Constraint-Aware Reinforcement Learning via Adaptive Action Scaling
Pith reviewed 2026-05-18 07:32 UTC · model grok-4.3
The pith
A modular regulator scales RL actions based on predicted violations to improve safety without overriding the policy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that decoupling safety into an adaptive action-scaling regulator, trained to minimize predicted constraint violations, yields stable safe reinforcement learning that avoids both the instability of joint reward-safety optimization and the need for external filters that require prior system knowledge.
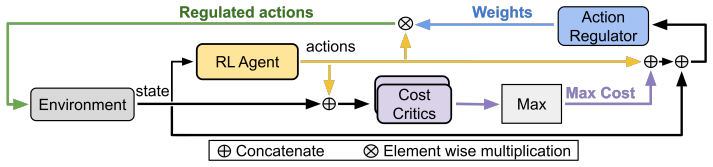
What carries the argument
The modular cost-aware regulator that predicts constraint violations and applies scaling factors to actions.
If this is right
- Integrates without modification to off-policy algorithms such as SAC and TD3.
- Achieves state-of-the-art return-to-cost ratios on Safety Gym tasks with sparse costs.
- Reduces constraint violations by up to 126 times while increasing returns by more than an order of magnitude.
Where Pith is reading between the lines
- The separation of the regulator from the task policy could let the same regulator be reused across different underlying algorithms or environments.
- This style of smooth modulation might extend to settings with continuous rather than sparse constraint signals.
- Real-world robotic deployment could benefit from the lack of required prior models for the safety component.
Load-bearing premise
The regulator can be trained to scale actions just enough to avoid violations while still allowing the policy to explore useful behaviors, based on accurate predictions from state-action pairs.
What would settle it
Training the full system on Safety Gym locomotion tasks and measuring whether constraint violations fall sharply while task returns stay high or increase; if violations remain high or returns collapse, the adaptive scaling claim does not hold.
Figures





read the original abstract
Safe reinforcement learning (RL) seeks to mitigate unsafe behaviors that arise from exploration during training by reducing constraint violations while maintaining task performance. Existing approaches typically rely on a single policy to jointly optimize reward and safety, which can cause instability due to conflicting objectives, or they use external safety filters that override actions and require prior system knowledge. In this paper, we propose a modular cost-aware regulator that scales the agent's actions based on predicted constraint violations, preserving exploration through smooth action modulation rather than overriding the policy. The regulator is trained to minimize constraint violations while avoiding degenerate suppression of actions. Our approach integrates seamlessly with off-policy RL methods such as SAC and TD3, and achieves state-of-the-art return-to-cost ratios on Safety Gym locomotion tasks with sparse costs, reducing constraint violations by up to 126 times while increasing returns by over an order of magnitude compared to prior methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a modular cost-aware regulator for safe reinforcement learning that adaptively scales the agent's actions based on predicted future constraint violations. This preserves exploration via smooth modulation rather than hard overrides or joint optimization of conflicting objectives. The regulator is trained separately to minimize violations without degenerate action suppression. The approach is claimed to integrate seamlessly with off-policy algorithms such as SAC and TD3, and to achieve state-of-the-art return-to-cost ratios on Safety Gym locomotion tasks with sparse costs, including up to 126-fold reductions in constraint violations and more than an order-of-magnitude improvement in returns relative to prior methods.
Significance. If the empirical claims and integration details hold, the work offers a practical, modular safety layer that can be added to existing off-policy RL pipelines without requiring system-specific knowledge or external filters. This could improve the performance-safety trade-off in sparse-cost settings and reduce instability from multi-objective training.
major comments (2)
- [Section 3.3] Section 3.3 (Regulator Integration with SAC/TD3): The claim of seamless integration requires that the critic be trained on the actually executed (scaled) actions rather than the policy's raw outputs. If the regulator is applied post-policy but the replay buffer or target computations use unscaled actions, the Q-values will be learned under the wrong action distribution. This breaks the off-policy correction and can cause the policy to optimize for an action space it never actually experiences, undermining both the reported return gains and the constraint reduction. The manuscript does not explicitly clarify the placement of the regulator inside or outside the learning loop.
- [Section 5.1 and Table 2] Section 5.1 and Table 2 (Empirical Results): The reported reductions in constraint violations by up to 126 times and returns increased by over an order of magnitude are load-bearing for the SOTA claim, yet the manuscript provides insufficient detail on the training procedure for the regulator, the exact baseline implementations, statistical significance across seeds, or error analysis. Without these, the quantitative gains cannot be verified as robust.
minor comments (2)
- [Section 3.1] Notation in Section 3.1: The distinction between the predicted constraint violation signal and the actual cost function is not clearly notated; a consistent symbol or subscript would improve readability.
