Towards a more realistic evaluation of machine learning models for bearing fault diagnosis
Pith reviewed 2026-05-21 21:16 UTC · model grok-4.3
The pith
Common ways of splitting bearing vibration data let models train and test on the same physical bearings, creating leakage that inflates accuracy scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
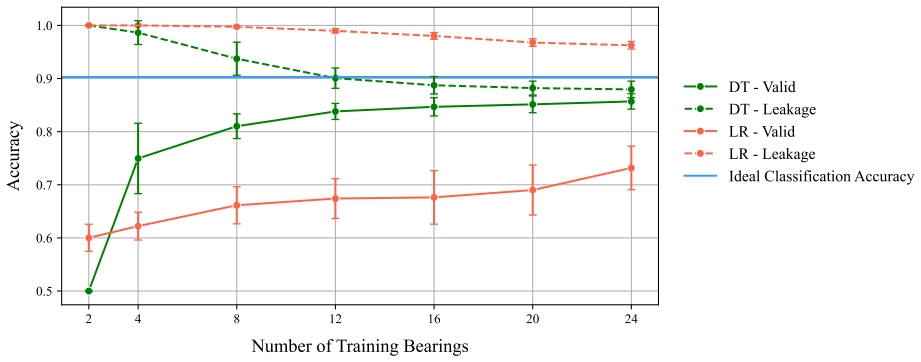
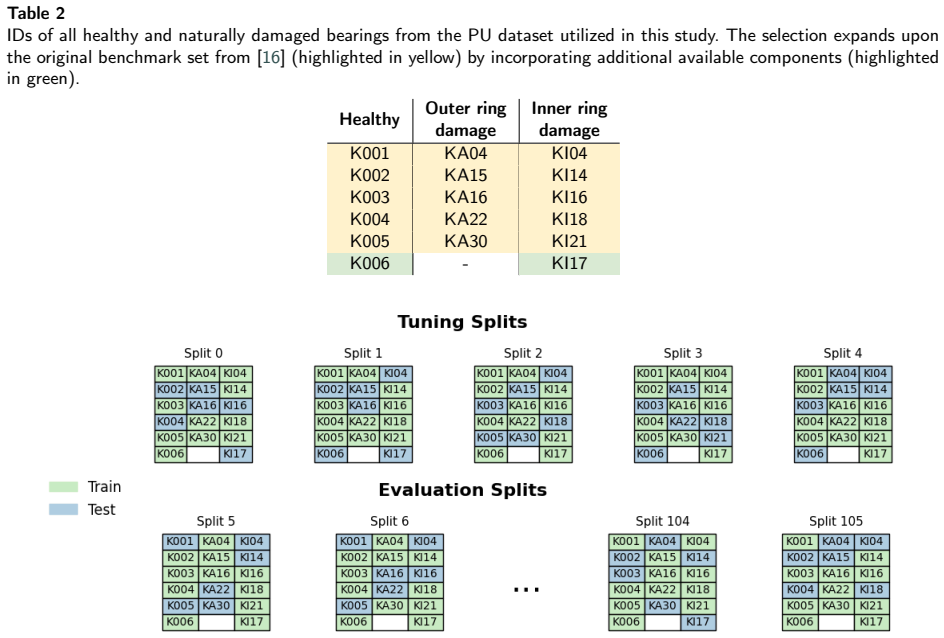
The authors argue that leakage from non-bearing-wise partitions is the primary cause of overstated results in existing machine learning studies of bearing faults. They show that enforcing a partition by physical bearing, reformulating the problem as multi-label classification, and adopting prevalence-independent ROC metrics produces substantially lower yet more realistic performance figures, with the count of unique training bearings emerging as the decisive variable for generalization.
