On the energy efficiency of sparse matrix computations on multi-GPU clusters
Pith reviewed 2026-05-18 10:20 UTC · model grok-4.3
The pith
Optimizing GPU computations and minimizing data movement across nodes reduces both runtime and energy use for large sparse linear systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
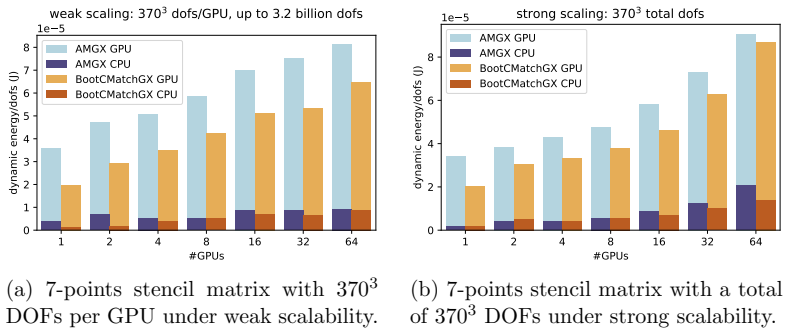
The library achieves energy-efficient execution of sparse linear system solves on multi-GPU platforms by exposing high parallelism in the algorithms and by optimizing implementations to limit data movement across memory hierarchies and compute nodes. Runtime energy profiles of the core components confirm that these choices lower both time-to-solution and energy consumption relative to less optimized approaches, while delivering measurable improvements over comparable frameworks on standard benchmarks.
What carries the argument
Methods that expose high parallelism in sparse matrix operations while optimizing data movement for efficient multi-GPU execution, paired with runtime tools for accurate energy measurement of those components.
Load-bearing premise
The energy measurement tools record true consumption without meaningful overhead or bias, and the chosen benchmarks reflect typical large-scale sparse linear system workloads.
What would settle it
Direct comparison of measured energy draw and runtime on the same multi-GPU cluster using a different sparse solver library that does not apply the same data-movement reductions, on the same set of benchmark matrices.
Figures















read the original abstract
We investigate the energy efficiency of a library designed for parallel computations with sparse matrices. The library leverages high-performance, energy-efficient Graphics Processing Unit (GPU) accelerators to enable large-scale scientific applications. Our primary development objective was to maximize parallel performance and scalability in solving sparse linear systems whose dimensions far exceed the memory capacity of a single node. To this end, we devised methods that expose a high degree of parallelism while optimizing algorithmic implementations for efficient multi-GPU usage. Previous work has already demonstrated the library's performance efficiency on large-scale systems comprising thousands of NVIDIA GPUs, achieving improvements over state-of-the-art solutions. In this paper, we extend those results by providing energy profiles that address the growing sustainability requirements of modern HPC platforms. We present our methodology and tools for accurate runtime energy measurements of the library's core components and discuss the findings. Our results confirm that optimizing GPU computations and minimizing data movement across memory and computing nodes reduces both time-to-solution and energy consumption. Moreover, we show that the library delivers substantial advantages over comparable software frameworks on standard benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates the energy efficiency of a library for parallel sparse matrix computations on multi-GPU clusters. It describes algorithmic optimizations to expose high parallelism and minimize data movement for solving large sparse linear systems exceeding single-node memory capacity. Building on prior performance results, the authors present a methodology and tools for runtime energy measurements of core components, reporting that these optimizations reduce both time-to-solution and energy consumption while delivering advantages over comparable frameworks on standard benchmarks.
Significance. If the energy reductions are substantiated by unbiased and calibrated measurements that properly isolate GPU and system-level consumption, the work would provide valuable empirical evidence for energy-aware design in large-scale HPC sparse linear algebra, addressing sustainability concerns in multi-thousand GPU deployments.
major comments (1)
- [Methodology for energy measurements] The central claim that optimizations reduce energy consumption rests on runtime energy profiles, yet the description of the measurement methodology (referenced in the abstract as addressing 'accurate runtime energy measurements of the library's core components') provides no details on calibration against external meters, quantification of monitoring overhead, or accounting for non-GPU power draw from host CPUs, interconnects, and memory in the multi-node cluster. This omission is load-bearing, as unaccounted bias or incomplete isolation could artifactually inflate reported savings.
minor comments (1)
- [Abstract] The abstract refers to 'standard benchmarks' without naming them or providing quantitative results, error bars, or exclusion criteria; this should be expanded in the main text for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for identifying an area where the manuscript can be strengthened. We address the major comment below and will revise the paper to provide greater transparency on the energy measurement approach.
read point-by-point responses
-
Referee: The central claim that optimizations reduce energy consumption rests on runtime energy profiles, yet the description of the measurement methodology (referenced in the abstract as addressing 'accurate runtime energy measurements of the library's core components') provides no details on calibration against external meters, quantification of monitoring overhead, or accounting for non-GPU power draw from host CPUs, interconnects, and memory in the multi-node cluster. This omission is load-bearing, as unaccounted bias or incomplete isolation could artifactually inflate reported savings.
