Demystifying MaskGIT Sampler and Beyond: Adaptive Order Selection in Masked Diffusion
Pith reviewed 2026-05-18 10:03 UTC · model grok-4.3
The pith
The MaskGIT sampler implicitly performs temperature sampling, and an asymptotically equivalent moment sampler offers a simpler choose-then-sample alternative.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The MaskGIT sampler implicitly performs temperature sampling. The moment sampler is asymptotically equivalent yet more tractable and employs a choose-then-sample approach by selecting unmasking positions before sampling tokens. Partial caching and a hybrid adaptive-unmasking strategy further improve efficiency.
What carries the argument
The moment sampler, which selects unmasking positions first then samples tokens, serving as a tractable and interpretable stand-in for MaskGIT's implicit temperature sampling.
If this is right
- Partial caching lets transformers approximate longer sampling trajectories at sub-linear extra cost.
- The hybrid approach formalizes the exploration-exploitation trade-off for choosing which positions to unmask next.
- The same choose-then-sample logic applies directly to text generation tasks.
- Efficiency improvements appear in both image and text domains without changing the underlying model.
Where Pith is reading between the lines
- The same analysis could be applied to masked diffusion in other modalities such as audio or video.
- Adaptive position selection might be combined with existing acceleration techniques like distillation.
- Explicit temperature control via the moment sampler could give practitioners a new knob for trading off diversity and fidelity.
- Testing the sampler on larger-scale models would reveal whether the tractability advantage scales.
Load-bearing premise
The theoretical equivalence and implicit temperature mechanism hold under the standard assumptions of the masked diffusion forward process and the specific token prediction heads used in image modeling.
What would settle it
Compare the token distributions and sample quality of MaskGIT and the moment sampler on the same trained model as the number of diffusion steps grows large; systematic divergence would falsify the asymptotic equivalence.
Figures





read the original abstract
Masked diffusion models have shown promising performance in generating high-quality samples in a wide range of domains, but accelerating their sampling process remains relatively underexplored. To investigate efficient samplers for masked diffusion, this paper theoretically analyzes the MaskGIT sampler for image modeling, revealing its implicit temperature sampling mechanism. Through this analysis, we introduce the "moment sampler," an asymptotically equivalent but more tractable and interpretable alternative to MaskGIT, which employs a "choose-then-sample" approach by selecting unmasking positions before sampling tokens. In addition, we improve the efficiency of choose-then-sample algorithms through two key innovations: a partial caching technique for transformers that approximates longer sampling trajectories without proportional computational cost, and a hybrid approach formalizing the exploration-exploitation trade-off in adaptive unmasking. Experiments in image and text domains demonstrate our theory as well as the efficiency of our proposed methods, advancing both theoretical understanding and practical implementation of masked diffusion samplers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper theoretically analyzes the MaskGIT sampler in masked diffusion models for image modeling, revealing an implicit temperature sampling mechanism. It introduces the moment sampler as an asymptotically equivalent but more tractable alternative employing a choose-then-sample strategy. Additional contributions include a partial caching technique for transformers and a hybrid exploration-exploitation approach for adaptive unmasking, with supporting experiments in image and text domains.
Significance. If the asymptotic equivalence and implicit mechanism hold under the paper's assumptions, the work would provide useful theoretical demystification of an existing sampler along with practical efficiency improvements for masked diffusion sampling. The choose-then-sample formulation and caching method are interpretable strengths that could aid further sampler design.
major comments (2)
- [§3] §3 (MaskGIT analysis): The derivation of implicit temperature sampling and asymptotic equivalence between MaskGIT and the moment sampler relies on limiting behavior of the masked diffusion forward process. The manuscript does not provide error bounds or analysis showing that this equivalence survives the finite discrete unmasking steps used in the image and text experiments, which is load-bearing for the central claim that the moment sampler is a faithful yet tractable replacement.
- [§5] §5 (Efficient choose-then-sample algorithms): The partial caching technique is presented as approximating longer trajectories without proportional cost, but no ablation quantifies the approximation error introduced by caching on the final sample distribution or on the claimed equivalence to MaskGIT.
