Adaptive Memory Momentum via a Model-Based Framework for Deep Learning Optimization
Pith reviewed 2026-05-18 09:42 UTC · model grok-4.3
The pith
Momentum becomes dynamic by fitting the loss surface with two planes, one from the current gradient and one from past gradients in memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The core claim is that a proximal two-plane model of the objective, built from the instantaneous gradient and the accumulated memory of past gradients, yields a closed-form rule for updating the momentum coefficient at every iteration; this rule replaces the conventional constant beta and produces an adaptive-memory optimizer that requires no additional tuning.
What carries the argument
The two-plane proximal approximation that combines the current gradient plane with a memory-derived plane to solve for the momentum coefficient that best fits the local model.
If this is right
- Adaptive memory can be dropped into existing first-order methods such as SGD and AdamW without changing their code structure or adding hyperparameters.
- The same two-plane derivation applies across convex problems and large-scale non-convex deep-learning workloads.
- Because the update uses only information already present in the optimizer state, no extra memory or gradient evaluations are required.
- The approach opens a route to other forms of online adaptivity that are derived from local model fits rather than heuristic schedules.
Where Pith is reading between the lines
- The same local-model idea could be applied to derive adaptive versions of other coefficients, such as the beta_2 term in Adam or the learning-rate schedule itself.
- If the two-plane fit proves reliable, it suggests a broader class of model-based first-order methods that stay simple yet adapt more than hand-tuned constants.
- Testing the method on problems where momentum is known to be harmful, such as very noisy gradients, would clarify its limits.
Load-bearing premise
The local two-plane model of the objective is accurate enough to produce a stable, useful adjustment to the momentum coefficient at each step.
What would settle it
Run the adaptive rule on a simple strongly convex quadratic where the optimal fixed momentum is known analytically; if the online coefficient stays near that optimum and yields faster convergence than the best fixed value, the approximation is useful; if it diverges or underperforms, the claim fails.
