Investigating the Representation of Backchannels and Fillers in Fine-tuned Language Models
Pith reviewed 2026-05-18 14:03 UTC · model grok-4.3
The pith
Fine-tuning enables language models to distinguish nuanced semantic variations in backchannels and fillers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
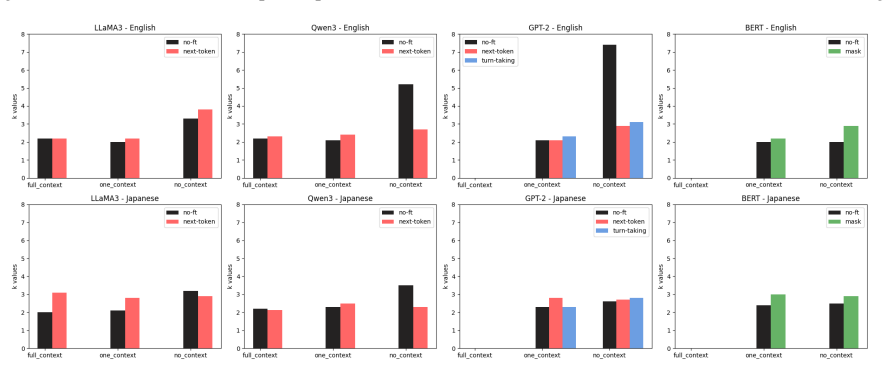
By fine-tuning transformer-based language models on dialogue corpora in English and Japanese where backchannels and fillers are preserved and annotated, the models learn representations that exhibit increased silhouette scores in clustering analyses, enabling them to distinguish nuanced semantic variations in the use of these expressions, while also generating utterances that more closely resemble human productions according to natural language generation metrics and qualitative analyses.
What carries the argument
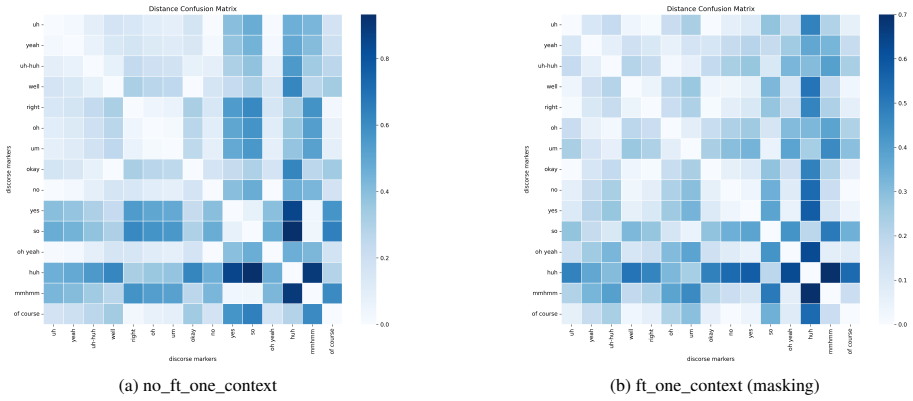
Clustering analysis applied to the learned representations of backchannels and fillers in fine-tuned models, which produces higher silhouette scores that separate different semantic uses.
If this is right
- Fine-tuned models distinguish nuanced semantic variations across different uses of backchannels and fillers.
- Utterances generated by fine-tuned models align more closely with human dialogue according to standard metrics.
- General language models can be turned into conversational models that handle human-like language more adequately.
Where Pith is reading between the lines
- Dialogue systems could gain better handling of listener feedback and turn-taking signals through similar fine-tuning.
- The method may extend to other subtle conversational cues in multilingual or task-oriented settings.
- Real interactive evaluations would test whether the measured improvements produce smoother conversations in practice.
Load-bearing premise
Higher silhouette scores in clustering and improved natural language generation metrics reliably reflect better semantic understanding rather than surface-level pattern matching.
What would settle it
Finding no gains in silhouette scores or human-likeness of generated output when the same fine-tuning is performed on versions of the corpora that remove or ignore backchannel and filler annotations.