minor comments (2)
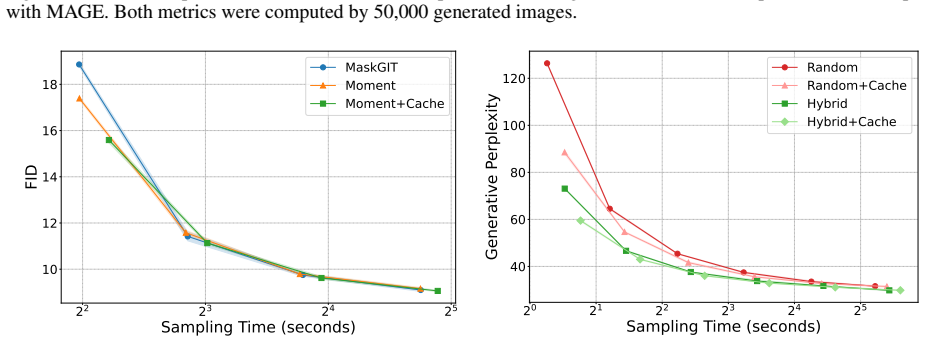
- [Figures] Figure 2 and 3: axis labels and legends are too small for readability; increase font size and add explicit step-count annotations.
- [§4] Notation in §4: the definition of the moment statistic should be stated as an explicit equation before the choose-then-sample algorithm is described.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of rigor in the theoretical analysis and empirical validation. We address each major comment point-by-point below, agreeing where revisions are warranted to strengthen the work.
read point-by-point responses
-
Referee: [§3] §3 (MaskGIT analysis): The derivation of implicit temperature sampling and asymptotic equivalence between MaskGIT and the moment sampler relies on limiting behavior of the masked diffusion forward process. The manuscript does not provide error bounds or analysis showing that this equivalence survives the finite discrete unmasking steps used in the image and text experiments, which is load-bearing for the central claim that the moment sampler is a faithful yet tractable replacement.
Authors: We agree that finite-step error analysis would provide stronger support for the practical utility of the moment sampler. The asymptotic equivalence is derived under the continuous-time limit of the forward process, which illuminates the implicit temperature mechanism, but we acknowledge that the manuscript relies on empirical validation (Sections 6 and 7) rather than explicit bounds for the discrete schedules used in experiments. In the revised manuscript, we will add a subsection to §3 deriving a finite-T total variation bound under standard assumptions on the masking rate schedule, accompanied by a short numerical study confirming the bound remains small for the step counts in our image and text experiments. revision: yes
-
Referee: [§5] §5 (Efficient choose-then-sample algorithms): The partial caching technique is presented as approximating longer trajectories without proportional cost, but no ablation quantifies the approximation error introduced by caching on the final sample distribution or on the claimed equivalence to MaskGIT.
Authors: We concur that an explicit quantification of the approximation error is necessary to substantiate the efficiency claims. While the partial caching method is motivated by the structure of the choose-then-sample procedure and transformer attention patterns, the current manuscript does not include a dedicated ablation on distributional impact. In the revision, we will expand §5 with an ablation study reporting metrics such as FID (images) and perplexity (text) for varying cache depths, as well as a direct comparison of sample statistics against the non-cached moment sampler and MaskGIT. This will clarify the regimes where the approximation preserves fidelity. revision: yes
Circularity Check
No significant circularity; derivation derives implicit mechanism from sampler definition
full rationale
The paper's central chain begins with a theoretical analysis of the MaskGIT sampler under the masked diffusion forward process, revealing an implicit temperature sampling mechanism directly from the sampler's definition and token prediction heads. From this analysis it constructs the moment sampler as an asymptotically equivalent choose-then-sample alternative. No step reduces a prediction or uniqueness claim to a fitted parameter, self-citation chain, or definitional tautology; the equivalence is presented as a mathematical consequence of the limiting regime rather than an input renamed as output. The work remains self-contained against external benchmarks of the diffusion process.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Masked diffusion forward process and token prediction heads behave as assumed in the MaskGIT analysis
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2 (Moment sampler approximates MaskGIT in the N ≫ k² regime) ... d_TV bound via Bernstein concentration on ∥p_i∥_β^β
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Heli Ben-Hamu, Itai Gat, Daniel Severo, Niklas Nolte, and Brian Karrer. Accelerated sampling from masked diffusion models via entropy bounded unmasking.arXiv preprint arXiv:2505.24857,
-
[2]
A pytorch reproduction of masked generative image transformer.arXiv preprint arXiv:2310.14400,
Victor Besnier and Mickael Chen. A pytorch reproduction of masked generative image transformer.arXiv preprint arXiv:2310.14400,