What carries the argument
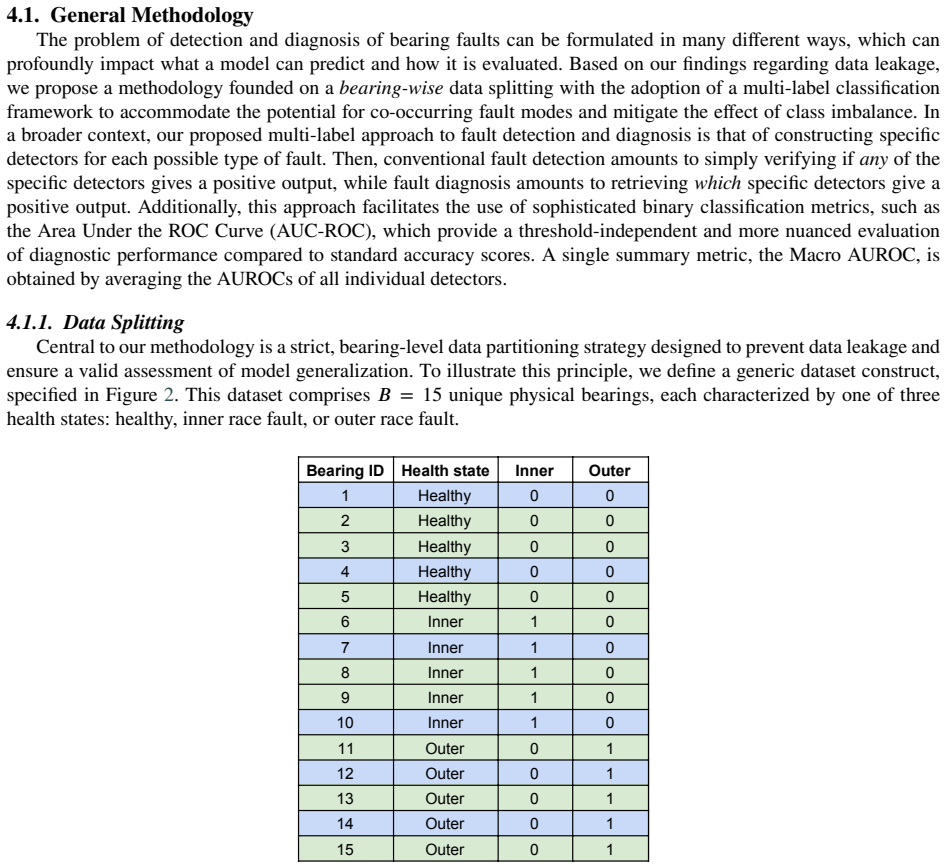
Bearing-wise data partitioning that places all measurements from any single physical bearing exclusively into the training set or the test set.
If this is right
- Reported accuracies for bearing fault models will drop once leakage is removed, but the remaining performance will be a better predictor of behavior on unseen equipment.
- Collecting data from a larger number of distinct bearings becomes the most effective way to improve generalization rather than refining model architecture alone.
- Multi-label classification allows simultaneous detection of co-occurring fault types that single-label setups miss.
- ROC-based metrics give a clearer comparison across datasets that differ in fault prevalence.
Where Pith is reading between the lines
- The same leakage patterns probably appear in other sensor-based diagnosis tasks that reuse measurements from the same physical units.
- Public benchmark datasets may need to be expanded with many more independent bearings before they can support claims of robust industrial performance.
- Engineers may have to gather site-specific bearing data rather than rely solely on existing public collections for reliable deployment.
Load-bearing premise
The bearings within each dataset are sufficiently independent that removing any one of them from the training pool still leaves a representative range of fault behaviors for real-world use.
What would settle it
If models retrained under a strict bearing-wise split on the same four datasets recover the high accuracies previously reported in the literature, the claim that leakage was the main driver of inflated performance would be refuted.
