GOAT: A Training Framework for Goal-Oriented Agent with Tools
Pith reviewed 2026-05-18 07:41 UTC · model grok-4.3
The pith
GOAT lets smaller open-source LLMs learn complex tool use by synthesizing training data automatically from API documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GOAT is a training framework that enables fine-tuning of LLM agents for complex tool use without human annotation by automatically synthesizing goal-oriented API execution data from API documents through a novel call-first generation paradigm that constructs training examples based on executed API call sequences, yielding state-of-the-art performance on multiple existing goal-oriented benchmarks as well as on the newly introduced GOATBench.
What carries the argument
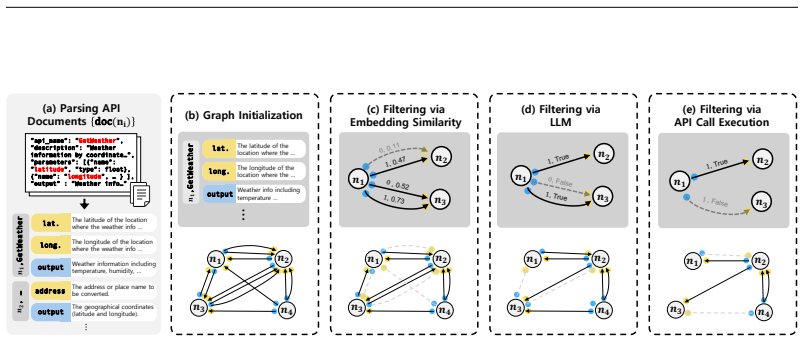
The call-first generation paradigm, which constructs training data based on executed API call sequences derived directly from API documents.
If this is right
- GOAT-trained agents achieve state-of-the-art performance across multiple existing goal-oriented benchmarks.
- Agents trained with GOAT also excel on the new GOATBench benchmark.
- This supplies a practical path to building robust open-source LLM agents capable of complex reasoning and tool use.
- Fine-tuning for goal-oriented API execution becomes possible without requiring human-annotated data.
Where Pith is reading between the lines
- The method could lower dependence on proprietary models for creating effective tool-using agents if API documentation is available.
- Similar synthesis techniques might extend to other agent domains where documentation exists but labeled interaction data does not.
- Domain-specific agents could be customized more readily by feeding in targeted API documents rather than general training sets.
Load-bearing premise
The automatically synthesized goal-oriented API execution data generated from API documents is of high enough quality, accuracy, and diversity to train models effectively for real-world complex tool use.
What would settle it
Testing GOAT-trained agents on APIs whose documentation is incomplete or whose execution outcomes deviate from the synthesized sequences, resulting in performance that collapses to levels seen in zero-shot baselines.
Figures




















read the original abstract
Current approaches rely on zero-shot evaluation due to the absence of training data; while proprietary models such as GPT-4 exhibit strong reasoning capabilities, smaller open-source models remain ineffective at complex tool use. To address this limitation, we propose a novel training framework GOAT, that enables fine-tuning LLM agents without human annotation. GOAT automatically synthesizes goal-oriented API execution data from API documents using a novel call-first generation paradigm, that constructs training data based on executed API call sequences. Through extensive experiments, we show that GOAT-trained agents achieve state-of-the-art performance across multiple existing goal-oriented benchmarks. In addition, we introduce GOATBench, a new goal-oriented API execution benchmark, and demonstrate that agents trained with GOAT also excel in this setting. These results highlight GOAT as a practical path toward building robust open-source LLM agents capable of complex reasoning and tool use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GOAT, a training framework that enables fine-tuning of LLM agents for goal-oriented tool use without human annotation. It automatically synthesizes training data from API documents via a novel call-first generation paradigm that constructs sequences based on executed API calls. The authors report that GOAT-trained agents achieve state-of-the-art performance on multiple existing goal-oriented benchmarks, and they introduce GOATBench as a new benchmark where GOAT agents also excel.
Significance. If the synthetic data is shown to be accurate and diverse, and if the reported gains are reproducible with proper baselines and error analysis, the work would offer a practical route to training capable open-source agents for complex tool use, reducing dependence on proprietary models and manual data collection.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The SOTA claim is asserted without any reported metrics, baselines, statistical significance tests, or error analysis in the abstract and is only partially detailed in the experiments section; this makes the central performance claim impossible to assess and is load-bearing for the paper's main contribution.
