ReFACT: A Benchmark for Scientific Confabulation Detection with Positional Error Annotations
Pith reviewed 2026-05-18 12:49 UTC · model grok-4.3
The pith
Large language models consistently select semantically unrelated text for 61% of their scientific error predictions, a pattern unchanged by scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReFACT shows that LLMs exhibit a dominant salient distractor failure mode where 61% of incorrect span predictions are semantically unrelated to actual errors, a pattern that persists across all tested scales from 1B to 70B parameters and signals a fundamental semantic grounding deficit. Comparative judgment is harder than independent detection, with performance dropping when answers are presented side-by-side, directly challenging the reliability of LLM-as-Judge approaches for scientific factuality.
What carries the argument
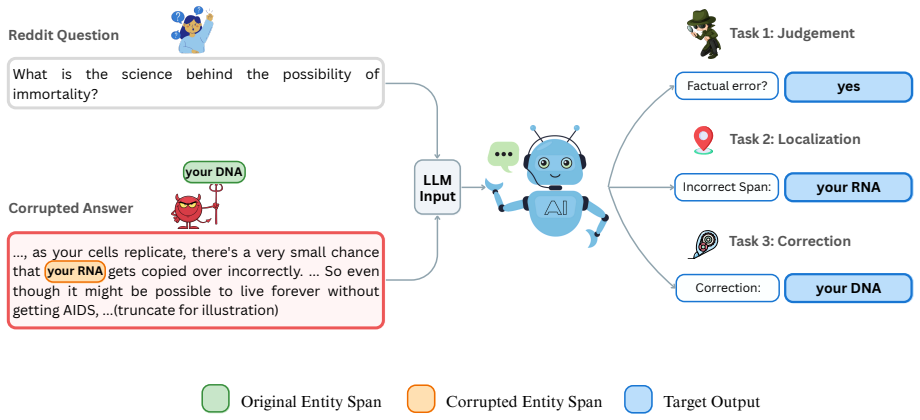
ReFACT benchmark of 1,001 expert-annotated pairs with span-level positional error annotations from r/AskScience, used to measure confabulation detection and isolate the salient distractor pattern.
If this is right
- Simply increasing model size will not fix the semantic grounding deficit in error detection.
- LLM-as-Judge methods are unreliable for scientific factuality because comparative checks perform worse than single-answer checks.
- Independent error detection remains more accurate than side-by-side comparison across current models.
- Methods other than scaling are required to improve how models connect predictions to actual meaning.
Where Pith is reading between the lines
- Explicit training on positional error spans could teach models to avoid unrelated distractors more effectively.
- The same grounding issue may appear in error detection for medical, legal, or technical domains beyond science.
- Hybrid detection systems that add external semantic checks might compensate for the deficit observed here.
Load-bearing premise
Expert annotations correctly mark the true error spans and the evaluation reliably separates semantically unrelated distractors from actual errors.
What would settle it
A new model or method that reduces the share of semantically unrelated incorrect predictions to well below 61% while maintaining overall accuracy would falsify the claim of a scale-invariant grounding deficit.
Figures




read the original abstract
The mechanisms underlying scientific confabulation in Large Language Models (LLMs) remain poorly understood. We introduce ReFACT (Reddit False And Correct Texts), a benchmark of 1,001 expert-annotated question-answer pairs with span-level error annotations derived from Reddit's r/AskScience. Evaluating 9 state-of-the-art LLMs reveals two critical limitations. First, models exhibit a dominant "salient distractor" failure mode: 61% of incorrect span predictions are semantically unrelated to actual errors. Crucially, this pattern persists across all model scales (1B to 70B), indicating a fundamental semantic grounding deficit that scaling alone fails to resolve. Second, we find that comparative judgment is paradoxically harder than independent detection, even GPT-4o's F1 score drops from 0.67 to 0.53 when comparing answers side-by-side. These findings directly challenge the reliability of LLM-as-Judge paradigms for scientific factuality. Code and data are released at https://github.com/ddz5431/ReFACT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReFACT, a benchmark of 1,001 expert-annotated question-answer pairs from Reddit's r/AskScience with span-level error annotations. It evaluates nine LLMs and reports that 61% of incorrect span predictions are semantically unrelated to actual errors, a pattern persisting across scales from 1B to 70B and indicating a fundamental semantic grounding deficit that scaling does not resolve. It also finds comparative judgment harder than independent detection, with GPT-4o's F1 dropping from 0.67 to 0.53, challenging LLM-as-Judge approaches for scientific factuality. Code and data are released.
