Kernel Treatment Effects with Adaptively Collected Data
Pith reviewed 2026-05-18 07:43 UTC · model grok-4.3
The pith
A kernel method for testing full distributional differences in treatment outcomes remains valid when assignments adapt based on past data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors introduce a kernel treatment effect framework for adaptive data collection that combines doubly robust RKHS scores with a witness function learned on one data fold; inference is then performed on a held-out fold via a projected, sequentially normalized scalar statistic that maintains valid type-I error despite the dependence induced by the adaptive policy.
What carries the argument
The projected, sequentially normalized scalar statistic constructed from doubly robust RKHS scores and a learned witness function.
If this is right
- Valid type-I error control is achieved for tests of both mean shifts and higher-moment or shape differences in outcome distributions.
- The procedure remains calibrated when treatment assignment depends on past outcomes.
- Power gains appear relative to adaptive baselines that only target scalar average effects.
- The same split-sample structure supports inference on interventional distributions represented in an RKHS.
Where Pith is reading between the lines
- The sequential normalization step may generalize to other kernel-based causal estimators that must handle policy-induced dependence.
- The framework could support adaptive experiments in settings such as online recommendation or sequential clinical trials where distributional outcomes matter.
- Extensions might replace the fixed split with more efficient cross-fitting while preserving the type-I guarantee.
Load-bearing premise
The doubly robust property of the RKHS scores continues to hold even though the adaptive assignment rule creates statistical dependence across observations.
What would settle it
A Monte Carlo study under a known null hypothesis with a specific adaptive policy in which the empirical rejection rate of the new test exceeds the nominal significance level.
Figures








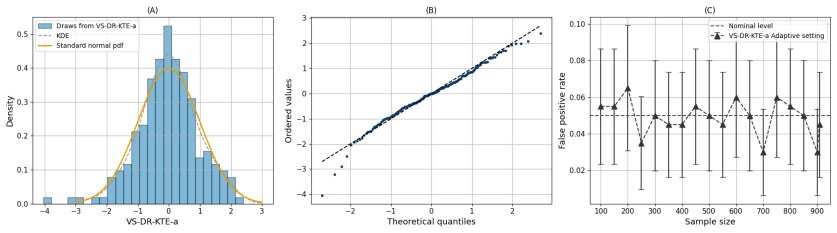

read the original abstract
Adaptive experiments improve efficiency by adjusting treatment assignments based on past outcomes, but this adaptivity breaks the i.i.d.\ assumptions that underpin classical asymptotics. At the same time, many questions of interest are distributional, extending beyond average effects. Kernel treatment effects (KTE) provide a flexible framework by representing interventional outcome distributions in an RKHS and comparing them via kernel distances. We present the first kernel-based framework for distributional inference under adaptive data collection. Our method combines doubly robust RKHS scores with a witness function learned on one fold, and performs inference on a second fold using a projected, sequentially normalized scalar statistic with valid type-I error. Experiments show that the resulting procedure is well calibrated and effective for both mean shifts and higher-moment differences, outperforming adaptive baselines limited to scalar effects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first kernel-based framework for distributional inference on treatment effects under adaptive data collection. It combines doubly robust RKHS scores with a witness function learned on one data fold and performs inference on a held-out fold via a projected, sequentially normalized scalar statistic that is claimed to deliver valid type-I error control. Experiments are reported to show calibration for both mean shifts and higher-moment differences, with outperformance relative to adaptive baselines restricted to scalar effects.
Significance. If the type-I error guarantee is rigorously established, the work would constitute a meaningful extension of kernel treatment effect methods to adaptive experimental settings, enabling flexible nonparametric distributional comparisons where classical i.i.d. asymptotics fail. The combination of cross-fitting, doubly robust scores, and sequential normalization is a natural technical direction, and the empirical demonstration of calibration for non-mean effects is a positive feature.
major comments (2)
- [§4 (Inference procedure) or Theorem on type-I error] The validity of type-I error for the sequentially normalized statistic (described in the abstract and presumably formalized in §4 or Theorem 2) rests on the doubly robust RKHS scores remaining conditionally mean-zero under the adaptive filtration. The cross-fit construction learns the witness on one fold and projects on the second, but the manuscript does not explicitly verify that estimation error in the witness remains orthogonal to future treatment probabilities induced by the adaptive policy; without this step the martingale property required for the normalized increments can fail even though double robustness holds in the non-adaptive case.
