DeepDetect: Learning All-in-One Dense Keypoints
Pith reviewed 2026-05-18 05:55 UTC · model grok-4.3
The pith
DeepDetect trains a lightweight network on fused outputs from classical detectors to generate dense semantically focused keypoints that adapt to challenging scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DeepDetect creates ground-truth masks by fusing outputs of seven keypoint and two edge detectors, then trains the ESPNet model on these masks to produce highly dense keypoints that focus on semantic content and remain adaptable to diverse and visually degraded conditions.
What carries the argument
Fusion of outputs from seven keypoint detectors and two edge detectors into semantic ground-truth masks used as labels to train ESPNet for dense keypoint prediction.
Load-bearing premise
That fusing outputs from multiple classical detectors produces reliable semantic ground-truth masks enabling the trained model to generalize across diverse and degraded scenes.
What would settle it
A new test dataset with photometric degradations or scene types absent from the fused training masks where DeepDetect shows lower density or repeatability than baseline detectors.
Figures





read the original abstract
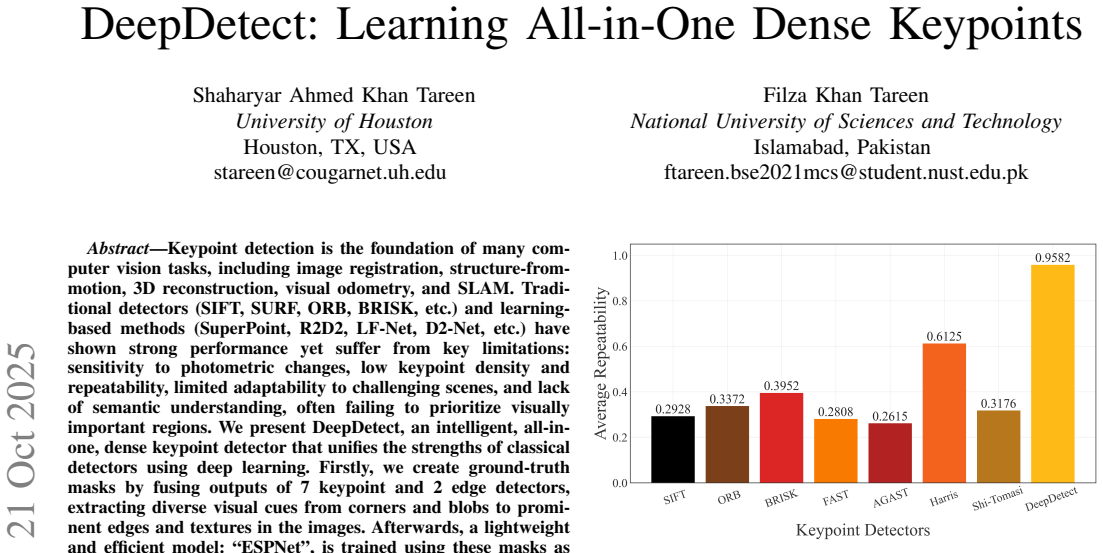
Keypoint detection is the foundation of many computer vision tasks, including image registration, structure-from-motion, 3D reconstruction, visual odometry, and SLAM. Traditional detectors (SIFT, ORB, BRISK, FAST, etc.) and learning-based methods (SuperPoint, R2D2, QuadNet, LIFT, etc.) have shown strong performance gains yet suffer from key limitations: sensitivity to photometric changes, low keypoint density and repeatability, limited adaptability to challenging scenes, and lack of semantic understanding, often failing to prioritize visually important regions. We present DeepDetect, an intelligent, all-in-one, dense detector that unifies the strengths of classical detectors using deep learning. Firstly, we create ground-truth masks by fusing outputs of 7 keypoint and 2 edge detectors, extracting diverse visual cues from corners and blobs to prominent edges and textures in the images. Afterwards, a lightweight and efficient model: ESPNet, is trained using fused masks as labels, enabling DeepDetect to focus semantically on images while producing highly dense keypoints, that are adaptable to diverse and visually degraded conditions. Evaluations on Oxford, HPatches, and Middlebury datasets demonstrate that DeepDetect surpasses other detectors achieving maximum values of 0.5143 (average keypoint density), 0.9582 (average repeatability), 338,118 (correct matches), and 842,045 (voxels in stereo 3D reconstruction).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce DeepDetect, an all-in-one dense keypoint detector. It first creates ground-truth masks by fusing outputs from seven keypoint detectors and two edge detectors to extract diverse visual cues from corners, blobs, edges, and textures. These masks then supervise training of the lightweight ESPNet model so that the detector learns to prioritize semantically important regions, yielding highly dense and repeatable keypoints that generalize to diverse and visually degraded scenes. Evaluations on the Oxford, HPatches, and Middlebury datasets are reported to surpass prior detectors, with peak values of 0.5143 (average keypoint density), 0.9582 (average repeatability), 338118 correct matches, and 842045 voxels in stereo 3D reconstruction.
