CoMelSinger: Discrete Token-Based Zero-Shot Singing Synthesis With Structured Melody Control and Guidance
Pith reviewed 2026-05-18 14:30 UTC · model grok-4.3
The pith
CoMelSinger achieves structured melody control in zero-shot singing synthesis by replacing text inputs with lyric and pitch tokens and using contrastive learning to reduce prosody leakage from acoustic prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CoMelSinger is a zero-shot SVS framework built on the MaskGCT architecture that replaces conventional text inputs with lyric and pitch tokens to preserve in-context generalization while enhancing melody conditioning, employs a coarse-to-fine contrastive learning strategy to explicitly regularize pitch redundancy between the acoustic prompt and melody input, and incorporates a lightweight encoder-only SVT module to align acoustic tokens with pitch and duration for fine-grained supervision.
What carries the argument
Coarse-to-fine contrastive learning strategy that regularizes pitch redundancy between the acoustic prompt and melody input while the model conditions on separate lyric and pitch tokens.
If this is right
- Pitch accuracy improves over competitive baselines in generated singing output.
- Timbre consistency is maintained across zero-shot transfers to new singers.
- Zero-shot transferability strengthens because melody conditioning no longer competes with prompt timbre.
- Frame-level pitch and duration alignment becomes available through the added SVT supervision module.
Where Pith is reading between the lines
- The same token-plus-contrastive pattern could be tested on related tasks such as instrumental music generation where one audio prompt must not leak timing or pitch into a separate control sequence.
- If the redundancy suppression holds across datasets, the approach might lower the amount of paired lyric-pitch data needed for training singing models in new languages.
- Real-world music apps could let users supply a short voice clip and a separate melody score without the voice sample overriding the intended notes.
Load-bearing premise
The coarse-to-fine contrastive learning strategy successfully suppresses pitch redundancy between the acoustic prompt and melody input without harming other aspects of generation quality or introducing new artifacts.
What would settle it
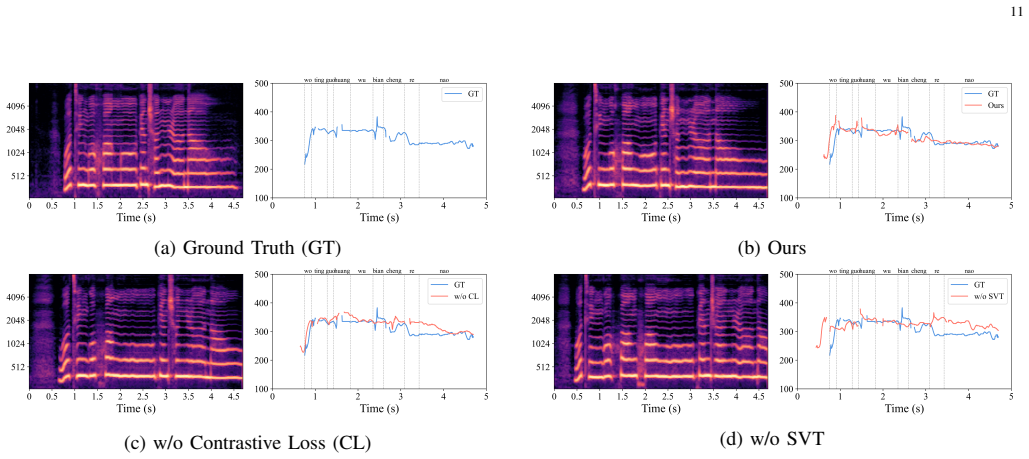
An ablation study in which removing the contrastive learning step yields no drop in pitch accuracy metrics or no rise in perceived artifacts would indicate the strategy is not performing the claimed disentanglement.
