Discrete Guidance Matching: Exact Guidance for Discrete Flow Matching
Pith reviewed 2026-05-18 14:10 UTC · model grok-4.3
The pith
Exact transition rates derived from discrete flow matching models enable single-forward-pass guidance for any desired distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
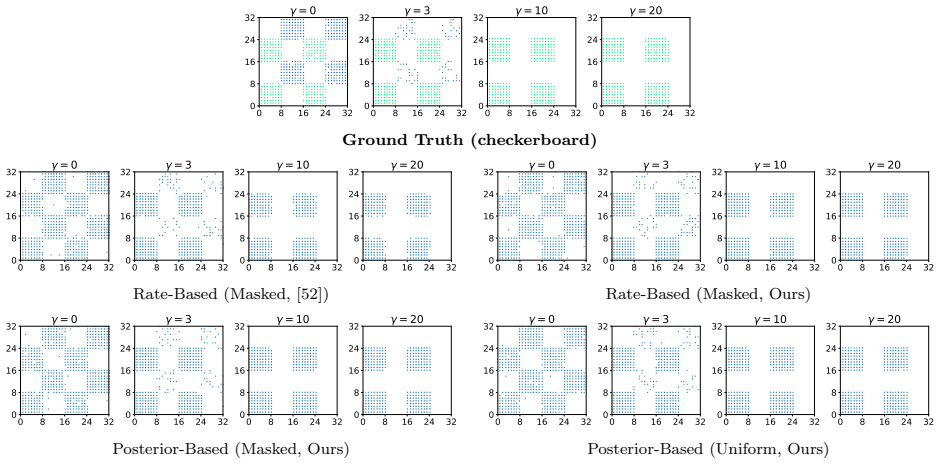
Given a model that has learned the unconditional transition rates of a discrete flow matching process, the exact transition rate for a guided or conditional target distribution is obtained by a direct, closed-form adjustment to those rates using the guidance function evaluated at the current state; this adjustment yields a valid continuous-time Markov chain whose marginal at the terminal time matches the desired distribution and requires only the single model evaluation already performed to read the learned rates.
What carries the argument
The exact guidance-adjusted transition rate obtained by correcting the learned discrete flow matching rates with a term derived from the guidance function.
If this is right
- Each sampling step requires only one forward pass through the model instead of repeated evaluations for an approximation.
- Existing first-order guidance methods emerge as the low-order truncation of the new exact rate formula.
- The same rate formula applies without change to masked diffusion models.
- Sampling quality improves on energy-guided simulations and on preference alignment for text-to-image and multimodal tasks.
Where Pith is reading between the lines
- The exact rate may permit larger effective time steps during sampling while still reaching the target distribution.
- The method could be combined with classifier-free guidance to further cut the number of model calls needed for conditional discrete generation.
- Applying the same derivation to other discrete diffusion or autoregressive frameworks would test whether the single-pass efficiency gain generalizes beyond flow matching.
Load-bearing premise
The learned model must have correctly captured the transition dynamics that the true data distribution would follow under the flow matching process.
What would settle it
Run many sampling trajectories with both the exact guidance and the first-order approximation on a small discrete space where the true posterior is known exactly, then compare the empirical distribution of the generated samples to the target posterior using total variation distance.
Figures













read the original abstract
Guidance provides a simple and effective framework for posterior sampling by steering the generation process towards the desired distribution. When modeling discrete data, existing approaches mostly focus on guidance with the first-order approximation to improve the sampling efficiency. However, such an approximation is inappropriate in discrete state spaces since the approximation error could be large. A novel guidance framework for discrete data is proposed to address this problem: we derive the exact transition rate for the desired distribution given a learned discrete flow matching model, leading to guidance that only requires a single forward pass in each sampling step, significantly improving efficiency. This unified novel framework is general enough, encompassing existing guidance methods as special cases, and it can also be seamlessly applied to the masked diffusion model. We demonstrate the effectiveness of our proposed guidance on energy-guided simulations and preference alignment on text-to-image generation and multimodal understanding tasks. The code is available at https://github.com/WanZhengyan/Discrete-Guidance-Matching.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Discrete Guidance Matching, deriving an exact transition rate for the target distribution conditioned on a learned discrete flow matching model. This yields a guidance procedure requiring only a single forward pass per sampling step, claimed to be more accurate than first-order approximations in discrete spaces. The framework is presented as general, subsuming prior guidance methods as special cases, and directly applicable to masked diffusion models. Empirical support is provided via energy-guided simulations and preference alignment experiments on text-to-image generation and multimodal tasks.