- [Theorem 1 / Proposition on asymptotic validity] The claim that the procedure controls type-I error for arbitrary adaptive assignment rules is load-bearing for the central contribution. The provided description does not state additional assumptions on the adaptive policy (e.g., bounded propensity scores or limited dependence) that would be needed to close the argument; if such conditions are implicit they should be made explicit and the proof adjusted accordingly.
minor comments (2)
- [§2 (Background)] Notation for the RKHS embeddings and the witness function projection should be introduced with a short table or diagram in §2 to improve readability for readers unfamiliar with kernel mean embeddings.
- [§5 (Experiments)] The experimental section reports calibration and outperformance but omits the precise adaptive policies simulated and the number of Monte Carlo replications; adding these details would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our work. The points raised regarding the martingale property and explicit assumptions for type-I error control under adaptivity are well-taken. We address each comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [§4 (Inference procedure) or Theorem on type-I error] The validity of type-I error for the sequentially normalized statistic (described in the abstract and presumably formalized in §4 or Theorem 2) rests on the doubly robust RKHS scores remaining conditionally mean-zero under the adaptive filtration. The cross-fit construction learns the witness on one fold and projects on the second, but the manuscript does not explicitly verify that estimation error in the witness remains orthogonal to future treatment probabilities induced by the adaptive policy; without this step the martingale property required for the normalized increments can fail even though double robustness holds in the non-adaptive case.
Authors: We appreciate the referee's identification of this expository gap. The cross-fit design ensures the witness function is estimated solely from the first fold and is therefore fixed (and measurable with respect to the past) when the score is evaluated on the second fold. Double robustness of the RKHS score then guarantees that its conditional expectation given the adaptive filtration is exactly zero, independent of the estimation error in the witness. This orthogonality preserves the martingale difference property for the normalized increments. We will add an explicit supporting lemma in the appendix that derives the required conditional orthogonality between the witness estimation error and the adaptive treatment probabilities. revision: yes
-
Referee: [Theorem 1 / Proposition on asymptotic validity] The claim that the procedure controls type-I error for arbitrary adaptive assignment rules is load-bearing for the central contribution. The provided description does not state additional assumptions on the adaptive policy (e.g., bounded propensity scores or limited dependence) that would be needed to close the argument; if such conditions are implicit they should be made explicit and the proof adjusted accordingly.
Authors: We agree that the assumptions on the adaptive policy must be stated explicitly rather than left implicit. The current proof relies on the propensity scores being uniformly bounded away from zero and one (to ensure the scores remain well-defined and the variance is controlled) and on the policy generating a filtration under which the cross-fit scores form a martingale difference sequence with bounded moments. These conditions are standard for adaptive inference but were not highlighted in the theorem statement. We will revise the statement of Theorem 2 to list these assumptions explicitly and update the proof to reference them at each step where they are used. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's claimed framework combines existing doubly robust RKHS scores with cross-fitting (witness function on one fold, inference on the second) and sequential normalization to obtain a scalar statistic whose type-I error is asserted to remain valid under adaptive assignment via martingale properties. No equation or step is shown to define the target distributional inference or the normalized statistic in terms of itself, nor does any central result reduce by construction to a fitted parameter or to a self-citation whose content is unverified. The load-bearing assumption—that the doubly robust scores remain conditionally mean-zero under the adaptive filtration—is presented as a substantive extension rather than a tautology, and the abstract and described procedure build on prior kernel and doubly robust literature without renaming known results or smuggling ansatzes via self-citation. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Doubly robust property of RKHS scores holds under adaptive sampling
- domain assumption Sequential normalization yields valid type-I error under adaptivity
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present the first kernel-based framework for distributional inference under adaptive data collection. Our method combines doubly robust RKHS scores with a witness function learned on one fold, and performs inference on a second fold using a projected, sequentially normalized scalar statistic
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 4.5 (Asymptotic normality of the stabilized RKHS estimator) ... Hilbert-space martingale CLT
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Semiparametric Efficient Test for Interpretable Distributional Treatment Effects
DR-ME is the first semiparametrically efficient finite-location kernel test for interpretable distributional treatment effects, using orthogonal doubly robust features derived from observational data.