- [Figure 3] Figure 3 caption: The legend does not distinguish between training and evaluation curves for the regulator, making it difficult to assess whether the reported improvements occur during or after regulator training.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below, providing clarifications on the technical integration and committing to expanded empirical details in revision.
read point-by-point responses
-
Referee: [Section 3.3] Section 3.3 (Regulator Integration with SAC/TD3): The claim of seamless integration requires that the critic be trained on the actually executed (scaled) actions rather than the policy's raw outputs. If the regulator is applied post-policy but the replay buffer or target computations use unscaled actions, the Q-values will be learned under the wrong action distribution. This breaks the off-policy correction and can cause the policy to optimize for an action space it never actually experiences, undermining both the reported return gains and the constraint reduction. The manuscript does not explicitly clarify the placement of the regulator inside or outside the learning loop.
Authors: We agree that the critic must be trained exclusively on the executed (scaled) actions to maintain correct off-policy learning. In the implementation, the regulator is placed inside the learning loop: the policy proposes an action, the regulator produces the scaled action, this scaled action is sent to the environment and stored in the replay buffer, and both the critic update and target computations use the scaled action. We will revise Section 3.3 to state this explicitly, including a brief description or pseudocode showing that the Q-function is learned under the distribution of actually executed actions. revision: yes
-
Referee: [Section 5.1 and Table 2] Section 5.1 and Table 2 (Empirical Results): The reported reductions in constraint violations by up to 126 times and returns increased by over an order of magnitude are load-bearing for the SOTA claim, yet the manuscript provides insufficient detail on the training procedure for the regulator, the exact baseline implementations, statistical significance across seeds, or error analysis. Without these, the quantitative gains cannot be verified as robust.
Authors: We acknowledge that greater detail is needed for reproducibility. In the revised manuscript we will augment Section 5.1 with: (i) the regulator’s training procedure, loss, architecture, and hyper-parameters; (ii) precise implementation notes for each baseline, including any tuning performed to ensure fair comparison; (iii) all metrics reported as mean ± standard deviation over five independent random seeds; and (iv) error bars or confidence intervals on the values in Table 2. These additions will allow readers to assess the robustness of the reported gains. revision: yes
Circularity Check
Modular regulator trained independently shows no circular derivation
full rationale
The paper presents a modular cost-aware regulator whose training objective (minimize constraint violations while avoiding degenerate suppression) is stated separately from the main policy's reward maximization in SAC/TD3. No equations or derivations are exhibited that reduce a claimed prediction or first-principles result to a fitted input by construction. The integration claim is presented as an engineering composition rather than a mathematical reduction, and no self-citation load-bearing uniqueness theorems or ansatzes are invoked in the provided text. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Predicted constraint violations from state-action pairs are sufficiently accurate to guide effective action scaling.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
regulator network ρθ(s, a,ĉ) ... Lreg = E[β·Qc(st,˜at) − λ·logρθ(st,at,ĉ)] ... element-wise scaling ˜at=ρt⊙at
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
integrates seamlessly with off-policy RL methods such as SAC and TD3 ... return-to-cost ratios on Safety Gym locomotion tasks
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al., “Human-level control through deep reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015
work page 2015
-
[2]
Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates,
S. Gu, E. Holly, T. Lillicrap, and S. Levine, “Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates,” in2017 IEEE international conference on robotics and automation (ICRA). IEEE, 2017, pp. 3389–3396
work page 2017
-
[3]
Daydreamer: World models for physical robot learning,
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and K. Goldberg, “Daydreamer: World models for physical robot learning,” inConference on robot learning. PMLR, 2023, pp. 2226–2240
