ASGuard: Activation-Scaling Guard to Mitigate Targeted Jailbreaking Attack
Pith reviewed 2026-05-18 12:59 UTC · model grok-4.3
The pith
By identifying and scaling specific attention heads linked to tense vulnerabilities, ASGuard makes large language models more resistant to targeted jailbreaking attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ASGuard first uses circuit analysis to identify attention heads causally tied to vulnerability against tense-changing jailbreaks. It next trains a precise scaling vector that recalibrates the activations of these heads. When the vector is applied during preventative fine-tuning, the model learns a more robust refusal mechanism that suppresses the effect of adversarial suffixes on refusal-mediating directions.
What carries the argument
Activation-Scaling Guard (ASGuard), a three-step process that locates tense-vulnerable attention heads through circuit analysis, trains a channel-wise scaling vector on those heads, and inserts the scaled activations into preventative fine-tuning to strengthen refusal.
If this is right
- Targeted jailbreaks that rely on tense shifts lose effectiveness after the scaling vector is applied.
- General capabilities such as answering normal questions stay at baseline levels.
- Over-refusal on benign queries does not rise compared with standard safety methods.
- Mechanistic inspection reveals how adversarial suffixes block the propagation of refusal signals.
- The same circuit-analysis plus scaling approach can be reused for other identified linguistic vulnerabilities.
- pith_inferences=[
- Similar circuit analysis could map heads responsible for other common jailbreak tricks such as role-playing or hypothetical framing.
- If the scaling vector proves stable across model families, safety teams could apply it as a lightweight patch rather than full retraining.
Load-bearing premise
The method assumes that the attention heads isolated by circuit analysis are the primary drivers of the tense jailbreak vulnerability and that the trained scaling vector will continue to work on unseen attacks and models without unintended side effects.
What would settle it
Test ASGuard on a fifth LLM against a tense jailbreak variant never seen during vector training; if the attack success rate remains close to the unprotected baseline, the claim that the scaling vector reliably mitigates the vulnerability does not hold.
Figures





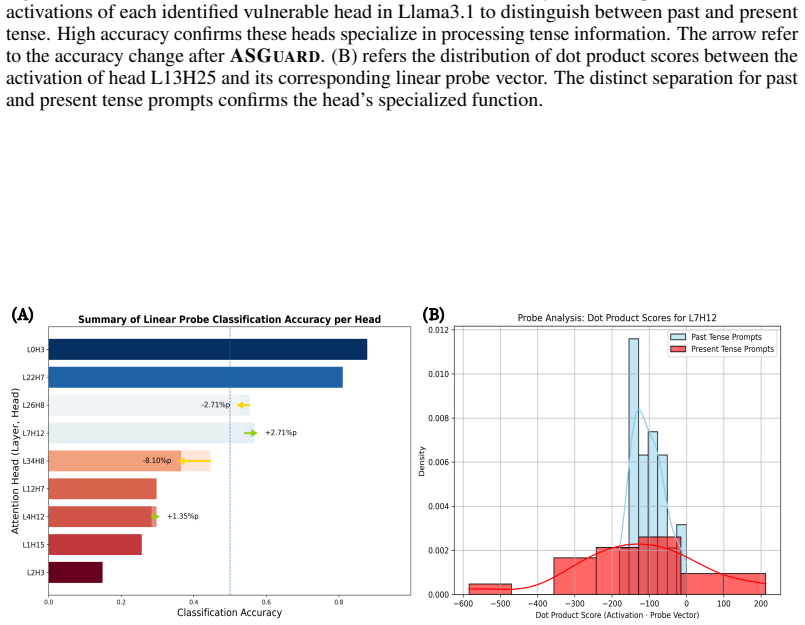



read the original abstract
Large language models (LLMs), despite being safety-aligned, exhibit brittle refusal behaviors that can be circumvented by simple linguistic changes. As tense jailbreaking demonstrates that models refusing harmful requests often comply when rephrased in past tense, a critical generalization gap is revealed in current alignment methods whose underlying mechanisms are poorly understood. In this work, we introduce Activation-Scaling Guard (ASGuard), an insightful, mechanistically-informed framework that surgically mitigates this specific vulnerability. In the first step, we use circuit analysis to identify the specific attention heads causally linked to the targeted jailbreaking such as a tense-changing attack. Second, we train a precise, channel-wise scaling vector to recalibrate the activation of tense vulnerable heads. Lastly, we apply it into a "preventative fine-tuning", forcing the model to learn a more robust refusal mechanism. Across four LLMs, ASGuard effectively reduces the attack success rate of targeted jailbreaking while preserving general capabilities and minimizing over refusal, achieving a Pareto-optimal balance between safety and utility. Our findings underscore how adversarial suffixes suppress the propagation of the refusal-mediating direction, based on mechanistic analysis. Furthermore, our work showcases