- [§3] §3 (Method, call-first paradigm): No quantitative validation is provided for the automatically synthesized data (e.g., human-verified correctness rate, coverage of parameter-binding edge cases, or comparison against real execution traces). Systematic errors in goal alignment or API ordering could produce spurious gains that do not generalize, directly undermining the claim that GOAT enables effective training for real-world tool use.
minor comments (2)
- [§2] §2 (Related Work): The discussion of prior tool-use benchmarks could include more recent open-source efforts for completeness.
- [Figure 2 and §3.2] Figure 2 and §3.2: The diagram of the call-first pipeline would benefit from explicit notation for the goal-to-sequence mapping to improve clarity.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestions. We address each major comment below and outline the revisions we plan to make to improve the clarity and rigor of the paper.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The SOTA claim is asserted without any reported metrics, baselines, statistical significance tests, or error analysis in the abstract and is only partially detailed in the experiments section; this makes the central performance claim impossible to assess and is load-bearing for the paper's main contribution.
Authors: We agree with the referee that the abstract should explicitly report key metrics to substantiate the state-of-the-art claim. In the revised version, we will modify the abstract to include specific performance numbers, such as the success rates achieved by GOAT-trained agents versus baselines on the benchmarks. For the experiments section, we will enhance the presentation by adding statistical significance tests (e.g., paired t-tests) and more detailed error analysis to make the results more robust and assessable. These changes will ensure the central claims are fully supported. revision: yes
-
Referee: [§3] §3 (Method, call-first paradigm): No quantitative validation is provided for the automatically synthesized data (e.g., human-verified correctness rate, coverage of parameter-binding edge cases, or comparison against real execution traces). Systematic errors in goal alignment or API ordering could produce spurious gains that do not generalize, directly undermining the claim that GOAT enables effective training for real-world tool use.
Authors: The referee raises a valid point regarding the need for quantitative validation of the synthesized data. Although the call-first generation paradigm inherently ties the data to executed API calls to promote correctness and goal alignment, we recognize that additional validation would strengthen the work. We will revise §3 to include a quantitative analysis: specifically, we will report the results of human verification on a subset of the generated trajectories, including correctness rates for goal alignment and parameter binding. We will also discuss coverage of edge cases and provide comparisons to real-world execution traces where available. This addition will address concerns about potential systematic errors. revision: yes
Circularity Check
No circularity: empirical pipeline from external API docs to benchmark evaluation
full rationale
The paper describes an automated data synthesis process that starts from external API documents and applies a call-first generation paradigm to produce training sequences. These sequences are then used to fine-tune agents, which are evaluated on separate existing goal-oriented benchmarks plus a newly introduced GOATBench. No equations, fitted parameters, or first-principles derivations are shown that reduce to their own inputs by construction. No self-citations are invoked to justify uniqueness or load-bearing premises. The central performance claims rest on experimental outcomes rather than logical equivalence to the synthesis assumptions, satisfying the criteria for a self-contained empirical result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can reliably interpret API documentation to generate valid and goal-oriented call sequences for data synthesis.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GOAT automatically synthesizes goal-oriented API execution data from API documents using a novel call-first generation paradigm... constructs training data based on executed API call sequences.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a novel training framework GOAT... Through extensive experiments, we show that GOAT-trained agents achieve state-of-the-art performance across multiple existing goal-oriented benchmarks.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
Provide a clear semantic description of what each input parameter and output of the API function represents
-
[3]
There can be multiple input parameters, including both required and optional parameters
-
[4]
If there are no required or optional parameters, return empty array for input parameter description. Output Format: - You must return a dictionary with the keys "input_params" and "output". - "input_params": Return an array of semantic descriptions for each input parameter. If there is None, return empty array. - "output": Return a semantic description fo...
-
[5]
API1 Document: A dictionary containing the details of API1’s output
-
[6]
API1 Semantic Descriptions: Natural language explanations of API1’s output
-
[7]
API2 Document: A dictionary containing the details of API2’s input
-
[8]
API2 Semantic Descriptions: Natural language explanations of API2’s input. Your task is to:
-
[9]
Analyze the semantic descriptions and the provided API documents to determine if API1’s output can be used as API2’s input
-
[10]
Return True only if the information in the output of API1 can be used as a valid input for API2
-
[11]
Do not return True when input of API1 can be reused in API2
-
[12]
Explain why the APIs are connectable or not. Output Format: - You must return a dictionary with the keys "connectable" and "reason". - "connectable": Return True only if API1’s output can be used as API2’s input, otherwise return False. - "reason": Provide a clear explanation describing why the APIs can or cannot be connected. ONLY return the dictionary a...
