Unsupervised Monocular Road Segmentation for Autonomous Driving via Scene Geometry
Pith reviewed 2026-05-18 06:32 UTC · model grok-4.3
The pith
Unsupervised road segmentation reaches 0.86 IoU on Cityscapes by using geometric priors and temporal consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
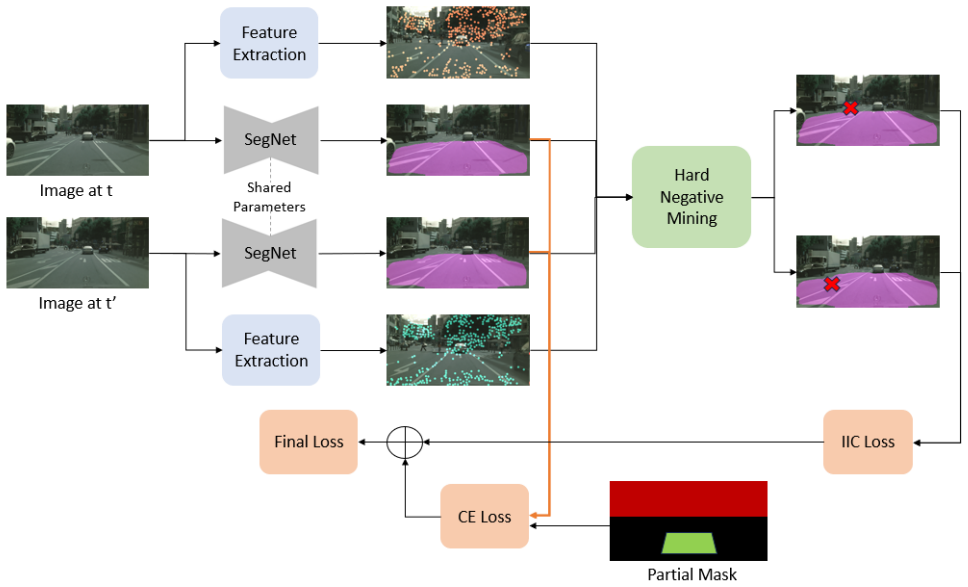
The paper establishes that binary road segmentation can be performed without manual annotations by first creating weak labels from geometric priors—pixels above the horizon line as non-road and a predefined quadrilateral in front of the vehicle as road—and subsequently refining these labels through a temporal consistency stage that tracks local feature points across frames and penalizes inconsistent assignments via mutual information maximization, ultimately achieving an IoU of 0.86 on Cityscapes and outperforming prior unsupervised methods.
What carries the argument
The two-stage pipeline of geometric weak label generation followed by temporal refinement using mutual information maximization on tracked feature points.
If this is right
- The approach removes the need for costly manually labeled datasets in road segmentation for autonomous driving.
- Geometric constraints and temporal cues together produce more precise and stable segmentations than competing unsupervised techniques.
- The method works with standard monocular cameras, supporting scalable deployment without extra hardware.
- Refinement via mutual information maximization enhances both accuracy and frame-to-frame label stability.
Where Pith is reading between the lines
- If the initial geometric assumptions hold across diverse environments, this could generalize to other unsupervised scene understanding tasks like lane detection.
- Extending the temporal consistency to longer sequences or incorporating additional cues like optical flow might further improve performance on challenging conditions.
- The fixed quadrilateral prior may require adaptation for different camera mounts or vehicle types to avoid introducing bias.
- Integration with other unsupervised methods could lead to hybrid systems that bootstrap from geometry before applying learned models.
Load-bearing premise
The predefined quadrilateral in front of the vehicle is always road and the horizon is always non-road in a way that does not create uncorrectable errors in the initial labels.
What would settle it
A dataset or sequence where the fixed front quadrilateral frequently includes non-road areas such as sidewalks or where horizon estimation is inaccurate, resulting in final IoU significantly below 0.86 even after refinement.
Figures


read the original abstract
This paper presents a fully unsupervised approach for binary road segmentation (road vs. non-road), eliminating the reliance on costly manually labeled datasets. The method leverages scene geometry and temporal cues to distinguish road from non-road regions. Weak labels are first generated from geometric priors, marking pixels above the horizon as non-road and a predefined quadrilateral in front of the vehicle as road. In a refinement stage, temporal consistency is enforced by tracking local feature points across frames and penalizing inconsistent label assignments using mutual information maximization. This enhances both precision and temporal stability. On the Cityscapes dataset, the model achieves an Intersection-over-Union (IoU) of 0.86, outperforming the competing unsupervised methods. These findings demonstrate the potential of combining geometric constraints and temporal consistency for scalable unsupervised road segmentation in autonomous driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a fully unsupervised binary road segmentation method for monocular images in autonomous driving. It first generates weak labels via fixed geometric priors (a predefined quadrilateral ahead of the vehicle labeled as road and pixels above the horizon labeled as non-road), then refines these labels by tracking local features across frames and maximizing mutual information to enforce temporal consistency. The central empirical claim is an IoU of 0.86 on Cityscapes that outperforms prior unsupervised baselines.