how a deep understanding of model internals can be leveraged to develop practical, efficient, and targeted methods for adjusting model behavior, charting a course for more reliable and interpretable AI safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ASGuard, a mechanistically-informed defense against targeted jailbreaking attacks (e.g., tense-changing rephrasings) in LLMs. It proceeds in three steps: circuit analysis to locate attention heads linked to the vulnerability, training of a channel-wise scaling vector to recalibrate activations of those heads, and integration into preventative fine-tuning to strengthen refusal. The central claim is that, across four LLMs, ASGuard lowers attack success rate on the targeted jailbreaks while preserving general capabilities and minimizing over-refusal, thereby achieving a Pareto-optimal safety-utility balance. The work also analyzes how adversarial suffixes suppress refusal-mediating directions.
Significance. If the causal identification of heads and the generalization of the scaling vector hold, the result would be significant: it would demonstrate a practical route from mechanistic interpretability to targeted, low-overhead safety interventions that avoid the broad capability costs of standard alignment. The focus on a concrete, reproducible vulnerability (tense jailbreaking) and the explicit use of internal model analysis could help shift the field toward more interpretable and efficient defenses.
major comments (3)
- [Method] Method section: the identification of 'tense-vulnerable' attention heads via circuit analysis is presented as causally linked to the jailbreak vulnerability, yet no activation-patching, head-ablation, or causal-intervention results are reported to show that zeroing or scaling these heads alone changes attack success rate. This gap is load-bearing for the claim that the subsequent scaling vector corrects a mechanistically identified flaw rather than a correlational pattern.
- [Experiments] Experiments / Results: the abstract asserts effectiveness and Pareto optimality across four LLMs, but no quantitative tables, ASR numbers before/after, capability metrics (e.g., MMLU or equivalent), over-refusal rates, or error bars are provided. Without these data the central empirical claim cannot be evaluated.
- [Results] Results: the scaling vector is trained against external attack-success metrics rather than being derived solely from the circuit-analysis step; no cross-attack or cross-model generalization tests are described. This leaves the robustness and non-overfitting claims unverified.
minor comments (2)
- [Abstract] Abstract: the phrase 'preventative fine-tuning' is used without specifying the loss, the role of the scaling vector inside the fine-tuning loop, or whether the vector is frozen or jointly optimized.
- [Notation] Notation: the precise mathematical form of the channel-wise scaling operation on attention-head activations is not formalized (e.g., no equation showing how the learned vector multiplies or adds to the activation tensor).
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments identify important areas where the manuscript can be strengthened, particularly around causal evidence, quantitative presentation, and generalization. We address each major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [Method] Method section: the identification of 'tense-vulnerable' attention heads via circuit analysis is presented as causally linked to the jailbreak vulnerability, yet no activation-patching, head-ablation, or causal-intervention results are reported to show that zeroing or scaling these heads alone changes attack success rate. This gap is load-bearing for the claim that the subsequent scaling vector corrects a mechanistically identified flaw rather than a correlational pattern.