Figures
read the original abstract
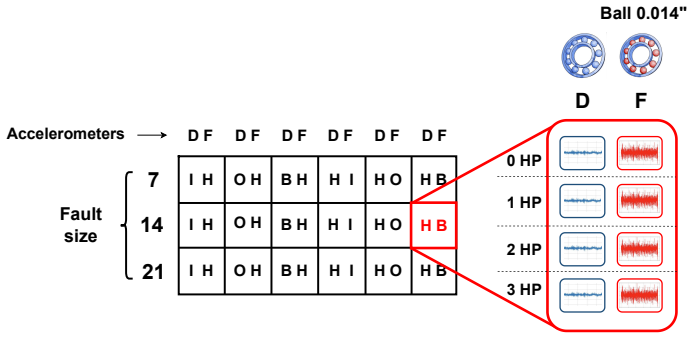
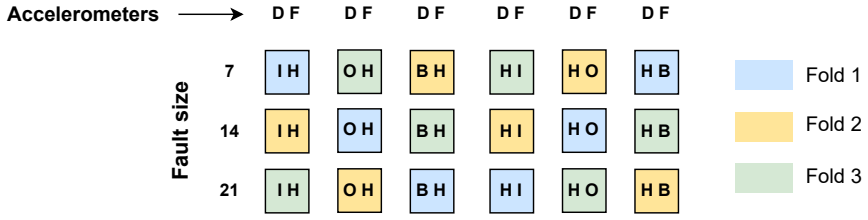
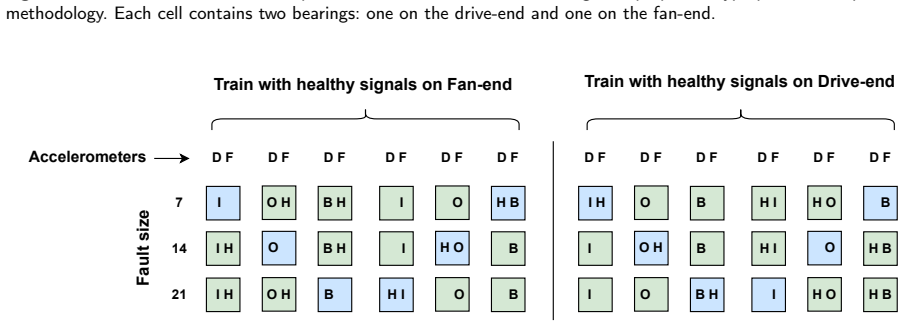
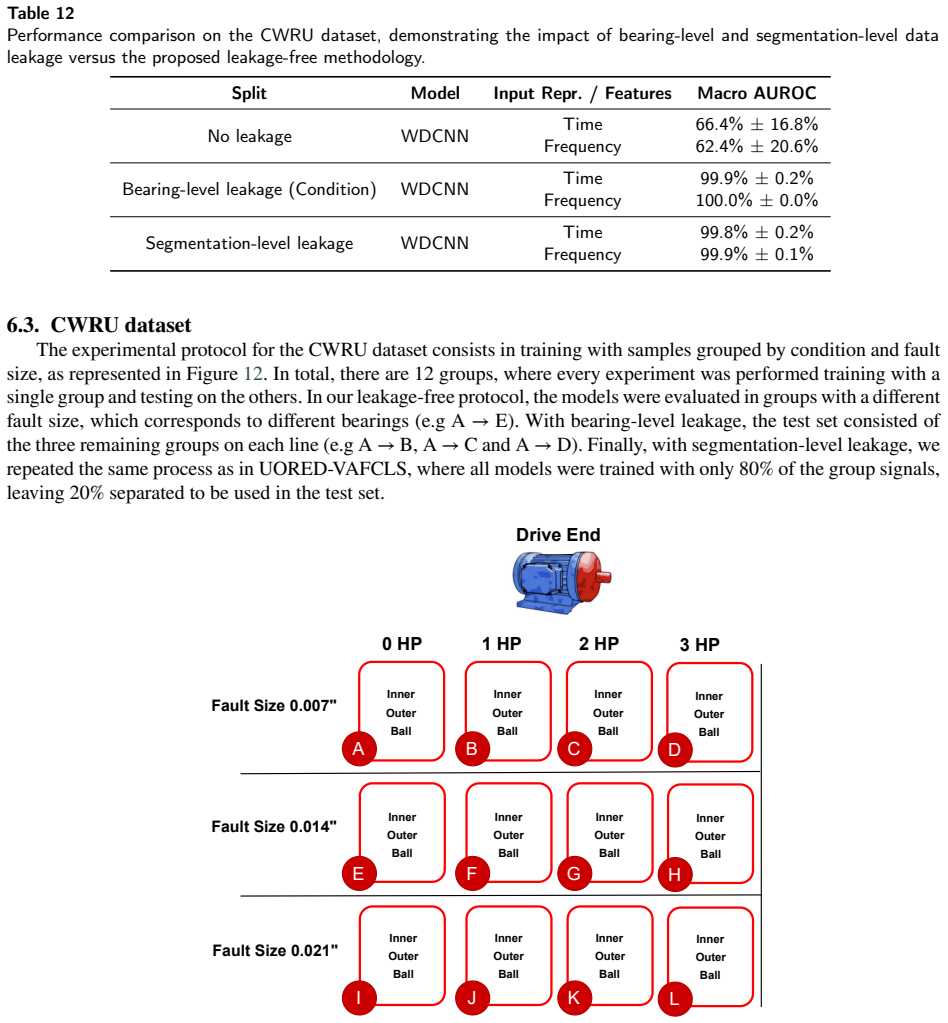
Reliable detection of bearing faults is essential for maintaining the safety and operational efficiency of rotating machinery. While recent advances in machine learning (ML), particularly deep learning, have shown strong performance in controlled settings, many studies fail to generalize to real-world applications due to methodological flaws, most notably data leakage. This paper investigates the issue of data leakage in vibration-based bearing fault diagnosis and its impact on model evaluation. We demonstrate that common dataset partitioning strategies, such as segment-wise and condition-wise splits, introduce spurious correlations that inflate performance metrics. To address this, we propose a rigorous, leakage-free evaluation methodology centered on bearing-wise data partitioning, ensuring no overlap between the physical components used for training and testing. Additionally, we reformulate the classification task as a multi-label problem, enabling the detection of co-occurring fault types and the use of prevalence-independent metrics based on the ROC curve. Beyond preventing leakage, we also examine the effect of dataset diversity on generalization, showing that the number of unique training bearings is a decisive factor for achieving robust performance. We evaluate our methodology on four widely adopted datasets: CWRU, Paderborn University (PU), University of Ottawa (UORED-VAFCLS) and HUST bearing. This study highlights the importance of leakage-aware evaluation protocols and provides practical guidelines for dataset partitioning, model selection, and validation, fostering the development of more trustworthy ML systems for industrial fault diagnosis applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that common dataset partitioning strategies such as segment-wise and condition-wise splits in vibration-based bearing fault diagnosis introduce spurious correlations and data leakage, inflating ML model performance metrics. It proposes a bearing-wise partitioning scheme that ensures no physical bearing overlap between training and test sets, reformulates the task as multi-label classification to handle co-occurring faults with prevalence-independent ROC metrics, and reports that performance drops under this split while improving as the number of unique training bearings increases. The approach is evaluated on the CWRU, Paderborn University (PU), UORED-VAFCLS, and HUST datasets.
