We Think, Therefore We Align LLMs to Helpful, Harmless and Honest Before They Go Wrong
Pith reviewed 2026-05-21 22:07 UTC · model grok-4.3
The pith
Adaptive Multi-Branch Steering aligns large language models to helpful, harmless, and honest objectives together by updating separate pathways relative to one shared reference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
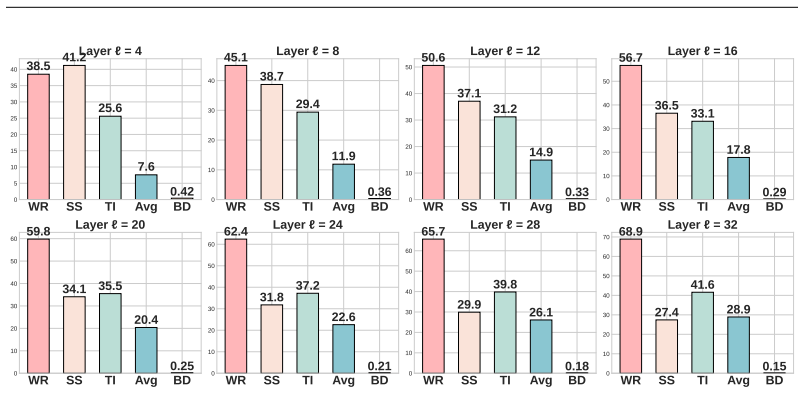
Adaptive Multi-Branch Steering is a two-stage framework in a 1-to-N Transformer setting that parameterizes objective-specific transformations relative to a shared representation. In Stage I a shared hidden representation is computed once. In Stage II this representation is replicated into N pathways and updated relative to a shared reference, capturing objective-specific deviations while restricting divergence. This produces N objective-specific responses within a single forward pass that can be combined at decoding to obtain a single response across objectives.
What carries the argument
Adaptive Multi-Branch Steering (AMBS), which computes a shared hidden representation once and then replicates and updates it into N objective-specific pathways relative to a shared reference so that multiple alignment objectives can be satisfied without interference.
If this is right
- LLMs produce responses that better satisfy helpfulness, harmlessness, and honesty at the same time in settings where single-objective methods overwrite each other.
- Performance gains appear across different model backbones in metrics such as WR, TI, and SS while token throughput and GPU hours remain comparable to baselines.
- Objective-specific responses remain consistent because all pathways start from the same shared representation before their targeted updates.
- The two-stage design keeps the cost of adding more objectives low because the shared representation is computed only once per forward pass.
Where Pith is reading between the lines
- The shared-reference design could extend naturally to alignment tasks that involve four or more simultaneous objectives without a proportional rise in inference cost.
- Separating the shared computation from the per-objective adjustments opens a route to faster serving systems that switch among value sets at decode time.
- If the reference representation preserves core model knowledge, the same structure might help retain general capabilities while fine-tuning for new objective combinations.
Load-bearing premise
Updating each objective-specific pathway relative to a single shared reference will capture the necessary deviations while automatically restricting harmful divergence and preserving consistency across objectives during decoding.
What would settle it
Measure the rate at which responses jointly satisfy all three HHH objectives on complex prompts where prior aligned models fail, and compare results when the shared-reference update step is removed versus kept.
Figures




read the original abstract
Alignment of Large Language Models (LLMs) is the ability to satisfy desired objectives during generation, which is critical for trustworthy deployment. In practice, alignment is often operationalized through multiple objectives such as Helpfulness, Harmlessness, and Honesty (HHH). Prior works study alignment via steering vectors in standard Transformer decoders but treat objectives in isolation, where optimizing a single objective can overwrite others, leading to interference. Recent works attempt to address this limitation by extending steering to a 1-to-N Transformer setting by replicating representations into objective-specific pathways, but apply transformations independently, resulting in inconsistent responses across objectives. Similarly, approaches such as safe RLHF and MoE-based designs study trade-offs across objectives but do not constrain objective-specific transformations within a shared representation during inference. As a result, even aligned State-of-the-Art (SOTA) LLMs can struggle to jointly satisfy HHH objectives in complex settings. To address this, we propose Adaptive Multi-Branch Steering (AMBS), a two-stage framework in a 1-to-N Transformer setting that parameterizes objective-specific transformations relative to a shared representation. In Stage I, a shared hidden representation is computed once. In Stage II, this representation is replicated into N pathways and updated relative to a shared reference, capturing objective-specific deviations while restricting divergence. This produces N objective-specific responses within a single forward pass, which can be combined at decoding to obtain a single response across objectives. Across multiple backbones, AMBS improves performance across HHH, with consistent gains in WR, TI, and SS (e.g., Avg 56.5% on LLaMA-2-7B) while maintaining efficiency (e.g., 189 Tok/s, 9 GPU-hrs).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Adaptive Multi-Branch Steering (AMBS), a two-stage 1-to-N Transformer framework for joint HHH (Helpful, Harmless, Honest) alignment of LLMs. Stage I computes a single shared hidden representation; Stage II replicates it into N objective-specific pathways that are updated relative to a shared reference to capture deviations while restricting divergence. This yields N responses in one forward pass that are combined at decoding. The authors report consistent gains on WR, TI, and SS metrics (e.g., 56.5% average on LLaMA-2-7B) across backbones while preserving efficiency (189 Tok/s, 9 GPU-hrs).