Significance. If the derivation is correct, the result supplies a principled, efficient exact-guidance mechanism for discrete generative models that avoids large approximation errors inherent to continuous relaxations. It unifies existing approaches and extends naturally to masked diffusion, with potential to improve sampling quality and speed in discrete domains such as text and structured data. The open-source code is a positive factor for reproducibility.
major comments (2)
- [§3.2, Eq. (8)] §3.2, Eq. (8): the exact rate matrix for the guided process is obtained by solving the Kolmogorov forward equation under the flow-matching objective; however, the manuscript does not supply an explicit error bound or empirical check showing that the learned rate matrix produces marginals that match the guided target exactly when the model is only an approximation to the true data distribution.
- [§5.1, Table 1] §5.1, Table 1: the reported efficiency gains (single forward pass) are measured against first-order baselines, but the comparison does not control for total FLOPs when the exact-rate computation itself may require additional matrix operations; this weakens the claim that the method is strictly more efficient under fixed compute.
minor comments (3)
- [§2] Notation for the unconditional rate matrix Q and the guided rate Q^g should be introduced earlier and used consistently to avoid confusion between the learned model and the guided process.
- [Figure 4] Figure 4 caption lacks standard-deviation shading or error bars on the preference-alignment curves, making it difficult to judge statistical reliability of the reported improvements.
- [§4] A short remark on how the method behaves when the discrete state space cardinality is very large (e.g., token vocabulary size) would help readers assess practical scalability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. The comments highlight important aspects of the derivation and empirical evaluation. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2, Eq. (8)] §3.2, Eq. (8): the exact rate matrix for the guided process is obtained by solving the Kolmogorov forward equation under the flow-matching objective; however, the manuscript does not supply an explicit error bound or empirical check showing that the learned rate matrix produces marginals that match the guided target exactly when the model is only an approximation to the true data distribution.
Authors: We agree that the exactness of the guided transition rates holds with respect to the learned discrete flow matching model. When this model only approximates the true data distribution, the resulting marginals will match the guided target only up to the model's approximation error; this is a general property of any learned generative model rather than a limitation specific to our derivation. Explicit error bounds would necessarily depend on the (unknown) approximation quality of the base model and are typically studied separately in the flow-matching literature. We will add a clarifying paragraph in §3.2 stating this conditional exactness and include an additional empirical verification (comparing empirical marginals to the target under the learned model) in the experiments section of the revision. revision: partial
-
Referee: [§5.1, Table 1] §5.1, Table 1: the reported efficiency gains (single forward pass) are measured against first-order baselines, but the comparison does not control for total FLOPs when the exact-rate computation itself may require additional matrix operations; this weakens the claim that the method is strictly more efficient under fixed compute.
Authors: The closed-form expression for the exact guidance rate in our framework is constructed so that it requires only a single forward pass of the base model; the subsequent algebraic operations to obtain the rate matrix are linear in the (small) discrete state dimension and do not involve further model evaluations or iterative solvers. In the regimes considered (token vocabularies and masked image patches), these operations contribute negligibly to total FLOPs relative to the neural network forward pass. Nevertheless, to address the concern directly we will augment Table 1 and §5.1 with an explicit FLOPs breakdown that accounts for both the model call and the rate-matrix construction, allowing a controlled comparison under fixed compute. revision: yes
Circularity Check
Derivation is self-contained; no circularity detected
full rationale
The central claim is a mathematical derivation of an exact transition rate from a learned discrete flow matching model using the flow matching objective and Kolmogorov forward equation. This produces guidance requiring only a single forward pass and is presented as generalizing prior methods as special cases. No steps reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations. The result is independent of the target distribution's specifics beyond the given model and does not rename known empirical patterns or smuggle ansatzes. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The pre-trained discrete flow matching model provides an accurate approximation to the data-generating process.
