InfiniPipe: Elastic Pipeline Parallelism for Efficient Variable-Length Long-Context LLM Training
Pith reviewed 2026-05-18 13:59 UTC · model grok-4.3
The pith
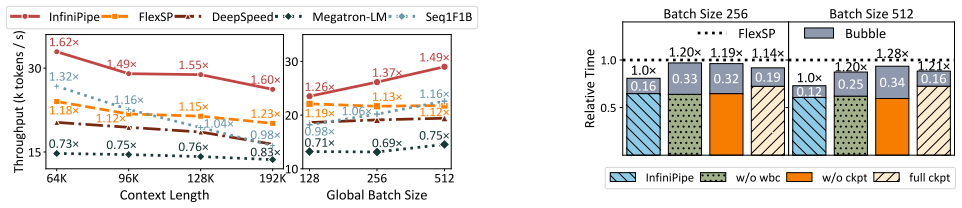
InfiniPipe achieves up to 1.69x speedup in long-context LLM training by using elastic pipeline parallelism that adapts partitioning to variable sequence lengths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that orchestrating token-level pipeline parallelism with batch-level pipeline parallelism in an elastic manner, combined with stage-aware chunk-level adaptive checkpointing, allows the system to adapt to resource and workload heterogeneity. This results in reduced communication overhead and better memory efficiency compared to monolithic static granularity methods. Experiments confirm a 1.69x speedup over state-of-the-art systems for variable-length long-context LLM training.
What carries the argument
Elastic Pipeline Parallelism (EPP) that dynamically orchestrates between token-level and batch-level pipeline parallelism to handle heterogeneity in resources and sequence length distributions.
If this is right
- LLM training with long and variable contexts becomes faster by a factor of 1.69 compared to prior pipeline parallelism systems.
- Hardware utilization improves by avoiding underuse in token slicing and excessive memory in batch packing.
- Gradient checkpointing can be applied adaptively at the chunk level without conflicting with the pipeline schedule.
- Training systems gain the ability to handle skewed real-world data distributions more effectively.
Where Pith is reading between the lines
- Similar elastic adaptation techniques could benefit other parallel computing domains with irregular workloads, such as graph processing or scientific simulations.
- This could reduce the need for specialized hardware in scaling up context lengths, making advanced LLM features more accessible.
- Integrating EPP with other forms of parallelism might further optimize large-scale training setups.
Load-bearing premise
The dynamic orchestration between token-level and batch-level pipeline parallelism incurs low enough overhead to deliver net performance improvements despite varying resources and sequence length distributions.
What would settle it
If benchmarks on heterogeneous clusters with real skewed sequence data show that EPP's scheduling and switching costs lead to overall slowdowns rather than the claimed speedup.
Figures








read the original abstract
Long context training is crucial for LLM's context extension. Existing schemes, such as sequence parallelism, incur substantial communication overhead. Pipeline parallelism (PP) reduces this cost, but its effectiveness hinges on partitioning granularity. Batch-level PP employing sequence packing exhibits high memory consumption in long-context scenarios, whereas token-level PP splitting sequences into slices alleviates memory overhead but may incur hardware under-utilization. Moreover, the skewed distribution of sequence length in real-world datasets renders monolithic and static granularity PP's sub-optimal performance. In this paper, we propose 1) \textit{Elastic Pipeline Parallelism} (EPP) that orchestrates token-level PP and batch-level PP to adapt to resource and workload heterogeneity, and 2) \textit{Stage-Aware Chunk-Level Adaptive Checkpointing} that efficiently integrates gradient checkpointing with EPP. Comprehensive experiments demonstrate that InfiniPipe achieves a 1.69x speedup over state-of-the-art systems. Our code is open-sourced at https://github.com/wsjdsg/InfiniPipe-code.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces InfiniPipe for long-context LLM training. It proposes Elastic Pipeline Parallelism (EPP) to dynamically orchestrate token-level and batch-level pipeline parallelism for adapting to resource heterogeneity and skewed sequence-length distributions, plus Stage-Aware Chunk-Level Adaptive Checkpointing to integrate gradient checkpointing. Experiments claim a 1.69x speedup over state-of-the-art systems, with open-sourced code at the provided GitHub link.
