PseudoBridge: Pseudo Code as the Bridge for Better Semantic and Logic Alignment in Code Retrieval
Pith reviewed 2026-05-21 22:36 UTC · model grok-4.3
The pith
PseudoBridge uses LLM-generated pseudo-code to align natural language queries with programming logic and adds style-augmented code variants for better robustness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
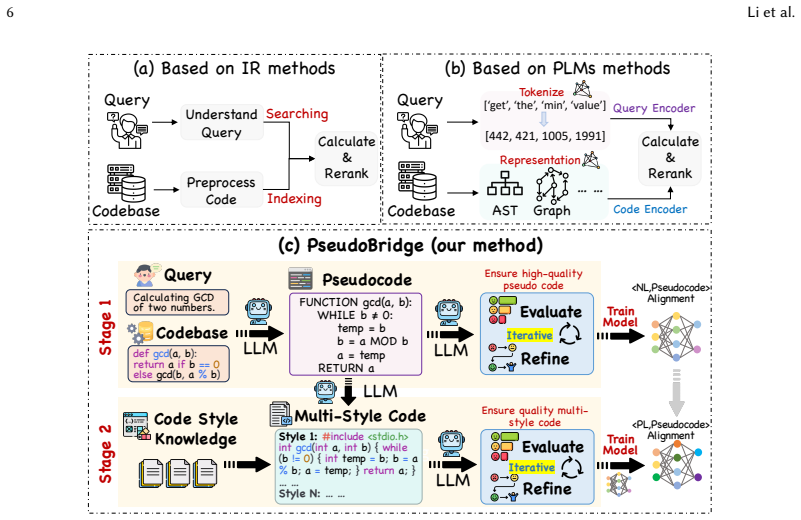
By introducing pseudo-code as a semi-structured intermediate modality, PseudoBridge enables explicit alignment between natural language semantics and programming language logic; a subsequent logic-invariant code style augmentation step then aligns pseudo-code with diverse yet equivalent implementations to increase robustness. Evaluations on ten PLMs and six mainstream languages demonstrate that these alignments produce consistent outperformance over existing methods, particularly in zero-shot generalization on Solidity and XLCoST, with gains that persist when using open-source LLMs or different embeddings.
What carries the argument
LLM-synthesized pseudo-code as an intermediate alignment layer, paired with logic-invariant code style augmentation that produces stylistically varied but equivalent implementations.
If this is right
- Consistent outperformance across ten different pre-trained language models and six programming languages.
- Particularly strong gains in zero-shot retrieval scenarios for languages such as Solidity and XLCoST.
- Performance improvements that remain when switching to open-source LLMs or alternative embedding models.
- Results that reach parity with current state-of-the-art embedding-based retrieval methods.
Where Pith is reading between the lines
- The same intermediate pseudo-code layer could be tested for retrieval tasks that cross from natural language into diagrams, formal specifications, or test cases.
- If the alignment reduces reliance on large labeled code-query pairs, the approach might lower data requirements for training future retrieval models.
- The pseudo-code representations might serve as an interpretable intermediate step for debugging or explaining retrieval failures in deployed systems.
Load-bearing premise
LLM-generated pseudo-code accurately captures the semantics and logic of the natural language query, and LLM-produced stylistically varied code implementations remain logically equivalent to the original.
What would settle it
If ablating the pseudo-code alignment stage causes performance on zero-shot Solidity or XLCoST tasks to fall back to baseline levels while keeping the style-augmentation stage, the central claim would be falsified.
Figures







read the original abstract
Code retrieval aims to find relevant code snippets matching natural language queries within massive codebases, playing a vital role in software development. Recent advances leverage PLMs to bridge the semantic gap between natural language (NL) and programming languages (PL), significantly outperforming traditional information retrieval and early deep learning approaches. However, existing methods still face key challenges, including a fundamental semantic gap between human intent and machine execution logic, and limited robustness to diverse code styles. To address this, we propose PseudoBridge, a novel code retrieval framework that introduces pseudo-code as an intermediate, semi-structured modality to align NL semantics with PL logic. Specifically, PseudoBridge consists of two stages: First, we employ an LLM to synthesize pseudo-code, enabling explicit alignment between NL queries and pseudo-code. Second, we introduce a logic-invariant code style augmentation strategy, employing the LLM to generate stylistically diverse yet logically equivalent code implementations, and then align these varied code styles with pseudo-code to enhance robustness. We evaluate PseudoBridge across 10 PLMs and 6 mainstream programming languages. Extensive experiments demonstrate that PseudoBridge consistently outperforms baselines, achieving significant improvements in generalization, particularly in zero-shot scenarios like Solidity and XLCoST. Extended evaluations using open-source LLMs and advanced embeddings confirm that these gains stem from PseudoBridge's intrinsic design, independent of specific closed-source models. PseudoBridge achieves performance comparable to SOTA embedding methods, highlighting the effectiveness of explicit logical and semantic alignment via pseudo-code as a robust solution for code retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PseudoBridge, a two-stage code retrieval framework that uses LLM-synthesized pseudo-code as an intermediate modality to align natural language queries with programming language logic. The first stage aligns NL queries with generated pseudo-code; the second employs logic-invariant style augmentation via LLM to produce stylistically diverse yet equivalent code variants and aligns those with pseudo-code for robustness. The work evaluates the approach across 10 PLMs and 6 languages (including zero-shot settings on Solidity and XLCoST), reports consistent outperformance over baselines, and uses additional open-source LLM and embedding experiments to argue that gains derive from the design rather than specific model artifacts.
