A Greedy PDE Router for Blending Neural Operators and Classical Methods
Pith reviewed 2026-05-18 12:28 UTC · model grok-4.3
The pith
An approximate greedy router blends neural operators and classical PDE solvers to reach target accuracy in fewer iterations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
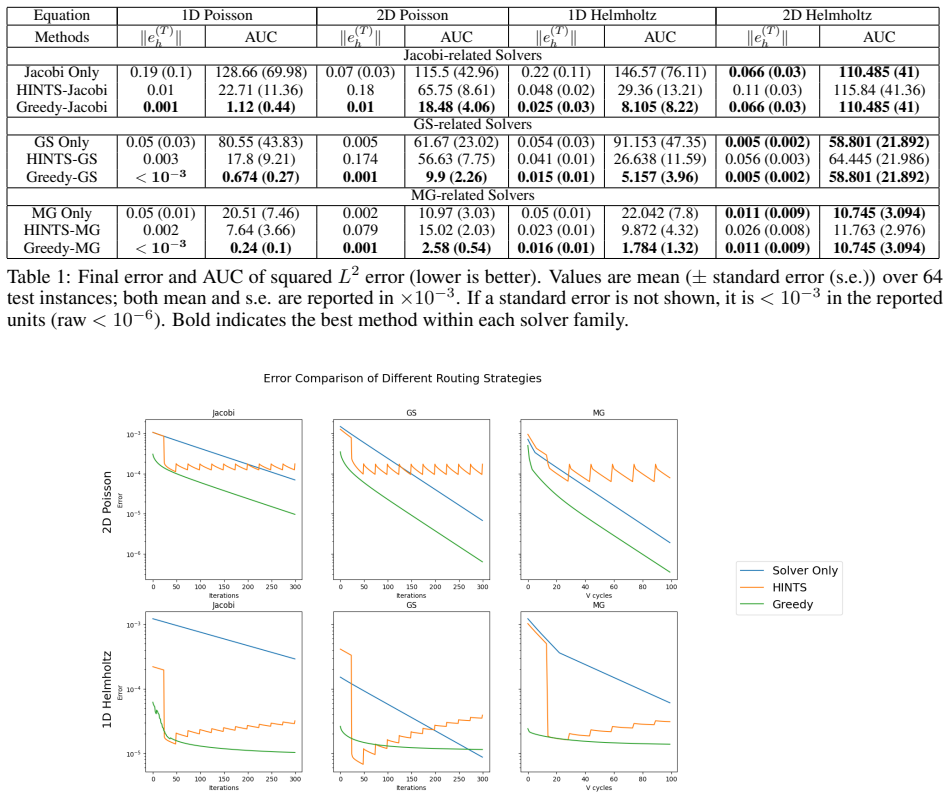
The central claim is that an approximate greedy router can select solvers from a mixed ensemble at each iteration of a PDE solve, producing hybrid trajectories whose final error and area-under-the-curve are lower than those of any single-solver baseline or existing hybrid method such as HINTS. On the Poisson and convection-diffusion equations the routed method reaches comparable error levels in substantially fewer iterations and exhibits more stable error decay.
What carries the argument
Approximate greedy router: a surrogate selection rule that mimics exact greedy choice of the next solver by estimating residual reduction without access to the true error norm.
If this is right
- The hybrid solver reaches lower final errors than single-solver baselines on the tested equations.
- Area under the error trajectory is smaller than for existing hybrid approaches such as HINTS.
- Comparable accuracy is attained after substantially fewer iterations.
- Error reduction remains more stable across iterations than in the compared methods.
Where Pith is reading between the lines
- The same routing logic could be tested on additional families of PDEs to check whether the error reductions persist outside the two equations studied.
- If the router can be trained once and reused on related problems, the cost of learning the approximation would become small relative to the savings in solver iterations.
- Linking the surrogate decision rule to classical a-posteriori error estimators might increase how closely the router matches true greedy behavior.
