LogitTrace: Detecting Benchmark Contamination via Layerwise Logit Trajectories
Pith reviewed 2026-05-18 14:29 UTC · model grok-4.3
The pith
Contaminated benchmark examples commit to answers earlier across layerwise logit trajectories than clean examples do.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
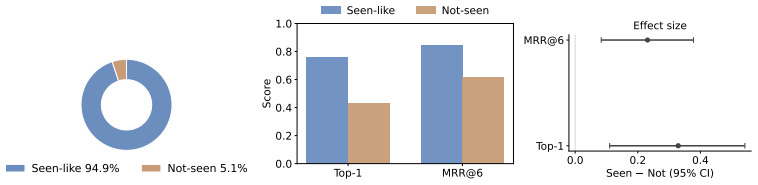
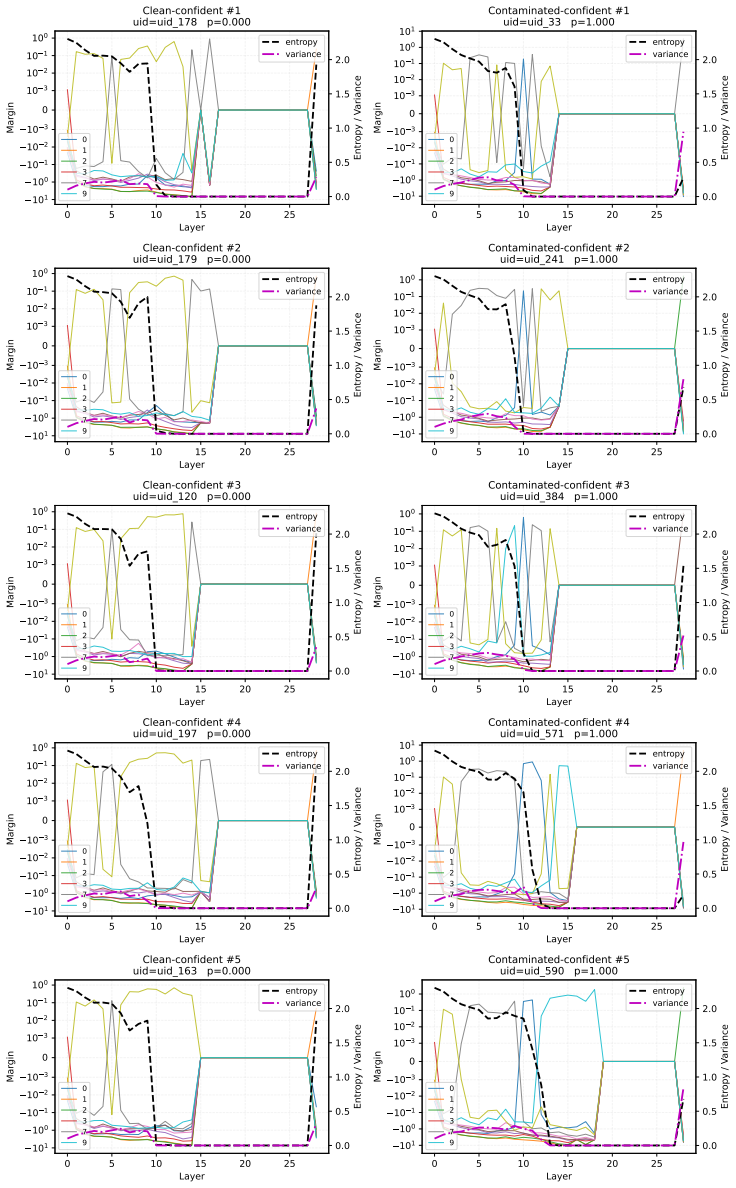
LogitTrace tracks the evolving logit values assigned to candidate answers as they pass through successive layers of the model. Contaminated examples display earlier commitment, with the target answer's logit rising sharply and stabilizing sooner, whereas clean examples show slower, more incremental growth consistent with step-by-step evidence accumulation. These patterns allow a simple classifier to distinguish contamination status across different models and input variants. Controlled experiments that inject target samples via LoRA reproduce the same early-commitment signatures, linking the observed trajectories to repeated exposure during training.
What carries the argument
Layerwise logit trajectories that record how preference logits for possible answers change from early to late layers, revealing the timing of decision stabilization.
If this is right
- Benchmark scores on tasks such as AIME or Math500 can be audited for hidden contamination using signals available inside the model itself.
- Detection continues to function on reworded or paraphrased questions that break surface-overlap and completion-based checks.
- The same layerwise view supplies a new observable for studying how memorization alters internal computation rather than just final outputs.
- Trajectory features could be monitored during evaluation to flag potential data leakage without requiring the original training corpus.
