Every Subtlety Counts: Fine-grained Person Independence Micro-Action Recognition via Distributionally Robust Optimization
Pith reviewed 2026-05-18 13:35 UTC · model grok-4.3
The pith
Distributionally robust optimization learns person-agnostic representations for micro-action recognition by aligning temporal and frequency motion features while regularizing subgroup variance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
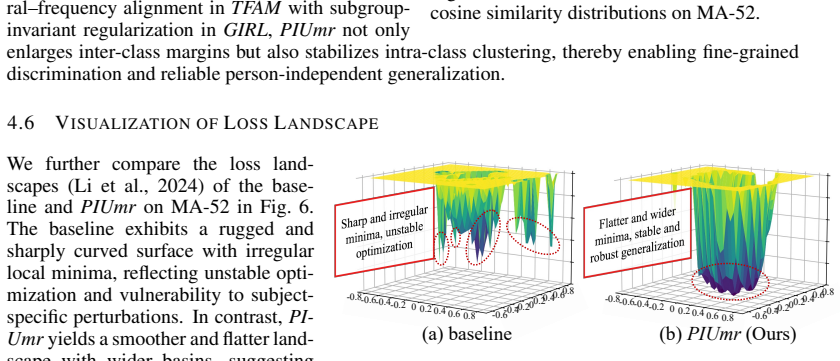
The Person Independence Universal Micro-action Recognition Framework integrates Distributionally Robust Optimization to learn person-agnostic representations. At the feature level, the Temporal-Frequency Alignment Module uses a dual-branch design where the temporal branch applies Wasserstein-regularized alignment to stabilize motion trajectories and the frequency branch introduces variance-guided perturbations for robustness to spectral differences, followed by consistency-driven fusion. At the loss level, the Group-Invariant Regularized Loss partitions samples into pseudo-groups to simulate unseen distributions, up-weights boundary cases, and regularizes subgroup variance to force the model
What carries the argument
The Person Independence Universal Micro-action Recognition Framework, which applies Distributionally Robust Optimization through a Temporal-Frequency Alignment Module at the feature level and a Group-Invariant Regularized Loss at the loss level to produce person-agnostic micro-action representations.
If this is right
- The framework outperforms prior methods in accuracy and robustness on the MA-52 dataset under fine-grained person-independent conditions.
- Plug-and-play modules can be added to other recognition pipelines at both feature and loss levels.
- Up-weighting boundary samples and regularizing subgroup variance forces models to handle difficult person-specific variations instead of relying on easy or frequent examples.
- Stable generalization holds when the same action manifests differently across individuals.
Where Pith is reading between the lines
- The same dual-branch alignment plus pseudo-group regularization could transfer to other fine-grained tasks such as gesture or facial micro-expression recognition where individual style varies.
- If the partitioning heuristic proves reliable, training datasets could require fewer distinct subjects while still supporting broad generalization.
- The variance-guided perturbations might generalize as a lightweight way to handle spectral variability in other time-series or video domains beyond micro-actions.
Load-bearing premise
Partitioning training samples into pseudo-groups successfully mimics distributions from unseen persons and that up-weighting boundary cases plus subgroup regularization will produce genuine generalization rather than artifacts from the partitioning step itself.
What would settle it
Measure accuracy drop when the trained model is tested on a fresh micro-action dataset recorded from entirely new individuals never seen during training or pseudo-group creation.
Figures





read the original abstract
Micro-action Recognition is vital for psychological assessment and human-computer interaction. However, existing methods often fail in real-world scenarios because inter-person variability causes the same action to manifest differently, hindering robust generalization. To address this, we propose the Person Independence Universal Micro-action Recognition Framework, which integrates Distributionally Robust Optimization principles to learn person-agnostic representations. Our framework contains two plug-and-play components operating at the feature and loss levels. At the feature level, the Temporal-Frequency Alignment Module normalizes person-specific motion characteristics with a dual-branch design: the temporal branch applies Wasserstein-regularized alignment to stabilize dynamic trajectories, while the frequency branch introduces variance-guided perturbations to enhance robustness against person-specific spectral differences. A consistency-driven fusion mechanism integrates both branches. At the loss level, the Group-Invariant Regularized Loss partitions samples into pseudo-groups to simulate unseen person-specific distributions. By up-weighting boundary cases and regularizing subgroup variance, it forces the model to generalize beyond easy or frequent samples, thus enhancing robustness to difficult variations. Experiments on the large-scale MA-52 dataset demonstrate that our framework outperforms existing methods in both accuracy and robustness, achieving stable generalization under fine-grained conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Person Independence Universal Micro-action Recognition Framework for fine-grained micro-action recognition robust to inter-person variability. It integrates Distributionally Robust Optimization via two plug-and-play modules: a Temporal-Frequency Alignment Module (with Wasserstein-regularized temporal alignment, variance-guided frequency perturbations, and consistency-driven fusion) at the feature level, and a Group-Invariant Regularized Loss (with pseudo-group partitioning of training samples, boundary-case up-weighting, and subgroup variance regularization) at the loss level. Experiments on the MA-52 dataset are reported to show improved accuracy and robustness over prior methods under person-independent conditions.