Authors: We agree that a more detailed exposition of the measurement methodology is warranted to support the energy-efficiency claims. The current manuscript outlines the tools employed for runtime profiling of the library components but does not fully elaborate on calibration procedures, overhead assessment, or separation of GPU versus host-system power. In the revised version we will expand the relevant section to include: explicit description of any calibration steps performed against external meters; quantitative assessment of monitoring overhead obtained through dedicated experiments; and clarification of how non-GPU contributions (host CPUs, interconnects, memory) were either measured separately or accounted for in the reported figures. These additions will allow readers to evaluate potential biases and will strengthen the empirical basis for the reported energy reductions. revision: yes
Circularity Check
No significant circularity: empirical measurements of energy and performance
full rationale
The paper presents a methodology for runtime energy measurements on multi-GPU sparse matrix computations and reports benchmark results showing reduced time-to-solution and energy via optimizations and minimized data movement. No derivation chain, first-principles predictions, or fitted parameters are claimed; results rest on direct experimental profiling and comparisons to other frameworks. Prior work is cited only for established performance baselines, not as a load-bearing uniqueness theorem or self-referential definition for the energy claims. The analysis is self-contained against external benchmarks and does not reduce any output to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Runtime energy measurement tools provide accurate consumption data for the library's core components without introducing significant overhead.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present our methodology and tools for accurate runtime energy measurements of the library's core components... optimizing GPU computations and minimizing data movement across memory and computing nodes reduces both time-to-solution and energy consumption.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BootCMatchGX... Algebraic MultiGrid (AMG) preconditioners... communication-reduction strategies
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Electricity 2025. Analysis and forecast to 2027
“Electricity 2025. Analysis and forecast to 2027.”https://www.iea. org/reports/electricity-2025
work page 2025
-
[2]
Energy-aware operation of HPC systems in Germany,
E. Suarez, H. Bockelmann, N. Eicker, J. Eitzinger, S. El Sayed, T. Fieseler, M. Frank, P. Frech, P. Giesselmann, D. Hackenberg, G. Hager, A. Herten, T. Ilsche, B. Koller, E. Laure, C. Manzano, S. Oeste, M. Ott, K. Reuter, R. Schneider, K. Thust, and B. von St. Vi- eth, “Energy-aware operation of HPC systems in Germany,”Frontiers in High Performance Comput...
work page 2025
- [3]
-
[4]
Understanding GPU power: A survey of profiling, modeling, and simulation methods,
R. A. Bridges, N. Imam, and T. M. Mintz, “Understanding GPU power: A survey of profiling, modeling, and simulation methods,”ACM Com- puting Surveys (CSUR), vol. 49, no. 3, pp. 1–27, 2016
work page 2016
-
[5]
On the performance and energy efficiency of sparse linear algebra on GPUs,
H. Anzt, S. Tomov, and J. Dongarra, “On the performance and energy efficiency of sparse linear algebra on GPUs,”The International Journal of High Performance Computing Applications, vol. 31, no. 5, pp. 375– 390, 2017
work page 2017
-
[6]
“Top500.”https://top500.org/lists/top500/2024/11/[Accessed: (13 May 2025)]. 25 1 2 4 8 16 32 64 #GPUs 170 175 180 185 190 195GPU power peak (W) weak scaling: 3703 dofs/GPU, up to 3.2 billion dofs AMGX BootCMatchGX (a) 7-points stencil matrix with 370 3 DOFs per GPU under weak scalability. 1 2 4 8 16 32 64 #GPUs 100 120 140 160 180GPU power peak (W) strong...
