TokenCake: A KV-Cache-centric Serving Framework for LLM-based Multi-Agent Applications
Pith reviewed 2026-05-21 21:14 UTC · model grok-4.3
The pith
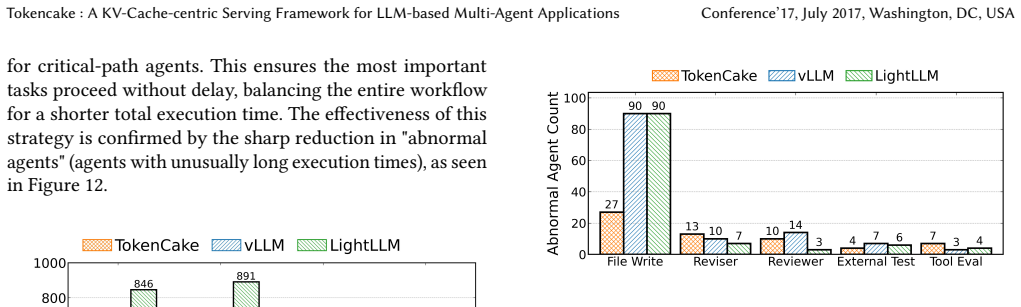
TokenCake reduces end-to-end latency in multi-agent LLM systems by more than 47 percent through proactive KV cache offloading and dynamic memory partitioning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TokenCake is a KV-cache-centric serving framework that co-optimizes scheduling and memory management for LLM multi-agent applications by employing an opportunistic temporal scheduler for proactive offloading during function calls and a spatial scheduler that uses dynamic partitioning guided by a hybrid priority metric to protect critical-path agents.
What carries the argument
The temporal scheduler's event-driven offload-and-predictive-upload policy combined with the spatial scheduler's hybrid priority metric that blends graph structure and runtime state to guide memory reservation.
If this is right
- End-to-end latency drops by over 47 percent on representative multi-agent benchmarks.
- Effective GPU memory utilization rises by up to 16.9 percent.
- Idle KV caches of stalled agents no longer occupy GPU memory during long external calls.
- Critical-path agents receive reserved memory blocks that reduce contention evictions.
Where Pith is reading between the lines
- The same offload-and-prioritize pattern could apply to other serving systems that mix compute with external I/O waits.
- If the hybrid priority metric generalizes, it might replace simpler FIFO or size-based eviction policies in future LLM runtimes.
- Workloads with many parallel short calls may need additional safeguards to avoid transfer overhead dominating the gains.
Load-bearing premise
Function-call durations must be long enough and predictable enough that proactive offloading and predictive uploading can hide transfer latency without creating new bottlenecks.
What would settle it
Running the same multi-agent benchmarks but with very short or highly variable function-call times and measuring whether end-to-end latency rises instead of falls compared with vLLM.
Figures











read the original abstract
Large Language Models (LLMs) are increasingly deployed in complex multi-agent applications that rely on external function calls. This workload creates severe performance challenges for the KV Cache: spatial contention leads to the eviction of critical agents' caches and temporal underutilization leaves the cache of agents stalled on long-running function calls idling in GPU memory. We present TokenCake, a KV-Cache-centric serving framework that bridges this gap by co-optimizing scheduling and memory management through an agent-aware design. TokenCake's Temporal Scheduler employs an event-driven, opportunistic policy to proactively offload idle KV Caches during function calls and uses predictive uploading to hide data transfer latency. TokenCake's Spatial Scheduler uses dynamic memory partitioning, guided by a hybrid priority metric combining graph structure and runtime state, to reserve GPU memory for critical-path agents. Our evaluation on representative multi-agent benchmarks shows that TokenCake reduces end-to-end latency by over 47.06% and improves effective GPU memory utilization by up to 16.9% compared to vLLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents TokenCake, a KV-cache-centric serving framework for LLM-based multi-agent applications. It proposes a Temporal Scheduler that uses event-driven opportunistic offloading of idle KV caches during function calls together with predictive uploading to hide PCIe transfer latency, and a Spatial Scheduler that performs dynamic GPU memory partitioning guided by a hybrid priority metric combining graph structure and runtime state. Evaluation on representative multi-agent benchmarks is reported to yield over 47.06% reduction in end-to-end latency and up to 16.9% improvement in effective GPU memory utilization relative to vLLM.