-
[3]
Chuangtao Chen, Qinglin Zhao, MengChu Zhou, Zhimin He, and Haozhen Situ. Overcoming dimensional factorization limits in discrete diffusion models through quantum joint distribution learning.arXiv preprint arXiv:2505.05151,
-
[4]
Marco Comunit `a, Zhi Zhong, Akira Takahashi, Shiqi Yang, Mengjie Zhao, Koichi Saito, Yukara Ikemiya, Takashi Shibuya, Shusuke Takahashi, and Yuki Mitsufuji. SpecMaskGIT: Masked generative modeling of audio spectro- grams for efficient audio synthesis and beyond.arXiv preprint arXiv:2406.17672,
-
[5]
VampNet: Music generation via masked acoustic token modeling
Hugo F Flores Garcia, Prem Seetharaman, Rithesh Kumar, and Bryan Pardo. VampNet: Music generation via masked acoustic token modeling. InISMIR 2023 Hybrid Conference,
work page 2023
-
[6]
Gabe Guo and Stefano Ermon. Reviving any-subset autoregressive models with principled parallel sampling and speculative decoding.arXiv preprint arXiv:2504.20456,
-
[7]
dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781,
Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. dKV-cache: The cache for diffusion language models. arXiv preprint arXiv:2505.15781,
-
[8]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Path planning for masked diffusion model sampling.arXiv preprint arXiv:2502.03540,
Fred Zhangzhi Peng, Zachary Bezemek, Sawan Patel, Jarrid Rector-Brooks, Sherwood Yao, Avishek Joey Bose, Alexander Tong, and Pranam Chatterjee. Path planning for masked diffusion model sampling.arXiv preprint arXiv:2502.03540,
-
[10]
Yinuo Ren, Haoxuan Chen, Yuchen Zhu, Wei Guo, Yongxin Chen, Grant M Rotskoff, Molei Tao, and Lexing Ying. Fast solvers for discrete diffusion models: Theory and applications of high-order algorithms.arXiv preprint arXiv:2502.00234,
-
[11]
Di[M]O: Distilling masked diffusion models into one-step generator.arXiv preprint arXiv:2503.15457,
Yuanzhi Zhu, Xi Wang, St´ephane Lathuili`ere, and Vicky Kalogeiton. Di[M]O: Distilling masked diffusion models into one-step generator.arXiv preprint arXiv:2503.15457,
-
[12]
12 DEMYSTIFYINGMASKGIT SAMPLER ANDBEYOND A Algorithms In this section, we itemize the algorithm pseudocodes of the MakGIT sampler (Algorithm 1), Moment Sampler (Al- gorithm 2), and the general form of choose-then-sample methods (Algorithm 3). Algorithm 1One-round of MaskGIT sampler: OneRoundMaskGIT((p i)i∈I , k, α) Require: (pi)i∈I: Family of probability ...
work page 2013
-
[13]
Therefore, the proof has been completed. C.2 Proof of Equation 4 Proof.By using the chain rule of KL divergence (Cover & Thomas, 2006, Theorem 2.5.3), we have DKL(q∥p) =D KL(qI ∥p I) +E xI ∼qI DKL(qI c|I(·|xI)∥p I c|I(·|xI)) ,(12) which shows the first inequality in (4). Let us first consider the KL divergence betweenq I andp I. First, we have DKL(qI ∥p I...
work page 2006
-
[14]
Thus, for the total variation distance, we have dTV(p, q) = 1 2 X x∈X |p(x)−q(x)| = 1 2 X x∈X (p(x)−q(x)) + + X x∈X (q(x)−p(x)) + ! = X x∈X (p(x)−q(x)) +. By using this, we have dTV(˜pmoment,˜pMaskGIT) = X i∈[N] k X z∈S N (˜pMaskGIT(i,z)−˜p moment(i,z)) + = X i∈[N] k X z∈Zϵ (˜pMaskGIT(i,z)−˜p moment(i,z)) + + X i∈[N] k X z̸∈Zϵ (˜pMaskGIT(i,z)−˜p moment(i,...
work page 2022
-
[15]
and its variants given the parameterα. Note that, in the final step (n=N) ofMomentor other temperature-sampling methods, we omit the sampling temperature (or takeα N → ∞), in order that it corresponds to the final step ofMaskGIT. D.2 Partial caching In the partial caching algorithm we described in Section 4.1, we have a degree of freedom in dividing the s...
work page 2023
-
[16]
It was trained on the OpenWebText dataset (Gokaslan & Cohen, 2019)
4, which is a masked diffusion model over a GPT-2 tok- enizers (Radford et al., 2019). It was trained on the OpenWebText dataset (Gokaslan & Cohen, 2019). The codebook size is|S|= 50257and the token sequence length is given byD=
work page 2019
-
[17]
We used the implementation of Deschenaux & Gulcehre (2025)
and averaged over 1024 samples. We used the implementation of Deschenaux & Gulcehre (2025). Entropy.Following the existing work (Gat et al., 2024; Zheng et al., 2025), we measured the sentence-wise entropy for checking the diversity of generated sentences. In our implementation (following the description of (Zheng et al., 2025)), for a sequence of tokensx...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.