Significance. If validated, the work addresses a practical bottleneck in scaling pipeline parallelism for variable-length sequences, which grows in importance with longer LLM contexts. The open-sourced code and focus on real-world skew are strengths that support reproducibility and potential adoption in distributed training frameworks.
major comments (2)
- [§5] §5 (Evaluation): the reported 1.69x speedup lacks accompanying measurements of EPP switching frequency, decision latency, reconfiguration overhead, or time fraction spent in orchestration versus compute. These data are load-bearing for the central claim that dynamic adaptation to skewed workloads delivers net gains rather than arising from static configurations or favorable test conditions.
- [§3] §3 (EPP Design): the exact decision logic, thresholds for switching between token-level and batch-level PP, and synchronization/flushing costs during stage reconfiguration are not quantified or ablated. This leaves the low-overhead assumption unverified despite being invoked to motivate the approach over monolithic static granularity.
minor comments (2)
- [Abstract] Abstract: specify the model sizes, hardware configurations, and sequence-length distributions used in the 'comprehensive experiments' to allow readers to assess generalizability.
- [§5] Figures in §5: ensure error bars or variance across runs are shown for all speedup and utilization plots.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of evaluation and design that we will address to strengthen the presentation of InfiniPipe. We respond to each major comment below.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation): the reported 1.69x speedup lacks accompanying measurements of EPP switching frequency, decision latency, reconfiguration overhead, or time fraction spent in orchestration versus compute. These data are load-bearing for the central claim that dynamic adaptation to skewed workloads delivers net gains rather than arising from static configurations or favorable test conditions.
Authors: We agree that these additional measurements would provide stronger evidence for the benefits of dynamic adaptation. The current evaluation emphasizes end-to-end performance on real-world skewed datasets, but we will revise §5 to include a new subsection with these metrics. We will report switching frequency, decision latency, reconfiguration overhead, and orchestration time fraction from our existing experimental runs, along with a comparison to static pipeline configurations to isolate the gains from elasticity. revision: yes
-
Referee: [§3] §3 (EPP Design): the exact decision logic, thresholds for switching between token-level and batch-level PP, and synchronization/flushing costs during stage reconfiguration are not quantified or ablated. This leaves the low-overhead assumption unverified despite being invoked to motivate the approach over monolithic static granularity.
Authors: We acknowledge that more precise details on the decision logic and costs would improve the rigor of §3. We will expand this section with pseudocode for the orchestration policy, the specific thresholds based on sequence length distribution and memory profiling, and an ablation study quantifying synchronization and flushing costs. This will directly verify the low-overhead nature of stage reconfigurations. revision: yes
Circularity Check
No circularity: empirical systems proposal with external validation
full rationale
This is an empirical systems paper proposing Elastic Pipeline Parallelism (EPP) to orchestrate token-level and batch-level PP for variable-length sequences, plus Stage-Aware Chunk-Level Adaptive Checkpointing. The central claim of 1.69x speedup is supported by measurements on open-sourced code rather than any derivation, equations, or fitted parameters. No load-bearing step reduces by construction to self-definition, renamed known results, or self-citation chains; the motivation from sequence-length skew is addressed through implementation and benchmarking against external baselines, keeping the work self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- EPP switching thresholds
axioms (1)
- domain assumption Real-world datasets exhibit skewed sequence length distributions that render static granularity PP sub-optimal
invented entities (2)
-
Elastic Pipeline Parallelism (EPP)
no independent evidence
-
Stage-Aware Chunk-Level Adaptive Checkpointing
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Elastic Pipeline Parallelism (EPP) that orchestrates token-level PP and batch-level PP to adapt to resource and workload heterogeneity
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Stage-Aware Chunk-Level Adaptive Checkpointing
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Nvidia collective communications library (nccl).https://developer. nvidia.com/nccl, 2021
work page 2021
-
[2]
Pytorch gpipe.https://pytorch.org/docs/stable/pipeline.html, 2021
work page 2021
-
[3]
Introducing meta llama 3: The most capable openly available llm to date.https://ai.meta.com/blog/meta-llama-3/, 2024
work page 2024
-
[4]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Beaumont, O., Eyraud-Dubois, L., and Shilova, A.Efficient combi- nation of rematerialization and offloading for training dnns.Advances in Neural Information Processing Systems 34(2021), 23844–23857
work page 2021
-
[6]
Bolusani, S., Besançon, M., Bestuzheva, K., Chmiela, A., Dionísio, J., Donkiewicz, T., van Doornmalen, J., Eifler, L., Ghannam, M., Gleixner, A., Graczyk, C., Halbig, K., Hedtke, I., Hoen, A., Ho- jny, C., van der Hulst, R., Kamp, D., Koch, T., Kofler, K., Lentz, J., Manns, J., Mexi, G., Mühmer, E., Pfetsch, M. E., Schlösser, F., Ser- rano, F., Shinano, Y...