work page 2023
-
[4]
Mastering the game of go without human knowledge,
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton,et al., “Mastering the game of go without human knowledge,”nature, vol. 550, no. 7676, pp. 354–359, 2017
work page 2017
-
[5]
Grandmaster level in starcraft II using multi-agent reinforcement learning,
O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. H. Choi, R. Powell, T. Ewalds, P. Georgiev,et al., “Grandmaster level in starcraft II using multi-agent reinforcement learning,”nature, vol. 575, no. 7782, pp. 350–354, 2019
work page 2019
-
[6]
Concrete Problems in AI Safety
D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Mané, “Concrete problems in AI safety,”arXiv preprint arXiv:1606.06565, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
A comprehensive survey on safe reinforcement learning,
J. Garcıa and F. Fernández, “A comprehensive survey on safe reinforcement learning,”Journal of Machine Learning Research, vol. 16, no. 1, pp. 1437–1480, 2015
work page 2015
-
[8]
Control barrier functions: Theory and applications,
A. D. Ames, S. Coogan, M. Egerstedt, G. Notomista, K. Sreenath, and P. Tabuada, “Control barrier functions: Theory and applications,” in2019 18th European control conference (ECC). Ieee, 2019, pp. 3420–3431
work page 2019
-
[9]
B. Dai, R. Khorrambakht, P. Krishnamurthy, V . Gonçalves, A. Tzes, and F. Khorrami, “Safe navigation and obstacle avoidance using differentiable optimization based control barrier functions,”IEEE Robotics and Automation Letters, vol. 8, no. 9, pp. 5376–5383, 2023
work page 2023
-
[10]
Z. Zhang, S. Han, J. Wang, and F. Miao, “Spatial-temporal-aware safe multi-agent reinforcement learning of connected autonomous vehicles in challenging scenarios,” inProc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), 2023, pp. 5574–5580
work page 2023
-
[11]
Dynamic model predictive shielding for provably safe reinforcement learning,
A. Banerjee, K. Rahmani, J. Biswas, and I. Dillig, “Dynamic model predictive shielding for provably safe reinforcement learning,”arXiv preprint arXiv:2405.13863, 2024
-
[12]
Safe multi-agent reinforcement learning for behavior- based cooperative navigation,
M. Dawood, S. Pan, N. Dengler, S. Zhou, A. P. Schoellig, and M. Bennewitz, “Safe multi-agent reinforcement learning for behavior- based cooperative navigation,”IEEE Robotics and Automation Letters, 2025
work page 2025
-
[13]
Exploring under constraints with model-based actor-critic and safety filters,
A. Agha, B. Kayalibay, A. Mirchev, P. van der Smagt, and J. Bayer, “Exploring under constraints with model-based actor-critic and safety filters,” in8th Annual Conference on Robot Learning, 2024
work page 2024
-
[14]
Constrained policy optimization,
J. Achiam, D. Held, A. Tamar, and P. Abbeel, “Constrained policy optimization,” inInternational conference on machine learning. PMLR, 2017, pp. 22–31
work page 2017
-
[15]
Reward Constrained Policy Optimization
C. Tessler, D. J. Mankowitz, and S. Mannor, “Reward constrained policy optimization,”arXiv preprint arXiv:1805.11074, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Benchmarking Batch Deep Reinforcement Learning Algorithms
A. Ray, J. Achiam, and D. Amodei, “Benchmarking safe exploration in deep reinforcement learning,”arXiv preprint arXiv:1910.01708, vol. 7, no. 1, p. 2, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[17]
Responsive safety in reinforce- ment learning by PID lagrangian methods,
A. Stooke, J. Achiam, and P. Abbeel, “Responsive safety in reinforce- ment learning by PID lagrangian methods,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 9133–9143
work page 2020
-
[18]
Sauté rl: Almost surely safe reinforcement learning using state augmentation,
A. Sootla, A. I. Cowen-Rivers, T. Jafferjee, Z. Wang, D. H. Mguni, J. Wang, and H. Ammar, “Sauté rl: Almost surely safe reinforcement learning using state augmentation,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 20 423–20 443
work page 2022
-
[19]
Enhancing safe exploration using safety state augmentation,
A. Sootla, A. Cowen-Rivers, J. Wang, and H. Bou Ammar, “Enhancing safe exploration using safety state augmentation,”Advances in Neural Information Processing Systems, vol. 35, pp. 34 464–34 477, 2022
work page 2022
-
[20]
Multi-task learning as a bargaining game,
A. Navon, A. Shamsian, I. Achituve, H. Maron, K. Kawaguchi, G. Chechik, and E. Fetaya, “Multi-task learning as a bargaining game,” arXiv preprint arXiv:2202.01017, 2022
-
[21]
Safety gymnasium: A unified safe reinforcement learning benchmark,