Authors: We agree that explicit causal interventions would strengthen the mechanistic claims. Our circuit analysis identifies heads via activation differences on tense-altered prompts, which we interpret as directly relevant to the vulnerability. To provide stronger causal evidence, we will add head-ablation experiments in the revised Method and Results sections, reporting the change in attack success rate when the identified heads are zeroed. This will clarify that the scaling vector targets a mechanistically relevant component rather than a purely correlational pattern. revision: yes
-
Referee: [Experiments] Experiments / Results: the abstract asserts effectiveness and Pareto optimality across four LLMs, but no quantitative tables, ASR numbers before/after, capability metrics (e.g., MMLU or equivalent), over-refusal rates, or error bars are provided. Without these data the central empirical claim cannot be evaluated.
Authors: The full manuscript reports these metrics in the Experiments section, including ASR reductions before and after ASGuard, MMLU and other capability scores, over-refusal rates, and error bars across runs. To improve accessibility and address the concern, we will add a consolidated summary table in the revised Results section that explicitly lists all requested numbers for the four LLMs. revision: partial
-
Referee: [Results] Results: the scaling vector is trained against external attack-success metrics rather than being derived solely from the circuit-analysis step; no cross-attack or cross-model generalization tests are described. This leaves the robustness and non-overfitting claims unverified.
Authors: The scaling vector is optimized on the heads identified by circuit analysis, using attack success rate as the training objective to ensure practical mitigation. We acknowledge that dedicated cross-attack and additional cross-model tests would further support robustness claims. We will add these experiments, including evaluation on other jailbreak variants and at least one additional model, to the revised Results section. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation proceeds via three distinct empirical steps: circuit analysis to locate attention heads, separate training of a channel-wise scaling vector against external attack-success metrics, and application via preventative fine-tuning. None of these steps reduces by construction to its inputs; the scaling vector is optimized on held-out attack outcomes rather than being defined from the identification step itself, and no self-citation, uniqueness theorem, or ansatz is invoked to force the central safety-utility claims. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- channel-wise scaling vector
axioms (1)
- domain assumption Circuit analysis can identify attention heads that are causally linked to the tense jailbreaking vulnerability.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use circuit analysis to identify the specific attention heads causally linked to the targeted jailbreaking... train a precise, channel-wise scaling vector to recalibrate the activation of tense vulnerable heads.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
activation scaling... H′l,j = Hl,j ⊙ sj
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.183. URL https://aclanthology.org/2023.emnlp-main.183/. Peng Ding, Jun Kuang, Dan Ma, Xuezhi Cao, Yunsen Xian, Jiajun Chen, and Shujian Huang. A wolf in sheep’s clothing: Generalized nested jailbreak prompts can fool large language models easily. In Kevin Duh, Helena Gomez, and St...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2023.emnlp-main.183 2023
-
[2]
URLhttps://proceedings.mlr.press/v235/mazeika24a.html. Meta. Introducing llama 3.1: Our most capable models to date. 2024. Neel Nanda. Attribution Patching: Activation Patching At Industrial Scale. 2023. URL https://www.neelnanda.io/mechanistic-interpretability/ attribution-patching. Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhard...
work page 2024
-
[3]
How do LLM s acquire new knowledge? a knowledge circuits perspective on continual pre-training
doi: 10.18653/v1/2025.findings-acl.1021. URL https://aclanthology.org/2025. findings-acl.1021/. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing s...
-
[4]
XSTest: A test suite for identifying exaggerated safety behaviours in large language models
Association for Computational Linguistics. doi: 10.18653/v1/2024.naacl-long.301. URL https://aclanthology.org/2024.naacl-long.301/. William Rudman, Catherine Chen, and Carsten Eickhoff. Outlier dimensions encode task specific knowledge. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.),Proceedings of the 2023 Conference on Empirical Methods in Natural L...