Figures




read the original abstract
Singing Voice Synthesis (SVS) aims to generate expressive vocal performances from structured musical inputs such as lyrics and pitch sequences. While recent progress in discrete codec-based speech synthesis has enabled zero-shot generation via in-context learning, directly extending these techniques to SVS remains non-trivial due to the requirement for precise melody control. In particular, prompt-based generation often introduces prosody leakage, where pitch information is inadvertently entangled within the timbre prompt, compromising controllability. We present CoMelSinger, a zero-shot SVS framework that enables structured and disentangled melody control within a discrete codec modeling paradigm. Built on the non-autoregressive MaskGCT architecture, CoMelSinger replaces conventional text inputs with lyric and pitch tokens, preserving in-context generalization while enhancing melody conditioning. To suppress prosody leakage, we propose a coarse-to-fine contrastive learning strategy that explicitly regularizes pitch redundancy between the acoustic prompt and melody input. Furthermore, we incorporate a lightweight encoder-only Singing Voice Transcription (SVT) module to align acoustic tokens with pitch and duration, offering fine-grained frame-level supervision. Experimental results demonstrate that CoMelSinger achieves notable improvements in pitch accuracy, timbre consistency, and zero-shot transferability over competitive baselines. Audio samples are available at https://danny-nus.github.io/CoMelSinger/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CoMelSinger, a zero-shot singing voice synthesis framework built on the non-autoregressive MaskGCT architecture. It replaces conventional text conditioning with lyric and pitch tokens to enable structured melody control, proposes a coarse-to-fine contrastive learning strategy to suppress prosody leakage between the acoustic prompt and melody input, and adds a lightweight encoder-only Singing Voice Transcription (SVT) module for frame-level pitch and duration alignment. The authors claim that these changes yield notable improvements in pitch accuracy, timbre consistency, and zero-shot transferability over competitive baselines, with audio samples provided for qualitative evaluation.
Significance. If the reported gains are robust and attributable to the proposed components, the work would represent a useful advance in controllable zero-shot SVS by addressing prosody leakage while retaining in-context generalization. The provision of audio samples is a positive step for perceptual assessment in this domain. The contrastive regularization approach is a plausible mechanism for the stated disentanglement goal.
major comments (2)
- [Experimental results / §5] The central claim of improved pitch accuracy and reduced prosody leakage rests on the coarse-to-fine contrastive learning strategy successfully suppressing pitch redundancy between the acoustic prompt and melody tokens. However, no ablation removing this component is reported, nor is a direct quantitative metric (such as pitch correlation scores or mutual information between prompt and melody tokens) provided to demonstrate the reduction in redundancy. This makes it impossible to isolate the contribution of the contrastive objective from the SVT module or other MaskGCT modifications.
- [§5] Table or figure presenting the main results (e.g., pitch accuracy and zero-shot metrics): without reported baseline numbers, standard deviations, or statistical significance tests, the magnitude of the claimed improvements cannot be assessed for practical relevance.
minor comments (2)
- [Abstract] The abstract uses the phrase 'notable improvements' without any numerical values; including at least one key metric (e.g., F0 error reduction) would improve clarity.
- [§3] Notation for the contrastive loss and SVT alignment objective could be introduced earlier with explicit definitions to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of experimental rigor that we will address to strengthen the presentation of our results. We respond to each major comment below.
read point-by-point responses
-
Referee: [Experimental results / §5] The central claim of improved pitch accuracy and reduced prosody leakage rests on the coarse-to-fine contrastive learning strategy successfully suppressing pitch redundancy between the acoustic prompt and melody tokens. However, no ablation removing this component is reported, nor is a direct quantitative metric (such as pitch correlation scores or mutual information between prompt and melody tokens) provided to demonstrate the reduction in redundancy. This makes it impossible to isolate the contribution of the contrastive objective from the SVT module or other MaskGCT modifications.
Authors: We agree that an explicit ablation isolating the coarse-to-fine contrastive learning strategy, together with direct quantitative metrics of pitch redundancy (e.g., correlation or mutual information between acoustic prompt and melody tokens), would more clearly demonstrate its contribution to suppressing prosody leakage. While the current experiments include comparisons of the full model against MaskGCT variants and other baselines, a dedicated ablation for this component alone was not reported. In the revised manuscript we will add this ablation study and the requested redundancy metrics to better separate the effect of the contrastive objective from the SVT module and other architectural changes. revision: yes
-
Referee: [§5] Table or figure presenting the main results (e.g., pitch accuracy and zero-shot metrics): without reported baseline numbers, standard deviations, or statistical significance tests, the magnitude of the claimed improvements cannot be assessed for practical relevance.
