Aligning Inductive Bias for Data-Efficient Generalization in State Space Models
Pith reviewed 2026-05-18 14:52 UTC · model grok-4.3
The pith
Task-Dependent Initialization aligns state space model bias with task spectra to boost data-efficient generalization when defaults mismatch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
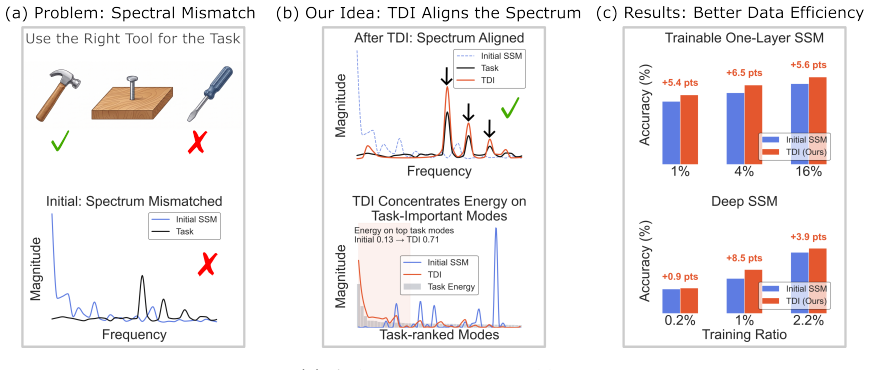
The paper claims that the inductive bias of linear time-invariant SSMs can be formalized as an SSM-induced kernel whose spectrum is governed by the frequency response. This leads to Task-Dependent Initialization, a power-spectrum matching technique that aligns the initial bias with the task's spectral properties prior to downstream training, thereby improving data-efficient generalization primarily under conditions of present task-relevant spectral structure and spectral mismatch in the default bias.
What carries the argument
Task-Dependent Initialization (TDI), a fast power-spectrum matching method that aligns the initial SSM bias with task spectral characteristics using the SSM-induced kernel.
If this is right
- TDI improves data-efficient generalization in controlled synthetic experiments when spectral structure is present.
- TDI enhances performance of trainable one-layer SSMs under conditions of spectral mismatch.
- TDI benefits deep SSMs on diverse real-world benchmarks when the default bias is spectrally mismatched.
- The gains appear primarily when task-relevant spectral structure is present and the default SSM bias does not match it.
Where Pith is reading between the lines
- The spectrum-matching idea could be adapted to initialize other sequence models such as transformers for similar data-efficiency gains.
- Testing TDI in settings with shifting tasks might reveal whether the alignment holds up in continual learning scenarios.
- Combining TDI with learned or hybrid biases could create more flexible starting points for sequence models.
- Kernel-spectrum analysis might serve as a diagnostic tool to spot inductive bias problems across a wider range of architectures.
Load-bearing premise
The spectrum of the SSM-induced kernel is governed by the model's frequency response in a way that allows power-spectrum matching to produce a useful alignment of inductive bias before downstream training.
What would settle it
Experiments on tasks with clear spectral structure where TDI shows no improvement or degrades performance compared to standard initialization would indicate the alignment does not reliably aid generalization.
Figures


read the original abstract
The remarkable success of modern AI has been closely tied to scaling laws, yet the finite supply of high-quality data makes data efficiency--learning more from less--an increasingly important frontier. A model's inductive bias is a critical lever for data efficiency, but foundational sequence models such as State Space Models (SSMs) often rely on fixed, task-agnostic biases. When this fixed prior is misaligned with the underlying structure of a task, the model may require additional samples to overcome its own bias before learning the relevant signal. In this work, we introduce a principled framework for understanding and aligning the inductive bias of linear time-invariant SSMs. We first formalize this bias through an SSM-induced kernel and show theoretically and empirically that its spectrum is governed by the model's frequency response. This characterization motivates Task-Dependent Initialization (TDI), a fast power-spectrum matching method that aligns the initial SSM bias with the task's spectral characteristics before downstream training. Across controlled synthetic experiments, trainable one-layer SSMs, and deep SSMs on diverse real-world benchmarks, TDI can improve data-efficient generalization primarily when task-relevant spectral structure is present and the default SSM bias is spectrally mismatched. Our results provide both a theoretical lens and a practical tool for task-adaptive inductive bias, suggesting a path toward more data-efficient sequence modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the inductive bias of linear time-invariant State Space Models (SSMs) can be formalized via an SSM-induced kernel whose spectrum is governed by the model's frequency response. This motivates Task-Dependent Initialization (TDI), a power-spectrum matching procedure that aligns the initial SSM bias with a task's spectral characteristics before training. Empirical results across synthetic experiments, one-layer SSMs, and deep SSMs on real-world benchmarks show improved data-efficient generalization primarily when task-relevant spectral structure exists and the default SSM bias is mismatched.