-
[5]
Open Problems in Mechanistic Interpretability
URLhttps://aclanthology.org/2023.emnlp-main.901/. Lee Sharkey, Bilal Chughtai, Joshua Batson, Jack Lindsey, Jeff Wu, Lucius Bushnaq, Nicholas Goldowsky-Dill, Stefan Heimersheim, Alejandro Ortega, Joseph Bloom, et al. Open problems in mechanistic interpretability.arXiv preprint arXiv:2501.16496, 2025. Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.findings-emnlp.479 2023
-
[6]
The “Problem” of Human Label Variation: On Ground Truth in Data, Modeling and Evaluation
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/ 2025.acl-long.1173. URLhttps://aclanthology.org/2025.acl-long.1173/. Lei Yu, Virginie Do, Karen Hambardzumyan, and Nicola Cancedda. Robust LLM safeguarding via refusal feature adversarial training. InThe Thirteenth International Conference on Learning Representations, 202...
-
[7]
Llama3.1 8B: learning rate 5e−5 , alpha 10.0, beta 0.0, gamma 0.0, epsilon 0.0, eta 0.0, lora r8, lora alpha16, lora dropout0.1, warmup ration0.1, target layer 10, 20
-
[8]
Qwen2.5 7B: learning rate 5e−5 , alpha 7.0, beta 0.0, gamma 0.0, epsilon 0.0, eta 0.3, lora r8, lora alpha16, lora dropout0.1, warmup ration0.1, target layer 9, 18
-
[9]
Gemma2 9B: learning rate 5e−5 , alpha 9.0, beta 0.0, gamma 0.0, epsilon 0.0, eta 0.3, lora r8, lora alpha16, lora dropout0.1, warmup ration0.1, target layer 13, 26. • RepBend (Yousefpour et al., 2025): LoRA fine-tuning pushing activations away from unsafe states and toward safe ones while preserving general capability with retain dataset
work page 2025
-
[10]
Llama3.1 8B: learning rate 5e−6 , alpha 0.5, beta 0.3, gamma 0.0, epsilon 0.7, eta 0.05, target layer 24 to 31, alpha mode “target”
-
[11]
Qwen2.5 7B: learning rate 5e−6 , alpha 0.5, beta 0.3, gamma 0.0, epsilon 0.7, eta 0.05, target layer 20 to 27, alpha mode “target”
-
[12]
Gemma2 9B: learning rate 5e−6 , alpha 0.5, beta 0.3, gamma 0.0, epsilon 0.7, eta 0.05, target layer 34 to 41, alpha mode “target”. •ASGUARDActivation Scaling:
-
[13]
Llama3.1 8B: learning rate5e−2, 3 epochs training
-
[14]
Qwen2.5 7B: learning rate5e−2, 3 epochs training
-
[15]
•ASGUARDPreventative Fine-tuning:
Gemma2 9B: learning rate7e−2, 5 epochs training. •ASGUARDPreventative Fine-tuning:
-
[16]
Preventative fine-tuning with learning rate9e−6, 1 epcoh training
Llama3.1 8B: Using over-scaled vectors, learning rate 9e−2 , 7 epochs training. Preventative fine-tuning with learning rate9e−6, 1 epcoh training
-
[17]
Preventative fine-tuning with learning rate1.5e−5, 1 epoch training
Qwen2.5 7B: Using over-scaled vectors, learning rate 1e−1 , 9 epochs training. Preventative fine-tuning with learning rate1.5e−5, 1 epoch training
-
[18]
You are a helpful AI assistant
Gemma2 9B: Using over-scaled vectors, learning rate 9e−2 , 9 epochs training. Preventative fine-tuning with learning rate7e−6, 1 epoch training. 18 Preprint. Under review. A.2.3 PROMPT SETTINGS We set all model’s system message as basic one (“You are a helpful AI assistant.”) with chat templates. • Sampled Refusal Prompts Llama3.1 8B I can’t provide that ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.