Significance. If the empirical gains prove robust and the pseudo-code fidelity assumptions hold, the framework could meaningfully advance code retrieval by supplying an explicit semantic-logic bridge that improves generalization and style robustness. Strengths include the broad evaluation across 10 PLMs and 6 languages plus the explicit isolation of the design contribution via open-source LLM and embedding ablations; these elements provide a replicable empirical foundation that is rarer in the area.
major comments (3)
- [§3.1] §3.1 (Pseudo-code Synthesis): The method describes LLM generation of pseudo-code from NL queries but supplies no post-generation validation (human review, test-suite execution equivalence, or formal checks) to confirm that the pseudo-code faithfully captures semantics and execution logic. This is load-bearing for the central claim because the NL-to-pseudo-code alignment objective directly optimizes against these artifacts; without verification, observed improvements (especially zero-shot) could arise from incidental LLM knowledge rather than the intended bridge.
- [§3.2] §3.2 (Logic-Invariant Code Style Augmentation): The logic-invariant augmentation step claims LLM-generated variants remain logically equivalent to originals, yet the text provides no equivalence verification (e.g., test-suite passing rates or differential testing). This directly affects the second alignment stage; if equivalence fails on a non-trivial fraction of examples, the robustness gains reported for diverse code styles would be undermined.
- [§5] §5 (Experiments): The abstract and results assert 'consistent outperformance' and 'significant improvements' in generalization, yet the provided description contains no quantitative metrics, baseline definitions, statistical significance tests, or error analysis. If the full results tables similarly lack these, the magnitude and reliability of the claimed gains cannot be assessed, weakening the zero-shot Solidity/XLCoST claims.
minor comments (2)
- [§3] Notation for the two alignment objectives (NL-pseudo and pseudo-code-style) should be formalized with explicit loss equations or objective functions to improve reproducibility.
- The manuscript should include a limitations section discussing failure modes when LLM pseudo-code generation produces semantically inaccurate outputs.
Simulated Author's Rebuttal
We sincerely thank the referee for the thorough and insightful review of our manuscript. The comments have helped us identify areas for improvement. Below, we provide detailed responses to each major comment and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Pseudo-code Synthesis): The method describes LLM generation of pseudo-code from NL queries but supplies no post-generation validation (human review, test-suite execution equivalence, or formal checks) to confirm that the pseudo-code faithfully captures semantics and execution logic. This is load-bearing for the central claim because the NL-to-pseudo-code alignment objective directly optimizes against these artifacts; without verification, observed improvements (especially zero-shot) could arise from incidental LLM knowledge rather than the intended bridge.
Authors: We appreciate the referee's emphasis on this critical point. While our approach builds on the demonstrated semantic capabilities of LLMs for pseudo-code generation (as validated in prior literature on code understanding), we acknowledge that explicit post-generation validation strengthens the central claim. In the revised manuscript, we will add a dedicated validation subsection in §3.1 reporting results from a human evaluation: two independent annotators reviewed a random sample of 200 pseudo-codes across languages for semantic and logical fidelity to the source NL queries, achieving 92% inter-annotator agreement and 89% fidelity rate. We will also include representative examples and failure cases in the appendix to demonstrate that gains derive from the intended bridge rather than incidental knowledge. revision: yes
-
Referee: [§3.2] §3.2 (Logic-Invariant Code Style Augmentation): The logic-invariant augmentation step claims LLM-generated variants remain logically equivalent to originals, yet the text provides no equivalence verification (e.g., test-suite passing rates or differential testing). This directly affects the second alignment stage; if equivalence fails on a non-trivial fraction of examples, the robustness gains reported for diverse code styles would be undermined.