Where Pith is reading between the lines
- Interventions that slow early commitment on seen examples might reduce inflated performance on contaminated benchmarks.
- The method could extend to detecting memorization induced by fine-tuning rather than pretraining exposure.
- Combining trajectory signals with existing overlap-based detectors might raise overall reliability without added external data.
Load-bearing premise
The observed differences in trajectory timing are produced by memorization from contamination rather than by question difficulty, prompt format, or model-specific factors that happen to align with contamination labels.
What would settle it
Finding that clean but unusually difficult examples produce the same early-commitment trajectory shape as known contaminated ones, or that rephrasing alone alters trajectories independently of contamination status.
Figures








read the original abstract
Large language models (LLMs) are commonly evaluated on challenging benchmarks such as AIME and Math500, where benchmark contamination can make memorized solutions appear as genuine reasoning. Existing detection methods largely rely on surface overlap, completion behavior, or final-output likelihood, and often degrade when inputs are simply rephrased. In this paper, we propose LogitTrace(Layerwise Logit Trajectories), a framework for analyzing memorization-like decision dynamics through intermediate logit trajectories. Instead of judging memorization only from the final answer, LogitTrace examines how model preferences emerge and stabilize across layers. We find that contaminated examples tend to show earlier commitment, while clean examples exhibit more gradual evidence accumulation. These trajectory signals allow a lightweight classifier to separate contaminated and clean examples across multiple models and input variants. Controlled LoRA injection experiments further show that repeated exposure to target samples induces similar trajectory patterns. Overall, our results suggest that LogitTrace provides evidence beyond surface overlap and final-output confidence, offering a useful lens for studying memorization-like behavior in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LogitTrace, a framework for detecting benchmark contamination in LLMs by analyzing layerwise logit trajectories rather than final outputs or surface overlap. It claims that contaminated examples exhibit earlier commitment to answers across layers, while clean examples show more gradual evidence accumulation; these signals enable a lightweight classifier to separate the two across models and input variants. Controlled LoRA injection experiments are presented as further evidence that repeated exposure induces similar trajectory patterns.
Significance. If the central claim holds after controls, the work offers a potentially useful internal-model lens on memorization that could complement existing detection methods and improve evaluation reliability on benchmarks such as AIME and Math500. The LoRA injection component provides a controlled causal test that is a methodological strength.
major comments (2)
- [Experimental Setup / Abstract] The central claim requires that trajectory differences are caused by contamination-induced memorization. However, the manuscript provides no indication that contaminated and clean examples are matched or controlled for question difficulty, length, lexical features, or prompt formatting (see skeptic note and abstract description of experiments). These factors independently modulate evidence accumulation speed; without regression controls, propensity matching, or difficulty-stratified ablations, the classifier separation and LoRA results risk being spurious.
- [Abstract / Results] The abstract states that a classifier works and that LoRA reproduces the pattern, yet reports no quantitative results, error bars, dataset sizes, accuracy metrics, or statistical tests. This absence makes it impossible to assess effect sizes, reproducibility, or whether post-hoc choices affect the separation claim.
minor comments (2)
- [Method] Clarify the precise operational definition of 'earlier commitment' (e.g., the layer index at which the target logit first exceeds a threshold or the rate of logit stabilization).
- [Introduction] Add a short related-work paragraph situating LogitTrace against prior internal-representation analyses of memorization.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of experimental rigor that we address below. We have revised the manuscript to incorporate additional controls and quantitative reporting as outlined in the point-by-point responses.
read point-by-point responses
-
Referee: [Experimental Setup / Abstract] The central claim requires that trajectory differences are caused by contamination-induced memorization. However, the manuscript provides no indication that contaminated and clean examples are matched or controlled for question difficulty, length, lexical features, or prompt formatting (see skeptic note and abstract description of experiments). These factors independently modulate evidence accumulation speed; without regression controls, propensity matching, or difficulty-stratified ablations, the classifier separation and LoRA results risk being spurious.
Authors: We agree that explicit controls for question difficulty, length, lexical features, and prompt formatting are necessary to strengthen the attribution of trajectory differences to contamination. Our original experiments drew contaminated and clean examples from the same benchmark distributions to reduce some baseline differences, but we did not report formal matching or regression adjustments. In the revision we will add difficulty-stratified ablations (binning by proxy difficulty metrics such as average model performance on held-out similar items), propensity-score matching on length and lexical overlap, and regression controls that partial out these covariates when evaluating classifier separation and LoRA-induced patterns. These additions will directly address the concern that the observed signals could be confounded. revision: yes
-
Referee: [Abstract / Results] The abstract states that a classifier works and that LoRA reproduces the pattern, yet reports no quantitative results, error bars, dataset sizes, accuracy metrics, or statistical tests. This absence makes it impossible to assess effect sizes, reproducibility, or whether post-hoc choices affect the separation claim.