work page 2024
-
[7]
G. Agostaet al., “Towards EXtreme scale Technologies and Accelerators for euROhpc hw/Sw Supercomputing Applications for exascale: The TEXTAROSSA approach,”Microprocessors and Microsystems, vol. 95, p. 104679, 2022
work page 2022
-
[8]
The TEXTAROSSA project: Cool all the way down to the hardware,
A. Filgueraset al., “The TEXTAROSSA project: Cool all the way down to the hardware,” in2024 27th Euromicro Conference on Digital System Design (DSD), pp. 526–533, IEEE, 2024
work page 2024
-
[9]
Alya toward exascale: algorithmic scalability using PSCToolkit,
H. Owen, O. Lehmkuhl, P. D’Ambra, F. Durastante, and S. Filippone, “Alya toward exascale: algorithmic scalability using PSCToolkit,”The Journal of Supercomputing, vol. 80, pp. 13533–13556, 2024
work page 2024
-
[10]
PETScML: Second-order solvers for training regression problems in scientific ma- chine learning,
S. Zampini, U. Zerbinati, G. Turkyyiah, and D. Keyes, “PETScML: Second-order solvers for training regression problems in scientific ma- chine learning,” inProceedings of the Platform for Advanced Scientific Computing Conference, PASC ’24, (New York, NY, USA), Association for Computing Machinery, 2024
work page 2024
-
[11]
Quantifying the energy cost of data movement in scientific applications,
G. Kestor, R. Gioiosa, D. J. Kerbyson, and A. Hoisie, “Quantifying the energy cost of data movement in scientific applications,” in2013 IEEE International Symposium on Workload Characterization (IISWC), pp. 56–65, 2013
work page 2013
-
[12]
The evolution of mathematical software,
J. Dongarra, “The evolution of mathematical software,”Commun. ACM, vol. 65, p. 66–72, nov 2022. 26
work page 2022
-
[13]
Analyzing GPU energy consump- tion in data movement and storage,
P. Delestrac, J. Miquel, D. Bhattacharjee, D. Moolchandani, F. Catthoor, L. Torres, and D. Novo, “Analyzing GPU energy consump- tion in data movement and storage,” in2024 IEEE 35th International Conference on Application-specific Systems, Architectures and Proces- sors (ASAP), pp. 143–151, 2024
work page 2024
-
[14]
Selecting optimal SpMV realizations for GPUs via machine learning,
E. Dufrechou, P. Ezzatti, and E. S. Quintana-Ort´ ı, “Selecting optimal SpMV realizations for GPUs via machine learning,”The International Journal of High Performance Computing Applications, vol. 35, no. 3, pp. 254–267, 2021
work page 2021
-
[15]
H. Anzt, M. Castillo, J. C. Fern´ andez, J. Dongarra, and S. Tomov, “Optimization of power consumption in the iterative solution of sparse linear systems on graphics processors,”Computer Science - Research and Development, vol. 27, no. 4, pp. 299–307, 2012
work page 2012
-
[16]
P. Luszczek, A. Abdelfattah, H. Anzt, A. Suzuki, and S. Tomov, “Batched sparse and mixed-precision linear algebra interface for effi- cient use of GPU hardware accelerators in scientific applications,”Fu- ture Generation Computer Systems, vol. 160, pp. 359–374, 2024
work page 2024
-
[17]
K. ´Swirydowicz, J. Firoz, J. Manzano, M. Halappanavar, S. Thomas, and K. Barker, “A performance and energy study of GPU-resident pre- conditioners for conjugate gradient solvers: In the context of existing and novel approaches,” in2024 IEEE 36th International Symposium on Computer Architecture and High Performance Computing (SBAC- PAD), pp. 70–80, 2024
work page 2024
-
[18]
BootCMatch: A soft- ware package for bootstrap AMG based on graph weighted matching,
P. D’Ambra, S. Filippone, and P. S. Vassilevski, “BootCMatch: A soft- ware package for bootstrap AMG based on graph weighted matching,” ACM Trans. Math. Softw., vol. 44, June 2018
work page 2018
-
[19]
AMG based on compatible weighted matching for GPUs,
M. Bernaschi, P. D’Ambra, and D. Pasquini, “AMG based on compatible weighted matching for GPUs,”Parallel Computing, vol. 92, p. 102599, 2020
work page 2020
-
[20]
BootCMatchG: An adap- tive algebraic multigrid linear solver for GPUs,
M. Bernaschi, P. D’Ambra, and D. Pasquini, “BootCMatchG: An adap- tive algebraic multigrid linear solver for GPUs,”Software Impacts, vol. 6, p. 100041, 2020
work page 2020
-
[21]
A multi-GPU aggregation-based AMG preconditioner for iterative linear solvers,
M. Bernaschi, A. Celestini, F. Vella, and P. D’Ambra, “A multi-GPU aggregation-based AMG preconditioner for iterative linear solvers,” IEEE Transactions on Parallel&Distributed Systems, vol. 34, pp. 2365– 2376, aug 2023. 27
work page 2023
-