Significance. If the results hold, the work offers a practical DRO-based approach to person-agnostic micro-action representations with potential value for psychological assessment and HCI applications. The plug-and-play design and explicit handling of temporal-frequency characteristics are constructive extensions of existing DRO literature; reproducible code or parameter-free derivations would further strengthen the contribution.
major comments (2)
- [Group-Invariant Regularized Loss] §3.2 (Group-Invariant Regularized Loss): the pseudo-group partitioning is defined in terms of the model's predictions on the training data and is used to simulate unseen person-specific distributions. This construction is load-bearing for the person-independence claim, yet the manuscript provides no explicit validation (e.g., correlation analysis with ground-truth person labels or comparison against random/feature-space splits) that the resulting groups capture genuine inter-person motion variability rather than training-set artifacts. Without such evidence the DRO-style robustness may reduce to ordinary regularization.
- [Experiments] Experiments section and Table 1: the reported gains on MA-52 lack cross-person splits, error bars, or ablations isolating the pseudo-group heuristic. The central generalization claim therefore rests on aggregate accuracy numbers whose stability under person-independent evaluation cannot be assessed from the given results.
minor comments (2)
- Abstract and §2: the free parameters 'variance-guided perturbation strength' and 'subgroup variance regularization weight' are introduced without stating their values or tuning protocol; please report the exact settings used for all experiments.
- [Temporal-Frequency Alignment Module] §3.1 (Temporal-Frequency Alignment Module): the consistency-driven fusion step would benefit from an explicit equation or algorithm box to clarify how the temporal and frequency branches are combined.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment in detail below, providing clarifications on our methodology and committing to specific revisions that strengthen the presentation of our person-independence claims and experimental validation.
read point-by-point responses
-
Referee: [Group-Invariant Regularized Loss] §3.2 (Group-Invariant Regularized Loss): the pseudo-group partitioning is defined in terms of the model's predictions on the training data and is used to simulate unseen person-specific distributions. This construction is load-bearing for the person-independence claim, yet the manuscript provides no explicit validation (e.g., correlation analysis with ground-truth person labels or comparison against random/feature-space splits) that the resulting groups capture genuine inter-person motion variability rather than training-set artifacts. Without such evidence the DRO-style robustness may reduce to ordinary regularization.
Authors: We appreciate the referee's emphasis on validating the pseudo-group partitioning mechanism in §3.2. This partitioning is intentionally prediction-driven to identify subgroups that approximate worst-case distributions under the DRO framework, with boundary-case up-weighting and subgroup variance regularization explicitly designed to promote person-agnostic features rather than fitting training artifacts. While the current manuscript does not report explicit correlation analysis against ground-truth person labels or comparisons to random/feature-space splits, the approach follows established DRO practices for simulating distribution shifts. In the revised version we will add a dedicated analysis (including Pearson correlation with person identities on MA-52 and quantitative comparisons to alternative splits) to demonstrate that the pseudo-groups reflect genuine inter-person motion variability. This addition will be placed in the Experiments section as a new validation subsection. revision: yes
-
Referee: [Experiments] Experiments section and Table 1: the reported gains on MA-52 lack cross-person splits, error bars, or ablations isolating the pseudo-group heuristic. The central generalization claim therefore rests on aggregate accuracy numbers whose stability under person-independent evaluation cannot be assessed from the given results.