Figures






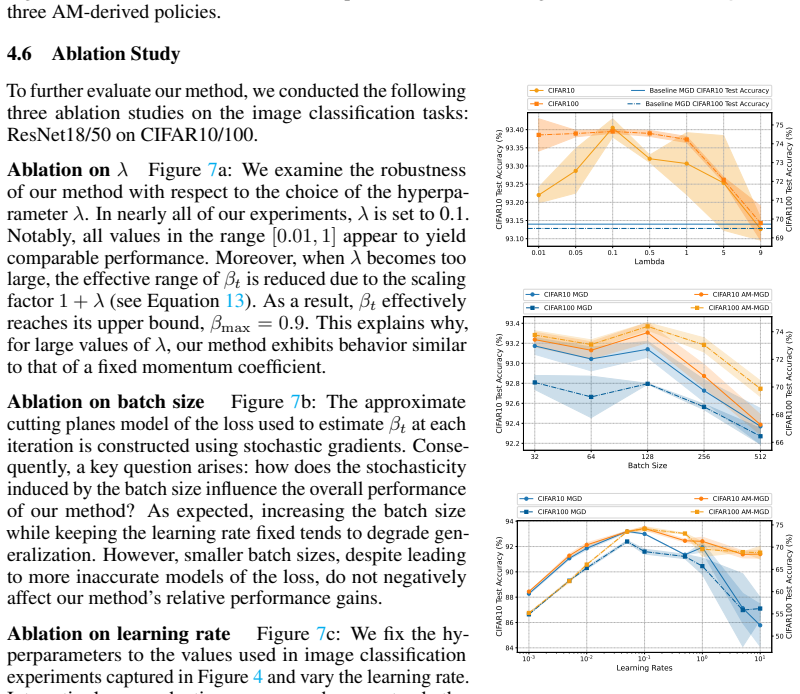




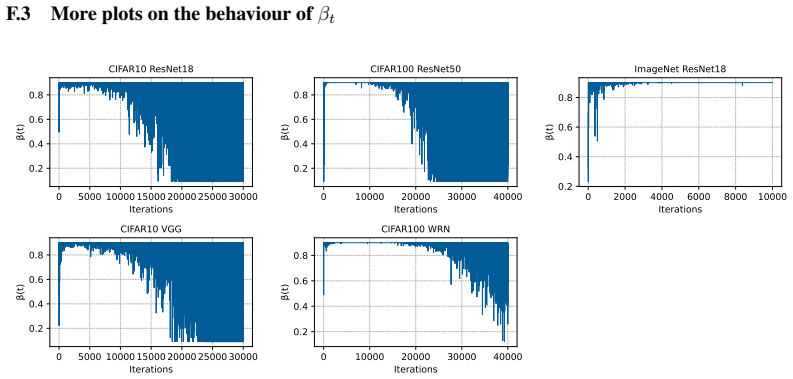
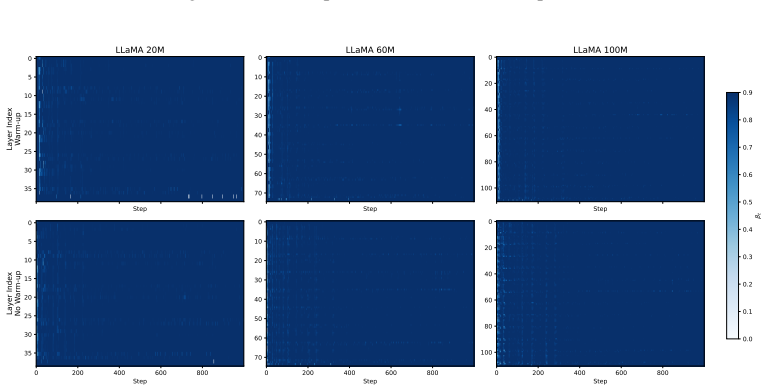
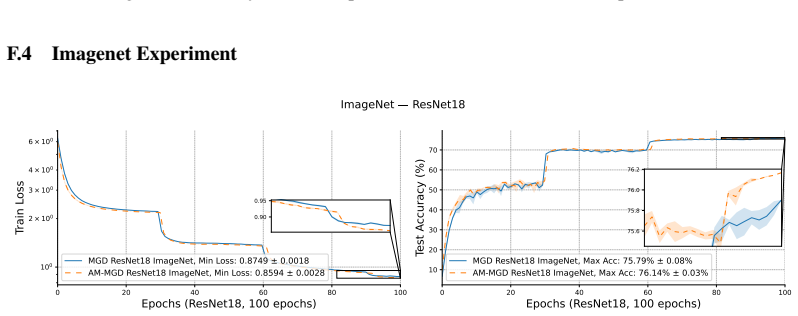
read the original abstract
The vast majority of modern deep learning models are trained with momentum-based first-order optimizers. The momentum term governs the optimizer's memory by determining how much each past gradient contributes to the current convergence direction. Fundamental momentum methods, such as Nesterov Accelerated Gradient and the Heavy Ball method, as well as more recent optimizers such as AdamW and Lion, all rely on the momentum coefficient that is customarily set to $\beta = 0.9$ and kept constant during model training, a strategy widely used by practitioners, yet suboptimal. In this paper, we introduce an \textit{adaptive memory} mechanism that replaces constant momentum with a dynamic momentum coefficient that is adjusted online during optimization. We derive our method by approximating the objective function using two planes: one derived from the gradient at the current iterate and the other obtained from the accumulated memory of the past gradients. To the best of our knowledge, such a proximal framework was never used for momentum-based optimization. Our proposed approach is novel, extremely simple to use, and does not rely on extra assumptions or hyperparameter tuning. We implement adaptive memory variants of both SGD and AdamW across a wide range of learning tasks, from simple convex problems to large-scale deep learning scenarios, demonstrating that our approach can outperform standard SGD and Adam with hand-tuned momentum coefficients. Finally, our work opens doors for new ways of inducing adaptivity in optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an adaptive memory mechanism to replace the fixed momentum coefficient (typically β=0.9) in first-order optimizers such as SGD and AdamW. The dynamic coefficient is obtained online by minimizing a proximal model that combines a linear approximation of the objective from the current gradient with a second plane derived from the accumulated memory of past gradients. The authors implement the resulting variants on tasks ranging from convex problems to large-scale deep learning and report improved performance over hand-tuned constant-momentum baselines without introducing extra hyperparameters.