Figures























read the original abstract
Backchannels and fillers are important linguistic expressions in dialogue, but often treated as 'noise' to be bypassed in modern transformer-based language models (LMs). Here, we study how they are represented in LMs using three fine-tuning strategies on three dialogue corpora in English and Japanese, in which backchannels and fillers are both preserved and annotated. This allows us to investigate how fine-tuning can help LMs learn these representations. We first apply clustering analysis to the learnt representation of backchannels and fillers, and find increased silhouette scores in representations from fine-tuned models, which suggests that fine-tuning enables LMs to distinguish the nuanced semantic variation in different backchannel and filler use. We also employ natural language generation metrics and qualitative analyses to verify that utterances produced by fine-tuned LMs resemble those produced by humans more closely. Our findings suggest the potential for transforming general LMs into conversational LMs that can produce human-like language more adequately.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates how fine-tuning affects representations of backchannels and fillers in transformer LMs. Using three fine-tuning strategies on annotated English and Japanese dialogue corpora, it reports higher silhouette scores from clustering of these tokens in fine-tuned models and claims this indicates better capture of nuanced semantic variation; it further uses NLG metrics and qualitative analysis to argue that fine-tuned models generate more human-like utterances.
Significance. If substantiated, the findings could help guide development of more dialogue-aware LMs by showing how fine-tuning can surface representations for phenomena typically treated as noise. The multilingual annotated corpora constitute a clear strength for cross-linguistic comparison.
major comments (2)
- [Abstract] Abstract: reports increased silhouette scores and closer human resemblance but provides no quantitative values, error bars, baseline comparisons, or details on data splits and statistical tests; the central claim therefore rests on high-level summary only.
- [Clustering analysis] Clustering analysis: silhouette scores quantify embedding separation but carry no information about what the clusters represent. Although the corpora are annotated, the reported analysis does not demonstrate alignment between cluster membership and annotated functions (e.g., continuer vs. assessment vs. surprise); without this alignment the scores may reflect surface statistics such as frequency or position rather than semantic nuance.
minor comments (2)
- [Methods] Expand the description of the three fine-tuning strategies, model checkpoints, and exact data splits to support reproducibility.
- [Results] Present full NLG metric tables with confidence intervals and significance tests rather than summary statements.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We value the recognition of our multilingual annotated corpora as a strength and the potential implications for dialogue-aware language models. We address each major comment below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: reports increased silhouette scores and closer human resemblance but provides no quantitative values, error bars, baseline comparisons, or details on data splits and statistical tests; the central claim therefore rests on high-level summary only.
Authors: We agree that the abstract summarizes results at a high level without specific numbers or details. In the revised manuscript, we will update the abstract to include key quantitative values such as the silhouette scores (with error bars or standard deviations where computed), baseline comparisons, information on data splits, and references to statistical tests supporting the improvements in clustering and generation quality. These additions will make the central claims more concrete while preserving conciseness. revision: yes
-
Referee: [Clustering analysis] Clustering analysis: silhouette scores quantify embedding separation but carry no information about what the clusters represent. Although the corpora are annotated, the reported analysis does not demonstrate alignment between cluster membership and annotated functions (e.g., continuer vs. assessment vs. surprise); without this alignment the scores may reflect surface statistics such as frequency or position rather than semantic nuance.