Significance. If the central claims are substantiated, the work would offer a practical route to dense, semantically informed keypoint detection by distilling classical detector responses into a single learned model. The choice of a lightweight ESPNet backbone is a positive efficiency consideration for downstream tasks such as SfM and SLAM. The reported gains in density and reconstruction voxels address acknowledged weaknesses of both hand-crafted and earlier learned detectors. However, the absence of a reproducible fusion procedure and supporting experimental controls limits the strength of these conclusions.
major comments (2)
- Method section (ground-truth mask creation): the procedure for fusing the outputs of the seven keypoint detectors and two edge detectors is not specified (union, majority vote, weighted combination, scale normalization, or post-processing). This detail is load-bearing for the claim that the resulting masks supply reliable semantic supervision rather than simply increasing label density; without it, the reported improvements in density (0.5143) and repeatability (0.9582) could be explained by label statistics alone.
- Experimental section and abstract: the superiority claims rest on maximum reported values (0.5143 density, 0.9582 repeatability, 338118 correct matches, 842045 reconstruction voxels) yet no ablation studies, training hyperparameters, loss formulation, statistical significance tests, or comparison protocol against the same baselines are provided. These omissions directly affect verifiability of the central performance assertions.
minor comments (2)
- Abstract: the phrase 'fusing outputs' should be expanded with at least a one-sentence description of the combination rule to orient readers before they reach the method section.
- Notation and metrics: ensure that 'average keypoint density' and 'average repeatability' are defined with explicit formulas or citations to the standard definitions used on Oxford and HPatches.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: Method section (ground-truth mask creation): the procedure for fusing the outputs of the seven keypoint detectors and two edge detectors is not specified (union, majority vote, weighted combination, scale normalization, or post-processing). This detail is load-bearing for the claim that the resulting masks supply reliable semantic supervision rather than simply increasing label density; without it, the reported improvements in density (0.5143) and repeatability (0.9582) could be explained by label statistics alone.
Authors: We agree that the fusion procedure requires explicit specification for reproducibility and to support the claim of semantic supervision. The original manuscript described the process only at a high level. We will revise the Method section to provide a complete, reproducible description of the fusion, including the combination rule, any normalization or scaling applied to detector outputs, thresholds, and post-processing steps. This addition will clarify that the masks are not merely denser but are constructed to aggregate diverse visual cues. revision: yes
-
Referee: Experimental section and abstract: the superiority claims rest on maximum reported values (0.5143 density, 0.9582 repeatability, 338118 correct matches, 842045 reconstruction voxels) yet no ablation studies, training hyperparameters, loss formulation, statistical significance tests, or comparison protocol against the same baselines are provided. These omissions directly affect verifiability of the central performance assertions.