work page 2024
- [7]
-
[8]
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhari- wal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agar- wal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., Mc- Candlish, S., Rad...
work page 2020
- [9]
-
[10]
Dao, T.Flashattention-2: Faster attention with better parallelism and work partitioning.CoRR abs/2307.08691(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Dao, T., Fu, D. Y., Ermon, S., Rudra, A., and Ré, C.Flashattention: Fast and memory-efficient exact attention with io-awareness. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022(2022), S. Koyejo, S. Mohamed, A. Agarwal...
work page 2022
-
[12]
DeepSeek-AI, Liu, A., Feng, B., W ang, B., W ang, B., Liu, B., Zhao, C., Dengr, C., Ruan, C., Dai, D., Guo, D., Yang, D., Chen, D., Ji, D., Li, E., Lin, F., Luo, F., Hao, G., Chen, G., Li, G., Zhang, H., Xu, H., Y ang, H., Zhang, H., Ding, H., Xin, H., Gao, H., Li, H., Qu, H., Cai, J. L., Liang, J., Guo, J., Ni, J., Li, J., Chen, J., Yuan, J., Qiu, J., So...
work page 2024
-
[13]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Y ang, A., Fan, A., et al.The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Fan, S., Rong, Y., Meng, C., et al.DAPPLE: a pipelined data parallel approach for training large models. InPPoPP(2021), ACM, pp. 431– 445
work page 2021
- [15]
-
[16]
InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles(2024), pp
Ge, H., Fu, F., Li, H., W ang, X., Lin, S., W ang, Y., Nie, X., Zhang, H., Miao, X., and Cui, B.Enabling parallelism hot switching for efficient training of large language models. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles(2024), pp. 178–194
work page 2024
- [17]
-
[18]
Jacobs, S. A., Tanaka, M., Zhang, C., Zhang, M., Song, S. L., Rajb- handari, S., and He, Y.Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models. CoRR abs/2309.14509(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
InProceedings of the Nineteenth European Conference on Computer Systems(2024), pp
Jiang, C., Jia, Z., Zheng, S., Wang, Y., and Wu, C.Dynapipe: Opti- mizing multi-task training through dynamic pipelines. InProceedings of the Nineteenth European Conference on Computer Systems(2024), pp. 542–559
work page 2024
- [21]
-
[22]
Krell, M. M., Kosec, M., Perez, S. P., and Fitzgibbon, A.Efficient sequence packing without cross-contamination: Accelerating large language models without impacting performance.arXiv preprint arXiv:2107.02027(2021)
-
[23]
Li, A., Gong, B., Y ang, B., Shan, B., Liu, C., Zhu, C., Zhang, C., Guo, C., Chen, D., Li, D., et al.Minimax-01: Scaling foundation models with lightning attention.arXiv preprint arXiv:2501.08313(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Li, D., Shao, R., Xie, A., Xing, E. P., Gonzalez, J. E., Stoica, I., Ma, X., and Zhang, H.Lightseq: Sequence level parallelism for distributed training of long context transformers.CoRR abs/2310.03294(2023)
-
[25]
P., Ma, X., Stoica, I., Gonzalez, J
Li, D., Shao, R., Xie, A., Xing, E. P., Ma, X., Stoica, I., Gonzalez, J. E., and Zhang, H.Distflashattn: Distributed memory-efficient at- tention for long-context llms training. InFirst Conference on Language Modeling(2024)
work page 2024
-
[26]
Li, S., and Hoefler, T.Chimera: efficiently training large-scale neural networks with bidirectional pipelines. InProceedings of the Interna- tional Conference for High Performance Computing, Networking, Storage and Analysis(2021), pp. 1–14
work page 2021
-
[27]
Li, S., Zhao, Y., V arma, R., Salpekar, O., Noordhuis, P., Li, T., Paszke, A., Smith, J., V aughan, B., Damania, P., and Chintala, S.Pytorch distributed: Experiences on accelerating data parallel training.Proc. VLDB Endow. 13, 12 (2020), 3005–3018
work page 2020
-
[28]
InInternational Conference on Machine Learning (2021), PMLR, pp