Significance. If the two-plane proximal approximation produces a stable, hyperparameter-free online rule that remains effective under stochastic non-convex gradients, the work supplies a principled and unusually simple route to momentum adaptivity. The absence of additional assumptions or tuning parameters would be a practical strength, and the explicit use of a memory-derived plane distinguishes the approach from existing adaptive optimizers.
major comments (2)
- [§3] §3 (Derivation of the proximal model): the claim that the composite two-plane surrogate remains sufficiently accurate to yield a useful momentum rule is load-bearing, yet the manuscript provides no analysis showing that the memory plane stays coherent with the current geometry when gradients are stochastic estimates; if the planes diverge, the argmin over the momentum coefficient can become erratic. A concrete stability argument or counter-example test is required.
- [§5.2, Table 3] §5.2 and Table 3 (large-scale experiments): the reported gains over AdamW with β=0.9 are presented without multiple random seeds, statistical significance tests, or ablation on the memory-plane weighting; this weakens the central empirical claim that the method consistently outperforms fixed-momentum baselines.
minor comments (2)
- [§2] The abstract states that the proximal framework 'was never used for momentum-based optimization,' but §2 should contain a more explicit comparison with prior model-based or proximal momentum variants to substantiate novelty.
- [§3] Notation for the memory plane and the resulting momentum update rule should be introduced with an explicit equation early in §3 rather than being described only in prose.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment below and indicate the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Derivation of the proximal model): the claim that the composite two-plane surrogate remains sufficiently accurate to yield a useful momentum rule is load-bearing, yet the manuscript provides no analysis showing that the memory plane stays coherent with the current geometry when gradients are stochastic estimates; if the planes diverge, the argmin over the momentum coefficient can become erratic. A concrete stability argument or counter-example test is required.
Authors: We agree that the coherence of the memory plane under stochastic gradients is a key point requiring further attention. The manuscript derives the two-plane proximal model and validates it empirically, but does not supply an explicit stability argument for the stochastic case. In the revised version we will add a short subsection to §3 that provides a stability argument under the assumption of bounded gradient variance, together with a simple counter-example test on a noisy quadratic objective that illustrates the conditions under which the planes remain sufficiently aligned for the resulting momentum rule to stay well-behaved. revision: yes
-
Referee: [§5.2, Table 3] §5.2 and Table 3 (large-scale experiments): the reported gains over AdamW with β=0.9 are presented without multiple random seeds, statistical significance tests, or ablation on the memory-plane weighting; this weakens the central empirical claim that the method consistently outperforms fixed-momentum baselines.