Authors: We acknowledge that including standard deviations and statistical significance tests would allow readers to better evaluate the practical significance of the reported gains. The main results table in §5 already presents comparisons against competitive baselines, but we will revise the table and accompanying text to explicitly report standard deviations computed over multiple runs and to include statistical significance tests (e.g., paired t-tests or Wilcoxon tests) for the primary metrics of pitch accuracy and zero-shot transferability. revision: yes
Circularity Check
No circularity: claims rest on proposed architecture and experimental results
full rationale
The paper proposes a new framework (CoMelSinger) built on MaskGCT with lyric/pitch tokens, a coarse-to-fine contrastive learning strategy to reduce prosody leakage, and an SVT module for alignment. Central claims of improved pitch accuracy and zero-shot transferability are presented as outcomes of these architectural and training choices, validated experimentally. No equations, parameters, or derivations reduce by construction to fitted inputs or self-referential definitions. Any self-citations are peripheral and not load-bearing for the core method or results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
coarse-to-fine contrastive learning strategy that explicitly regularizes pitch redundancy between the acoustic prompt and melody input
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Techsinger: Technique controllable multilingual singing voice synthesis via flow matching,
W. Guo, Y . Zhang, C. Pan, R. Huang, L. Tang, R. Li, Z. Hong, Y . Wang, and Z. Zhao, “Techsinger: Technique controllable multilingual singing voice synthesis via flow matching,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 22, 2025, pp. 23 978– 23 986
work page 2025
-
[2]
Sinsy: A deep neural network-based singing voice synthesis system,
Y . Hono, K. Hashimoto, K. Oura, Y . Nankaku, and K. Tokuda, “Sinsy: A deep neural network-based singing voice synthesis system,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 2803–2815, 2021
work page 2021
-
[3]
J.-S. Hwang, S.-H. Lee, and S.-W. Lee, “Hiddensinger: High-quality singing voice synthesis via neural audio codec and latent diffusion models,”Neural Networks, vol. 181, p. 106762, 2025
work page 2025
-
[4]
Diffsinger: Singing voice synthesis via shallow diffusion mechanism,
J. Liu, C. Li, Y . Ren, F. Chen, and Z. Zhao, “Diffsinger: Singing voice synthesis via shallow diffusion mechanism,” inProceedings of the AAAI conference on artificial intelligence, vol. 36, no. 10, 2022, pp. 11 020– 11 028
work page 2022
-
[5]
Comospeech: One-step speech and singing voice synthesis via consistency model,
Z. Ye, W. Xue, X. Tan, J. Chen, Q. Liu, and Y . Guo, “Comospeech: One-step speech and singing voice synthesis via consistency model,” in Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 1831–1839
work page 2023
-
[6]
Visinger: Variational inference with adversarial learning for end-to-end singing voice synthesis,
Y . Zhang, J. Cong, H. Xue, L. Xie, P. Zhu, and M. Bi, “Visinger: Variational inference with adversarial learning for end-to-end singing voice synthesis,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7237–7241
work page 2022
-
[7]
Stylesinger: Style transfer for out-of-domain singing voice synthesis,
Y . Zhang, R. Huang, R. Li, J. He, Y . Xia, F. Chen, X. Duan, B. Huai, and Z. Zhao, “Stylesinger: Style transfer for out-of-domain singing voice synthesis,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 17, 2024, pp. 19 597–19 605
work page 2024
-
[8]
Sintechsvs: A singing technique controllable singing voice synthesis system,
J. Zhao, L. Q. H. Chetwin, and Y . Wang, “Sintechsvs: A singing technique controllable singing voice synthesis system,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 2641–2653, 2024
work page 2024
-
[9]
Y . Zhang, H. Xue, H. Li, L. Xie, T. Guo, R. Zhang, and C. Gong, “Visinger2: High-fidelity end-to-end singing voice synthesis enhanced by digital signal processing synthesizer,” inInterspeech 2023, 2023, pp. 4444–4448
work page 2023
-
[10]
Hierarchical diffusion model for zero-shot singing voice synthesis with midi priors,