Significance. If the relative-update mechanism in Stage II successfully enforces cross-objective consistency without explicit penalties or extra parameters, AMBS would offer a parameter-efficient alternative to independent steering vectors or post-hoc MoE/RLHF combinations for multi-objective alignment. The single-forward-pass design and reported throughput numbers suggest practical deployment value for trustworthy LLMs.
major comments (2)
- [Abstract] Abstract / Stage II description: The central claim that replicating the shared representation and updating each pathway 'relative to a shared reference' automatically 'restrict[s] divergence' and 'preserv[es] consistency across objectives during decoding' is load-bearing for all reported HHH gains and the single-pass consistency result. No equation, pseudocode, or explicit constraint (e.g., divergence penalty, projection onto common subspace, or tied parameters) is supplied in the description; an independent learned transformation per pathway would be expected to reintroduce the overwriting problem noted for prior 1-to-N methods.
- [Experiments] Experiments section (performance claims): The reported gains (e.g., Avg 56.5% on LLaMA-2-7B, consistent WR/TI/SS improvements) are presented without reference to specific baselines, ablation controls for the shared-reference update, statistical tests, or variance across runs. This makes it impossible to isolate whether the improvements stem from the proposed relative-update mechanism or from other implementation details such as the decoding combination step.
minor comments (2)
- [Method] Notation for the N pathways and the 'shared reference' vector should be introduced with explicit symbols (e.g., h_shared, h_i for pathway i) rather than prose only, to allow readers to verify the update rule.
- [Experiments] The efficiency numbers (Tok/s and GPU-hrs) would benefit from a direct comparison table against the 1-to-N baselines mentioned in the related-work discussion.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below with clarifications and indicate where revisions will be made to improve the presentation of AMBS.
read point-by-point responses
-
Referee: [Abstract] Abstract / Stage II description: The central claim that replicating the shared representation and updating each pathway 'relative to a shared reference' automatically 'restrict[s] divergence' and 'preserv[es] consistency across objectives during decoding' is load-bearing for all reported HHH gains and the single-pass consistency result. No equation, pseudocode, or explicit constraint (e.g., divergence penalty, projection onto common subspace, or tied parameters) is supplied in the description; an independent learned transformation per pathway would be expected to reintroduce the overwriting problem noted for prior 1-to-N methods.
Authors: We agree that the abstract offers a concise, high-level description of Stage II and that an explicit formulation would strengthen the central claim regarding divergence restriction. The manuscript text describes the process of replicating the shared representation and updating pathways relative to a shared reference to capture deviations, but we acknowledge the absence of a formal equation or pseudocode in the provided description. In the revised version we will insert a precise mathematical definition of the relative update (anchoring each pathway to the shared reference) along with pseudocode for the two-stage inference procedure. This will explicitly show how the mechanism avoids fully independent transformations and thereby mitigates the overwriting issue. revision: yes
-
Referee: [Experiments] Experiments section (performance claims): The reported gains (e.g., Avg 56.5% on LLaMA-2-7B, consistent WR/TI/SS improvements) are presented without reference to specific baselines, ablation controls for the shared-reference update, statistical tests, or variance across runs. This makes it impossible to isolate whether the improvements stem from the proposed relative-update mechanism or from other implementation details such as the decoding combination step.