Li, Z., Zhuang, S., Guo, S., Zhuo, D., Zhang, H., Song, D., and Stoica, I.Terapipe: Token-level pipeline parallelism for training large-scale language models. InInternational Conference on Machine Learning (2021), PMLR, pp. 6543–6552
work page 2021
-
[29]
Liu, A., Feng, B., Xue, B., W ang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Liu, H., Zaharia, M., and Abbeel, P.Ring attention with blockwise transformers for near-infinite context.CoRR abs/2310.01889(2023). 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Liu, W., Li, M., Tan, G., and Jia, W.Mario: Near zero-cost activation checkpointing in pipeline parallelism. InProceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming(2025), pp. 197–211
work page 2025
-
[32]
Liu, Z., Cheng, S., Zhou, H., and You, Y.Hanayo: Harnessing wave- like pipeline parallelism for enhanced large model training efficiency. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis(2023), pp. 1–13
work page 2023
-
[33]
InInternational Conference on Machine Learning(2021), PMLR, pp
Narayanan, D., Phanishayee, A., Shi, K., Chen, X., and Zaharia, M.Memory-efficient pipeline-parallel dnn training. InInternational Conference on Machine Learning(2021), PMLR, pp. 7937–7947
work page 2021
-
[34]
Narayanan, D., Shoeybi, M., Casper, J., et al.Efficient large-scale language model training on GPU clusters using megatron-lm. InSC (2021), ACM, pp. 58:1–58:15
work page 2021
-
[35]
InThe Twelfth International Conference on Learning Rep- resentations(2024)
Qi, P., W an, X., Huang, G., and Lin, M.Zero bubble (almost) pipeline parallelism. InThe Twelfth International Conference on Learning Rep- resentations(2024)
work page 2024
-
[36]
Rajbhandari, S., Rasley, J., Ruwase, O., and He, Y.Zero: memory optimizations toward training trillion parameter models. InSC(2020), IEEE/ACM
work page 2020
-
[37]
Horovod: fast and easy distributed deep learning in TensorFlow
Sergeev, A., and Balso, M. D.Horovod: fast and easy distributed deep learning in tensorflow.CoRR abs/1802.05799(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [38]
-
[39]
Sun, Z., Cao, H., W ang, Y., Feng, G., Chen, S., W ang, H., and Chen, W.Adapipe: Optimizing pipeline parallelism with adaptive recompu- tation and partitioning. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3(2024), pp. 86–100
work page 2024
-
[40]
Tillet, P., Kung, H.-T., and Cox, D.Triton: an intermediate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages(2019), pp. 10–19
work page 2019
-
[41]
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Canton-Ferrer, C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V., Goyal, N., Hartshorn, A., Hosseini, S., Hou, R., Inan, H., Kar- das, M., Kerkez, V., ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
W ang, Y., W ang, S., Zhu, S., Fu, F., Liu, X., Xiao, X., Li, H., Li, J., Wu, F., and Cui, B.Flexsp: Accelerating large language model training via flexible sequence parallelism. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(2025), pp. 421–436
work page 2025
- [43]
-
[44]
Y ang, A., Li, A., Y ang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [45]
-
[46]
In2025 USENIX Annual Technical Conference (USENIX ATC 25) (2025), pp
Zhao, H., Tian, Q., Li, H., and Chen, Z.{FlexPipe}: Maximizing train- ing efficiency for transformer-based models with {Variable-Length} inputs. In2025 USENIX Annual Technical Conference (USENIX ATC 25) (2025), pp. 143–159
work page 2025
-
[47]
Zhao, Y., Gu, A., V arma, R., Luo, L., Huang, C., Xu, M., Wright, L., Shojanazeri, H., Ott, M., Shleifer, S., Desmaison, A., Balioglu, C., Damania, P., Nguyen, B., Chauhan, G., Hao, Y., Mathews, A., and Li, S.Pytorch FSDP: experiences on scaling fully sharded data parallel.Proc. VLDB Endow. 16, 12 (2023), 3848–3860. 14 Table 3.End-to-end time and the prop...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.