Authors: We acknowledge that reporting peak values without accompanying details reduces verifiability. We will expand the Experimental section to include ablation studies (e.g., on the effect of fusing different numbers of detectors), the full set of training hyperparameters, the loss formulation used to supervise the ESPNet model, statistical significance testing against baselines, and an explicit description of the evaluation protocol ensuring consistent comparison settings. Where space permits, we will also report means and variances in addition to the maximum values. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a standard supervised distillation pipeline: classical detectors are run to produce fused masks that serve as training labels for ESPNet, after which the learned model is evaluated on held-out benchmark datasets (Oxford, HPatches, Middlebury). No equations, fitted parameters, or predictions are shown to reduce by construction to the same inputs; the central claim that the trained model generalizes to degraded scenes rests on empirical results rather than any self-referential definition or self-citation load-bearing step. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fused outputs from classical keypoint and edge detectors constitute reliable semantic ground truth for training a dense detector.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We create ground-truth masks by fusing outputs of 7 keypoint and 2 edge detectors... ESPNet is trained using fused masks as labels
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
achieving maximum values of 0.5143 (average keypoint density), 0.9582 (average repeatability)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A performance evaluation of local descriptors,
K. Mikolajczyk and C. Schmid, “A performance evaluation of local descriptors,”IEEE transactions on pattern analysis and machine intel- ligence, vol. 27, no. 10, pp. 1615–1630, 2005
work page 2005
-
[2]
Toward robust pedestrian detection with data augmentation,
S. Cygert and A. Czy ˙zewski, “Toward robust pedestrian detection with data augmentation,”IEEE Access, vol. 8, pp. 136 674–136 683, 2020
work page 2020
-
[3]
Automatic panoramic image stitching using invariant features,
M. Brown and D. G. Lowe, “Automatic panoramic image stitching using invariant features,”International journal of computer vision, vol. 74, no. 1, pp. 59–73, 2007
work page 2007
-
[4]
Detection of interest points in turbid underwater images,
R. Garcia and N. Gracias, “Detection of interest points in turbid underwater images,” inOCEANS 2011 IEEE-Spain. IEEE, 2011, pp. 1–9
work page 2011
-
[5]
Visual odometry for planetary exploration rovers in sandy terrains,
L. Li, J. Lian, L. Guo, and R. Wang, “Visual odometry for planetary exploration rovers in sandy terrains,”International Journal of Advanced Robotic Systems, vol. 10, no. 5, p. 234, 2013
work page 2013
-
[6]
Present and future of slam in extreme underground environments,
K. Ebadi, L. Bernreiter, H. Biggie, G. Catt, Y . Chang, A. Chatterjee, C. E. Denniston, S.-P. Deschˆenes, K. Harlow, S. Khattaket al., “Present and future of slam in extreme underground environments,”arXiv preprint arXiv:2208.01787, 2022
-
[7]
A comparative analysis of sift, surf, kaze, akaze, orb, and brisk,
S. A. K. Tareen and Z. Saleem, “A comparative analysis of sift, surf, kaze, akaze, orb, and brisk,” in2018 International conference on computing, mathematics and engineering technologies (iCoMET). IEEE, 2018, pp. 1–10
work page 2018
-
[8]
S. A. K. Tareen and R. H. Raza, “Potential of sift, surf, kaze, akaze, orb, brisk, agast, and 7 more algorithms for matching extremely variant image pairs,” in2023 4th International Conference on Computing, Mathematics and Engineering Technologies (iCoMET). IEEE, 2023, pp. 1–6
work page 2023
-
[9]
A comparison of sift, pca-sift and surf,
L. Juan and O. Gwun, “A comparison of sift, pca-sift and surf,” International Journal of Image Processing (IJIP), vol. 3, no. 4, pp. 143– 152, 2009
work page 2009
-
[10]
Image Matching Using SIFT, SURF, BRIEF and ORB: Performance Comparison for Distorted Images
E. Karami, S. Prasad, and M. Shehata, “Image matching using sift, surf, brief and orb: performance comparison for distorted images,”arXiv preprint arXiv:1710.02726, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Affine covariant regions datasets,
V . G. Group, “Affine covariant regions datasets,” http://www.robots.ox. ac.uk/∼vgg/data, 2004, accessed: Aug. 14, 2025
work page 2004
-
[12]
Distinctive image features from scale-invariant keypoints,