[22]
Communication-reduced conjugate gradient variants for GPU-accelerated clusters,
M. Bernaschi, M. G. Carrozzo, A. Celestini, G. Piperno, and P. D’Ambra, “Communication-reduced conjugate gradient variants for GPU-accelerated clusters,” in2025 33rd Euromicro International Con- ference on Parallel, Distributed, and Network-Based Processing (PDP), pp. 178–186, 2025
work page 2025
-
[23]
Methods of conjugate gradients for solving linear systems,
M. Hestenes and E. Stiefel, “Methods of conjugate gradients for solving linear systems,”Journal of Research of the National Bureau of Stan- dards, vol. 49, pp. 409–436, 1952
work page 1952
-
[24]
A massively parallel solver for discrete Poisson-like problems,
Y. Notay and A. Napov, “A massively parallel solver for discrete Poisson-like problems,”Journal of Computational Physics, vol. 281, pp. 237–250, 2015
work page 2015
-
[25]
A. Chronopoulos and C. Gear, “On the efficient implementation of pre- conditioned s-step conjugate gradient methods on multiprocessors with memory hierarchy,”Parallel Computing, vol. 11, no. 1, pp. 37–53, 1989
work page 1989
-
[26]
AmgX: A library for GPU accelerated algebraic multi- grid and preconditioned iterative methods,
M. Naumov, M. Arsaev, P. Castonguay, J. Cohen, J. Demouth, J. Eaton, S. Layton, N. Markovskiy, I. Reguly, N. Sakharnykh, V. Sellappan, and R. Strzodka, “AmgX: A library for GPU accelerated algebraic multi- grid and preconditioned iterative methods,”SIAM Journal on Scientific Computing, vol. 37, no. 5, pp. S602–S626, 2015
work page 2015
-
[27]
RAPL in action: Experiences in using RAPL for power measurements,
K. N. Khan, M. Hirki, T. Niemi, J. K. Nurminen, and Z. Ou, “RAPL in action: Experiences in using RAPL for power measurements,”ACM Transactions on Modeling and Performance Evaluation of Computing Systems (TOMPECS), vol. 3, no. 2, pp. 1–26, 2018
work page 2018
-
[28]
Likwid: A lightweight performance-oriented tool suite for x86 multicore environments,
J. Treibig, G. Hager, and G. Wellein, “Likwid: A lightweight performance-oriented tool suite for x86 multicore environments,” in2010 39th international conference on parallel processing workshops, pp. 207– 216, IEEE, 2010
work page 2010
-
[29]
“Likwid.”https://github.com/RRZE-HPC/likwid[Accessed: (31 March 2025)]
work page 2025
-
[30]
NVIDIA management library: NVML API reference guide
“NVIDIA management library: NVML API reference guide.” https://docs.nvidia.com/deploy/nvml-api/nvml-api-reference. html#nvml-api-reference[Accessed: (31 March 2025)]
work page 2025
- [31]
- [32]
-
[33]
Energy-efficient parallel com- puting: Challenges to scaling,
A. Lastovetsky and R. R. Manumachu, “Energy-efficient parallel com- puting: Challenges to scaling,”Information, vol. 14, no. 4, p. 248, 2023
work page 2023
-
[34]
L. Tan, S. Kothapalli, L. Chen, O. Hussaini, R. Bissiri, and Z. Chen, “A survey of power and energy efficient techniques for high performance numerical linear algebra operations,”Parallel Computing, vol. 40, no. 10, pp. 559–573, 2014
work page 2014
-
[35]
“Ginkgo.”https://ginkgo-project.github.io
-
[36]
Ginkgo: A modern linear operator algebra framework for high performance computing,
H. Anzt, T. Cojean, G. Flegar, F. G¨ obel, T. Gr¨ utzmacher, P. Nayak, T. Ribizel, Y. M. Tsai, and E. S. Quintana-Ort´ ı, “Ginkgo: A modern linear operator algebra framework for high performance computing,” ACM Transactions on Mathematical Software, vol. 48, pp. 2:1–2:33, Feb. 2022
work page 2022
-
[37]
AmgX: A library for GPU accelerated algebraic multigrid and preconditioned iter- ative methods,
M. Naumov, M. Arsaev, P. Castonguay, J. Cohen, J. Demouth, J. Eaton, S. Layton, N. Markovskiy, I. Reguly, N. Sakharnykh,et al., “AmgX: A library for GPU accelerated algebraic multigrid and preconditioned iter- ative methods,”SIAM Journal on Scientific Computing, vol. 37, no. 5, pp. S602–S626, 2015
work page 2015
-
[38]
NVIDIA, Algebraic multigrid solver (AmgX) library version 2.5.0, 2025
“NVIDIA, Algebraic multigrid solver (AmgX) library version 2.5.0, 2025.”https://github.com/NVIDIA/AMGX
work page 2025
-
[39]
J. Dongarra, M. Heroux, and P. Luszczek, “High-performance conjugate- gradient benchmark: A new metric for ranking high-performance com- puting systems,”The International Journal of High Performance Com- puting Applications, vol. 30, no. 1, pp. 3–10, 2016. 29
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.