Authors: We acknowledge that silhouette scores alone measure separation without revealing cluster semantics, and that surface features could contribute. Although the corpora contain functional annotations, the current analysis does not explicitly align clusters with these labels. To address this directly, we will add an analysis in the revision that quantifies the correspondence between cluster membership and annotated functions (e.g., via contingency tables, cluster purity, or normalized mutual information). This will provide evidence that the improved separation in fine-tuned models reflects semantic nuance rather than frequency or positional artifacts alone. We will adjust our claims if the alignment proves weaker than anticipated. revision: yes
Circularity Check
No circularity: empirical metrics on annotated corpora
full rationale
The paper conducts an empirical study of fine-tuned language model representations for backchannels and fillers using clustering (silhouette scores) and NLG metrics on three annotated dialogue corpora. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the reported chain. The central claim rests on direct comparison of experimental outputs against baselines rather than any self-referential reduction of results to inputs by construction, rendering the analysis self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We first apply clustering analysis to the learnt representation of backchannels and fillers, and find increased silhouette scores in representations from fine-tuned models
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fine-tuning enables LMs to distinguish the nuanced semantic variation in different backchannel and filler use
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Herv \'e Abdi and Lynne J Williams. 2010. Principal component analysis. Wiley interdisciplinary reviews: computational statistics, 2(4):433--459
work page 2010
-
[4]
AI@Meta. 2024. https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md Llama 3 model card
work page 2024
-
[5]
2023 International Joint Conference on Neural Networks (IJCNN) , year =
Ahmed Amer, Chirag Bhuvaneshwara, Gowtham K. Addluri, Mohammed M. Shaik, Vedant Bonde, and Philipp Müller. 2023. https://doi.org/10.1109/IJCNN54540.2023.10191640 Backchannel detection and agreement estimation from video with transformer networks . In 2023 International Joint Conference on Neural Networks (IJCNN), pages 1--8
-
[6]
Anne H Anderson, Miles Bader, Ellen Gurman Bard, Elizabeth Boyle, Gwyneth Doherty, Simon Garrod, Stephen Isard, Jacqueline Kowtko, Jan McAllister, Jim Miller, et al. 1991. https://doi.org/10.1177/002383099103400404 The hcrc map task corpus . Language and speech, 34(4):351--366
-
[7]
Peter Ball. 1975. Listeners' responses to filled pauses in relation to floor apportionment. British Journal of Social & Clinical Psychology
work page 1975
-
[8]
Claire Augusta Bergey and Simon DeDeo. 2024. http://arxiv.org/abs/2403.08890 From "um" to "yeah": Producing, predicting, and regulating information flow in human conversation
-
[9]
Andr \'e Berthold and Anthony Jameson. 1999. https://doi.org/https://doi.org/10.1007/978-3-7091-2490-1_23 Interpreting symptoms of cognitive load in speech input . In UM99 User Modeling, pages 235--244, Vienna. Springer Vienna
-
[10]
Hendrik Buschmeier and Stefan Kopp. 2018. https://core.ac.uk/download/pdf/211847289.pdf Communicative listener feedback in human-agent interaction: Artificial speakers need to be attentive and adaptive . In Proceedings of the 17th international conference on autonomous agents and multiagent systems, pages 1213--1221
-
[11]
Eugene Charniak and Mark Johnson. 2001. https://aclanthology.org/N01-1016/ Edit detection and parsing for transcribed speech . In Second Meeting of the North A merican Chapter of the Association for Computational Linguistics
work page 2001
-
[12]
Grzegorz Chrupa a. 2023. https://doi.org/10.18653/v1/2023.findings-acl.495 Putting natural in natural language processing . In Findings of the Association for Computational Linguistics: ACL 2023, pages 7820--7827, Toronto, Canada. ACL
-
[13]
Herbert H. Clark. 1996. https://doi.org/10.1017/CBO9780511620539 Using Language . Cambridge University Press, Cambridge, UK
-
[14]
Herbert H. Clark and Jean E. Fox Tree . 2002. https://doi.org/https://doi.org/10.1016/S0010-0277(02)00017-3 Using uh and um in spontaneous speaking . Cognition, 84(1):73--111
-
[15]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. https://doi.org/10.18653/v1/N19-1423 BERT : Pre-training of deep bidirectional transformers for language understanding . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long a...
-
[16]
Mark Dingemanse and Andreas Liesenfeld. 2022. https://doi.org/10.18653/v1/2022.acl-long.385 From text to talk: H arnessing conversational corpora for humane and diversity-aware language technology . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5614--5633, Dublin, Ireland. ACL
-
[17]
Tanvi Dinkar, Chlo \'e Clavel, and Ioana Vasilescu. 2022. https://aclanthology.org/2022.tal-3.3/ Fillers in spoken language understanding: Computational and psycholinguistic perspectives . In Traitement Automatique des Langues, Volume 63, Num \'e ro 3 : Etats de l'art en TAL [Review articles in NLP] , pages 37--62, France. ATALA (Association pour le Trait...