Authors: We thank the referee for noting the need for greater transparency in the experimental protocol. The MA-52 results were obtained under person-independent evaluation with training and test sets constructed to have no person overlap, consistent with the person-independence focus stated in the abstract and introduction. Nevertheless, we acknowledge that the manuscript would benefit from explicit documentation of the cross-person split procedure, reporting of error bars (mean ± std over multiple seeds), and an ablation isolating the pseudo-group heuristic within the Group-Invariant Regularized Loss. In the revision we will expand the Experiments section and Table 1 to include these elements, along with a targeted ablation comparing performance with and without the prediction-based partitioning. These changes will allow direct assessment of result stability under person-independent conditions. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper presents an empirical method paper proposing two plug-and-play modules (Temporal-Frequency Alignment Module with Wasserstein alignment and variance perturbations, plus Group-Invariant Regularized Loss with pseudo-group partitioning) under standard DRO principles drawn from prior literature. Performance claims rest on experiments against the external MA-52 benchmark rather than any closed mathematical derivation. No equations or steps are shown reducing a claimed prediction or generalization result to a fitted parameter or self-citation by construction. The pseudo-group heuristic is a design choice for simulating shifts, but the paper does not define the target robustness in terms of those groups in a self-referential loop. This is a normal non-circular empirical contribution.
Axiom & Free-Parameter Ledger
free parameters (2)
- variance-guided perturbation strength
- subgroup variance regularization weight
axioms (2)
- domain assumption Pseudo-groups formed by partitioning training samples can stand in for unseen person-specific distributions.
- domain assumption Wasserstein-regularized alignment and variance-guided perturbations together produce person-agnostic representations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Group-Invariant Regularized Loss (GIRL) partitions samples into pseudo-groups... up-weighting hard boundary cases and regularizing subgroup variance... LGIRL = Lgrp + λvar Rvar
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Temporal–Frequency Alignment Module... Wasserstein-regularized alignment... variance-guided perturbations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Micro and macro facial expression recognition using advanced local motion patterns
Benjamin Allaert, Ioan Marius Bilasco, and Chaabane Djeraba. Micro and macro facial expression recognition using advanced local motion patterns. IEEE Transactions on Affective Computing, 13 0 (1): 0 147--158, 2022
work page 2022
-
[2]
Wasserstein generative adversarial networks
Martin Arjovsky, Soumith Chintala, and L\' e on Bottou. Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, ICML'17, pp.\ 214–223. JMLR.org, 2017
work page 2017
-
[3]
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? In Proceedings of the International Conference on Machine Learning (ICML), July 2021
work page 2021
-
[4]
Distilling knowledge from frequencies for efficient video recognition
Dian Chen, Yunhe He, Zhiqiang Xu, Chunjing Zhang, and Changhu Wang. Distilling knowledge from frequencies for efficient video recognition. In Proceedings of the 29th ACM International Conference on Multimedia (ACM MM), pp.\ 4823--4832, 2021 a
work page 2021
-
[5]
Smg: A micro-gesture dataset towards spontaneous body gestures for emotional stress state analysis
Haoyu Chen, Henglin Shi, Xin Liu, Xiaobai Li, and Guoying Zhao. Smg: A micro-gesture dataset towards spontaneous body gestures for emotional stress state analysis. International Journal of Computer Vision, 131 0 (6): 0 1346--1366, 2023
work page 2023
-
[6]
Spatio-temporal-frequency feature fusion for multimodal learning
Jie Chen, Wei Zhang, and Qiang Li. Spatio-temporal-frequency feature fusion for multimodal learning. Sensors, 24 0 (18): 0 6090, 2024
work page 2024
-
[7]
Channel-wise topology refinement graph convolution for skeleton-based action recognition
Yuxin Chen, Ziqi Zhang, Chunfeng Yuan, Bing Li, Ying Deng, and Weiming Hu. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp.\ 13339--13348, 2021 b
work page 2021
-
[8]
Feng-Qi Cui, Anyang Tong, Jinyang Huang, Jie Zhang, Dan Guo, Zhi Liu, and Meng Wang. Learning from heterogeneity: Generalizing dynamic facial expression recognition via distributionally robust optimization. In Proceedings of the 33nd ACM International Conference on Multimedia, MM '25, New York, NY, USA, 2025. Association for Computing Machinery