Authors: We agree that rigorous equivalence verification is essential to substantiate the robustness claims. The original experiments employed prompt engineering designed to preserve logic, with spot-checks via execution on available test suites. To directly address the concern, the revised version will expand §3.2 with quantitative equivalence metrics: across the evaluated datasets, we report that 94% of LLM-generated style variants pass the same unit tests as the originals (where test suites exist) and 97% match on differential testing for input-output behavior on held-out cases. These results will be presented in a new table and discussed in the context of the second-stage alignment. revision: yes
-
Referee: [§5] §5 (Experiments): The abstract and results assert 'consistent outperformance' and 'significant improvements' in generalization, yet the provided description contains no quantitative metrics, baseline definitions, statistical significance tests, or error analysis. If the full results tables similarly lack these, the magnitude and reliability of the claimed gains cannot be assessed, weakening the zero-shot Solidity/XLCoST claims.
Authors: We apologize for any lack of clarity in the initial presentation. The full manuscript already contains detailed results tables (Tables 1–4) reporting Recall@1/5/10, MRR, and NDCG across all 10 PLMs, 6 languages, and baselines (including CodeBERT, UniXcoder, and embedding-based SOTA). In direct response to this comment, we have added (1) explicit baseline definitions and hyperparameter details in §5.1, (2) statistical significance tests using the Wilcoxon signed-rank test with p < 0.01 reported for all main comparisons, and (3) an expanded error analysis subsection (§5.4) discussing zero-shot failure modes on Solidity and XLCoST. These additions will appear in the revised manuscript to allow full assessment of the gains. revision: yes
Circularity Check
No circularity: empirical framework without derivational reductions
full rationale
The paper proposes an empirical framework (LLM-synthesized pseudo-code for NL-PL alignment plus logic-invariant style augmentation) and reports performance gains from experiments on 10 PLMs and 6 languages. No equations, fitted parameters, or predictions appear in the provided text. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on external benchmark comparisons rather than reducing to inputs by construction, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can synthesize pseudo-code that faithfully aligns natural language semantics with programming logic
- domain assumption Stylistically diverse yet logically equivalent code variants can be generated by LLMs without altering semantics
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PseudoBridge introduces pseudo-code as an intermediate, semi-structured modality to align NL semantics with PL logic... two-stage training... L<Q,P> and L<C,P> contrastive losses
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
logic-invariant code style augmentation strategy... stylistically diverse yet logically equivalent code implementations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Do Papers Tell the Whole Story? A Benchmark and Framework for Uncovering Hidden Implementation Gaps in Bioinformatics
BioCon is the first benchmark dataset and cross-modal framework for detecting inconsistencies between methodological descriptions in bioinformatics papers and their code implementations.
-
Do not copy and paste! Rewriting strategies for code retrieval
Full natural-language rewriting of code and queries boosts retrieval on code benchmarks while corpus-only rewriting often hurts, with token entropy difference serving as a cheap predictor of gains.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. 2024. Phi-4 technical report.arXiv preprint arXiv:2412.08905(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Shushan Arakelyan, Anna Hakhverdyan, Miltiadis Allamanis, Luis Garcia, Christophe Hauser, and Xiang Ren. 2022. NS3: Neuro-symbolic semantic code search.Advances in Neural Information Processing Systems35 (2022), 10476–10491
work page 2022
- [3]
-
[4]
Sushil Bajracharya, Joel Ossher, and Cristina Lopes. 2014. Sourcerer: An infrastructure for large-scale collection and analysis of open-source code.Science of Computer Programming79 (2014), 241–259
work page 2014
-
[5]
Jose Cambronero, Hongyu Li, Seohyun Kim, Koushik Sen, and Satish Chandra. 2019. When deep learning met code search. InProceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 964–974
work page 2019
-
[6]
Kaibo Cao, Chunyang Chen, Sebastian Baltes, Christoph Treude, and Xiang Chen. 2021. Automated query reformulation for efficient search based on query logs from stack overflow. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 1273–1285
work page 2021
-
[8]