work page 2022
-
[18]
Kaja Dobrovoljc and Matej Martinc. 2018. https://doi.org/10.18653/v1/W18-6005 Er ... well, it matters, right? on the role of data representations in spoken language dependency parsing . In Proceedings of the Second Workshop on Universal Dependencies ( UDW 2018) , pages 37--46, Brussels, Belgium. ACL
-
[19]
Erik Ekstedt and Gabriel Skantze. 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.268 T urn GPT : a transformer-based language model for predicting turn-taking in spoken dialog . In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 2981--2990, Online. ACL
-
[20]
Carol Figueroa, Adaeze Adigwe, Magalie Ochs, and Gabriel Skantze. 2022. https://aclanthology.org/2022.lrec-1.197/ Annotation of communicative functions of short feedback tokens in switchboard . In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 1849--1859, Marseille, France. ELRA
work page 2022
-
[21]
J.R. Firth. 1968. A synopsis of linguistic theory 1930-1955. In F.R. Palmer, editor, Selected Papers of J.R. Firth 1952-1959, pages 1--32. Longman. Reprinted from Studies in Linguistic Analysis, 1957, pp. 1--32
work page 1968
-
[22]
Jean E Fox Tree. 2010. https://doi.org/10.1111/j.1749-818X.2010.00195.x Discourse markers across speakers and settings . Language and linguistics compass, 4(5):269--281
-
[23]
Janet M. Fuller. 2003. https://doi.org/https://doi.org/10.1016/S0378-2166(02)00065-6 The influence of speaker roles on discourse marker use . Journal of Pragmatics, 35(1):23--45
-
[24]
Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. https://aclanthology.org/2021.emnlp-main.552 Simcse: Simple contrastive learning of sentence embeddings . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6894--6910, Online and Punta Cana, Dominican Republic. ACL
work page 2021
-
[25]
E.C. Holliman, J.J. Godfrey, and J. McDaniel. 1992. https://doi.org/10.1109/ICASSP.1992.225858 SWITCHBOARD: telephone speech corpus for research and development . In Acoustics, Speech, and Signal Processing, IEEE International Conference on, volume 2, pages 517--520, Los Alamitos, CA, USA. IEEE Computer Society
-
[26]
Julian Hough, Casey Kennington, David Schlangen, and Jonathan Ginzburg. 2015. https://aclanthology.org/W15-0125 Incremental semantics for dialogue processing: Requirements, and a comparison of two approaches . In Proceedings of the 11th International Conference on Computational Semantics, pages 206--216, London, UK. ACL
work page 2015
-
[27]
Christine Howes and Arash Eshghi. 2021. https://doi.org/10.1007/s10849-020-09328-1 Feedback relevance spaces: Interactional constraints on processing contexts in dynamic syntax . Journal of Logic, Language and Information, 30:331--362
-
[28]
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. 2021. https://doi.org/10.1109/TASLP.2021.3122291 Hubert: Self-supervised speech representation learning by masked prediction of hidden units . IEEE/ACM transactions on audio, speech, and language processing, 29:3451--3460
-
[29]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lo RA : Low-rank adaptation of large language models . In International Conference on Learning Representations
work page 2022
-
[30]
Ganesh Jawahar, Beno \^i t Sagot, and Djam \'e Seddah. 2019. https://doi.org/10.18653/v1/P19-1356 What does BERT learn about the structure of language? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3651--3657, Florence, Italy. ACL
-
[31]
Fredrik J rgensen. 2007. https://aclanthology.org/W07-2435/ The effects of disfluency detection in parsing spoken language . In Proceedings of the 16th Nordic Conference of Computational Linguistics ( NODALIDA 2007) , pages 240--244, Tartu, Estonia. University of Tartu, Estonia
work page 2007
-
[32]
Andreas Jucker. 1998. Discourse markers: Descriptions and theory. John Benjamin
work page 1998
-
[33]
And people just you know like ‘wow’
Andreas H. Jucker and Sara W. Smith. 1998. https://doi.org/10.1075/pbns.57.10juc “ And people just you know like ‘wow’”. Discourse markers as negotiating strategies . In Andreas H. Jucker and Yael Ziv, editors, Discourse Markers: Description and Theory, pages 171--201. John Benjamins, Amsterdam, The Netherlands
-
[34]
Masahito Kawamori, Akira Shimazu, and Takeshi Kawabata. 1996. A phonological study on japanese discourse markers. In Proceedings of the Korean Society for Language and Information Conference, pages 297--306. Korean Society for Language and Information
work page 1996
-
[35]
Martin Kay. 1992. Verbmobil: A Translation System for Face-to-Face Dialog. University of Chicago Press, Chicago, IL, USA
work page 1992
-
[36]