Authors: We thank the referee for highlighting this gap in experimental rigor. The current experiments section reports aggregate improvements on WR, TI, and SS metrics across backbones and compares against prior steering approaches, yet we agree that dedicated ablations isolating the shared-reference update, variance across runs, and statistical tests are missing. In the revision we will add an ablation that removes the relative-update component, report standard deviations over multiple seeds, and include appropriate statistical significance tests to better attribute gains to the proposed mechanism rather than decoding or other factors. revision: yes
Circularity Check
No significant circularity; method description is self-contained
full rationale
The paper describes a two-stage AMBS framework in which Stage I computes a shared hidden representation and Stage II replicates it into N pathways then updates each relative to a shared reference. No equations, derivations, or fitted parameters are shown that reduce the claimed restriction on divergence or the HHH performance gains to a self-referential quantity by construction. Prior works are cited only to motivate the problem; the central mechanism is presented as an independent parameterization rather than derived from or equivalent to any self-citation or input fit. Empirical results on WR, TI, and SS are reported as measured outcomes, not as predictions forced by the method definition itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A shared hidden representation computed once can serve as a stable reference for objective-specific updates without losing task-relevant information.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
In Stage I, post-attention hidden states ... are computed once ... In Stage II, this representation is cloned into parallel branches and steered via a policy–reference mechanism
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L^(n)_cos = 1 - cos(y^(n)_+, y^(n)_-)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Constitutional ai: Harmlessness from ai feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Colin McKinnon, et al. Constitutional ai: Harmlessness from ai feedback. In Advances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[3]
Accelerating large language model decoding with speculative sampling
Shouyuan Chen, Yang Yu, Mohammed Muqeeth, Deepak Narayanan, Eric Qin, Yanping Huang, Xinyi Song, Romal Thoppilan, Zhifeng Xu, Nan Chen, et al. Accelerating large language model decoding with speculative sampling. In International Conference on Machine Learning (ICML), volume 202 of Proceedings of Machine Learning Research, pp.\ 5188--5218, 2023
work page 2023
-
[4]
Continual learning and catastrophic forgetting
Zhiyuan Chen and Bing Liu. Continual learning and catastrophic forgetting. In Lifelong Machine Learning, pp.\ 55--75. Springer, 2022
work page 2022
-
[5]
Deep reinforcement learning from human preferences
Paul Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems (NeurIPS), pp.\ 4299--4307, 2017
work page 2017
-
[6]
Nouha Dziri, Sasha Milton, Mo Yu, Osmar Zaiane, and Siva Reddy. On the origin of hallucinations in conversational models: Is it the datasets or the models? In Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 5274--5296, 2022
work page 2022
-
[7]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. Toy models of superposition. arXiv preprint arXiv:2209.10652, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
The capacity for moral self-correction in large language models
Deep Ganguli, Amanda Askell, Yuntao Bai, Anna Chen, Anna Goldie, Kamal Ndousse, Sam Ringer, Nicholas Schiefer, Ilya Sutskever, Nikolas Tran-Johnson, et al. The capacity for moral self-correction in large language models. arXiv preprint arXiv:2302.07459, 2023
-
[9]
Honestllm: Toward an honest and helpful large language model
Chujie Gao, Siyuan Wu, Yue Huang, Dongping Chen, Qihui Zhang, Zhengyan Fu, Yao Wan, Lichao Sun, and Xiangliang Zhang. Honestllm: Toward an honest and helpful large language model. arXiv preprint arXiv:2406.00380, 2024
-
[10]
Scaling laws and interpretability of learning from repeated data
Evan Hernandez, Jiawei Wang, and Samuel R Bowman. Scaling laws and interpretability of learning from repeated data. arXiv preprint arXiv:2307.10444, 2023
-
[11]
Beavertails: Towards improved safety alignment of llm via a human-preference dataset
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. Beavertails: Towards improved safety alignment of llm via a human-preference dataset. Advances in Neural Information Processing Systems, 36: 0 24678--24704, 2023 a
work page 2023
-
[12]
Aligner: Efficient alignment by learning to correct
Jiaming Ji, Boyuan Chen, Hantao Lou, Donghai Hong, Borong Zhang, Xuehai Pan, Tianyi Alex Qiu, Juntao Dai, and Yaodong Yang. Aligner: Efficient alignment by learning to correct. Advances in Neural Information Processing Systems, 37: 0 90853--90890, 2024
work page 2024
-
[13]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yanfei Xu, Eric Ishii, Yejin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 55 0 (12): 0 1--38, 2023 b
work page 2023
-
[14]
Too helpful, too harmless, too honest or just right? arXiv preprint arXiv:2509.08486, 2025
Gautam Siddharth Kashyap, Mark Dras, and Usman Naseem. Too helpful, too harmless, too honest or just right? arXiv preprint arXiv:2509.08486, 2025
-
[15]
Chatgpt for good? on opportunities and challenges of large language models for education
Enkelejda Kasneci, Kevin Sessler, Stefan K \"u chemann, Maria Bannert, Darya Dementieva, Frank Fischer, Urs Gasser, Georg Groh, Gjergji Kasneci, Stephan Krusche, et al. Chatgpt for good? on opportunities and challenges of large language models for education. Learning and Individual Differences, 103: 0 102274, 2023
work page 2023
-
[16]
Efficient streaming language models with attention sinks
Devin Kreuzer, Suraj Bhargava, Roman Svirschevski, Ziyi Huang, Aakanksha Chowdhery, Adam Roberts, Sebastian Borgeaud, Jack W Rae, and Yi Tay. Efficient streaming language models with attention sinks. In International Conference on Machine Learning (ICML), volume 202 of Proceedings of Machine Learning Research, pp.\ 17341--17355, 2023
work page 2023
-
[17]
Inference-time intervention: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Vi \'e gas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems, 36: 0 41451--41530, 2023 a
work page 2023
-
[18]
Alpacaeval: An automatic evaluator of instruction-following models, 2023 b
Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Alpacaeval: An automatic evaluator of instruction-following models, 2023 b
work page 2023
-
[19]
Contrastive activation steering of language models
Zekun Li, Andy Zou, James Zou, and Chelsea Finn. Contrastive activation steering of language models. In International Conference on Learning Representations (ICLR), 2023 c
work page 2023
-
[20]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 3214--3252, 2022
work page 2022
-
[21]
Aligning large language models with human preferences through representation engineering
Wenhao Liu, Xiaohua Wang, Muling Wu, Tianlong Li, Changze Lv, Zixuan Ling, Zhu JianHao, Cenyuan Zhang, Xiaoqing Zheng, and Xuan-Jing Huang. Aligning large language models with human preferences through representation engineering. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 10619-...