work page 2025
-
[9]
Skateformer: skeletal-temporal transformer for human action recognition
Jeonghyeok Do and Munchurl Kim. Skateformer: skeletal-temporal transformer for human action recognition. In European Conference on Computer Vision, pp.\ 401--420. Springer, 2025
work page 2025
-
[10]
Pyskl: Towards good practices for skeleton action recognition
Haodong Duan, Jiaqi Wang, Kai Chen, and Dahua Lin. Pyskl: Towards good practices for skeleton action recognition. In Proceedings of the 30th ACM International Conference on Multimedia, MM '22, pp.\ 7351–7354, New York, NY, USA, 2022. Association for Computing Machinery
work page 2022
-
[11]
X3d: Expanding architectures for efficient video recognition
Christoph Feichtenhofer. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
work page 2020
-
[12]
Slowfast networks for video recognition
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp.\ 6202--6211, 2019
work page 2019
-
[13]
Also: Adaptive loss scaling for distributionally robust optimization
Pavel Feoktistov, Xiaojie Wang, and Jie Zhang. Also: Adaptive loss scaling for distributionally robust optimization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. to appear
work page 2025
-
[14]
Hardness-weighted sampling for robust medical image segmentation
Lucas Fidon, Wenqi Li, Cheng Zhang, and Ben Glocker. Hardness-weighted sampling for robust medical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), pp.\ 532--541, 2020
work page 2020
-
[15]
Motion matters: Motion-guided modulation network for skeleton-based micro-action recognition
Jihao Gu, Kun Li, Fei Wang, Yanyan Wei, Zhiliang Wu, Hehe Fan, and Meng Wang. Motion matters: Motion-guided modulation network for skeleton-based micro-action recognition. In Proceedings of the 33rd ACM International Conference on Multimedia (ACM MM), 2025 a
work page 2025
-
[16]
Motion matters: Motion-guided modulation network for skeleton-based micro-action recognition, 2025 b
Jihao Gu, Kun Li, Fei Wang, Yanyan Wei, Zhiliang Wu, Hehe Fan, and Meng Wang. Motion matters: Motion-guided modulation network for skeleton-based micro-action recognition, 2025 b
work page 2025
-
[17]
Benchmarking micro-action recognition: Dataset, methods, and applications
Dan Guo, Kun Li, Bin Hu, Yan Zhang, and Meng Wang. Benchmarking micro-action recognition: Dataset, methods, and applications. IEEE Transactions on Circuits and Systems for Video Technology, 2024
work page 2024
-
[18]
The kinetics human action video dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, and Andrew Zisserman. The kinetics human action video dataset. In Proceedings of the British Machine Vision Conference (BMVC), 2017
work page 2017
-
[19]
Hierarchically decomposed graph convolutional networks for skeleton-based action recognition
Junghoon Lee, Minhyeok Lee, Dogyoon Lee, and Sangyoon Lee. Hierarchically decomposed graph convolutional networks for skeleton-based action recognition. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp.\ 10410--10419, 2022
work page 2023
-
[20]
Prototypical calibrating ambiguous samples for micro-action recognition
Kun Li, Dan Guo, Guoliang Chen, Chunxiao Fan, Jingyuan Xu, Zhiliang Wu, Hehe Fan, and Meng Wang. Prototypical calibrating ambiguous samples for micro-action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp.\ 4815--4823, 2025
work page 2025
-
[21]
Uniformer: Unifying convolution and self-attention for visual recognition
Kunchang Li, Yali Wang, Junhao Zhang, Peng Gao, Guanglu Song, Yu Liu, Hongsheng Li, and Yu Qiao. Uniformer: Unifying convolution and self-attention for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell., 45 0 (10): 0 12581–12600, October 2023. ISSN 0162-8828
work page 2023
-
[22]
Mengke Li, Ye Liu, Yang Lu, Yiqun Zhang, Yiu ming Cheung, and Hui Huang. Improving visual prompt tuning by gaussian neighborhood minimization for long-tailed visual recognition. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[23]
Distributionally robust optimization: A review on theory and applications, 2022 a
Fengming Lin, Xiaolei Fang, and Zheming Gao. Distributionally robust optimization: A review on theory and applications, 2022 a . ISSN 2155-3289
work page 2022
-
[24]
Tsm: Temporal shift module for efficient video understanding
Ji Lin, Chuang Gan, and Song Han. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp.\ 7083--7093, 2019
work page 2019
-
[25]
On the convergence of distributionally robust optimization methods