Authors: We concur that the large-scale results would be more convincing with additional statistical rigor. The original experiments were reported from single runs owing to computational cost. In the revision we will re-run the §5.2 experiments and update Table 3 to report means and standard deviations over at least three independent random seeds, include paired t-tests for significance against the β=0.9 baselines, and add an ablation that varies the memory-plane weighting to confirm robustness of the observed gains. revision: yes
Circularity Check
Derivation via two-plane proximal model is self-contained with no reduction to inputs
full rationale
The paper derives the adaptive momentum coefficient explicitly by minimizing a proximal surrogate that combines a linear model from the current gradient with a second plane built from accumulated past gradients. This produces an online update rule directly from the argmin operation on the composite approximation rather than by fitting a parameter to data and relabeling the fit as a prediction. No self-citation chain, uniqueness theorem, or ansatz is invoked to justify the core construction; the method is presented as a first-principles proximal framework applied to momentum. The derivation therefore remains independent of its own outputs and does not collapse by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The objective function can be usefully approximated locally by two planes, one from the current gradient and one from accumulated past gradients.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We derive our method by approximating the objective function using two planes: one derived from the gradient at the current iterate and the other obtained from the accumulated memory of the past gradients... β*_t = Clip[0,1] ((ˆf(x_t)-f(x_t))(λ+1)/η - ⟨d_t-g_t,g_t+λ d_t⟩ / ∥d_t-g_t∥²)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
f^m_t(x) = max{ f(x_t)+g_t^⊤(x-x_t), ˆf(x_t)+(1/η)(x_{t-1}-x_t)^⊤(x-x_t) } ... proximal step yields heavy-ball update with adaptive β_t
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
K. Alex. Learning multiple layers of features from tiny images.https://www. cs. toronto. edu/kriz/learning-features-2009-TR. pdf, 2009
work page 2009
-
[2]
H. Asi, K. Chadha, G. Cheng, and J. C. Duchi. Minibatch stochastic approximate proximal point methods.Advances in neural information processing systems, 33:21958–21968, 2020
work page 2020
- [3]
- [4]
-
[5]
L. Bottou. Online algorithms and stochastic approximations. InOnline Learning and Neural Networks. Cambridge University Press, 1998
work page 1998
- [6]
-
[7]
C.-C. Chang and C.-J. Lin. LIBSVM: A library for support vector machines.ACM Transactions on Intelligent Systems and Technology, 2:27:1–27:27, 2011. Software available at http: //www.csie.ntu.edu.tw/~cjlin/libsvm
work page 2011
-
[8]
J. Chen, C. Wolfe, Z. Li, and A. Kyrillidis. Demon: Improved neural network training with momentum decay. InICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 3958–3962, 2022
work page 2022
-
[9]
X. Chen, C. Liang, D. Huang, E. Real, K. Wang, H. Pham, X. Dong, T. Luong, C.-J. Hsieh, Y . Lu, et al. Symbolic discovery of optimization algorithms.Advances in neural information processing systems, 36, 2024
work page 2024
-
[10]
D. Davis and D. Drusvyatskiy. Stochastic model-based minimization of weakly convex functions. SIAM Journal on Optimization, 29(1):207–239, 2019
work page 2019
- [11]
-
[12]
A. Defazio and K. Mishchenko. Learning-rate-free learning by d-adaptation. InInternational Conference on Machine Learning, pages 7449–7479. PMLR, 2023
work page 2023
-
[13]
Q. Deng and W. Gao. Minibatch and momentum model-based methods for stochastic weakly convex optimization. InProceedings of the 35th International Conference on Neural Information Processing Systems, NIPS ’21, Red Hook, NY , USA, 2021. Curran Associates Inc
work page 2021
- [14]
-
[15]
P. Giselsson and S. Boyd. Monotonicity and restart in fast gradient methods. In53rd IEEE Conference on Decision and Control, pages 5058–5063. IEEE, 2014
work page 2014
- [16]
-