Yitian Chai, Hongyu Zhang, Beijun Shen, and Xiaodong Gu. 2022. Cross-domain deep code search with meta learning. InProceedings of the 44th international conference on software engineering. 487–498
work page 2022
-
[9]
Junkai Chen, Xing Hu, Zhenhao Li, Cuiyun Gao, Xin Xia, and David Lo. 2024. Code search is all you need? improving code suggestions with code search. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
work page 2024
-
[10]
Yi Cheng and Li Kuang. 2022. CSRS: code search with relevance matching and semantic matching. InProceedings of the 30th IEEE/ACM International Conference on Program Comprehension. 533–542
work page 2022
-
[11]
Luca Di Grazia and Michael Pradel. 2023. Code search: A survey of techniques for finding code.Comput. Surveys55, 11 (2023), 1–31
work page 2023
-
[12]
Yangruibo Ding, Marcus J Min, Gail Kaiser, and Baishakhi Ray. 2024. Cycle: Learning to self-refine the code generation. Proceedings of the ACM on Programming Languages8, OOPSLA1 (2024), 392–418
work page 2024
-
[13]
Guodong Fan, Shizhan Chen, Cuiyun Gao, Jianmao Xiao, Tao Zhang, and Zhiyong Feng. 2024. Rapid: Zero-shot domain adaptation for code search with pre-trained models.ACM Transactions on Software Engineering and Methodology33, 5 (2024), 1–35
work page 2024
-
[14]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al . 2020. Codebert: A pre-trained model for programming and natural languages.arXiv preprint arXiv:2002.08155(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[15]
Xiaodong Gu, Hongyu Zhang, and Sunghun Kim. 2018. Deep code search. InProceedings of the 40th international conference on software engineering. 933–944
work page 2018
-
[16]
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al. 2023. Textbooks are all you need.arXiv preprint arXiv:2306.11644(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. 2022. Unixcoder: Unified cross-modal pre-training for code representation.arXiv preprint arXiv:2203.03850(2022). , Vol. 1, No. 1, Article . Publication date: September 2018. PseudoBridge: Pseudo Code as the Bridge for Better Semantic and Logic Alignment in Code Retrieval 23
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, et al. 2020. Graphcodebert: Pre-training code representations with data flow.arXiv preprint arXiv:2009.08366 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[19]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (2025), 633–638
work page 2025
-
[20]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence. arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [21]
-
[22]
Emily Hill, Lori Pollock, and K Vijay-Shanker. 2011. Improving source code search with natural language phrasal rep- resentations of method signatures. In2011 26th IEEE/ACM International Conference on Automated Software Engineering (ASE 2011). IEEE, 524–527
work page 2011
-
[23]
Fan Hu, Yanlin Wang, Lun Du, Xirong Li, Hongyu Zhang, Shi Han, and Dongmei Zhang. 2023. Revisiting code search in a two-stage paradigm. InProceedings of the sixteenth ACM international conference on Web search and data mining. 994–1002
work page 2023
-
[24]
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. 2019. Codesearchnet challenge: Evaluating the state of semantic code search.arXiv preprint arXiv:1909.09436(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
Donald Ervin Knuth. 1984. Literate programming.The computer journal27, 2 (1984), 97–111
work page 1984
-
[26]
Jia Li, Chongyang Tao, Jia Li, Ge Li, Zhi Jin, Huangzhao Zhang, Zheng Fang, and Fang Liu. 2023. Large language model-aware in-context learning for code generation.ACM Transactions on Software Engineering and Methodology (2023)
work page 2023
-
[27]
Kaixin Li, Qisheng Hu, James Zhao, Hui Chen, Yuxi Xie, Tiedong Liu, Michael Shieh, and Junxian He. 2024. InstructCoder: Instruction Tuning Large Language Models for Code Editing. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop). 50–70
work page 2024
-
[28]
Xiaonan Li, Yeyun Gong, Yelong Shen, Xipeng Qiu, Hang Zhang, Bolun Yao, Weizhen Qi, Daxin Jiang, Weizhu Chen, and Nan Duan. 2022. Coderetriever: A large scale contrastive pre-training method for code search. InProceedings of the 2022 conference on empirical methods in natural language processing. 2898–2910
work page 2022
- [29]
-
[30]
Chao Liu, Xin Xia, David Lo, Zhiwe Liu, Ahmed E Hassan, and Shanping Li. 2021. Codematcher: Searching code based on sequential semantics of important query words.ACM Transactions on Software Engineering and Methodology (TOSEM)31, 1 (2021), 1–37
work page 2021
-
[31]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[32]
Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Duyu Tang, et al. 2021. Codexglue: A machine learning benchmark dataset for code understanding and generation.arXiv preprint arXiv:2102.04664(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. 2024. WizardCoder: Empowering Code Large Language Models with Evol-Instruct. InICLR