Load-bearing premise
The practical surrogate used by the router can select solvers nearly as effectively as true greedy selection would if the exact error were known.
What would settle it
On the same Poisson or convection-diffusion test problems, a run in which the routed hybrid shows no reduction in final error or area-under-curve relative to the best single solver would show that the approximation fails to deliver the claimed gains.
Figures

read the original abstract
When solving PDEs, classical numerical solvers are often computationally expensive, while machine learning methods can suffer from spectral bias, failing to capture high-frequency components. Designing an optimal hybrid iterative solver--where, at each iteration, a solver is selected from an ensemble of solvers to leverage their complementary strengths--poses a challenging combinatorial problem. While greedy selection is desirable for its constant-factor approximation guarantee to the optimal solution under Lipschitz assumptions, it requires knowledge of the true error at each step, which is unavailable in practice. We address this by proposing an approximate greedy router that efficiently mimics a greedy approach to solver selection. Empirical results on the Poisson and convection-diffusion equations show that our method consistently reduces final error and area-under-the-curve (AUC) of the error trajectory relative to single-solver baselines and existing hybrid approaches such as HINTS. In particular, our method reaches comparable error levels in substantially fewer iterations while exhibiting more stable error decay.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an approximate greedy router for hybrid iterative PDE solvers that selects at each step from an ensemble of neural operators and classical numerical methods. The router is designed to approximate exact greedy selection (which has a constant-factor guarantee under Lipschitz assumptions on the error) without access to the true residual norm. On the Poisson and convection-diffusion equations, the method is reported to achieve lower final error and lower AUC of the error trajectory than single-solver baselines and the existing hybrid HINTS approach, while reaching target accuracy in fewer iterations with more stable decay.
Significance. If the empirical gains are shown to arise specifically from the routing mechanism rather than the mere presence of the hybrid ensemble, the work would provide a practical and theoretically motivated way to blend neural and classical solvers for PDEs. The constant-factor guarantee for exact greedy under Lipschitz conditions is a clear strength, and reproducible code or machine-checked elements would further strengthen the contribution.
major comments (2)
- [Experiments] Experiments section (results on Poisson and convection-diffusion): the reported error reductions and AUC improvements versus baselines and HINTS are not accompanied by an ablation that replaces the approximate router with random or fixed-order selection on the same ensemble, nor by a quantitative fidelity metric (e.g., selection agreement rate or regret relative to an oracle using true residual norm). This leaves open the possibility that gains derive from the ensemble itself rather than the greedy logic, which is load-bearing for the central claim.
- [Method] Method section (description of the approximate router): the claim that the router sufficiently mimics true greedy selection under the Lipschitz assumptions is not supported by any verification that the Lipschitz condition holds uniformly across neural-operator and classical steps on the reported PDEs, nor by sensitivity analysis when the assumption is relaxed.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief explicit statement of the precise Lipschitz assumption required for the constant-factor guarantee.
- [Figures] Figure captions for error trajectories should include the number of independent runs and error bars to allow assessment of stability claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work proposing an approximate greedy router for hybrid PDE solvers. The comments highlight important aspects for strengthening the empirical and theoretical support of our claims. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section (results on Poisson and convection-diffusion): the reported error reductions and AUC improvements versus baselines and HINTS are not accompanied by an ablation that replaces the approximate router with random or fixed-order selection on the same ensemble, nor by a quantitative fidelity metric (e.g., selection agreement rate or regret relative to an oracle using true residual norm). This leaves open the possibility that gains derive from the ensemble itself rather than the greedy logic, which is load-bearing for the central claim.