[17]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
P. Goyal, P. Dollár, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y . Jia, and K. He. Accurate, large minibatch sgd: Training imagenet in 1 hour.arXiv preprint arXiv:1706.02677, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [19]
-
[20]
W. W. Hager and H. Zhang. A survey of nonlinear conjugate gradient methods.Pacific journal of Optimization, 2(1):35–58, 2006
work page 2006
-
[21]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770– 778, 2016
work page 2016
- [22]
-
[23]
C. Hu, W. Pan, and J. Kwok. Accelerated gradient methods for stochastic optimization and online learning.Advances in Neural Information Processing Systems, 22, 2009
work page 2009
-
[24]
M. Ivgi, O. Hinder, and Y . Carmon. Dog is sgd’s best friend: A parameter-free dynamic step size schedule. InInternational Conference on Machine Learning, pages 14465–14499. PMLR, 2023
work page 2023
-
[25]
S. Jelassi and Y . Li. Towards understanding how momentum improves generalization in deep learning. InInternational Conference on Machine Learning, pages 9965–10040. PMLR, 2022
work page 2022
- [26]
-
[27]
D. S. Kalra and M. Barkeshli. Why warmup the learning rate? underlying mechanisms and improvements.Advances in Neural Information Processing Systems, 37:111760–111801, 2024
work page 2024
-
[28]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Rad- ford, J. Wu, and D. Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[29]
J. E. Kelley, Jr. The cutting-plane method for solving convex programs.Journal of the society for Industrial and Applied Mathematics, 8(4):703–712, 1960
work page 1960
-
[30]
J. L. Kim, P. Toulis, and A. Kyrillidis. Convergence and stability of the stochastic proximal point algorithm with momentum. InLearning for Dynamics and Control Conference, pages 1034–1047. PMLR, 2022
work page 2022
-
[31]
D. P. Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
K. C. Kiwiel. An aggregate subgradient method for nonsmooth convex minimization.Mathe- matical Programming, 27:320–341, 1983
work page 1983
-
[33]
K. C. Kiwiel.Methods of descent for nondifferentiable optimization, volume 1133. Springer, 2006
work page 2006
- [34]
-
[35]
H. Liu, Z. Li, D. L. W. Hall, P. Liang, and T. Ma. Sophia: A scalable stochastic second-order optimizer for language model pre-training. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
work page 2024
-
[36]
J. Liu, J. Su, X. Yao, Z. Jiang, G. Lai, Y . Du, Y . Qin, W. Xu, E. Lu, J. Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Y . Liu, Y . Gao, and W. Yin. An improved analysis of stochastic gradient descent with momentum. Advances in Neural Information Processing Systems, 33:18261–18271, 2020
work page 2020
-
[38]
N. Loizou and P. Richtárik. Momentum and stochastic momentum for stochastic gradient, newton, proximal point and subspace descent methods.Computational Optimization and Applications, 77(3):653–710, 2020. 11
work page 2020
- [39]
-
[40]
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2017
work page 2017
-
[41]
I. Loshchilov and F. Hutter. SGDR: stochastic gradient descent with warm restarts. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017
work page 2017
- [42]
-
[43]
Y . Malitsky and K. Mishchenko. Adaptive gradient descent without descent.arXiv preprint arXiv:1910.09529, 2019
- [44]
-
[45]
D. Oikonomou and N. Loizou. Stochastic polyak step-sizes and momentum: Convergence guarantees and practical performance.arXiv preprint arXiv:2406.04142, 2024
-
[46]
A. Orvieto, S. Lacoste-Julien, and N. Loizou. Dynamics of sgd with stochastic polyak stepsizes: Truly adaptive variants and convergence to exact solution.Advances in Neural Information Processing Systems, 35:26943–26954, 2022
work page 2022
-
[47]
B. O’donoghue and E. Candes. Adaptive restart for accelerated gradient schemes.Foundations of computational mathematics, 15:715–732, 2015
work page 2015
-
[48]
M. Pagliardini, P. Ablin, and D. Grangier. The ademamix optimizer: Better, faster, older. InThe Twelfth International Conference on Learning Representations, ICLR 2025, 2025
work page 2025
-