D.-M. Byun, S.-B. Kim, and S.-W. Lee, “Hierarchical diffusion model for zero-shot singing voice synthesis with midi priors,”IEEE Transac- tions on Audio, Speech and Language Processing, 2025
work page 2025
-
[11]
Midi-voice: Expressive zero-shot singing voice synthesis via midi-driven priors,
D.-M. Byun, S.-H. Lee, J.-S. Hwang, and S.-W. Lee, “Midi-voice: Expressive zero-shot singing voice synthesis via midi-driven priors,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 12 622–12 626
work page 2024
-
[12]
Make-a-voice: Unified voice synthesis with discrete representation,
R. Huang, C. Zhang, Y . Wang, D. Yang, L. Liu, Z. Ye, Z. Jiang, C. Weng, Z. Zhao, and D. Yu, “Make-a-voice: Unified voice synthesis with discrete representation,”arXiv preprint arXiv:2305.19269, 2023
-
[13]
Spsinger: Multi-singer singing voice synthesis with short reference prompt,
J. Zhao, C. Low, and Y . Wang, “Spsinger: Multi-singer singing voice synthesis with short reference prompt,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
work page 2025
-
[14]
Everyone-can-sing: Zero-shot singing voice synthesis and conversion with speech reference,
S. Dai, Y . Wang, R. B. Dannenberg, and Z. Jin, “Everyone-can-sing: Zero-shot singing voice synthesis and conversion with speech reference,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
work page 2025
-
[15]
Neural codec language models are zero-shot text to speech synthesizers,
S. Chen, C. Wang, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Li, L. He, S. Zhao, and F. Wei, “Neural codec language models are zero-shot text to speech synthesizers,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 705–718, 2025
work page 2025
-
[16]
Z. Du, Q. Chen, S. Zhang, K. Hu, H. Lu, Y . Yang, H. Hu, S. Zheng, Y . Gu, Z. Maet al., “Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens,”arXiv preprint arXiv:2407.05407, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wanget al., “Cosyvoice 2: Scalable streaming speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Maskgct: Zero-shot text-to-speech with masked generative codec transformer,
Y . Wang, H. Zhan, L. Liu, R. Zeng, H. Guo, J. Zheng, Q. Zhang, X. Zhang, S. Zhang, and Z. Wu, “Maskgct: Zero-shot text-to-speech with masked generative codec transformer,” inThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
work page 2025
-
[19]
Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, E. Liu, Y . Leng, K. Song, S. Tang, Z. Wu, T. Qin, X. Li, W. Ye, S. Zhang, J. Bian, L. He, J. Li, and S. Zhao, “Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,” inForty-first International Conference on Machine Learning, ICML 2024. OpenReview.net, 2024
work page 2024
-
[20]
H. Guo, F. Xie, K. Xie, D. Yang, D. Guo, X. Wu, and H. Meng, “Socodec: A semantic-ordered multi-stream speech codec for efficient language model based text-to-speech synthesis,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 645–651
work page 2024
-
[21]
Soundstorm: Efficient parallel audio generation,
Z. Borsos, M. Sharifi, D. Vincent, E. Kharitonov, N. Zeghidour, and M. Tagliasacchi, “Soundstorm: Efficient parallel audio generation,” arXiv preprint arXiv:2305.09636, 2023
-
[22]
Opencpop: A high-quality open source chinese popular song corpus for singing voice synthesis,
Y . Wang, X. Wang, P. Zhu, J. Wu, H. Li, H. Xue, Y . Zhang, L. Xie, and M. Bi, “Opencpop: A high-quality open source chinese popular song corpus for singing voice synthesis,” in23rd Annual Conference of the International Speech Communication Association, Interspeech 2022. ISCA, 2022, pp. 4242–4246
work page 2022
-
[23]
M4singer: A multi-style, multi-singer and musical score provided mandarin singing corpus,
L. Zhang, R. Li, S. Wang, L. Deng, J. Liu, Y . Ren, J. He, R. Huang, J. Zhu, X. Chenet al., “M4singer: A multi-style, multi-singer and musical score provided mandarin singing corpus,”Advances in Neural Information Processing Systems, vol. 35, pp. 6914–6926, 2022
work page 2022
-
[24]
Singstyle111: A multilingual singing dataset with style transfer,
S. Dai, Y . Wu, S. Chen, R. Huang, and R. B. Dannenberg, “Singstyle111: A multilingual singing dataset with style transfer,” inProceedings of the 24th International Society for Music Information Retrieval Conference, ISMIR 2023, 2023, pp. 765–773