Tianyi Lin, Zaiwei Hu, Jose Blanchet, Peter Glynn, and Yinyu Yang. On the convergence of distributionally robust optimization methods. In Advances in Neural Information Processing Systems (NeurIPS), 2022 b
work page 2022
-
[26]
Chenyu Liu, XINLIANG ZHOU, Zhengri Zhu, Liming Zhai, Ziyu Jia, and Yang Liu. VBH - GNN : Variational bayesian heterogeneous graph neural networks for cross-subject emotion recognition. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[27]
imigue: An identity-free video dataset for micro-gesture understanding and emotion analysis
Xin Liu, Henglin Shi, Haoyu Chen, Zitong Yu, Xiaobai Li, and Guoying Zhao. imigue: An identity-free video dataset for micro-gesture understanding and emotion analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 10631--10642, June 2021 a
work page 2021
-
[28]
Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. Video swin transformer. arXiv preprint arXiv:2106.13230, 2021 b
-
[29]
End-to-end learning of compressed video action recognition with decoding-free temporal modeling
Zhaoyang Liu, Tianyu Xu, Chenyang Wu, Xiangyu Yang, Yu Qiao, and Limin Wang. End-to-end learning of compressed video action recognition with decoding-free temporal modeling. In Proceedings of the British Machine Vision Conference (BMVC), 2021 c
work page 2021
-
[30]
Disentangling and unifying graph convolutions for skeleton-based action recognition
Ziyu Liu, Hongwen Zhang, Zhenghao Chen, Zhiyong Wang, and Wanli Ouyang. Disentangling and unifying graph convolutions for skeleton-based action recognition. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 140--149, 2020
work page 2020
-
[31]
Understanding emotional body expressions via large language models
Haifeng Lu, Jiuyi Chen, Feng Liang, Mingkui Tan, Runhao Zeng, and Xiping Hu. Understanding emotional body expressions via large language models. Proceedings of the AAAI Conference on Artificial Intelligence, 39 0 (2): 0 1447--1455, Apr. 2025
work page 2025
-
[32]
Maxime Oquab, Timoth \'e e Darcet, Th \'e o Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Pat...
work page 2024
-
[33]
Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. In International Conference on Learning Representations (ICLR), 2020
work page 2020
-
[34]
Hao Shao, Shengju Qian, and Yu Liu. Temporal interlacing network. AAAI, 2020
work page 2020
-
[35]
Skeleton-based action recognition with multi-stream adaptive graph convolutional networks
Lei Shi, Yifan Zhang, Jian Cheng, and Hanqing Lu. Skeleton-based action recognition with multi-stream adaptive graph convolutional networks. IEEE Transactions on Image Processing, 29: 0 9532--9545, 2020
work page 2020
-
[36]
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of Machine Learning Research, 2008
work page 2008
-
[37]
Tdn: Temporal difference networks for efficient action recognition
Limin Wang, Zhanhui Tong, Bin Ji, and Gangshan Wu. Tdn: Temporal difference networks for efficient action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 1895--1904, 2021
work page 1904
-
[38]
Facialpulse: An efficient rnn-based depression detection via temporal facial landmarks
Ruiqi Wang, Jinyang Huang, Jie Zhang, Xin Liu, Xiang Zhang, Zhi Liu, Peng Zhao, Sigui Chen, and Xiao Sun. Facialpulse: An efficient rnn-based depression detection via temporal facial landmarks. In Proceedings of the 32nd ACM International Conference on Multimedia, MM '24, pp.\ 311–320, New York, NY, USA, 2024. Association for Computing Machinery. ISBN 979...
work page 2024
-
[39]
Xinghan Wang, Xin Xu, and Yadong Mu. Neural koopman pooling: Control-inspired temporal dynamics encoding for skeleton-based action recognition. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 10597--10607, 2023
work page 2023
-
[40]
Understanding contrastive learning via distributionally robust optimization
Junkang Wu, Jiawei Chen, Jiancan Wu, Wentao Shi, Xiang Wang, and Xiangnan He. Understanding contrastive learning via distributionally robust optimization. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS '23, Red Hook, NY, USA, 2023
work page 2023
-
[41]
Learning discriminative representations for skeleton based action recognition
Huanyu Zhou, Qingjie Liu, and Yunhong Wang. Learning discriminative representations for skeleton based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 10608--10617, June 2023
work page 2023
-
[42]
Transformers without normalization
Jiachen Zhu, Xinlei Chen, Kaiming He, Yann LeCun, and Zhuang Liu. Transformers without normalization. In 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[43]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[44]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[45]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[46]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.