Significance. If the temporal refinement demonstrably corrects systematic mismatches introduced by the initial priors rather than reinforcing them, the work would offer a practical route to scalable road segmentation without manual labels. The combination of external geometric assumptions with a standard mutual-information objective is straightforward, but its value hinges on whether the reported performance gain is attributable to the method or to the strength of the priors themselves.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the reported IoU of 0.86 is presented without error bars, confidence intervals, or statistical tests against baselines, and no ablation isolating the temporal mutual-information term from the geometric priors alone is provided; this leaves the outperformance claim without the quantitative support needed to evaluate robustness.
- [Method] Method section (weak-label generation): the paper does not describe how the quadrilateral and horizon parameters are chosen or validated across scenes (fixed vs. per-frame adaptation), nor does it quantify how often these priors produce incorrect initial labels (e.g., quadrilateral overlapping sidewalks or parked cars) or demonstrate that the subsequent refinement corrects rather than propagates those errors.
minor comments (2)
- Add a clear statement of the exact Cityscapes split and evaluation protocol used for the IoU metric.
- Figure captions should explicitly indicate whether visualized outputs are before or after the temporal refinement stage.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the reported IoU of 0.86 is presented without error bars, confidence intervals, or statistical tests against baselines, and no ablation isolating the temporal mutual-information term from the geometric priors alone is provided; this leaves the outperformance claim without the quantitative support needed to evaluate robustness.
Authors: We agree that error bars and an ablation study would provide stronger quantitative support for the claims. In the revised manuscript, we will report the IoU of 0.86 along with standard deviations computed across multiple runs on different Cityscapes splits. We will also add an ablation experiment that evaluates performance using only the geometric priors versus the full method with temporal feature tracking and mutual information maximization, to isolate the contribution of the refinement stage. revision: yes
-
Referee: [Method] Method section (weak-label generation): the paper does not describe how the quadrilateral and horizon parameters are chosen or validated across scenes (fixed vs. per-frame adaptation), nor does it quantify how often these priors produce incorrect initial labels (e.g., quadrilateral overlapping sidewalks or parked cars) or demonstrate that the subsequent refinement corrects rather than propagates those errors.
Authors: We agree that additional details on the weak-label generation are needed. We will revise the Method section to clarify that the horizon is determined from a fixed vanishing-point assumption calibrated to the Cityscapes camera setup and that the quadrilateral is a fixed region in the lower image center, selected to approximate the forward road area. We will include a sensitivity analysis for these fixed parameters and add qualitative examples illustrating initial label errors (such as overlaps with sidewalks) along with corresponding outputs after temporal refinement to show error correction. A full per-scene error quantification would require additional manual annotations beyond the scope of the current unsupervised setting, but the added examples and ablation will help demonstrate that refinement improves rather than propagates errors. revision: partial
Circularity Check
No significant circularity; derivation relies on external priors and independent evaluation
full rationale
The paper generates initial weak labels from fixed geometric priors (predefined quadrilateral ahead of the vehicle as road and horizon line as non-road) and refines them via a standard mutual-information temporal consistency term on tracked features. These steps use scene assumptions external to the target metric and are evaluated against independent Cityscapes ground-truth labels for the reported 0.86 IoU. No equations or claims reduce the final result to a fit on the evaluation data, no self-citation chain is load-bearing for the core method, and the approach remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pixels above the horizon line are always non-road and a fixed quadrilateral directly ahead of the vehicle is always road.
- domain assumption Local feature points tracked across frames belong to the same semantic class and therefore should receive consistent labels.