Authors: We agree that isolating the contribution of the approximate greedy routing mechanism from the mere availability of a hybrid ensemble is essential to support the central claim. In the revised manuscript we will add ablation experiments that apply random selection and fixed-order cycling over the identical ensemble of neural operators and classical methods. We will also report quantitative fidelity metrics, including the selection agreement rate with an oracle router that has access to the true residual norm and the cumulative regret relative to that oracle. These additions will clarify whether the observed gains in final error, AUC, and iteration count arise specifically from the routing logic. revision: yes
-
Referee: [Method] Method section (description of the approximate router): the claim that the router sufficiently mimics true greedy selection under the Lipschitz assumptions is not supported by any verification that the Lipschitz condition holds uniformly across neural-operator and classical steps on the reported PDEs, nor by sensitivity analysis when the assumption is relaxed.
Authors: The Lipschitz condition is invoked to establish the constant-factor guarantee for exact greedy selection; our approximate router is constructed to emulate this selection without direct residual-norm access. We did not explicitly verify that the condition holds uniformly across the neural-operator and classical steps for the Poisson and convection-diffusion equations, as deriving or estimating the requisite Lipschitz constants for the composite error-reduction operators is analytically non-trivial. In the revision we will expand the method section with a clearer discussion of the assumption and include a sensitivity analysis that perturbs the selection process or tests performance under controlled relaxations of the Lipschitz property to assess robustness of the empirical results. revision: partial
Circularity Check
No circularity: empirical hybrid solver proposal with independent validation
full rationale
The paper presents an algorithmic contribution—an approximate greedy router for selecting among neural-operator and classical PDE solvers at each iteration—supported by direct empirical comparisons on Poisson and convection-diffusion problems. No derivation chain is claimed that reduces a target quantity to a fitted parameter or self-referential definition; the router is explicitly described as an approximation to unavailable true-greedy selection, and performance is measured by observable error metrics against external baselines and HINTS. No load-bearing self-citation, uniqueness theorem imported from the authors’ prior work, or ansatz smuggled via citation appears in the provided abstract or description. The central claims rest on reported reductions in final error and AUC, which are falsifiable against the stated baselines and do not collapse to the method’s own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning to route llms with confidence tokens.arXiv preprint arXiv:2410.13284,
Yu-Neng Chuang, Prathusha Kameswara Sarma, Parikshit Gopalan, John Boccio, Sara Bolouki, Xia Hu, and Helen Zhou. Learning to route llms with confidence tokens.arXiv preprint arXiv:2410.13284,
-
[2]
Yu-Neng Chuang, Leisheng Yu, Guanchu Wang, Lizhe Zhang, Zirui Liu, Xuanting Cai, Yang Sui, Vladimir Braver- man, and Xia Hu. Confident or seek stronger: Exploring uncertainty-based on-device llm routing from benchmark- ing to generalization.arXiv preprint arXiv:2502.04428,
-
[3]
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Ruhle, Laks V
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Ruhle, Laks VS Lakshmanan, and Ahmed Hassan Awadallah. Hybrid llm: Cost-efficient and quality-aware query routing.arXiv preprint arXiv:2404.14618,
-
[4]
Surya Narayanan Hari and Matt Thomson. Tryage: Real-time, intelligent routing of user prompts to large language models.arXiv preprint arXiv:2308.11601,
-
[5]
RouterBench: A Benchmark for Multi-LLM Routing System