Significance. If the empirical findings hold, the work is significant for promoting more trustworthy evaluation protocols in industrial ML applications. It directly targets a known source of over-optimism in the bearing fault diagnosis literature by demonstrating concrete performance gaps on four public datasets and by linking generalization to training-set diversity. The multi-label reformulation and emphasis on leakage-free splits provide actionable guidelines that could improve reproducibility and real-world applicability.
major comments (1)
- The central claim that bearing-wise splits remove leakage rests on the assumption that physical bearings constitute the dominant source of independent variation; the manuscript should explicitly test or discuss whether shared manufacturing batches or sensor mounting effects across bearings could still induce correlations even after a bearing-wise split (see the weakest-assumption note in the stress test).
minor comments (3)
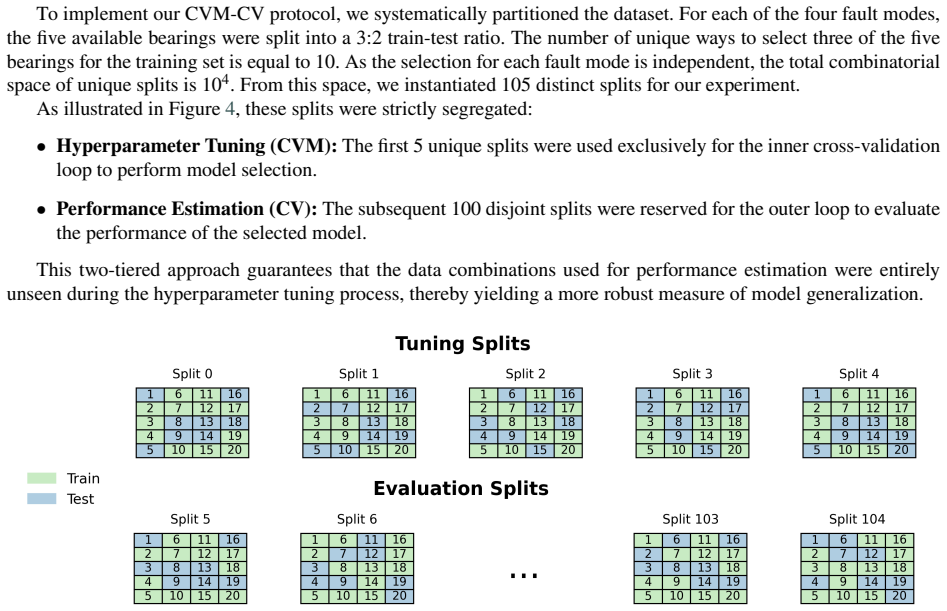
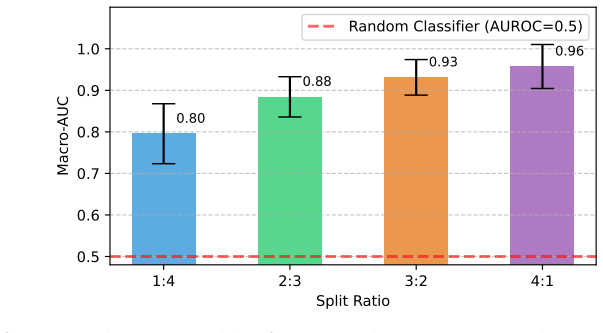
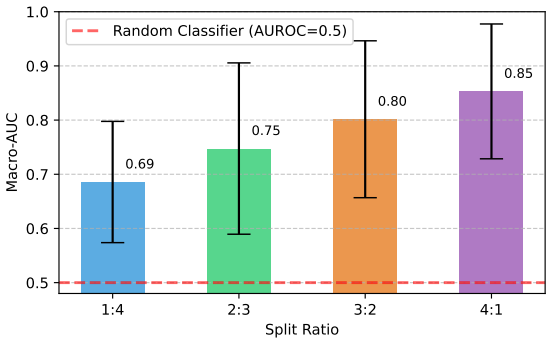
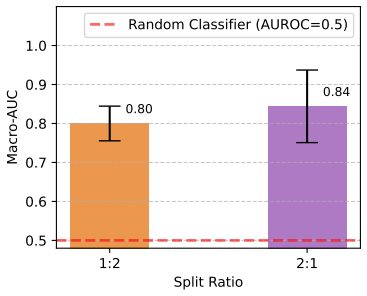
- The abstract and experimental sections would benefit from reporting the exact train/test bearing counts and split ratios used for each of the four datasets to allow direct replication.