Authors: The referee is correct that the abstract and high-level results summary omitted concrete metrics. The full manuscript contains the underlying experiments, but these details were not elevated to the abstract. We will revise the abstract to report dataset sizes (number of contaminated and clean examples per model), classifier accuracy with standard deviations across multiple runs or folds, and statistical significance tests comparing trajectory features between conditions. Error bars will be added to figures, and a summary table of quantitative results will be included in the main text so that effect sizes and reproducibility can be evaluated directly. revision: yes
Circularity Check
No significant circularity in LogitTrace derivation chain
full rationale
The paper's central method observes empirical differences in layerwise logit trajectories (earlier commitment for contaminated examples vs. gradual accumulation for clean ones) and trains a lightweight classifier on these signals, with supporting LoRA injection experiments to induce similar patterns via repeated exposure. No derivation step reduces by construction to self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The approach relies on observable model behaviors across models and input variants rather than tautological inputs, making the chain self-contained against external contamination benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Differences in layerwise logit trajectories reliably indicate memorization versus genuine reasoning.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
contaminated samples tend to lock onto an answer with high confidence much earlier in the forward pass, whereas clean samples exhibit more gradual evidence accumulation
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use the logit lens to project intermediate hidden states into the output space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[2]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, et al. Extracting training data from large language models. In USENIX Security Symposium, 2021
work page 2021
-
[3]
Quantifying memorization across neural language models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. Quantifying memorization across neural language models. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[4]
Investigating data contamination in modern benchmarks for large language models
Chunyuan Deng, Yilun Zhao, Xiangru Tang, Mark Gerstein, and Arman Cohan. Investigating data contamination in modern benchmarks for large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2024
work page 2024
-
[5]
Yiheng Dong, Yuxin Guo, Yuxiang Wang, Yinpeng Chen, Xiaohui Sun, Lei Zhang, and Heng Ji. Generalization or memorization? data contamination and trustworthy evaluation for large language models. In Findings of the Association for Computational Linguistics: ACL 2024, 2024
work page 2024
-
[6]
Duarte, Xuandong Zhao, Arlindo L
André V. Duarte, Xuandong Zhao, Arlindo L. Oliveira, and Lei Li. DE-COP : Detecting copyrighted content in language models training data, 2024
work page 2024
-
[7]
Data contamination quiz: A tool to detect and estimate contamination in large language models, 2023
Shahriar Golchin and Mihai Surdeanu. Data contamination quiz: A tool to detect and estimate contamination in large language models, 2023
work page 2023
-
[8]
Time travel in LLMs : Tracing data contamination in large language models
Shahriar Golchin and Mihai Surdeanu. Time travel in LLMs : Tracing data contamination in large language models. In Proceedings of the 2024 International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[9]
Copyright violations and large language models
Antonia Karamolegkou, Jiaang Li, Li Zhou, and Anders S gaard. Copyright violations and large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
work page 2023
-
[10]
Memorization or reasoning? exploring the idiom understanding of llms
Jisu Kim, Youngwoo Shin, Uiji Hwang, Jihun Choi, Richeng Xuan, and Taeuk Kim. Memorization or reasoning? exploring the idiom understanding of llms. arXiv preprint arXiv:2505.16216, 2025
-
[11]
Muhammed Yusuf Kocyigit, Eleftheria Briakou, Daniel Deutsch, Jiaming Luo, Colin Cherry, and Markus Freitag. Overestimation in llm evaluation: A controlled large-scale study on data contamination’s impact on machine translation, 2025
work page 2025
-
[12]
Aochong Oliver Li and Tanya Goyal. Memorization vs. reasoning: Updating llms with new knowledge. In Findings of the Association for Computational Linguistics: ACL 2025, 2025
work page 2025
-
[13]
Task contamination: Language models may not be few-shot anymore, 2023
Changmao Li and Jeffrey Flanigan. Task contamination: Language models may not be few-shot anymore, 2023
work page 2023
-
[14]
Lost in the Middle: How Language Models Use Long Contexts
Xuefeng Li, Jason Wei, Denny Zhou, et al. Evaluating verbal reasoning in language models. arXiv preprint arXiv:2307.03172, 2023 a
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Estimating contamination via perplexity: Quantifying memorisation in language model evaluation
Yucheng Li et al. Estimating contamination via perplexity: Quantifying memorisation in language model evaluation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023 b