[49]
B. T. Polyak. Some methods of speeding up the convergence of iteration methods.Ussr computational mathematics and mathematical physics, 4(5):1–17, 1964
work page 1964
-
[50]
B. T. Polyak. Introduction to optimization. 1987
work page 1987
- [51]
-
[52]
H. Robbins and S. Monro. A stochastic approximation method.The annals of mathematical statistics, pages 400–407, 1951
work page 1951
-
[53]
R. T. Rockafellar. Monotone operators and the proximal point algorithm.SIAM journal on control and optimization, 14(5):877–898, 1976
work page 1976
-
[54]
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115:211–252, 2015
work page 2015
-
[55]
A. Ruszczy ´nski. A linearization method for nonsmooth stochastic programming problems. Mathematics of Operations Research, 12(1):32–49, 1987
work page 1987
-
[56]
S. Saab Jr, S. Phoha, M. Zhu, and A. Ray. An adaptive polyak heavy-ball method.Machine Learning, 111(9):3245–3277, 2022
work page 2022
-
[57]
F. Schaipp, R. Ohana, M. Eickenberg, A. Defazio, and R. M. Gower. Momo: Momentum models for adaptive learning rates.arXiv preprint arXiv:2305.07583, 2023
-
[58]
O. Sebbouh, R. M. Gower, and A. Defazio. Almost sure convergence rates for stochastic gradient descent and stochastic heavy ball. InConference on Learning Theory, pages 3935–3971. PMLR, 2021. 12
work page 2021
-
[59]
N. Shazeer and M. Stern. Adafactor: Adaptive learning rates with sublinear memory cost. In International Conference on Machine Learning, pages 4596–4604. PMLR, 2018
work page 2018
-
[60]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition.CoRR, abs/1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[61]
L. N. Smith. Cyclical learning rates for training neural networks. In2017 IEEE winter conference on applications of computer vision (WACV), pages 464–472. IEEE, 2017
work page 2017
-
[62]
I. Sutskever, J. Martens, G. Dahl, and G. Hinton. On the importance of initialization and momentum in deep learning. InInternational conference on machine learning, pages 1139–
-
[63]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample. Llama: Open and efficient foundation language models.ArXiv, abs/2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
P. Tseng. An incremental gradient (-projection) method with momentum term and adaptive stepsize rule.SIAM Journal on Optimization, 8(2):506–531, 1998
work page 1998
-
[65]
N. Vyas, D. Morwani, R. Zhao, M. Kwun, I. Shapira, D. Brandfonbrener, L. Janson, and S. Kakade. Soap: Improving and stabilizing shampoo using adam. InThe Twelfth International Conference on Learning Representations, ICLR 2025, 2025
work page 2025
-
[66]
B. Wang, T. Nguyen, T. Sun, A. L. Bertozzi, R. G. Baraniuk, and S. J. Osher. Scheduled restart momentum for accelerated stochastic gradient descent.SIAM Journal on Imaging Sciences, 15(2):738–761, 2022
work page 2022
-
[67]
X. Wang, M. Johansson, and T. Zhang. Generalized polyak step size for first order optimization with momentum. InInternational Conference on Machine Learning, pages 35836–35863. PMLR, 2023
work page 2023
-
[68]
M. Wortsman, P. J. Liu, L. Xiao, K. Everett, A. Alemi, B. Adlam, J. D. Co-Reyes, I. Gur, A. Kumar, R. Novak, et al. Small-scale proxies for large-scale transformer training instabilities. InThe Twelfth International Conference on Learning Representations, ICLR 2024, 2024
work page 2024
-
[69]
Y . Yan, T. Yang, Z. Li, Q. Lin, and Y . Yang. A unified analysis of stochastic momentum methods for deep learning.arXiv preprint arXiv:1808.10396, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [70]
- [71]
-
[72]
S. Zagoruyko. Wide residual networks.arXiv preprint arXiv:1605.07146, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[73]
Z. Zhuang, M. Liu, A. Cutkosky, and F. Orabona. Understanding adamw through proximal methods and scale-freeness.Transactions on machine learning research, 2022. 13 A Derivation of Adaptive Memory Momentum A cutting plane model of the function fm(x) = max n f(x t) +g ⊤ (x−x t), ˆf(x t) +d ⊤ t (x−x t) o Tthe update is defined by: xt+1 = argmin x fm(x) + 1 2...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.