- Clarify how the multi-label formulation handles cases where multiple fault types co-occur on the same bearing; an explicit label-encoding example or reference to the ROC implementation would improve clarity.
- Figure captions and table headers should explicitly state whether the reported metrics are macro-averaged or micro-averaged ROC-AUC to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has helped us strengthen the discussion of assumptions underlying our proposed evaluation protocol. We address the major comment below and have made corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: The central claim that bearing-wise splits remove leakage rests on the assumption that physical bearings constitute the dominant source of independent variation; the manuscript should explicitly test or discuss whether shared manufacturing batches or sensor mounting effects across bearings could still induce correlations even after a bearing-wise split (see the weakest-assumption note in the stress test).
Authors: We agree that physical bearings are not necessarily the only possible source of correlation and that factors such as shared manufacturing batches or sensor mounting could in principle induce residual dependencies. Our bearing-wise partitioning is designed to eliminate the most direct and commonly overlooked form of leakage—reusing multiple segments or operating conditions from the identical physical bearing—which the literature has shown to produce unrealistically high performance. In the revised manuscript we have added an explicit paragraph in the Discussion section acknowledging this limitation of the assumption, noting that the public datasets (CWRU, PU, UORED-VAFCLS, HUST) lack batch-level or mounting metadata that would allow an empirical stress test of these secondary effects. We therefore treat the bearing-wise split as a necessary but not always sufficient condition for leakage-free evaluation and recommend that future dataset releases include such metadata. This addition does not change our empirical results but clarifies the scope of the claims. revision: partial
- Explicit empirical testing of manufacturing-batch or sensor-mounting correlations is not possible with the current public datasets because they do not release the required metadata.
Circularity Check
No significant circularity
full rationale
The manuscript is an empirical comparison of dataset partitioning schemes on four public bearing-fault datasets. Its central claims rest on measured performance differences between segment-wise, condition-wise, and bearing-wise splits, together with a multi-label ROC reformulation; none of these quantities are defined in terms of parameters fitted from the same evaluation data, nor do they reduce to self-citations or imported uniqueness theorems. The argument is therefore self-contained against external benchmarks and contains no load-bearing step that collapses to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vibration signals from distinct physical bearings are independent enough that placing all data from one bearing entirely in train or test removes spurious correlations.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a rigorous, leakage-free evaluation methodology centered on bearing-wise data partitioning, ensuring no overlap between the physical components used for training and testing. Additionally, we reformulate the classification task as a multi-label problem, enabling the detection of co-occurring fault types and the use of prevalence-independent metrics such as Macro AUROC.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the number of unique training bearings is a decisive factor for achieving robust performance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Y. Lei, B. Yang, X. Jiang, F. Jia, N. Li, A. K. Nandi, Applications of machine learning to machine fault diagnosis: A review and roadmap, Mechanical Systems and Signal Processing 138 (2020) 106587
work page 2020
-
[2]
S. Kapoor, E. M. Cantrell, K. Peng, T. H. Pham, C. A. Bail, O. E. Gundersen, J. M. Hofman, J. Hullman, M. A. Lones, M. M. Malik, P. Nanayakkara, R. A. Poldrack, I. D. Raji, M. Roberts, M. J. Salganik, M. Serra-Garcia, B. M. Stewart, G. Vandewiele, A. Narayanan, Reforms: Consensus-based recommendations for machine-learning-based science, Science Advances 1...