- standard math Discrete state transitions can be modeled via continuous-time Markov chains whose rate matrix admits an exact closed-form expression under the guidance distribution.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We derive the exact transition rate for the desired distribution given a learned discrete flow matching model... posterior-based guidance... Bregman divergence
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Kolmogorov forward equation... transition rate u_q_t ... conditional expectation of the density ratio
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
dFlowGRPO: Rate-Aware Policy Optimization for Discrete Flow Models
dFlowGRPO is a new rate-aware RL method for discrete flow models that outperforms prior GRPO approaches on image generation and matches continuous flow models while supporting broad probability paths.
Reference graph
Works this paper leans on
-
[1]
Building normalizing flows with stochastic in- terpolants
Michael S Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic in- terpolants. InInternational Conference on Learning Representations, 2023
work page 2023
-
[2]
Block diffusion: Interpolating between autoregressive and diffusion language models
Marianne Arriola, Aaron Gokaslan, Justin T Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models. InInternational Conference on Learning Rep- resentations, 2025
work page 2025
-
[3]
Structured denoising diffusion models in discrete state-spaces
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces. InAdvances in Neural Infor- mation Processing Systems, volume 34, pages 17981–17993, 2021
work page 2021
-
[4]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.ArXiv, abs/2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Banerjee, Xin Guo, and Hui Wang
A. Banerjee, Xin Guo, and Hui Wang. On the optimality of conditional expectation as a Bregman predictor.IEEE Transactions on Information Theory, 51(7):2664–2669, 2005
work page 2005
-
[6]
Joe Benton, Yuyang Shi, Valentin De Bortoli, George Deligiannidis, and Arnaud Doucet. From denoising diffusions to denoising Markov models.Journal of the Royal Statistical Society Series B: Statistical Methodology, 86(2):286–301, 2024
work page 2024
-
[7]
Improving image generation with better captions
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, Wesam Manassra, Prafulla Dhariwal, Casey Chu, Yunxin Jiao, and Aditya Ramesh. Improving image generation with better captions
-
[8]
A continuous time framework for discrete denoising models
Andrew Campbell, Joe Benton, Valentin De Bortoli, Thomas Rainforth, George Deligiannidis, and Arnaud Doucet. A continuous time framework for discrete denoising models. InAdvances in Neural Information Processing Systems, volume 35, pages 28266–28279, 2022. 11
work page 2022
-
[9]
Andrew Campbell, Jason Yim, Regina Barzilay, Tom Rainforth, and Tommi Jaakkola. Gen- erative flows on discrete state-spaces: Enabling multimodal flows with applications to protein co-design. InInternational Conference on Machine Learning, 2024
work page 2024
-
[10]
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T. Freeman. MaskGIT: Masked generative image transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11315–11325, 2022
work page 2022
-
[11]
Pixart-α: Fast training of diffusion trans- former for photorealistic text-to-image synthesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-α: Fast training of diffusion trans- former for photorealistic text-to-image synthesis. InInternational Conference on Learning Representations, 2024
work page 2024
-
[12]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-Pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
MobileVLM : A Fast, Strong and Open Vision Language Assistant for Mobile Devices
Xiangxiang Chu, Limeng Qiao, Xinyang Lin, Shuang Xu, Yang Yang, Yiming Hu, Fei Wei, Xinyu Zhang, Bo Zhang, Xiaolin Wei, and Chunhua Shen. MobileVLM: A fast, strong and open vision language assistant for mobile devices.arXiv preprint arXiv:2312.16886, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
Xiangxiang Chu, Limeng Qiao, Xinyu Zhang, Shuang Xu, Fei Wei, Yang Yang, Xiaofei Sun, Yiming Hu, Xinyang Lin, Bo Zhang, and Chunhua Shen. Mobilevlm v2: Faster and stronger baseline for vision language model.ArXiv, abs/2402.03766, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Albert Li, Pascale Fung, and Steven C. H. Hoi. Instructblip: Towards general- purpose vision-language models with instruction tuning.ArXiv, abs/2305.06500, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image synthesis. In Advances in Neural Information Processing Systems, volume 34, pages 8780–8794, 2021