Reference graph
Works this paper leans on
-
[1]
Deepcut: Unsupervised segmentation using graph neural networks clustering
Amit Aflalo, Shai Bagon, Tamar Kashti, and Yonina El- dar. Deepcut: Unsupervised segmentation using graph neural networks clustering. InICCV, pages 32–41, 2023. 2
work page 2023
-
[2]
Dong Bao, Jun Zhou, Gervase Tuxworth, Jue Zhang, and Yongsheng Gao. Hierarchical context learning of object components for unsupervised semantic segmentation.Pat- tern Recognition, 167:111713, 2025. 2
work page 2025
-
[3]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In ICCV, pages 9650–9660, 2021. 2
work page 2021
-
[4]
Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolu- tion, and fully connected crfs.IEEE TPAMI, 40(4):834–848,
-
[5]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InCVPR, pages 3213–3223, 2016. 2, 4
work page 2016
-
[6]
Unsupervised semantic seg- mentation by contrasting object mask proposals
Wouter Van Gansbeke, Simon Vandenhende, Stamatios Georgoulis, and Luc Van Gool. Unsupervised semantic seg- mentation by contrasting object mask proposals. InICCV, pages 10052–10062, 2021. 2
work page 2021
- [7]
-
[8]
Infoseg: Unsuper- vised semantic image segmentation with mutual information maximization
Robert Harb and Patrick Kn ¨obelreiter. Infoseg: Unsuper- vised semantic image segmentation with mutual information maximization. InDAGM German Conference on Pattern Recognition, pages 18–32, 2021. 2
work page 2021
-
[9]
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V . Le, and Hartwig Adam. Searching for mobilenetv3. InICCV, pages 1314– 1324, 2019. 4
work page 2019
-
[10]
Dongbo Huang, Hui Wang, Yuqian Zhao, Feifei Guo, Fan Zhang, Pei Chen, Chunhua Yang, and Weihua Gui. Weakly supervised free-space segmentation by fusing spatial priors and region features for auto-driving.Multimedia Systems, 31(4):273. 2
-
[11]
Xu Ji, Joao F. Henriques, and Andrea Vedaldi. Invariant information clustering for unsupervised image classification and segmentation. InICCV, pages 9865–9874, 2019. 2, 3, 4
work page 2019
-
[12]
Weakly supervised semantic segmentation for driving scenes
Dongseob Kim, Seungho Lee, Junsuk Choe, and Hyunjung Shim. Weakly supervised semantic segmentation for driving scenes. InProceedings of the AAAI Conference on Artificial Intelligence, pages 2741–2749, 2024. 2
work page 2024
-
[13]
Jiyoung Kim, Kyuhong Shim, Insu Lee, and Byonghyo Shim. Expand-and-quantize: unsupervised semantic seg- 6 mentation using high-dimensional space and product quan- tization. InAAAI, pages 2768–2776, 2024. 2
work page 2024
-
[14]
Unsupervised video object seg- mentation via prototype memory network
Minhyeok Lee, Suhwan Cho, Seunghoon Lee, Chaewon Park, and Sangyoun Lee. Unsupervised video object seg- mentation via prototype memory network. InWACV, pages 5924–5934, 2023. 2
work page 2023
-
[15]
Ac- seg: Adaptive conceptualization for unsupervised semantic segmentation
Kehan Li, Zhennan Wang, Zesen Cheng, Runyi Yu, Yian Zhao, Guoli Song, Chang Liu, Li Yuan, and Jie Chen. Ac- seg: Adaptive conceptualization for unsupervised semantic segmentation. InCVPR, pages 7162–7172, 2023. 2
work page 2023
-
[16]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, pages 740–755, 2014. 5
work page 2014
-
[17]
Fully convolutional networks for semantic segmentation
Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In CVPR, pages 3431–3440, 2015. 1
work page 2015
-
[18]
Deep super- pixel cut for unsupervised image segmentation
Qinghong Lin; Weichan Zhong; Jianglin Lu. Deep super- pixel cut for unsupervised image segmentation. InICPR, pages 8870–8876, 2020. 2
work page 2020
-
[19]
An iterative image reg- istration technique with an application to stereo vision
Bruce D Lucas and Takeo Kanade. An iterative image reg- istration technique with an application to stereo vision. In IJCAI’81: 7th international joint conference on Artificial in- telligence, pages 674–679, 1981. 4
work page 1981
-
[20]
Luke Melas-Kyriazi, Christian Rupprecht, Iro Laina, and Andrea Vedaldi. Deep spectral methods: A surprisingly strong baseline for unsupervised semantic segmentation and localization. InCVPR, pages 8364–8375, 2022. 2