-
[3]
S. Kapoor, A. Narayanan, Leakage and the reproducibility crisis in machine-learning-based science, Patterns 4 (9) (2023) 100804.doi: https://doi.org/10.1016/j.patter.2023.100804. URL https://www.sciencedirect.com/science/article/pii/S2666389923001599
-
[4]
T.W.Rauber,A.L.daSilvaLoca,F.d.A.Boldt,A.L.Rodrigues,F.M.Varejão,Anexperimentalmethodologytoevaluatemachinelearning methodsforfaultdiagnosisbasedonvibrationsignals,ExpertSystemswithApplications167(2021)114022. doi:10.1016/j.eswa.2020. 114022
-
[5]
J. Hendriks, P. Dumond, D. Knox, Towards better benchmarking using the CWRU bearing fault dataset, Mechanical Systems and Signal Processing 169 (2022) 108732
work page 2022
- [6]
-
[7]
D. R. Roberts, V. Bahn, S. Ciuti, M. S. Boyce, J. Elith, G. Guillera-Arroita, S. Hauenstein, J. J. Lahoz-Monfort, B. Schröder, W. Thuiller, D. I. Warton, B. A. Wintle, F. Hartig, C. F. Dormann, Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure, Ecography 40 (8) (2017) 913–929.doi:10.1111/ecog.02881
-
[8]
F.Pedregosa,G.Varoquaux,A.Gramfort,V.Michel,B.Thirion,O.Grisel,M.Blondel,P.Prettenhofer,R.Weiss,V.Dubourg,J.Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, E. Duchesnay, Scikit-learn: Machine learning in Python, Journal of Machine Learning Research 12 (2011) 2825–2830
work page 2011
-
[9]
S. Kaufman, S. Rosset, C. Perlich, Leakage in data mining: Formulation, detection, and avoidance, Vol. 6, 2011, pp. 556–563.doi: 10.1145/2020408.2020496
-
[10]
M.A.Lones,Howtoavoidmachinelearningpitfalls:aguideforacademicresearchers,CoRRabs/2108.02497(2021). arXiv:2108.02497. URL https://arxiv.org/abs/2108.02497
-
[11]
M. A. Lones, Avoiding common machine learning pitfalls, Patterns (2024) 101046doi:10.1016/j.patter.2024.101046
-
[12]
I. M. D. S. Varejão, L. G. D. O. Costa, L. H. P. D. Silva, A. Rodrigues, M. P. Ribeiro, F. M. Varejão, T. Oliveira-Santos, The similarity bias problem: What it is and how it impacts vibration based intelligent fault diagnosis, Mechanical Systems and Signal Processing 235 (2025) 112822, publisher: Elsevier BV.doi:10.1016/j.ymssp.2025.112822. URL https://li...
-
[13]
L. Wheat, M. V. Mohrenschildt, S. Habibi, D. Al-Ani, Impact of Data Leakage in Vibration Signals Used for Bearing Fault Diagnosis, IEEEAccess12(2024)169879–169895,publisher:InstituteofElectricalandElectronicsEngineers(IEEE). doi:10.1109/access.2024. 3497716. URL https://ieeexplore.ieee.org/document/10752530/
-
[14]
D. Wang, Y. Li, L. Jia, Y. Song, Y. Liu, Novel three-stage feature fusion method of multimodal data for bearing fault diagnosis, IEEE Transactions on Instrumentation and Measurement 70 (2021) 1–10.doi:10.1109/TIM.2021.3071232
-
[15]
D.Wang,Y.Li,L.Jia,Y.Song,T.Wen,Attention-basedbilinearfeaturefusionmethodforbearingfaultdiagnosis,IEEE/ASMETransactions on Mechatronics 28 (3) (2023) 1695–1705.doi:10.1109/TMECH.2022.3223358
-
[16]
C. Lessmeier, J. K. Kimotho, D. Zimmer, W. Sextro, Condition monitoring of bearing damage in electromechanical drive systems by using motor current signals of electric motors: A benchmark data set for data-driven classification, in: PHM society European conference, Vol. 3, 2016
work page 2016
-
[17]