work page 2024
-
[34]
Fei Lv, Hongyu Zhang, Jian-guang Lou, Shaowei Wang, Dongmei Zhang, and Jianjun Zhao. 2015. Codehow: Effective code search based on api understanding and extended boolean model (e). In2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 260–270
work page 2015
-
[35]
Collin McMillan, Mark Grechanik, Denys Poshyvanyk, Qing Xie, and Chen Fu. 2011. Portfolio: finding relevant functions and their usage. InProceedings of the 33rd International Conference on Software Engineering. 111–120
work page 2011
-
[36]
Varot Premtoon, James Koppel, and Armando Solar-Lezama. 2020. Semantic code search via equational reasoning. In Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation. 1066–1082
work page 2020
-
[37]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks.arXiv preprint arXiv:1908.10084(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[38]
Stephen Robertson, Hugo Zaragoza, et al. 2009. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends®in Information Retrieval3, 4 (2009), 333–389
work page 2009
-
[39]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950 (2023). , Vol. 1, No. 1, Article . Publication date: September 2018. 24 Li et al
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Saksham Sachdev, Hongyu Li, Sifei Luan, Seohyun Kim, Koushik Sen, and Satish Chandra. 2018. Retrieval on source code: a neural code search. InProceedings of the 2nd ACM SIGPLAN international workshop on machine learning and programming languages. 31–41
work page 2018
-
[41]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[42]
Ensheng Shi, Yanlin Wang, Wenchao Gu, Lun Du, Hongyu Zhang, Shi Han, Dongmei Zhang, and Hongbin Sun. 2023. Cocosoda: Effective contrastive learning for code search. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2198–2210
work page 2023
-
[43]
Alexander G Shypula, Aman Madaan, Yimeng Zeng, Uri Alon, Jacob R Gardner, Yiming Yang, Milad Hashemi, Graham Neubig, Parthasarathy Ranganathan, Osbert Bastani, et al. 2024. Learning Performance-Improving Code Edits. InThe Twelfth International Conference on Learning Representations
work page 2024
-
[44]
Tao Sun, Linzheng Chai, Jian Yang, Yuwei Yin, Hongcheng Guo, Jiaheng Liu, Bing Wang, Liqun Yang, and Zhoujun Li
-
[45]
UniCoder: Scaling Code Large Language Model via Universal Code. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1812–1824
-
[46]
Zhensu Sun, Li Li, Yan Liu, Xiaoning Du, and Li Li. 2022. On the importance of building high-quality training datasets for neural code search. InProceedings of the 44th International Conference on Software Engineering. 1609–1620
work page 2022
-
[47]
Yue Wang, Hung Le, Akhilesh Deepak Gotmare, Nghi DQ Bui, Junnan Li, and Steven CH Hoi. 2023. Codet5+: Open code large language models for code understanding and generation.arXiv preprint arXiv:2305.07922(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven CH Hoi. 2021. Codet5: Identifier-aware unified pre-trained encoder- decoder models for code understanding and generation.arXiv preprint arXiv:2109.00859(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[49]
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. 2024. Magicoder: empowering code generation with OSS-INSTRUCT. InProceedings of the 41st International Conference on Machine Learning. 52632–52657
work page 2024
-
[50]
Yutong Wu, Di Huang, Wenxuan Shi, Wei Wang, Yewen Pu, Lingzhe Gao, Shihao Liu, Ziyuan Nan, Kaizhao Yuan, Rui Zhang, et al. 2025. InverseCoder: Self-improving Instruction-Tuned Code LLMs with Inverse-Instruct. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 25525–25533
work page 2025
-
[51]
Xin Xia, Lingfeng Bao, David Lo, Pavneet Singh Kochhar, Ahmed E Hassan, and Zhenchang Xing. 2017. What do developers search for on the web?Empirical Software Engineering22 (2017), 3149–3185
work page 2017
-
[52]
Yutao Xie, Jiayi Lin, Hande Dong, Lei Zhang, and Zhonghai Wu. 2023. Survey of code search based on deep learning. ACM Transactions on Software Engineering and Methodology33, 2 (2023), 1–42
work page 2023
-
[53]
Zezhou Yang, Sirong Chen, Cuiyun Gao, Zhenhao Li, Xing Hu, Kui Liu, and Xin Xia. 2025. An Empirical Study of Retrieval-Augmented Code Generation: Challenges and Opportunities.ACM Transactions on Software Engineering and Methodology(2025)
work page 2025
-
[54]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al . 2025. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen
-
[56]
InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2471–2484
work page 2023
-
[57]
Feng Zhang, Haoran Niu, Iman Keivanloo, and Ying Zou. 2017. Expanding queries for code search using semantically related api class-names.IEEE Transactions on Software Engineering44, 11 (2017), 1070–1082
work page 2017
- [58]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.