-
[15]
Populate the API function’s required parameters and optional parameters with appropriate values, ensuring that all required parameters are included and match the correct data types. Output Format: - You must return a dictionary where each parameter name is the key, and the parameter value is the value of the dictionary. - Ensure each parameter value has t...
-
[16]
API Document: A dictionary containing information about an API function, including parameter names, data types, and descriptions
-
[17]
API Call Results: The result of one or more previous API function calls
-
[18]
Reason: An array explaining how the API Call Results can be used to populate the parameters for the current API call. Your task is to:
-
[20]
Populate the API function’s required and optional parameters using the following rules: - First, use values justified by the API Call Results and the Reason array. - If a parameter cannot be filled this way, infer it using the information in the API Document (e.g., parameter descriptions or type hints)
-
[21]
Ensure all parameter values match the correct data types as specified in the API Document. Output Format: - Return a dictionary where each key is a parameter name and the value is the parameter’s value. - If no parameters can be populated from the available information, return an empty dictionary. ONLY return the parameter dictionary as your output. DO NO...
-
[22]
api_result: A result from the first API call
-
[23]
llm_result: Parameters and their values for calling next API. Your task is to:
-
[24]
Analyze the contents of api_result to determine if it was used as input in llm_result
-
[25]
Provide an explanation about whether or not the first API result influenced the parameters of the next API call. Output Format: - You must return a dictionary with the keys "connectable" and "reason". - "connectable": Return True if api_result was used in llm_result, otherwise return False. - "reason": Provide a clear explanation describing why api_result...
-
[26]
API Document: A dictionary containing information about an API function, with details. Your task is to:
-
[27]
Create a fictional scenario where you need to use the API
-
[28]
Populate the API function’s required parameters and optional parameters with appropriate values, ensuring that all required parameters are included and match the correct data types. Output Format: - Return a dictionary where each parameter name is the key, and the parameter value is the value of the dictionary. - Ensure each parameter value has the correc...
-
[29]
It should be used solely to understand the API and identify its required and optional parameters
‘API Document‘: This key provides information about an API function, including its details. It should be used solely to understand the API and identify its required and optional parameters. - **Important:** Do not use any values from the ‘API Document‘ directly to populate parameters for the API call
-
[30]
This is used to reference parameters by their indices
‘Parameter Dictionary‘: This key contains a dictionary where each key is a parameter index, and each value is the corresponding parameter name. This is used to reference parameters by their indices
-
[31]
‘Parameter Value‘: This key contains a dictionary that maps each parameter index to a dictionary detailing how to obtain the parameter’s value based on previous API call results: - Each value includes: - ‘docid‘: The unique ID of the document from which the parameter value is derived. This ‘docid‘ corresponds directly to a ‘docid‘ in the ‘Previous Result‘...
-
[32]
‘Previous Result‘: This key contains a dictionary of results from previous API function calls. Each key is a ‘docid‘ that corresponds to a previous API call, and each value contains the results returned by that call. The ‘docid‘ used here matches the ‘docid‘ referenced in the ‘Parameter Value‘. ### Your task is to follow these steps:
-
[33]
**Identify Parameter Names**: - Use the ‘Parameter Dictionary‘ to reference the names of parameters using their indices provided in the ‘Parameter Value‘
-
[34]
**Extract Parameter Values**: - For each parameter identified, use its index to find the corresponding ‘docid‘ and ‘reason‘ in the ‘Parameter Value‘. - Locate the specific data in ‘Previous Result‘ based on the ‘docid‘ and ensure the data matches the reasons and conditions for use. - The results from ‘Previous Result‘ (API1) will be applied to the paramet...
-
[35]
- Populate only those parameters that are explicitly mentioned in the ‘Parameter Value‘
**Populate the Dictionary**: - Create a dictionary where each parameter name (from the ‘Parameter Dictionary‘) is the key, and the extracted value from ‘Previous Result‘ is the corresponding value. - Populate only those parameters that are explicitly mentioned in the ‘Parameter Value‘. Exclude all others. - **DO NOT use any default values or other values ...
-
[36]
**Validate and Output**: - Confirm that all parameters listed in the ‘Parameter Value‘ are properly populated without using default or unrelated values from the ‘API Document‘. - Return a dictionary where each parameter name is the key and the parameter value is the value of the dictionary. - If no parameters can be properly populated using the provided d...