Reference graph
Works this paper leans on
-
[1]
S. Athey, D. Eckles, and G. W. Imbens. Design and analysis of experiments in the digital age.Annual Review of Economics, 14:779–806, 2022. doi: 10.1146/annurev-economics-051520-023803
-
[2]
A. Berlinet and C. Thomas-Agnan.Reproducing kernel Hilbert spaces in probability and statistics. Springer Science & Business Media, 2011
work page 2011
-
[3]
A. Bibaut and N. Kallus. Demystifying inference after adaptive experiments.Annual Review of Statistics and its Application, 12(1):407–423, 2025
work page 2025
- [4]
-
[5]
Bosq.Linear processes in function spaces: theory and applications, volume 149
D. Bosq.Linear processes in function spaces: theory and applications, volume 149. Springer Science & Business Media, 2000
work page 2000
-
[6]
S. Caria, B. Gordon, M. Kasy, et al. Adaptive experiments in economics.Annual Review of Economics, 15:615–647, 2023. doi: 10.1146/annurev-economics-091622-031912
-
[7]
V. Chernozhukov, I. Fernández-Val, and B. Melly. Inference on counterfactual distributions.Econometrica, 81(6):2205–2268, 2013
work page 2013
-
[8]
S.-C. Chow and M. Chang.Adaptive Design Methods in Clinical Trials. Chapman & Hall/CRC, 2nd edition, 2011
work page 2011
-
[9]
DoubleDebiasedMachineLearningNonparametricInferencewithContinuous Treatments
K.ColangeloandY.-Y.Lee. DoubleDebiasedMachineLearningNonparametricInferencewithContinuous Treatments. Technical report, 2020. URLhttps://arxiv.org/pdf/2004.03036
- [10]
-
[11]
R. M. Dudley.Real Analysis and Probability. Cambridge Studies in Advanced Mathematics. Cambridge University Press, 2002
work page 2002
- [12]
-
[13]
A. Garivier and E. Kaufmann. Optimal best arm identification with fixed confidence. InProceedings of the 29th Conference on Learning Theory (COLT), pages 998–1027, 2016
work page 2016
-
[14]
T. Gärtner. A survey of kernels for structured data.ACM SIGKDD explorations newsletter, 5(1):49–58, 2003
work page 2003
-
[15]
A. Gretton. Introduction to rkhs, and some simple kernel algorithms.Adv. Top. Mach. Learn. Lecture Conducted from University College London, 16(5-3):2, 2013
work page 2013
-
[16]
A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Schölkopf, and A. Smola. A kernel two-sample test. Journal of Machine Learning Research, 13(25):723–773, 2012
work page 2012
-
[17]
A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Schölkopf, and A. Smola. A kernel two-sample test.The Journal of Machine Learning Research, 13(1):723–773, 2012
work page 2012
- [18]
-
[19]
P. Hall and C. C. Heyde.Martingale limit theory and its application. Academic press, 1980
work page 1980
-
[20]
J. L. Hill. Bayesian nonparametric modeling for causal inference.Journal of Computational and Graphical Statistics, 20(1):217–240, 2011. doi: 10.1198/jcgs.2010.08162. URLhttps://doi.org/10.1198/jcgs. 2010.08162
-
[21]
K. Hirano and J. R. Porter. Asymptotic representations for sequential decisions, adaptive experiments, and batched bandits.arXiv preprint arXiv:2302.03117, 2023
-
[22]
S. R. Howard, A. Ramdas, J. McAuliffe, and J. Sekhon. Time-uniform chernoff bounds via nonnegative supermartingales.Annals of Statistics, 49(2):1055–1080, 2021
work page 2021
-
[23]
T. Hsing and R. Eubank.Theoretical Foundations of Functional Data Analysis, with an Introduction to Linear Operators. Wiley, 2015
work page 2015
- [24]
-
[25]
M. Kanagawa and K. Fukumizu. Recovering Distributions from Gaussian RKHS Embeddings. In Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics, volume33, 2014
work page 2014
- [26]
-
[27]
T. Lattimore and C. Szepesvári.Bandit Algorithms. Cambridge University Press, 2020. doi: 10.1017/ 9781108571401
work page 2020
-
[28]
L. Li, W. Chu, J. Langford, and R. E. Schapire. A contextual-bandit approach to personalized news article recommendation. InProceedings of the 19th International Conference on World Wide Web (WWW), pages 661–670, 2010
work page 2010
-
[29]
Z. Li, D. Meunier, M. Mollenhauer, and A. Gretton. Optimal rates for regularized conditional mean embedding learning.Advances in Neural Information Processing Systems, 35:4433–4445, 2022
work page 2022
-
[30]
A. Luedtke and I. Chung. One-step estimation of differentiable Hilbert-valued parameters.The Annals of Statistics, 52(4):1534 – 1563, 2024