Qitian Jason Hu, Jacob Bieker, Xiuyu Li, Nan Jiang, Benjamin Keigwin, Gaurav Ranganath, Kurt Keutzer, and Shriyash Kaustubh Upadhyay. Routerbench: A benchmark for multi-llm routing system.arXiv preprint arXiv:2403.12031,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Zhongzhan Huang, Guoming Ling, Yupei Lin, Yandong Chen, Shanshan Zhong, Hefeng Wu, and Liang Lin. Routereval: A comprehensive benchmark for routing llms to explore model-level scaling up in llms.arXiv preprint arXiv:2503.10657,
-
[7]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Deven- dra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Siavash Khodakarami, Vivek Oommen, Aniruddha Bora, and George Em Karniadakis. Mitigating spectral bias in neural operators via high-frequency scaling for physical systems.arXiv preprint arXiv:2503.13695,
-
[9]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[10]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations.arXiv preprint arXiv:2010.08895, 2020a. Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Andrew Stuart, Kaushik Bhattacharya, and Anima Anandkuma...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[11]
Lizuo Liu and Wei Cai. Multiscale deeponet for nonlinear operators in oscillatory function spaces for building seismic wave responses.arXiv preprint arXiv:2111.04860,
-
[12]
Theory of the Frequency Principle for General Deep Neural Networks
11 Tao Luo, Zheng Ma, Zhi-Qin John Xu, and Yaoyu Zhang. Theory of the frequency principle for general deep neural networks.arXiv preprint arXiv:1906.09235,
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[13]
Routoo: Learning to route to large language models effectively.arXiv preprint arXiv:2401.13979,
Alireza Mohammadshahi, Arshad Rafiq Shaikh, and Majid Yazdani. Routoo: Learning to route to large language models effectively.arXiv preprint arXiv:2401.13979,
-
[14]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Out- rageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Large language model rout- ing with benchmark datasets.arXiv preprint arXiv:2309.15789, 2023
Tal Shnitzer, Anthony Ou, M ´ırian Silva, Kate Soule, Yuekai Sun, Justin Solomon, Neil Thompson, and Mikhail Yurochkin. Large language model routing with benchmark datasets.arXiv preprint arXiv:2309.15789,
-
[16]
A Performance Bound for the Greedy Algorithm in a Generalized Class of String Optimization Problems
Brandon Van Over, Bowen Li, Edwin KP Chong, and Ali Pezeshki. A performance bound for the greedy algorithm in a generalized class of string optimization problems.arXiv preprint arXiv:2409.05020,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Zhi-Qin John Xu, Yaoyu Zhang, Tao Luo, Yanyang Xiao, and Zheng Ma. Frequency principle: Fourier analysis sheds light on deep neural networks.arXiv preprint arXiv:1901.06523,
-
[18]
Zhi-Qin John Xu, Lulu Zhang, and Wei Cai. On understanding and overcoming spectral biases of deep neural network learning methods for solving pdes.arXiv preprint arXiv:2501.09987,
-
[19]
Zhilin You, Zhenli Xu, and Wei Cai. Mscalefno: Multi-scale fourier neural operator learning for oscillatory function spaces.arXiv preprint arXiv:2412.20183,
-
[20]
In a 2-grid method, a few iterations of the smoother (e.x
13 A Background A.1 Multigrid LetA h, A2h represent the coefficient matrix on a fine grid with discretization parameterhand2h,u h andf h represent the PDE solution and constant vector on a grid discretized byh,R 2h h denote the restriction matrix which transfers vectors from a fine grid to a coarse one, andI h 2h is the interpolation matrix transfers vect...
work page 2017
-
[21]
15 In order to prove weakly-α-supermodularity, we must first prove prefix monotonicity
•Property 3:Ifg 1 andg 2 are Lipschitz continuous functions with Lipschitz constants ofρ 1 andρ 2 respec- tively, the Lipschitz constant ofg 1 ◦g 2 isρ 1ρ2. 15 In order to prove weakly-α-supermodularity, we must first prove prefix monotonicity. Prefix monotonicity:LetS⪯S ′ whereS ′ =S⊕N. h(S′) = ◦1 t=|S′| I−C S′ t ◦ La h e(0) h 2 2 = ◦|S|+1 t=|S′| I−C S′ ...
work page 2023
-
[22]
We do this by generating samples in Fourier space: for each non-zero modek, we draw an independent complex coefficient from a Gaussian distribution with mean 0 and variance(4π 2∥k∥2 2 + 9)−2, enforce a Hermitian symmetry to obtain a real-valued field, set the DC mode to0to ensure zero mean for Poisson, and apply inverse Discrete Fourier Transform to obtai...
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.