work page 2023
-
[25]
Libritts: A corpus derived from librispeech for text-to-speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “Libritts: A corpus derived from librispeech for text-to-speech,” in20th Annual Conference of the International Speech Communication Association, Interspeech 2019. ISCA, 2019, pp. 1526–1530
work page 2019
-
[26]
Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation,
H. He, Z. Shang, C. Wang, X. Li, Y . Gu, H. Hua, L. Liu, C. Yang, J. Li, P. Shiet al., “Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation,” inIEEE Spoken Language Technology Workshop, SLT 2024. IEEE, 2024, pp. 885–890
work page 2024
-
[27]
Libri-light: A benchmark for asr with limited or no supervision,
J. Kahn, M. Riviere, W. Zheng, E. Kharitonov, Q. Xu, P.-E. Mazar ´e, J. Karadayi, V . Liptchinsky, R. Collobert, C. Fuegenet al., “Libri-light: A benchmark for asr with limited or no supervision,” in2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020. IEEE, 2020, pp. 7669–7673
work page 2020
-
[28]
Dctts: Discrete diffusion model with contrastive learning for text-to-speech generation,
Z. Wu, Q. Li, S. Liu, and Q. Yang, “Dctts: Discrete diffusion model with contrastive learning for text-to-speech generation,” inICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 11 336–11 340
work page 2024
-
[29]
Avqvc: One- shot voice conversion by vector quantization with applying contrastive learning,
H. Tang, X. Zhang, J. Wang, N. Cheng, and J. Xiao, “Avqvc: One- shot voice conversion by vector quantization with applying contrastive learning,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 4613–4617
work page 2022
-
[30]
Unsupervised speech decomposition via triple information bottleneck,
K. Qian, Y . Zhang, S. Chang, M. Hasegawa-Johnson, and D. Cox, “Unsupervised speech decomposition via triple information bottleneck,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 7836–7846
work page 2020
-
[31]
X. Zhao, F. Liu, C. Song, Z. Wu, S. Kang, D. Tuo, and H. Meng, “Dis- entangling content and fine-grained prosody information via hybrid asr bottleneck features for voice conversion,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7022–7026
work page 2022
-
[32]
Robust disentangled variational speech representation learning for zero-shot voice conversion,
J. Lian, C. Zhang, and D. Yu, “Robust disentangled variational speech representation learning for zero-shot voice conversion,” inICASSP 2022- 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6572–6576
work page 2022
-
[33]
Prosody-adaptable audio codecs for zero-shot voice conversion via in-context learning,
J. Zhao, X. Wang, and Y . Wang, “Prosody-adaptable audio codecs for zero-shot voice conversion via in-context learning,”arXiv preprint arXiv:2505.15402, 2025
-
[34]
V ocaloid-commercial singing synthesizer based on sample concatenation,
H. Kenmochi and H. Ohshita, “V ocaloid-commercial singing synthesizer based on sample concatenation,” inInterspeech, vol. 2007, 2007, pp. 4009–4010. 13
work page 2007
-
[35]
Synthesis of the singing voice by performance sampling and spectral models,
J. Bonada and X. Serra, “Synthesis of the singing voice by performance sampling and spectral models,”IEEE signal processing magazine, vol. 24, no. 2, pp. 67–79, 2007
work page 2007
-
[36]
An HMM-based singing voice synthesis system,
K. Saino, H. Zen, Y . Nankaku, A. Lee, and K. Tokuda, “An HMM-based singing voice synthesis system,” inProc. Interspeech 2006, 2006, pp. paper 2077–Thu1BuP.7
work page 2006
-
[37]
Xiaoicesing: A high- quality and integrated singing voice synthesis system,
P. Lu, J. Wu, J. Luan, X. Tan, and L. Zhou, “Xiaoicesing: A high- quality and integrated singing voice synthesis system,” in21st Annual Conference of the International Speech Communication Association, Interspeech 2020. ISCA, 2020, pp. 1306–1310
work page 2020
-
[38]
Deepsinger: Singing voice synthesis with data mined from the web,
Y . Ren, X. Tan, T. Qin, J. Luan, Z. Zhao, and T.-Y . Liu, “Deepsinger: Singing voice synthesis with data mined from the web,” inProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020, pp. 1979–1989
work page 2020
-
[39]
Wgansing: A multi- voice singing voice synthesizer based on the wasserstein-gan,