Significance. If the central claims hold, the work supplies both a theoretical characterization of SSM inductive bias and a practical, fast initialization method for task-adaptive alignment. The combination of controlled synthetic tests with one-layer and deep SSM evaluations on benchmarks provides a reasonably strong empirical foundation for the data-efficiency gains under spectral mismatch conditions.
major comments (1)
- [Abstract and the extension to trainable models] The theoretical characterization (Abstract and the kernel-spectrum derivation) is developed for linear time-invariant SSMs, yet the central empirical claims extend to trainable one-layer and deep SSMs. Gradient updates can alter realized poles/zeros and thus the effective kernel spectrum within a few steps; the manuscript must demonstrate that the initial power-spectrum alignment persists after training or otherwise controls the post-training kernel spectrum, otherwise the attribution of generalization gains to sustained spectral alignment rather than incidental initialization effects is weakened.
minor comments (2)
- [Method section] Clarify the exact procedure for applying power-spectrum matching in multi-layer SSMs, including whether matching is performed independently per layer or on the composite kernel.
- [Experiments] Add explicit comparison of pre- and post-training frequency responses or kernel spectra in the synthetic experiments to directly test persistence of alignment.
Simulated Author's Rebuttal
We appreciate the referee's careful reading and insightful comments on our work. We respond to the major comment below, clarifying the scope of our theoretical results and proposing revisions to better connect them to the empirical findings on trainable models.
read point-by-point responses
-
Referee: [Abstract and the extension to trainable models] The theoretical characterization (Abstract and the kernel-spectrum derivation) is developed for linear time-invariant SSMs, yet the central empirical claims extend to trainable one-layer and deep SSMs. Gradient updates can alter realized poles/zeros and thus the effective kernel spectrum within a few steps; the manuscript must demonstrate that the initial power-spectrum alignment persists after training or otherwise controls the post-training kernel spectrum, otherwise the attribution of generalization gains to sustained spectral alignment rather than incidental initialization effects is weakened.
Authors: We thank the referee for highlighting this important distinction. Our theoretical analysis indeed focuses on LTI SSMs to derive the kernel-spectrum relationship in a controlled setting. For the trainable cases, we view TDI primarily as an initialization technique rather than a claim of sustained spectral alignment throughout training. The empirical gains in data-efficient generalization, particularly in the synthetic experiments where spectral mismatch is explicitly controlled, suggest that starting with a better-aligned bias facilitates faster learning of the relevant features, even as parameters evolve. To directly address the concern, we will revise the manuscript to include an analysis of the frequency response evolution during training. Specifically, we plan to add plots showing the power spectrum of the SSM kernel at initialization and at various training checkpoints for the one-layer and deep models. This will help illustrate the extent to which the initial alignment persists or influences the learned model. If the alignment does not fully persist, we will discuss the benefits in terms of improved optimization trajectories. We believe this addition will strengthen the paper and clarify the mechanism behind the observed improvements. revision: yes
Circularity Check
Derivation self-contained via external task spectrum and independent benchmarks
full rationale
The paper defines an SSM-induced kernel to formalize inductive bias, derives that its spectrum follows the frequency response (theoretically and empirically), and uses this to motivate TDI as power-spectrum matching to an externally observed task spectrum. No equations reduce the claimed alignment or generalization gains to a fitted parameter or self-citation by construction; experiments on synthetic cases, one-layer models, and real-world deep SSMs provide separate validation. The central result therefore retains independent content.
Axiom & Free-Parameter Ledger
free parameters (1)
- power-spectrum matching parameters
axioms (1)
- domain assumption The spectrum of the SSM-induced kernel is governed by the model's frequency response
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.2 (Frequency response governs the SSM-induced spectrum). ... ˜η_j ∼ |H(ω_j)|²
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Definition 2 (Spectral Matching Loss). L_spec = ||S_model/||S_model|| − S_task/||S_task|||²
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
[2024] propose spectral initializations to better control frequency response
analyze and tune this bias, and Agarwal et al. [2024] propose spectral initializations to better control frequency response. In contrast, we connect the SSM frequency response to an induced kernel spectrum and explicitly relate this spectrum to task-model alignment and sample efficiency. Initialization and data-dependent adaptation.Initialization plays an...
work page 2024
-
[2]
Thus, the SVD of˜TTT is determined by the SVD ofMMM = SSS(VVV ⊤QQQ)DDD, where ˜TTT = U UMΣM VMU UMΣM VMU UMΣM VM ⊤QQQ⊤ for MMM = UMΣM VMUMΣM VMUMΣM VM ⊤. Since bothVVV ⊤ and QQQ are orthogonal,VVV ⊤QQQ is itself an orthogonal change of basis: it maps the Fourier basisVVV ⊤ into the eigenbasis of the data covariance (columns of QQQ). Therefore, the singula...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.