D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” International journal of computer vision, vol. 60, no. 2, pp. 91–110, 2004
work page 2004
-
[13]
M. A. Fischler and R. C. Bolles, “Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography,”Communications of the ACM, vol. 24, no. 6, pp. 381–395, 1981
work page 1981
-
[14]
Matching with prosac-progressive sample consensus,
O. Chum and J. Matas, “Matching with prosac-progressive sample consensus,” in2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05), vol. 1. IEEE, 2005, pp. 220–226
work page 2005
-
[15]
Superpoint: Self- supervised interest point detection and description,
D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Self- supervised interest point detection and description,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2018, pp. 224–236
work page 2018
-
[16]
R2d2: Reliable and repeatable detector and descriptor,
J. Revaud, C. De Souza, M. Humenberger, and P. Weinzaepfel, “R2d2: Reliable and repeatable detector and descriptor,”Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[17]
Lf-net: Learning local features from images,
Y . Ono, E. Trulls, P. Fua, and K. M. Yi, “Lf-net: Learning local features from images,”Advances in neural information processing systems, vol. 31, 2018
work page 2018
-
[18]
D2-net: A trainable cnn for joint description and detection of local features,
M. Dusmanu, I. Rocco, T. Pajdla, M. Pollefeys, J. Sivic, A. Torii, and T. Sattler, “D2-net: A trainable cnn for joint description and detection of local features,” inProceedings of the ieee/cvf conference on computer vision and pattern recognition, 2019, pp. 8092–8101
work page 2019
-
[19]
Speeded-up robust features (surf),
H. Bay, A. Ess, T. Tuytelaars, and L. Van Gool, “Speeded-up robust features (surf),”Computer vision and image understanding, vol. 110, no. 3, pp. 346–359, 2008
work page 2008
-
[20]
P. F. Alcantarilla, A. Bartoli, and A. J. Davison, “Kaze features,” in European conference on computer vision. Springer, 2012, pp. 214– 227
work page 2012
-
[21]
Orb: An efficient alternative to sift or surf,
E. Rublee, V . Rabaud, K. Konolige, and G. Bradski, “Orb: An efficient alternative to sift or surf,” in2011 International conference on computer vision. Ieee, 2011, pp. 2564–2571
work page 2011
-
[22]
Brisk: Binary robust invariant scalable keypoints,
S. Leutenegger, M. Chli, and R. Y . Siegwart, “Brisk: Binary robust invariant scalable keypoints,” in2011 International conference on com- puter vision. Ieee, 2011, pp. 2548–2555
work page 2011
-
[23]
Machine learning for high-speed corner detection,
E. Rosten and T. Drummond, “Machine learning for high-speed corner detection,” inEuropean conference on computer vision. Springer, 2006, pp. 430–443
work page 2006
-
[24]
Adaptive and generic corner detection based on the accelerated segment test,
E. Mair, G. D. Hager, D. Burschka, M. Suppa, and G. Hirzinger, “Adaptive and generic corner detection based on the accelerated segment test,” inEuropean conference on Computer vision. Springer, 2010, pp. 183–196
work page 2010
-
[25]
A computational approach to edge detection,
J. Canny, “A computational approach to edge detection,”IEEE Transac- tions on pattern analysis and machine intelligence, no. 6, pp. 679–698, 2009
work page 2009
-
[26]
Design of an image edge detection filter using the sobel operator,
N. Kanopoulos, N. Vasanthavada, and R. L. Baker, “Design of an image edge detection filter using the sobel operator,”IEEE Journal of solid- state circuits, vol. 23, no. 2, pp. 358–367, 1988
work page 1988
-
[27]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean conference on computer vision. Springer, 2014, pp. 740–755
work page 2014
-
[28]
Towards a simulation driven stereo vision system,
M. Peris, S. Martull, A. Maki, Y . Ohkawa, and K. Fukui, “Towards a simulation driven stereo vision system,” inProceedings of the 21st International Conference on Pattern Recognition (ICPR2012). IEEE, 2012, pp. 1038–1042
work page 2012
-
[29]
Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation,
S. Mehta, M. Rastegari, A. Caspi, L. Shapiro, and H. Hajishirzi, “Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation,” inProceedings of the european conference on computer vision (ECCV), 2018, pp. 552–568
work page 2018
-
[30]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inInternational Conference on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241
work page 2015
-
[31]
Pyramid scene parsing network,
H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2881–2890
work page 2017
-
[32]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems, vol. 32, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.