P. Chandna, M. Blaauw, J. Bonada, and E. G ´omez, “Wgansing: A multi- voice singing voice synthesizer based on the wasserstein-gan,” in2019 27th European signal processing conference (EUSIPCO). IEEE, 2019, pp. 1–5
work page 2019
-
[40]
Singgan: Generative adversarial network for high-fidelity singing voice generation,
R. Huang, C. Cui, F. Chen, Y . Ren, J. Liu, Z. Zhao, B. Huai, and Z. Wang, “Singgan: Generative adversarial network for high-fidelity singing voice generation,” inProceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 2525–2535
work page 2022
-
[41]
Toksing: Singing voice synthesis based on discrete tokens,
Y . Wu, C. Zhang, J. Shi, Y . Tang, S. Yang, and Q. Jin, “Toksing: Singing voice synthesis based on discrete tokens,” in25th Annual Conference of the International Speech Communication Association, Interspeech 2024. ISCA, 2024
work page 2024
-
[42]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM transactions on audio, speech, and language processing, vol. 29, pp. 3451–3460, 2021
work page 2021
-
[43]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449– 12 460, 2020
work page 2020
-
[44]
Speak foreign languages with your own voice: Cross-lingual neural codec language modeling,
Z. Zhang, L. Zhou, C. Wang, S. Chen, Y . Wu, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Liet al., “Speak foreign languages with your own voice: Cross-lingual neural codec language modeling,”arXiv preprint arXiv:2303.03926, 2023
-
[45]
Vall-e 2: Neural codec language models are human parity zero-shot text to speech synthesizers,
S. Chen, S. Liu, L. Zhou, Y . Liu, X. Tan, J. Li, S. Zhao, Y . Qian, and F. Wei, “Vall-e 2: Neural codec language models are human parity zero-shot text to speech synthesizers,”arXiv preprint arXiv:2406.05370, 2024
-
[46]
Vall-e r: Robust and efficient zero-shot text-to-speech synthesis via monotonic alignment,
B. Han, L. Zhou, S. Liu, S. Chen, L. Meng, Y . Qian, Y . Liu, S. Zhao, J. Li, and F. Wei, “Vall-e r: Robust and efficient zero-shot text-to-speech synthesis via monotonic alignment,”arXiv preprint arXiv:2406.07855, 2024
-
[47]
Accelerating codec-based speech synthesis with multi- token prediction and speculative decoding,
T. D. Nguyen, J.-H. Kim, J. Choi, S. Choi, J. Park, Y . Lee, and J. S. Chung, “Accelerating codec-based speech synthesis with multi- token prediction and speculative decoding,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
work page 2025
-
[48]
Prosody-tts: An end-to-end speech synthesis system with prosody control,
G. Pamisetty and K. Sri Rama Murty, “Prosody-tts: An end-to-end speech synthesis system with prosody control,”Circuits, Systems, and Signal Processing, vol. 42, no. 1, pp. 361–384, 2023
work page 2023
-
[49]
Hierarchical prosody modeling and control in non-autoregressive parallel neural tts,
T. Raitio, J. Li, and S. Seshadri, “Hierarchical prosody modeling and control in non-autoregressive parallel neural tts,” inICASSP 2022- 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7587–7591
work page 2022
-
[50]
J. Liu, Z. Liu, Y . Hu, Y . Gao, S. Zhang, and Z. Ling, “Diffstyletts: Diffusion-based hierarchical prosody modeling for text-to-speech with diverse and controllable styles,” inProceedings of the 31st International Conference on Computational Linguistics, COLING 2025. Association for Computational Linguistics, 2025, pp. 5265–5272
work page 2025
-
[51]
Drawspeech: Expressive speech synthesis using prosodic sketches as control conditions,
W. Chen, S. Yang, G. Li, and X. Wu, “Drawspeech: Expressive speech synthesis using prosodic sketches as control conditions,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
work page 2025
-
[52]
Expressive singing synthesis us- ing local style token and dual-path pitch encoder,
J. Lee, H.-S. Choi, and K. Lee, “Expressive singing synthesis us- ing local style token and dual-path pitch encoder,”arXiv preprint arXiv:2204.03249, 2022
-
[53]
Prompt-singer: Controllable singing-voice-synthesis with natural language prompt,
Y . Wang, R. Hu, R. Huang, Z. Hong, R. Li, W. Liu, F. You, T. Jin, and Z. Zhao, “Prompt-singer: Controllable singing-voice-synthesis with natural language prompt,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024. Association...