work page 2023
-
[16]
Feder Cooper, Daphne Ippolito, Christopher A
Milad Nasr, Javier Rando, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A. Feder Cooper, Daphne Ippolito, Christopher A. Choquette-Choo, Florian Tram \`e r, and Katherine Lee. Scalable extraction of training data from aligned, production language models. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[17]
Interpreting GPT : The logit lens, 2020
Nostalgebraist. Interpreting GPT : The logit lens, 2020. Online blog post
work page 2020
-
[18]
OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Avi Schwarzschild, Zhili Feng, Pratyush Maini, Zachary C. Lipton, and J. Zico Kolter. Memorization with compression: Rethinking llm memorization through the lens of adversarial compression. In Advances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[20]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, pp.\ 618--626, 2017
work page 2017
-
[21]
Detecting pretraining data from large language models
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[22]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Dice: Detecting in-distribution contamination in llm's fine-tuning phase for math reasoning
Shangqing Tu, Kejian Zhu, Yushi Bai, Zijun Yao, Lei Hou, and Juanzi Li. Dice: Detecting in-distribution contamination in llm's fine-tuning phase for math reasoning. arXiv preprint arXiv:2406.04197, 2024
-
[24]
Reasoning or memorization? unreliable results of reinforcement learning due to data contamination
Yifei Wu, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, et al. Reasoning or memorization? unreliable results of reinforcement learning due to data contamination. arXiv preprint arXiv:2503.04683, 2025
-
[25]
Jialiang Xu, Shenglan Li, Zhaozhuo Xu, and Denghui Zhang. Do llms know to respect copyright notice? In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024
work page 2024
-
[26]
arXiv preprint arXiv:2311.04850 , year =
Shuo Yang, Wei-Lin Chiang, Lianmin Zheng, Joseph E Gonzalez, and Ion Stoica. Rethinking benchmark and contamination for language models with rephrased samples. arXiv preprint arXiv:2311.04850, 2023
-
[27]
Data contamination can cross language barriers
Feng Yao, Yufan Zhuang, Zihao Sun, Sunan Xu, Animesh Kumar, and Jingbo Shang. Data contamination can cross language barriers. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024
work page 2024
-
[28]
Data contamination calibration for black-box llms
Wentao Ye, Jiaqi Hu, Liyao Li, Haobo Wang, Gang Chen, and Junbo Zhao. Data contamination calibration for black-box llms. In Findings of the Association for Computational Linguistics: ACL 2024, 2024
work page 2024
-
[29]
Codeipprompt: Intellectual property infringement assessment of code language models
Zhiyuan Yu, Yuhao Wu, Ning Zhang, Chenguang Wang, Yevgeniy Vorobeychik, and Chaowei Xiao. Codeipprompt: Intellectual property infringement assessment of code language models. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pp.\ 40373--40389. PMLR, 2023
work page 2023
-
[30]
Huixuan Zhang, Yun Lin, and Xiaojun Wan. PaCoST : Paired confidence significance testing for benchmark contamination detection in large language models. In Findings of the Association for Computational Linguistics: EMNLP 2024, 2024 a
work page 2024
-
[31]
Pre-training data detection for large language models: A divergence-based calibration method
Weichao Zhang, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan, and Xueqi Cheng. Pre-training data detection for large language models: A divergence-based calibration method. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024 b
work page 2024
-
[32]
Measuring copyright risks of large language models via partial information probing
Weijie Zhao, Huajie Shao, Zhaozhuo Xu, Suzhen Duan, and Denghui Zhang. Measuring copyright risks of large language models via partial information probing. In Proceedings of the International Conference on Data-Centric AI (DCAI), 2024
work page 2024
-
[33]
Don't make your llm an evaluation benchmark cheater
Kun Zhou, Yutao Zhu, Zhipeng Chen, Wentong Chen, Wayne Xin Zhao, Xu Chen, Yankai Lin, Ji-Rong Wen, and Jiawei Han. Don't make your llm an evaluation benchmark cheater. arXiv preprint arXiv:2311.01964, 2023
-
[34]
Inference-time decontamination: Reusing leaked benchmarks for large language model evaluation
Qin Zhu, Qinyuan Cheng, Runyu Peng, Xiaonan Li, Ru Peng, Tengxiao Liu, Xipeng Qiu, and Xuanjing Huang. Inference-time decontamination: Reusing leaked benchmarks for large language model evaluation. In Findings of the Association for Computational Linguistics: EMNLP 2024, 2024 a
work page 2024
-
[35]
Clean-eval: Clean evaluation on contaminated large language models
Wenhong Zhu, Hongkun Hao, Zhiwei He, Yunze Song, Yumeng Zhang, Hanxu Hu, Yiran Wei, Rui Wang, and Hongyuan Lu. Clean-eval: Clean evaluation on contaminated large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2024 b
work page 2024
-
[36]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[37]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[38]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[39]
b/G5O6 m= 'BV ۜ i?漠7S 1ɞ/ps>Yem'>y1 R a AV
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.