work page 2022
-
[21]
Autore- gressive unsupervised image segmentation
Yassine Ouali, C ´eline Hudelot, and Myriam Tami. Autore- gressive unsupervised image segmentation. InECCV, pages 142–158, 2020. 2
work page 2020
-
[22]
Hierarchical feature align- ment network for unsupervised video object segmentation
Gensheng Pei, Fumin Shen, Yazhou Yao, Guo-Sen Xie, Zhenmin Tang, and Jinhui Tang. Hierarchical feature align- ment network for unsupervised video object segmentation. InECCV, pages 596–613, 2022. 2
work page 2022
-
[23]
Reciprocal transformations for unsupervised video object segmentation
Sucheng Ren, Wenxi Liu, Yongtuo Liu, Haoxin Chen, Guo- qiang Han, and Shengfeng He. Reciprocal transformations for unsupervised video object segmentation. InCVPR, pages 15455–15464, 2021. 2
work page 2021
-
[24]
Refining weakly- supervised free space estimation through data augmentation and recursive training
Franc ¸ois Robinet and Rapha ¨el Frank. Refining weakly- supervised free space estimation through data augmentation and recursive training. InArtificial Intelligence and Machine Learning, pages 30–45, 2022. 2
work page 2022
-
[25]
Weakly-supervised free space estimation through stochastic co-teaching
Franc ¸ois Robinet, Claudia Parera, Christian Hundt, and Rapha¨el Frank. Weakly-supervised free space estimation through stochastic co-teaching. InWACV, pages 618–627,
-
[26]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMICCAI, pages 234–241, 2015. 1
work page 2015
-
[27]
Leveraging hidden positives for unsupervised semantic segmentation
Hyun Seok Seong, WonJun Moon, SuBeen Lee, and Jae-Pil Heo. Leveraging hidden positives for unsupervised semantic segmentation. InCVPR, pages 19540–19549, 2023. 2
work page 2023
-
[28]
Jianbo Shi and Carlo Tomasi. Good features to track. In 1994 Proceedings of IEEE conference on computer vision and pattern recognition, pages 593–600, 1994. 4
work page 1994
-
[29]
Unsupervised semantic segmentation through depth-guided feature correlation and sampling
Leon Sick, Dominik Engel, Pedro Hermosilla, and Timo Ropinski. Unsupervised semantic segmentation through depth-guided feature correlation and sampling. InCVPR, pages 3637–3646, 2024. 2
work page 2024
-
[30]
Fodvid: flow-guided object discovery in videos.arXiv preprint arXiv:2307.04392, 2023
Silky Singh, Shripad Deshmukh, Mausoom Sarkar, Rishabh Jain, Mayur Hemani, and Balaji Krishnamurthy. Fodvid: flow-guided object discovery in videos.arXiv preprint arXiv:2307.04392, 2023. 2
- [31]
-
[32]
Drive & segment: Unsupervised semantic segmentation of urban scenes via cross-modal distillation
Antonin V obecky, David Hurych, Oriane Sim ´eoni, Spyros Gidaris, Andrei Bursuc, Patrick P´erez, and Josef Sivic. Drive & segment: Unsupervised semantic segmentation of urban scenes via cross-modal distillation. InECCV, pages 478– 495, 2022. 2
work page 2022
-
[33]
Wenguan Wang, Hongmei Song, Shuyang Zhao, Jianbing Shen, Sanyuan Zhao, Steven C. H. Hoi, and Haibin Ling. Learning unsupervised video object segmentation through visual attention. InCVPR, pages 3064–3074, 2019. 2
work page 2019
-
[34]
Crowley, and Dominique Vaufreydaz
Yangtao Wang, Xi Shen, Shell Xu Hu, Yuan Yuan, James L. Crowley, and Dominique Vaufreydaz. Self-supervised trans- formers for unsupervised object discovery using normalized cut. InCVPR, pages 14543–14553, 2022. 2
work page 2022
-
[35]
Lu Xiong, Yongkun Wen, Yuyao Huang, Junqiao Zhao, and Wei Tian. Joint unsupervised learning of depth, pose, ground normal vector and ground segmentation by a monocular camera sensor.Sensors, 20(13):3737, 2020. 2, 5
work page 2020
-
[36]
Transfgu: A top-down ap- proach to fine-grained unsupervised semantic segmentation
Zhaoyuan Yin, Pichao Wang, Fan Wang, Xianzhe Xu, Han- ling Zhang, Hao Li, and Rong Jin. Transfgu: A top-down ap- proach to fine-grained unsupervised semantic segmentation. InECCV, pages 73–89, 2022. 2
work page 2022
-
[37]
Yunzhi Zhuge, Hongyu Gu, Lu Zhang, Jinqing Qi, and Huchuan Lu. Learning motion and temporal cues for unsu- pervised video object segmentation.IEEE Transactions on Neural Networks and Learning Systems, 36(5):9084–9097,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.