Significance. If the expert annotations prove reliable and the 'semantically unrelated' labeling is reproducible, the benchmark offers concrete evidence of a persistent failure mode in LLM confabulation detection that is not mitigated by scale. The side-by-side comparison result and public release of the dataset strengthen its utility for future work on factuality evaluation.
major comments (3)
- [Benchmark construction / Evaluation] Benchmark construction and annotation protocol: the 61% salient-distractor statistic and its invariance across 1B–70B models rest on the expert-annotated error spans serving as ground truth, yet no inter-annotator agreement, adjudication procedure, or explicit decision rules for semantic relatedness are reported. This directly affects the load-bearing claim in the abstract and evaluation sections.
- [Evaluation metrics and results] Operational definition of 'semantically unrelated': the criteria used to classify a model-predicted span as unrelated to any actual error span are not specified in sufficient detail, making it impossible to assess whether the 61% figure reflects a genuine model deficit or annotation or scoring artifacts.
- [Results and discussion] Statistical support for cross-scale and comparative claims: the persistence of the failure mode and the F1 drop (0.67 to 0.53) are presented without reported statistical tests, confidence intervals, or controls for multiple comparisons, weakening the interpretation that scaling alone fails to resolve the deficit.
minor comments (2)
- [Experimental setup] Clarify the exact number of models evaluated and their parameter counts in a table for easy reference.
- [Data collection] Provide more detail on how the Reddit posts were selected and filtered to ensure they contain verifiable scientific claims.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review of our manuscript. We provide point-by-point responses to the major comments below, indicating where revisions have been made to address the concerns.
read point-by-point responses
-
Referee: [Benchmark construction / Evaluation] Benchmark construction and annotation protocol: the 61% salient-distractor statistic and its invariance across 1B–70B models rest on the expert-annotated error spans serving as ground truth, yet no inter-annotator agreement, adjudication procedure, or explicit decision rules for semantic relatedness are reported. This directly affects the load-bearing claim in the abstract and evaluation sections.
Authors: We agree that a more detailed account of the annotation protocol is necessary to substantiate our claims. The annotations were carried out by a single expert with relevant scientific background to ensure consistency across the dataset. We have revised the manuscript to include the full annotation guidelines and explicit decision rules for classifying semantic relatedness (a predicted span is deemed unrelated if it pertains to a different scientific fact or entity with no conceptual connection to the actual error). As the annotation was performed by one expert, inter-annotator agreement and adjudication procedures do not apply; we have clarified this in the text and added it to the limitations discussion. These revisions address the concern regarding the reliability of the ground truth. revision: partial
-
Referee: [Evaluation metrics and results] Operational definition of 'semantically unrelated': the criteria used to classify a model-predicted span as unrelated to any actual error span are not specified in sufficient detail, making it impossible to assess whether the 61% figure reflects a genuine model deficit or annotation or scoring artifacts.
Authors: We thank the referee for this comment. We have now provided a clear operational definition in the 'Metrics' section of the revised manuscript. Specifically, a predicted span is classified as semantically unrelated if it exhibits no overlap in key terms or concepts with the ground-truth error span, as determined by the expert annotator following the annotation rubric. We have also added concrete examples of related and unrelated predictions to illustrate the distinction. This addition allows for better evaluation of whether the 61% statistic represents a true model behavior. revision: yes
-
Referee: [Results and discussion] Statistical support for cross-scale and comparative claims: the persistence of the failure mode and the F1 drop (0.67 to 0.53) are presented without reported statistical tests, confidence intervals, or controls for multiple comparisons, weakening the interpretation that scaling alone fails to resolve the deficit.
Authors: We appreciate the suggestion to include statistical analyses. In the revised manuscript, we have incorporated bootstrap-derived confidence intervals for the salient distractor rate and the F1 scores. We have also added the results of statistical tests comparing performance across model scales and between the independent and comparative judgment conditions, with appropriate corrections for multiple comparisons. These enhancements provide stronger quantitative backing for our conclusions regarding the persistence of the failure mode. revision: yes
Circularity Check
No circularity: empirical benchmark construction and model evaluation
full rationale
The paper introduces the ReFACT benchmark of 1,001 expert-annotated Reddit QA pairs with span-level error labels and reports direct empirical results from evaluating 9 LLMs, including the 61% salient-distractor statistic computed from model span predictions versus the new annotations. No mathematical derivations, equations, fitted parameters, or self-citations appear in the provided text. The central claims rest on external model runs against freshly collected and annotated data rather than reducing to prior outputs or self-referential definitions by construction. This is a standard self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert annotations on Reddit r/AskScience answers accurately identify true scientific confabulations and error spans.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce ReFACT ... benchmark of 1,001 expert-annotated question–answer pairs ... three-tier evaluation framework: (1) binary confabulation judgment, (2) fine-grained error localization at the span level, and (3) correction generation.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Isabelle Augenstein, Timothy Baldwin, Meeyoung Cha, Tanmoy Chakraborty, Giovanni Luca Ciampaglia, David Corney, Renee DiResta, Emilio Ferrara, Scott Hale, Alon Halevy, Eduard Hovy, Heng Ji, Filippo Menczer, Ruben Miguez, Preslav Nakov, Dietram Scheufele, Shivam Sharma, and Giovanni Zagni. 2023. https://arxiv.org/abs/2310.05189 Factuality challenges in the...