work page 2024
-
[22]
Haoran Lu, Luyang Fang, Ruidong Zhang, Xinliang Li, Jiazhang Cai, Huimin Cheng, Lin Tang, Ziyu Liu, Zeliang Sun, Tao Wang, et al. Alignment and safety in large language models: Safety mechanisms, training paradigms, and emerging challenges. arXiv preprint arXiv:2507.19672, 2025
-
[23]
Multi-attribute steering of language models via targeted intervention
Duy Nguyen, Archiki Prasad, Elias Stengel-Eskin, and Mohit Bansal. Multi-attribute steering of language models via targeted intervention. arXiv preprint arXiv:2502.12446, 2025
-
[24]
Training language models to follow instructions with human feedback
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[25]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[26]
Extracting steering vectors from pretrained language models
Nishant Subramani, Shubham Sharma, Joyce Xu, Abhay Sharma, Afra Feyza Aky \"u rek, He He, and Mohit Bansal. Extracting steering vectors from pretrained language models. In Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 9603--9620, 2022
work page 2022
-
[27]
Analyzing the generalization and reliability of steering vectors, 2025
Daniel Tan, David Chanin, Aengus Lynch, Dimitrios Kanoulas, Brooks Paige, Adria Garriga-Alonso, and Robert Kirk. Analyzing the generalization and reliability of steering vectors, 2025
work page 2025
-
[28]
Stanford alpaca: An instruction-following llama model, 2023
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Stanford alpaca: An instruction-following llama model, 2023
work page 2023
-
[29]
F., Ilhan, F., Huang, T., Hu, S., Yahn, Z., and Liu, L
Selim Furkan Tekin, Fatih Ilhan, Tiansheng Huang, Sihao Hu, Zachary Yahn, and Ling Liu. H 3 fusion: Helpful, harmless, honest fusion of aligned llms. arXiv preprint arXiv:2411.17792, 2024
-
[30]
Multi-agent reinforcement learning with focal diversity optimization
Selim Furkan Tekin, Fatih Ilhan, Tiansheng Huang, Sihao Hu, Zachary Yahn, and Ling Liu. Multi-agent reinforcement learning with focal diversity optimization. arXiv preprint arXiv:2502.04492, 2025
-
[31]
Large language models in medicine
Ajithkumar J Thirunavukarasu, Daniel SW Ting, Harini Elangovan, Laura Gutierrez, Julian H Tan, Darren S Ting, Han Lin, Arun Thirunavukarasu, Li Liu, Bhargav Raman, et al. Large language models in medicine. Nature Medicine, 29: 0 1930--1940, 2023
work page 1930
-
[32]
Steering language models with activation additions
Alexander Turner, Sam Ringer, William Saunders, and Ben Shlegeris. Steering language models with activation additions. In Advances in Neural Information Processing Systems (NeurIPS), 2023 a
work page 2023
-
[33]
Steering language models with activation additions
Alexander Turner, Sam Ringer, William Saunders, and Ben Shlegeris. Steering language models with activation additions. In Advances in Neural Information Processing Systems (NeurIPS), 2023 b
work page 2023
-
[34]
Finetuned language models are zero-shot learners
Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. In International Conference on Learning Representations (ICLR), 2022
work page 2022
-
[35]
Yichen Wu, Hong Wang, Peilin Zhao, Yefeng Zheng, Ying Wei, and Long-Kai Huang. Mitigating catastrophic forgetting in online continual learning by modeling previous task interrelations via pareto optimization. In Forty-first international conference on machine learning, 2024
work page 2024
-
[36]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[37]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[38]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[39]
Y 1ST= dpd @RK u) h5ƦL6e `ȚyR8 p# \ NV ؚ.KV 0َ n l1 ; U J1z ׆PCJ] xb \ Y>
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.