work page 2024
-
[54]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
CLAPSpeech: Learning prosody from text context with contrastive language-audio pre-training,
Z. Ye, R. Huang, Y . Ren, Z. Jiang, J. Liu, J. He, X. Yin, and Z. Zhao, “CLAPSpeech: Learning prosody from text context with contrastive language-audio pre-training,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Jul. 2023, pp. 9317–9331
work page 2023
-
[56]
Controlling prosody in end-to-end TTS: A case study on contrastive focus generation,
S. Latif, I. Kim, I. Calapodescu, and L. Besacier, “Controlling prosody in end-to-end TTS: A case study on contrastive focus generation,” inProceedings of the 25th Conference on Computational Natural Language Learning. Association for Computational Linguistics, Nov. 2021, pp. 544–551
work page 2021
-
[57]
Learning de- identified representations of prosody from raw audio,
J. Weston, R. Lenain, U. Meepegama, and E. Fristed, “Learning de- identified representations of prosody from raw audio,” inInternational Conference on Machine Learning. PMLR, 2021, pp. 11 134–11 145
work page 2021
-
[58]
Contrastive context-speech pretraining for expressive text-to-speech synthesis,
Y . Xiao, X. Wang, X. Tan, L. He, X. Zhu, S. Zhao, and T. Lee, “Contrastive context-speech pretraining for expressive text-to-speech synthesis,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 2099–2107
work page 2024
-
[59]
Symmetric cross entropy for robust learning with noisy labels,
Y . Wang, X. Ma, Z. Chen, Y . Luo, J. Yi, and J. Bailey, “Symmetric cross entropy for robust learning with noisy labels,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 322–330
work page 2019
-
[60]
Learn- ing speech representation from contrastive token-acoustic pretraining,
C. Qiang, H. Li, Y . Tian, R. Fu, T. Wang, L. Wang, and J. Dang, “Learn- ing speech representation from contrastive token-acoustic pretraining,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 10 196–10 200
work page 2024
-
[61]
Robust singing voice transcription serves synthesis,
R. Li, Y . Zhang, Y . Wang, Z. Hong, R. Huang, and Z. Zhao, “Robust singing voice transcription serves synthesis,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024. Association for Computational Linguistics, 2024, pp. 9751–9766
work page 2024
-
[62]
T. Wang, R. Fu, J. Yi, Z. Wen, and J. Tao, “Singing-tacotron: Global duration control attention and dynamic filter for end-to-end singing voice synthesis,” inProceedings of the 1st International Workshop on Deepfake Detection for Audio Multimedia, 2022, pp. 53–59
work page 2022
-
[63]
Fastspeech: Fast, robust and controllable text to speech,
Y . Ren, Y . Ruan, X. Tan, T. Qin, S. Zhao, Z. Zhao, and T.-Y . Liu, “Fastspeech: Fast, robust and controllable text to speech,”Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[64]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022
work page 2022
-
[65]
Multi-singer: Fast multi-singer singing voice vocoder with a large-scale corpus,
R. Huang, F. Chen, Y . Ren, J. Liu, C. Cui, and Z. Zhao, “Multi-singer: Fast multi-singer singing voice vocoder with a large-scale corpus,” in Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 3945–3954
work page 2021
-
[66]
Wavlm: Large-scale self-supervised pre- training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self-supervised pre- training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
work page 2022
-
[67]
Singmos: An extensive open- source singing voice dataset for mos prediction,
Y . Tang, J. Shi, Y . Wu, and Q. Jin, “Singmos: An extensive open- source singing voice dataset for mos prediction,”arXiv preprint arXiv:2406.10911, 2024
-
[68]
Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers,
K. Shen, Z. Ju, X. Tan, E. Liu, Y . Leng, L. He, T. Qin, S. Zhao, and J. Bian, “Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers,” inThe Twelfth International Conference on Learning Representations, ICLR 2024. OpenReview.net, 2024
work page 2024
-
[69]
Y . A. Li, X. Jiang, C. Han, and N. Mesgarani, “StyleTTS-ZS: Effi- cient high-quality zero-shot text-to-speech synthesis with distilled time- varying style diffusion,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Associatio...
work page 2025
-
[70]
Aishell-3: A multi-speaker mandarin tts corpus and the baselines,
Y . Shi, H. Bu, X. Xu, S. Zhang, and M. Li, “Aishell-3: A multi-speaker mandarin tts corpus and the baselines,”arXiv preprint arXiv:2010.11567, 2020
-
[71]
Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,”Advances in neural information processing systems, vol. 33, pp. 17 022–17 033, 2020
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.