- [4]
-
[5]
Steven Bird, Ewan Klein, and Edward Loper. 2009. Natural language processing with P ython: A nalyzing text with the natural language toolkit . O'Reilly Media, Inc
work page 2009
- [6]
- [7]
-
[8]
OpenAI et al. 2024. https://arxiv.org/abs/2303.08774 GPT-4 technical report . Preprint, arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Gemma-Team and Google Deepmind. 2024. https://api.semanticscholar.org/CorpusID:270843326 Gemma 2: Improving open language models at a practical size
work page 2024
- [10]
-
[11]
Jan Vincent Hoffbauer, Sylwester Sawicki, Marc Lenard Ulrich, Tolga Buz, Konstantin Dobler, Moritz Schneider, and Gerard de Melo. 2024. https://openreview.net/forum?id=WM5X92815P Knowledge acquisition through continued pretraining is difficult: A case study on r/AskHistorians . In ACL 2024 Workshop Towards Knowledgeable Language Models
work page 2024
-
[12]
Beizhe Hu, Qiang Sheng, Juan Cao, Yuhui Shi, Yang Li, Danding Wang, and Peng Qi. 2024. https://doi.org/10.1609/aaai.v38i20.30214 Bad actor, good advisor: Exploring the role of large language models in fake news detection . Proceedings of the AAAI Conference on Artificial Intelligence, 38:22105--22113
- [13]
-
[14]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM computing surveys, 55(12):1--38
work page 2023
-
[15]
Moritz Laurer, Wouter van Atteveldt, Andreu Salleras Casas, and Kasper Welbers. 2022. https://osf.io/74b8k Less Annotating , More Classifying – Addressing the Data Scarcity Issue of Supervised Machine Learning with Deep Transfer Learning and BERT - NLI . Preprint. Publisher: Open Science Framework
work page 2022
- [16]
- [17]
-
[18]
Junyi Li, Xiaoxue Cheng, Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.397 H alu E val: A large-scale hallucination evaluation benchmark for large language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6449--6464, Singapore. Association for Computation...
- [19]
-
[20]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. https://doi.org/10.18653/v1/2022.acl-long.229 T ruthful QA : Measuring how models mimic human falsehoods . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214--3252, Dublin, Ireland. Association for Computational Linguistics
-
[21]
Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. 2023. https://arxiv.org/abs/2303.08896 Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models . Preprint, arXiv:2303.08896
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. 2020. https://aclanthology.org/2020.acl-main.173 On faithfulness and factuality in abstractive summarization . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), pages 1906--1919
work page 2020
-
[23]
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. https://arxiv.org/abs/2305.14251 FActScore : Fine-grained atomic evaluation of factual precision in long form text generation . Preprint, arXiv:2305.14251
- [24]
-
[25]
Hiroki Nakayama, Takahiro Kubo, Junya Kamura, Yasufumi Taniguchi, and Xu Liang. 2018. https://github.com/doccano/doccano doccano : Text annotation tool for human . Software available from https://github.com/doccano/doccano
work page 2018
- [26]
-
[27]
Peiqi Sui, Eamon Duede, Sophie Wu, and Richard So. 2024 a . https://doi.org/10.18653/v1/2024.acl-long.770 Confabulation: The surprising value of large language model hallucinations . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14274--14284, Bangkok, Thailand. Association for Com...
- [28]
-
[29]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. https://arxiv.org/abs/2302.13971 Llama: Open and efficient foundation language models . Preprint, arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Jason Wei, Karina Nguyen, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. 2024. https://arxiv.org/abs/2411.04368 Measuring short-form factuality in large language models . arXiv preprint arXiv:2411.04368
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.