Yoonho Lee, Annie S Chen, Fahim Tajwar, Ananya Kumar, Huaxiu Yao, Percy Liang, and Chelsea Finn. 2023. https://openreview.net/forum?id=APuPRxjHvZ Surgical fine-tuning improves adaptation to distribution shifts . In The Eleventh International Conference on Learning Representations
work page 2023
-
[37]
Andreas Liesenfeld and Mark Dingemanse. 2022. https://aclanthology.org/2022.lrec-1.126/ Building and curating conversational corpora for diversity-aware language science and technology . In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 1178--1192, Marseille, France. European Language Resources Association
work page 2022
-
[38]
Amil Merchant, Elahe Rahimtoroghi, Ellie Pavlick, and Ian Tenney. 2020. https://doi.org/10.18653/v1/2020.blackboxnlp-1.4 What happens to BERT embeddings during fine-tuning? In Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, pages 33--44, Online. ACL
-
[39]
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. https://proceedings.neurips.cc/paper_files/paper/2013/file/9aa42b31882ec039965f3c4923ce901b-Paper.pdf Distributed representations of words and phrases and their compositionality . In Advances in Neural Information Processing Systems, volume 26. Curran
work page 2013
-
[40]
Hedderich, and Dietrich Klakow
Marius Mosbach, Anna Khokhlova, Michael A. Hedderich, and Dietrich Klakow. 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.227 O n the I nterplay B etween F ine-tuning and S entence-level P robing for L inguistic K nowledge in P re-trained T ransformers . In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 2502--2516, Online. ACL
-
[41]
Bill Noble and Vladislav Maraev. 2021. https://aclanthology.org/2021.iwcs-1.16 Large-scale text pre-training helps with dialogue act recognition, but not without fine-tuning . In Proceedings of the 14th International Conference on Computational Semantics (IWCS), pages 166--172, Groningen, The Netherlands (online). ACL
work page 2021
-
[42]
Toshiki Onishi, Naoki Azuma, Shunichi Kinoshita, Ryo Ishii, Atsushi Fukayama, Takao Nakamura, and Akihiro Miyata. 2023. https://doi.org/10.1145/3570945.3607298 Prediction of various backchannel utterances based on multimodal information . In Proceedings of the 23rd ACM International Conference on Intelligent Virtual Agents, IVA '23, New York, NY, USA. Ass...
-
[43]
Volha Petukhova and Harry Bunt. 2009. Towards a multidimensional semantics of discourse markers in spoken dialogue. In Proceedings of the Eight International Conference on Computational Semantics, pages 157--168
work page 2009
-
[44]
Ildiko Pilan, Laurent Pr \'e vot, Hendrik Buschmeier, and Pierre Lison. 2024. https://doi.org/10.18653/v1/2024.sigdial-1.38 Conversational feedback in scripted versus spontaneous dialogues: A comparative analysis . In Proceedings of the 25th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 440--457, Kyoto, Japan. ACL
-
[45]
Livia Qian and Gabriel Skantze. 2024. https://doi.org/10.21437/Interspeech.2024-1082 Joint learning of context and feedback embeddings in spoken dialogue . In Interspeech 2024, pages 2955--2959
-
[46]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine Mcleavey, and Ilya Sutskever. 2023. https://proceedings.mlr.press/v202/radford23a.html Robust speech recognition via large-scale weak supervision . In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 28492--28518. PMLR
work page 2023
-
[47]
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners
work page 2019
-
[48]
Ralph L Rose. 2015. Um and uh as differential delay markers: The role of contextual factors. In Proceedings of Disfluency in Spontaneous Speech (DiSS). The 7th Workshop on Disfluency in Spontaneous Speech, pages 73--76
work page 2015
-
[49]
Peter J. Rousseeuw. 1987. https://doi.org/10.1016/0377-0427(87)90125-7 Silhouettes: a graphical aid to the interpretation and validation of cluster analysis . Computational and Applied Mathematics, 20:53--65
-
[50]
Robin Ruede, Markus M \"u ller, Sebastian St \"u ker, and Alex Waibel. 2017. https://www.isca-archive.org/interspeech_2017/ruede17_interspeech.pdf Enhancing backchannel prediction using word embeddings. In Interspeech, pages 879--883
work page 2017
-
[51]
Serhad Sarica and Jianxi Luo. 2021. https://doi.org/10.1371/journal.pone.0254937 Stopwords in technical language processing . PLOS ONE, 16(8):1--13
-
[52]
Kei Sawada, Tianyu Zhao, Makoto Shing, Kentaro Mitsui, Akio Kaga, Yukiya Hono, Toshiaki Wakatsuki, and Koh Mitsuda. 2024. https://aclanthology.org/2024.lrec-main.1213 Release of pre-trained models for the J apanese language . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COL...