J. Ji, B. Zhang, J. Zhou, X. Pan, W. Huang, R. Sun, Y . Geng, Y . Zhong, J. Dai, and Y . Yang, “Safety gymnasium: A unified safe reinforcement learning benchmark,”Advances in Neural Information Processing Systems, vol. 36, pp. 18 964–18 993, 2023
work page 2023
-
[22]
Reinforce- ment learning with adaptive regularization for safe control of critical systems,
H. Tian, H. Hamedmoghadam, R. Shorten, and P. Ferraro, “Reinforce- ment learning with adaptive regularization for safe control of critical systems,”arXiv preprint arXiv:2404.15199, 2024
-
[23]
Recovery rl: Safe reinforcement learning with learned recovery zones,
B. Thananjeyan, A. Balakrishna, S. Nair, M. Luo, K. Srinivasan, M. Hwang, J. E. Gonzalez, J. Ibarz, C. Finn, and K. Goldberg, “Recovery rl: Safe reinforcement learning with learned recovery zones,” IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 4915–4922, 2021
work page 2021
-
[24]
Towards safe reinforcement learning with a safety editor policy,
H. Yu, W. Xu, and H. Zhang, “Towards safe reinforcement learning with a safety editor policy,”Advances in Neural Information Processing Systems, vol. 35, pp. 2608–2621, 2022
work page 2022
-
[25]
Iterative reachability estimation for safe reinforcement learning,
M. Ganai, Z. Gong, C. Yu, S. Herbert, and S. Gao, “Iterative reachability estimation for safe reinforcement learning,”Advances in Neural Information Processing Systems, vol. 36, pp. 69 764–69 797, 2023
work page 2023
-
[26]
Spectral- risk safe reinforcement learning with convergence guarantees,
D. Kim, T. Cho, S. Han, H. Chung, K. Lee, and S. Oh, “Spectral- risk safe reinforcement learning with convergence guarantees,”arXiv preprint arXiv:2405.18698, 2024
-
[27]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational conference on machine learning. Pmlr, 2018, pp. 1861–1870
work page 2018
-
[28]
Addressing function approxi- mation error in actor-critic methods,
S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approxi- mation error in actor-critic methods,” inInternational conference on machine learning. PMLR, 2018, pp. 1587–1596
work page 2018
-
[29]
Safe exploration for optimization with gaussian processes,
Y . Sui, A. Gotovos, J. Burdick, and A. Krause, “Safe exploration for optimization with gaussian processes,” inInternational Conference on Machine Learning. PMLR, 2015, pp. 997–1005
work page 2015
-
[30]
Safe Exploration in Continuous Action Spaces
G. Dalal, K. Dvijotham, M. Vecerik, T. Hester, C. Paduraru, and Y . Tassa, “Safe exploration in continuous action spaces,”arXiv preprint arXiv:1801.08757, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Safe deep reinforcement learning for multi-agent systems with continuous action spaces,
Z. Sheebaelhamd, K. Zisis, A. Nisioti, D. Gkouletsos, D. Pavllo, and J. Kohler, “Safe deep reinforcement learning for multi-agent systems with continuous action spaces,”arXiv preprint arXiv:2108.03952, 2021
-
[32]
A. W. Goodall and F. Belardinelli, “Leveraging approximate model- based shielding for probabilistic safety guarantees in continuous environments,”arXiv preprint arXiv:2402.00816, 2024
-
[33]
Safe reinforcement learning using black-box reachability analysis,
M. Selim, A. Alanwar, S. Kousik, G. Gao, M. Pavone, and K. H. Johansson, “Safe reinforcement learning using black-box reachability analysis,”IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 10 665–10 672, 2022
work page 2022
-
[34]
Safe reinforcement learning with dead-ends avoidance and recovery,
X. Zhang, H. Zhang, H. Zhou, C. Huang, D. Zhang, C. Ye, and J. Zhao, “Safe reinforcement learning with dead-ends avoidance and recovery,” IEEE Robotics and Automation Letters, vol. 9, no. 1, pp. 491–498, 2023
work page 2023
-
[35]
CVaR-constrained policy optimization for safe reinforcement learning,
Q. Zhang, S. Leng, X. Ma, Q. Liu, X. Wang, B. Liang, Y . Liu, and J. Yang, “CVaR-constrained policy optimization for safe reinforcement learning,”IEEE Transactions on Neural Networks and Learning Systems, 2024
work page 2024
-
[36]
Constraint-conditioned policy optimization for versatile safe reinforce- ment learning,
Y . Yao, Z. Liu, Z. Cen, J. Zhu, W. Yu, T. Zhang, and D. Zhao, “Constraint-conditioned policy optimization for versatile safe reinforce- ment learning,”Advances in Neural Information Processing Systems, vol. 36, pp. 12 555–12 568, 2023
work page 2023
-
[37]
Altman,Constrained Markov decision processes
E. Altman,Constrained Markov decision processes. Routledge, 2021
work page 2021
-
[38]
R. S. Sutton, A. G. Barto,et al.,Reinforcement learning: An introduction. MIT press Cambridge, 1998, vol. 1
work page 1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.