-
[37]
‘API Document‘: A dictionary containing information about the API function, including its details, required parameters, optional parameters, and their respective default values
-
[38]
‘Partially Filled Parameters‘: A dictionary where some parameters have already been populated, but others are still missing. Your task is to:
-
[39]
Review the ‘API Document‘ to identify which parameters (required and optional) are still missing from the ‘Partially Filled Parameters‘ dictionary
-
[40]
Use your judgment to select realistic and suitable values
Populate the missing parameters based on the following rules: - Fill in missing parameters with appropriate values that align with the parameter descriptions in the ‘API Document‘. Use your judgment to select realistic and suitable values. - Ensure all required parameters are included with appropriate values. - Optional parameters can remain unfilled if n...
-
[41]
Ensure that all parameter values match the correct data types specified in the ‘API Document‘. Output Format: - Return a dictionary where each parameter name is the key, and the parameter value is the value of the dictionary. - The dictionary must include all required parameters (filled with appropriate values) and may include optional parameters (if fill...
-
[42]
’API Document’: A structured description of the API, including its purpose, required and optional parameters, and any relevant context about its functionality
-
[43]
You must generate language instruction that enables execution of this call
’API call’: A dictionary of specific parameter values intended for execution of the API call. You must generate language instruction that enables execution of this call
-
[44]
Some values in ’API call’ references values in this result
’Previous API Response’: The output or result from preceding API calls. Some values in ’API call’ references values in this result. If this is empty, it should not be referenced. ### Your task is to follow these steps:
-
[45]
- Classify keys into two groups: a
** Classify Parameters in ’API call’: - For each key in ’API call’, check if its value can be directly derived from the ’Previous API Response’. - Classify keys into two groups: a. Derived Parameters: Parameters whose values are obtained from the ’Previous API Response’. b. Fixed Parameters: Parameters with values that are not contained in ’Previous API Response’
-
[46]
** Generate Language Instruction: - Generate a clear and concise language instruction that enables the execution of the ’API call’. - Use the ’API Document’ to understand the intent of the ’API call’ and ensure that the generated instruction aligns with its goal. The instruction must be goal-oriented, actionable, and contextually accurate. - Incorporate t...
-
[47]
Infer the broader purpose by analyzing how these subinstructions connect logically and build upon each other’s results
-
[48]
Synthesize them into one natural, user-friendly query that preserves crucial details and dependencies but does not mention the subinstructions themselves
-
[49]
Represent information at a high level wherever possible, but retain all specific details (e.g., IDs, names, dates) from the **first subinstruction** exactly as they are
-
[50]
For subinstructions after the first one, prioritize connecting them through context (e.g., "first video," "latest episode") rather than using specific identifiers unless absolutely necessary
-
[51]
Ensure that every subinstruction meaningfully contributes to the final query, preventing any extraneous or unaligned steps
-
[52]
thought": A short explanation of how you derived the final query from the subinstructions. -
Avoid any technical language or references to specific APIs in the final query. ### Guidelines: - Include all essential identifiers or conditions (e.g., names, dates, relevant context) from the subinstructions. Do not omit or generalize key details from the **first subinstruction**. - For subsequent subinstructions, derive necessary information from the r...
-
[53]
’User Query’: A natural language question or request from the user
-
[54]
Each dictionary contains: - ’subinstruction’: A brief description of the step taken
’API Call Result’: A list of dictionaries, each representing a step or subinstruction carried out to fulfill the user query. Each dictionary contains: - ’subinstruction’: A brief description of the step taken. - ’api response’: The actual data or result obtained from executing the subinstruction. ### Your task is to follow these steps:
-
[55]
** Analyze API Call Result: ** - Examine each dictionary in the ’API Call Result’ list. - Understand the purpose of each ’subinstruction’ and the corresponding ’api response.’ - Identify how each ’api response’ contributes to answering the ’User Query.’ - If necessary, combine results from multiple subinstructions to generate a comprehensive answer
-
[56]
** Generate Final Answer: ** - Construct a coherent and natural response to the ’User Query’ based on the collected information from ’API Call Result.’ - Use clear and concise language, phrasing the answer in a way that feels conversational and human-like. - Ensure the final response directly addresses the user’s request without unnecessary detail. - Summ...
- [57]
- [58]
-
[59]
Only if the answer is fully based on tool results **and** correctly answers all aspects of the query, return "Solved". No "Unsure" status is allowed. Output format: { "content": "<Step-by-step reasoning and explanation>", "answer_status": "Solved" | "Unsolved" } Figure 21:Prompt used for success rate metric. 32
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.