work page 2021
-
[17]
Haodong Duan, Junming Yang, Yu Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiao wen Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, Dahua Lin, and Kai Chen. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models.Proceedings of the 32nd ACM International Conference on Multimedia, 2024
work page 2024
-
[18]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M¨ uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InInternational Conference on Machine Learning, 2024
work page 2024
-
[19]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Machel Reid et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.ArXiv, abs/2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
On the guidance of flow matching
Ruiqi Feng, Chenglei Yu, Wenhao Deng, Peiyan Hu, and Tailin Wu. On the guidance of flow matching. InInternational Conference on Machine Learning, 2025
work page 2025
-
[21]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and Rongrong Ji. MME: A compre- hensive evaluation benchmark for multimodal large language models.ArXiv, abs/2306.13394, 2023. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Itai Gat, Tal Remez, Neta Shaul, Felix Kreuk, Ricky TQ Chen, Gabriel Synnaeve, Yossi Adi, and Yaron Lipman. Discrete flow matching. InAdvances in Neural Information Processing Systems, volume 37, pages 133345–133385, 2024
work page 2024
-
[23]
SEED-X: Multimodal Models with Unified Multi-granularity Comprehension and Generation
Yuying Ge, Sijie Zhao, Jinguo Zhu, Yixiao Ge, Kun Yi, Lin Song, Chen Li, Xiaohan Ding, and Ying Shan. SEED-X: Multimodal models with unified multi-granularity comprehension and generation.arXiv preprint arXiv:2404.14396, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Dhruba Ghosh, Hanna Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused frame- work for evaluating text-to-image alignment.ArXiv, abs/2310.11513, 2023
- [25]
-
[26]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020
work page 2020
-
[27]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021
work page 2021
-
[28]
Generator matching: Generative modeling with arbitrary markov processes
Peter Holderrieth, Marton Havasi, Jason Yim, Neta Shaul, Itai Gat, Tommi Jaakkola, Brian Karrer, Ricky TQ Chen, and Yaron Lipman. Generator matching: Generative modeling with arbitrary markov processes. InInternational Conference on Learning Representations, 2025
work page 2025
-
[29]
Gritsenko, Jasmijn Bastings, Ben Poole, Rianne van den Berg, and Tim Salimans
Emiel Hoogeboom, Alexey A. Gritsenko, Jasmijn Bastings, Ben Poole, Rianne van den Berg, and Tim Salimans. Autoregressive diffusion models. InInternational Conference on Learning Representations, 2022
work page 2022
-
[30]
Argmax flows and multinomial diffusion: Learning categorical distributions
Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forr´ e, and Max Welling. Argmax flows and multinomial diffusion: Learning categorical distributions. InAdvances in Neural Information Processing Systems, volume 34, pages 12454–12465, 2021
work page 2021
-
[31]
Drew A. Hudson and Christopher D. Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering.2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6693–6702, 2019
work page 2019
-
[32]
Unified language-vision pretraining in LLM with dynamic discrete visual tokenization
Yang Jin, Kun Xu, Kun Xu, Liwei Chen, Chao Liao, Jianchao Tan, Quzhe Huang, Bin Chen, Chenyi Lei, An Liu, Chengru Song, Xiaoqiang Lei, Di Zhang, Wenwu Ou, Kun Gai, and Yadong Mu. Unified language-vision pretraining in LLM with dynamic discrete visual tokenization. ArXiv, abs/2309.04669, 2023
-
[33]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Systems, volume 35, pages 26565–26577, 2022
work page 2022
-
[34]
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
work page 2023
-
[35]
Rush, Douwe Kiela, Matthieu Cord, Victor Sanh, and et al
Hugo Lauren¸ con, Daniel van Strien, Stas Bekman, Leo Tronchon, Lucile Saulnier, Thomas Wang, Siddharth Karamcheti, Amanpreet Singh, Giada Pistilli, Yacine Jernite, Anton 13 Lozhkov, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh, and et al. Introduc- ing idefics: An open reproduction of state-of-the-art visual language model, 2023. Hugging Fa...