work page 2024
-
[31]
D. Martinez Taboada, A. Ramdas, and E. Kennedy. An efficient doubly-robust test for the kernel treatment effect. InAdvances in Neural Information Processing Systems, volume 36, pages 59924–59952, 2023
work page 2023
-
[32]
L. Matthey, I. Higgins, D. Hassabis, and A. Lerchner. dsprites: Disentanglement testing sprites dataset. https://github.com/deepmind/dsprites-dataset/, 2017
work page 2017
-
[33]
K. Muandet, M. Kanagawa, S. Saengkyongam, and S. Marukatat. Counterfactual mean embeddings. Journal of Machine Learning Research, 22(162):1–71, 2021
work page 2021
-
[34]
J. Park and K. Muandet. A measure-theoretic approach to kernel conditional mean embeddings.Advances in Neural Information Processing Systems, 2020
work page 2020
-
[35]
J. Park, U. Shalit, B. Schölkopf, and K. Muandet. Conditional distributional treatment effect with kernel conditional mean embeddings and u-statistic regression. InInternational conference on machine learning, pages 8401–8412, 2021
work page 2021
-
[36]
V. Perchet, P. Rigollet, S. Chassang, and E. Snowberg. Batched bandit problems.The Annals of Statistics, 44:660–681, 04 2016
work page 2016
-
[37]
I. Pinelis. Optimum bounds for the distributions of martingales in banach spaces.The Annals of Probability, pages 1679–1706, 1994
work page 1994
-
[38]
S. Qiang and M. Bayati. Dynamic pricing with demand learning and strategic consumers: An application to online retail.Operations Research, 64(4):931–944, 2016. doi: 10.1287/opre.2016.1514
-
[39]
R. T. Rockafellar, S. Uryasev, et al. Optimization of conditional value-at-risk.Journal of risk, 2:21–42, 2000
work page 2000
-
[40]
C. Rothe. Nonparametric estimation of distributional policy effects.Journal of Econometrics, 155(1): 56–70, 2010
work page 2010
-
[41]
S. Shekhar, I. Kim, and A. Ramdas. A permutation-free kernel independence test.Journal of Machine Learning Research, 24(369):1–68, 2023
work page 2023
-
[42]
Simon.Trace Ideals and Their Applications, volume 120 ofMathematical Surveys and Monographs
B. Simon.Trace Ideals and Their Applications, volume 120 ofMathematical Surveys and Monographs. American Mathematical Society, 2nd edition, 2005. 13
work page 2005
- [43]
- [44]
-
[45]
L. Song, J. Huang, A. Smola, and K. Fukumizu. Hilbert space embeddings of conditional distributions with applications to dynamical systems. InProceedings of the 26th Annual International Conference on Machine Learning, pages 961–968, 2009
work page 2009
-
[46]
B. Sriperumbudur, A. Gretton, K. Fukumizu, B. Schölkopf, and G. Lanckriet. Hilbert space embeddings and metrics on probability measures.Journal of Machine Learning Research, 11:1517–1561, 2010
work page 2010
-
[47]
A. v. d. Vaart and J. A. Wellner. Weak convergence and empirical processes with applications to statistics. Journal of the Royal Statistical Society-Series A Statistics in Society, 160(3):596–608, 1997
work page 1997
-
[48]
A. W. van der Vaart.Asymptotic Statistics. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 1998. doi: 10.1017/CBO9780511802256
-
[49]
I. Waudby-Smith and A. Ramdas. Time-uniform central limit theorems and confidence sequences. In International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 10663–10672, 2021
work page 2021
- [50]
- [51]
- [52]
- [53]
- [54]
-
[55]
K. Zhang, L. Janson, and S. Murphy. Statistical inference with m-estimators on adaptively collected data.Advances in neural information processing systems, 34:7460–7471, 2021. 14 Appendix This appendix is organized as follows: – Appendix 9: summary of the notations used in the paper and in the analysis. –Appendix 10: a review of reproducing kernel Hilbert...
work page 2021
-
[56]
(K(00) X,r +λI) −1K(00) X,r (K(00) X,r +λI) −1K(01) X,r 0 0 # , µ 1,r =
are needed. PlainL2 nuisance consistency and the mild Cesàro stabilization of the logging policy suffice to deliver the predictable quadratic-variation limit and Bosq’s (B2). We now provide an additional lemma on the convergence of the inverse of the average of conditional variance estimators. Lemma 11.3(Average stabilizer).Let bωt be estimators with rati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.