li, Fei Huang, and Yongbin Li. 2023. Large language models are versatile decomposers: Decomposing evidence and questions for table-based reasoning. In Proceedings of the 46th international ACM SIGIR conference on research and development in information retrieval, pages 174--184
work page 2023
- [33]
-
[34]
Peiying Yu, Guoxin Chen, and Jingjing Wang. 2025. https://doi.org/10.18653/v1/2025.acl-long.853 Table-critic: A multi-agent framework for collaborative criticism and refinement in table reasoning . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 17432--17451, Vienna, Austria. Associ...
-
[35]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, et al. 2018. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
work page 2018
-
[36]
Xuanliang Zhang, Dingzirui Wang, Longxu Dou, Qingfu Zhu, and Wanxiang Che. 2025. A survey of table reasoning with large language models. Frontiers of Computer Science, 19(9):199348
work page 2025
- [37]
-
[38]
Yilun Zhao, Lyuhao Chen, Arman Cohan, and Chen Zhao. 2024. Tapera: enhancing faithfulness and interpretability in long-form table qa by content planning and execution-based reasoning. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12824--12840
work page 2024
-
[39]
Wei Zhou, Mohsen Mesgar, Annemarie Friedrich, and Heike Adel. 2025. Efficient multi-agent collaboration with tool use for online planning in complex table question answering. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 945--968
work page 2025
-
[40]
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[41]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.