I. Tsamardinos, A. Rakhshani, V. Lagani, Performance-estimation properties of cross-validation-based protocols with simultaneous hyper- parameter optimization, International Journal on Artificial Intelligence Tools 24 (05) (2015) 1540023
work page 2015
-
[18]
URL https://linkinghub.elsevier.com/retrieve/pii/S2352340923004456
M.Sehri,P.Dumond,M.Bouchard,UniversityofOttawaconstantloadandspeedrolling-elementbearingvibrationandacousticfaultsignature datasets, Data in Brief 49 (2023) 109327, publisher: Elsevier BV.doi:10.1016/j.dib.2023.109327. URL https://linkinghub.elsevier.com/retrieve/pii/S2352340923004456
-
[19]
URL https://www.sciencedirect.com/science/article/pii/S0888327015002034
W.A.Smith,R.B.Randall,Rollingelementbearingdiagnosticsusingthecasewesternreserveuniversitydata:Abenchmarkstudy,Mechanical Systems and Signal Processing 64-65 (2015) 100–131.doi:https://doi.org/10.1016/j.ymssp.2015.04.021. URL https://www.sciencedirect.com/science/article/pii/S0888327015002034
-
[20]
M. González, V. G. Díaz, B. L. Pérez, B. C. P. G-Bustelo, J. P. Anzola, Bearing fault diagnosis with envelope analysis and machine learning approaches using cwru dataset, IEEE Access 11 (2023) 57796–57805.doi:10.1109/ACCESS.2023.3283466
-
[21]
URL https://www.mdpi.com/1424-8220/17/2/425
W.Zhang,G.Peng,C.Li,Y.Chen,Z.Zhang,ANewDeepLearningModelforFaultDiagnosiswithGoodAnti-NoiseandDomainAdaptation Ability on Raw Vibration Signals, Sensors 17 (2) (2017) 425, publisher: MDPI AG.doi:10.3390/s17020425. URL https://www.mdpi.com/1424-8220/17/2/425
-
[22]
J. Jiao, M. Zhao, J. Lin, C. Ding, Deep Coupled Dense Convolutional Network With Complementary Data for Intelligent Fault Diagnosis, IEEE Transactions on Industrial Electronics 66 (12) (2019) 9858–9867, publisher: Institute of Electrical and Electronics Engineers (IEEE). J. P. Vieira et al.:Preprint submitted to Elsevier Page 24 of 25 doi:10.1109/tie.2019...
-
[23]
275–283.doi:10.1109/ icdmw51313.2020.00046
J.VanDenHoogen,S.Bloemheuvel,M.Atzmueller,AnImprovedWide-KernelCNNforClassifyingMultivariateSignalsinFaultDiagnosis, in: 2020 International Conference on Data Mining Workshops (ICDMW), IEEE, Sorrento, Italy, 2020, pp. 275–283.doi:10.1109/ icdmw51313.2020.00046. URL https://ieeexplore.ieee.org/document/9346555/
-
[24]
Q. Wei, Y. Liu, X. Ruan, A report on audio tagging with deeper cnn, 1d-convnet and 2d-convnet, DCASE, 2018. URL https://dcase.community/documents/challenge2018/technical_reports/DCASE2018_WEI_53.pdf
work page 2018
-
[25]
P. Tchatchoua, G. Graton, M. Ouladsine, J.-F. Christaud, Application of 1D ResNet for Multivariate Fault Detection on Semiconductor Manufacturing Equipment, Sensors 23 (22) (2023) 9099, publisher: MDPI AG.doi:10.3390/s23229099. URL https://www.mdpi.com/1424-8220/23/22/9099
-
[26]
Z. Yan, H. Liu, SMoCo: A Powerful and Efficient Method Based on Self-Supervised Learning for Fault Diagnosis of Aero-Engine Bearing under Limited Data, Mathematics 10 (15) (2022) 2796, publisher: MDPI AG.doi:10.3390/math10152796. URL https://www.mdpi.com/2227-7390/10/15/2796 J. P. Vieira et al.:Preprint submitted to Elsevier Page 25 of 25
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.