-
[53]
Lawrence Schourup. 1999. https://doi.org/https://doi.org/10.1016/S0024-3841(96)90026-1 Discourse markers . Lingua, 107(3):227--265
-
[54]
Gabriel Skantze. 2017. https://doi.org/10.18653/v1/W17-5527 Towards a general, continuous model of turn-taking in spoken dialogue using LSTM recurrent neural networks . In Proceedings of the 18th Annual SIG dial Meeting on Discourse and Dialogue , pages 220--230, Saarbr \"u cken, Germany. ACL
-
[55]
Gabriel Skantze. 2021. https://doi.org/10.1016/j.csl.2020.101178 Turn-taking in conversational systems and human-robot interaction: a review . Computer Speech & Language, 67:101178
-
[56]
it has the ability to make the other person feel comfortable
James Allen Todd. 2019. https://doi.org/https://doi.org/10.1016/j.lingua.2019.102737 “it has the ability to make the other person feel comfortable”: L1 japanese speakers’ folk descriptions of aizuchi . Lingua, 230:102737
-
[57]
Olcay T \"u rk, Petra Wagner, Hendrik Buschmeier, Angela Grimminger, Yu Wang, and Stefan Lazarov. 2023. https://pub.uni-bielefeld.de/download/2980545/2980546/Turk-etal-2023-MMSYM.pdf Mundex: A multimodal corpus for the study of the understanding of explanations . In Book of Abstracts of the 1st International Multimodal Communication Symposium
-
[58]
Mayumi Usami, editor. 2023. https://mmsrv.ninjal.ac.jp/btsj/corpus.html Building of a Japanese 1000 Person Natural Conversation Corpus for Pragmatic Analyses and Its Multilateral Studies, and NINJAL Institute-Based Projects: Multiple Approaches to Analyzing the Communication of Japanese Language Learners . NINJAL
work page 2023
-
[59]
Laurens Van der Maaten and Geoffrey Hinton. 2008. http://jmlr.org/papers/v9/vandermaaten08a.html Visualizing data using t-SNE . Journal of Machine Learning Research, 86:2579--2605
work page 2008
-
[60]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. https://doi.org/10.18653/v1/W18-5446 GLUE : A multi-task benchmark and analysis platform for natural language understanding . In Proceedings of the 2018 EMNLP Workshop B lackbox NLP : Analyzing and Interpreting Neural Networks for NLP , pages 353--355, Brussels, Be...
-
[61]
Siyang Wang, Joakim Gustafson, and \'E va Sz \'e kely. 2022. https://aclanthology.org/2022.lrec-1.210/ Evaluating sampling-based filler insertion with spontaneous TTS . In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 1960--1969, Marseille, France. European Language Resources Association
work page 2022
-
[62]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
https://huggingface.co/rinna/japanese-gpt2-medium rinna/japanese-gpt2-medium
Tianyu Zhao and Kei Sawada. https://huggingface.co/rinna/japanese-gpt2-medium rinna/japanese-gpt2-medium
-
[64]
Zheng Zhao, Yftah Ziser, and Shay B Cohen. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.847 Layer by layer: Uncovering where multi-task learning happens in instruction-tuned large language models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 15195--15214, Miami, Florida, USA. ACL
-
[65]
Yichu Zhou and Vivek Srikumar. 2021. https://doi.org/10.18653/v1/2021.naacl-main.401 D irect P robe: Studying representations without classifiers . In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5070--5083, Online. ACL
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.