work page 2023
-
[36]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed-bench: Benchmarking multimodal LLMs with generative comprehension.ArXiv, abs/2307.16125, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Xiner Li, Yulai Zhao, Chenyu Wang, Gabriele Scalia, Gokcen Eraslan, Surag Nair, Tom- maso Biancalani, Shuiwang Ji, Aviv Regev, Sergey Levine, et al. Derivative-free guidance in continuous and discrete diffusion models with soft value-based decoding.arXiv preprint arXiv:2408.08252, 2024
-
[38]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji rong Wen. Evaluating object hallucination in large vision-language models. InConference on Empirical Methods in Natural Language Processing, 2023
work page 2023
-
[39]
Dual diffusion for unified image generation and understanding
Zijie Li, Henry Li, Yichun Shi, Amir Barati Farimani, Yuval Kluger, Linjie Yang, and Peng Wang. Dual diffusion for unified image generation and understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[40]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023
work page 2023
-
[41]
World model on million-length video and language with blockwise RingAttention
Hao Liu, Wilson Yan, Matei Zaharia, and Pieter Abbeel. World model on million-length video and language with blockwise RingAttention. InInternational Conference on Learning Representations, 2025
work page 2025
-
[42]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26286–26296, 2023
work page 2024
-
[43]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In Advances in Neural Information Processing Systems, volume 36, pages 34892–34916, 2023
work page 2023
-
[44]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-GRPO: Training flow matching models via online rl. ArXiv, abs/2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[46]
MMBench: Is Your Multi-modal Model an All-around Player?
Yuanzhan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. Mmbench: Is your multi-modal model an all-around player?ArXiv, abs/2307.06281, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Discrete diffusion modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. InInternational Conference on Machine Learning, 2024
work page 2024
-
[48]
Cheng Lu, Huayu Chen, Jianfei Chen, Hang Su, Chongxuan Li, and Jun Zhu. Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning. InInternational Conference on Machine Learning, pages 22825–22855. PMLR, 2023. 14
work page 2023
-
[49]
Concrete score matching: Generalized score matching for discrete data
Chenlin Meng, Kristy Choi, Jiaming Song, and Stefano Ermon. Concrete score matching: Generalized score matching for discrete data. InAdvances in Neural Information Processing Systems, volume 35, pages 34532–34545, 2022
work page 2022
-
[50]
Scaling up masked diffusion models on text
Shen Nie, Fengqi Zhu, Chao Du, Tianyu Pang, Qian Liu, Guangtao Zeng, Min Lin, and Chongxuan Li. Scaling up masked diffusion models on text. InInternational Conference on Learning Representations, 2025
work page 2025
-
[51]
Large language diffusion models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models. InInternational Conference on Learning Representations, 2025
work page 2025
-
[52]
Unlocking guid- ance for discrete state-space diffusion and flow models
Hunter Nisonoff, Junhao Xiong, Stephan Allenspach, and Jennifer Listgarten. Unlocking guid- ance for discrete state-space diffusion and flow models. InInternational Conference on Learning Representations, 2025
work page 2025
-
[53]
Cambridge University Press, 1998
James R Norris.Markov chains, volume 2. Cambridge University Press, 1998
work page 1998
-
[54]
Your absorbing discrete diffusion secretly models the conditional distributions of clean data
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional distributions of clean data. InInternational Conference on Learning Representations, 2025
work page 2025
-
[55]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems, volume 35, pages 27730–27744, 2022
work page 2022
-
[56]
Transfer learning for diffusion models
Yidong Ouyang, Liyan Xie, Hongyuan Zha, and Guang Cheng. Transfer learning for diffusion models. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[57]
SDXL: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M¨ uller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. InInternational Conference on Learning Representations, 2024
work page 2024
-
[58]
DeFoG: Discrete flow matching for graph generation
Yiming Qin, Manuel Madeira, Dorina Thanou, and Pascal Frossard. DeFoG: Discrete flow matching for graph generation. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[59]
Du, Zehuan Yuan, and Xinglong Wu
Liao Qu, Huichao Zhang, Yiheng Liu, Xu Wang, Yi Jiang, Yiming Gao, Hu Ye, Daniel K. Du, Zehuan Yuan, and Xinglong Wu. Tokenflow: Unified image tokenizer for multimodal understanding and generation.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2545–2555, 2024
work page 2025
-
[60]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, volume 36, pages 53728–53741, 2023
work page 2023
-
[61]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with CLIP latents.arXiv preprint arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[62]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨ orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022. 15
work page 2022
-
[63]
Simple and effective masked diffusion language models
Subham Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexander Rush, and Volodymyr Kuleshov. Simple and effective masked diffusion language models. InAdvances in Neural Information Processing Systems, volume 37, pages 130136– 130184, 2024
work page 2024
-
[64]
Yair Schiff, Subham Sekhar Sahoo, Hao Phung, Guanghan Wang, Sam Boshar, Hugo Dalla- Torre, Bernardo P. de Almeida, Alexander M. Rush, Thomas Pierrot, and Volodymyr Kuleshov. Simple guidance mechanisms for discrete diffusion models. InInternational Con- ference on Learning Representations, 2025
work page 2025
-
[65]
Neta Shaul, Itai Gat, Marton Havasi, Daniel Severo, Anuroop Sriram, Peter Holderrieth, Brian Karrer, Yaron Lipman, and Ricky T. Q. Chen. Flow matching with general discrete paths: a kinetic-optimal perspective. InInternational Conference on Learning Representations, 2025
work page 2025
-
[66]
Simplified and generalized masked diffusion for discrete data
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data. InAdvances in Neural Information Processing Systems, volume 37, pages 103131–103167, 2024
work page 2024
-
[67]
Training and inference on any-order autoregres- sive models the right way
Andy Shih, Dorsa Sadigh, and Stefano Ermon. Training and inference on any-order autoregres- sive models the right way. InAdvances in Neural Information Processing Systems, volume 35, pages 2762–2775, 2022
work page 2022
-
[68]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational Conference on Machine Learning, pages 2256–2265. PMLR, 2015
work page 2015
-
[69]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021
work page 2021
-
[70]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021
work page 2021
-
[71]
Score-based continuous- time discrete diffusion models
Haoran Sun, Lijun Yu, Bo Dai, Dale Schuurmans, and Hanjun Dai. Score-based continuous- time discrete diffusion models. InInternational Conference on Learning Representations, 2023
work page 2023
-
[72]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
Unified multimodal discrete diffusion.arXiv preprint arXiv:2503.20853, 2025
Alexander Swerdlow, Mihir Prabhudesai, Siddharth Gandhi, Deepak Pathak, and Katerina Fragkiadaki. Unified multimodal discrete diffusion.arXiv preprint arXiv:2503.20853, 2025
-
[74]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team, Mingda Chen, and Jacob Kahn. Chameleon: Mixed-modal early-fusion foundation models.ArXiv, abs/2405.09818, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[75]
MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
Shengbang Tong, David Fan, Jiachen Zhu, Yunyang Xiong, Xinlei Chen, Koustuv Sinha, Michael Rabbat, Yann LeCun, Saining Xie, and Zhuang Liu. Metamorph: Multimodal under- standing and generation via instruction tuning.ArXiv, abs/2412.14164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[76]
DiGress: Discrete denoising diffusion for graph generation
Clement Vignac, Igor Krawczuk, Antoine Siraudin, Bohan Wang, Volkan Cevher, and Pas- cal Frossard. DiGress: Discrete denoising diffusion for graph generation. InInternational Conference on Learning Representations, 2023. 16
work page 2023
-
[77]
Illume: Illuminating your LLMs to see, draw, and self-enhance.ArXiv, abs/2412.06673, 2024
Chunwei Wang, Guansong Lu, Junwei Yang, Runhu Huang, Jianhua Han, Lu Hou, Wei Zhang, and Hang Xu. Illume: Illuminating your LLMs to see, draw, and self-enhance.ArXiv, abs/2412.06673, 2024
-
[78]
Jin Wang, Yao Lai, Aoxue Li, Shifeng Zhang, Jiacheng Sun, Ning Kang, Chengyue Wu, Zhen- guo Li, and Ping Luo. FUDOKI: Discrete flow-based unified understanding and generation via kinetic-optimal velocities.arXiv preprint arXiv:2505.20147, 2025
-
[79]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Tao Li, Boya Wu, Bo Zhao, Bowen Zhang, Lian-zi Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Tiejun Huang, and Zhongyuan Wang. Emu3: Next-token prediction is all you need.arXiv p...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[80]
Janus: Decoupling visual encoding for unified multimodal understanding and generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, and Ping Luo. Janus: Decoupling visual encoding for unified multimodal understanding and generation. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 12966–12977, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.