Significance. If the empirical results hold under varied workloads, the work would provide a practical advance in efficient serving for multi-agent LLM systems by jointly addressing spatial KV-cache contention and temporal underutilization during external function calls. The explicit co-design of scheduling and memory management around agent criticality is a focused contribution to the emerging area of multi-agent inference serving.
major comments (2)
- [Evaluation] Evaluation section: the central claim of 47.06% end-to-end latency reduction is presented without any reported distribution or statistics on function-call durations, the fraction of execution time spent inside calls versus generation, or sensitivity sweeps that vary call length. Because the Temporal Scheduler's net benefit depends on calls being sufficiently long and predictable to hide offload/upload round-trip cost, the absence of this workload characterization makes the quantitative result difficult to interpret or generalize.
- [§4.2] §4.2 (Temporal Scheduler): the predictive uploading policy is described as issuing uploads in advance, yet no accuracy metrics, false-positive overhead, or fallback behavior when predictions miss are provided. This is load-bearing for the latency claim, as incorrect predictions could introduce stalls or wasted bandwidth that offset the reported gains.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from a brief statement of the specific multi-agent benchmarks and the range of function-call durations observed in the evaluation.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight important aspects of workload characterization and policy details that will improve the clarity and interpretability of our results. We address each major comment below and have prepared revisions to incorporate the suggested additions.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central claim of 47.06% end-to-end latency reduction is presented without any reported distribution or statistics on function-call durations, the fraction of execution time spent inside calls versus generation, or sensitivity sweeps that vary call length. Because the Temporal Scheduler's net benefit depends on calls being sufficiently long and predictable to hide offload/upload round-trip cost, the absence of this workload characterization makes the quantitative result difficult to interpret or generalize.
Authors: We agree that additional workload characterization strengthens the interpretation of the latency results. In the revised manuscript we will add a dedicated subsection (and associated figure) to the Evaluation section that reports: (1) the empirical distribution of function-call durations observed in the benchmarks, (2) the fraction of total execution time spent inside calls versus token generation, and (3) a sensitivity sweep over call lengths. These data confirm that the reported gains remain consistent for the range of call durations typical in multi-agent workloads, because the event-driven offloading and predictive upload hide PCIe latency once calls exceed a modest threshold. revision: yes
-
Referee: [§4.2] §4.2 (Temporal Scheduler): the predictive uploading policy is described as issuing uploads in advance, yet no accuracy metrics, false-positive overhead, or fallback behavior when predictions miss are provided. This is load-bearing for the latency claim, as incorrect predictions could introduce stalls or wasted bandwidth that offset the reported gains.
Authors: We acknowledge that quantitative characterization of the predictive uploading policy was omitted. In the revised §4.2 we will add: prediction accuracy (fraction of correct advance uploads), measured false-positive overhead (extra PCIe bandwidth from unnecessary uploads), and the fallback behavior (immediate on-demand upload on a miss, which preserves correctness at the cost of a short stall). These metrics are derived from the same benchmark runs and will be reported to demonstrate that the net benefit of the policy is positive under realistic prediction error rates. revision: yes
Circularity Check
No circularity: empirical system evaluation with no derivation chain
full rationale
The paper describes a KV-cache serving framework with Temporal and Spatial Schedulers for multi-agent LLM workloads. Central claims consist of measured end-to-end latency reductions (47.06%) and GPU memory utilization gains (16.9%) obtained from benchmark runs against vLLM. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text; performance numbers are direct empirical outcomes rather than quantities defined in terms of the paper's own inputs. Assumptions about function-call duration and predictability are workload properties external to the framework and do not create self-referential loops. No self-citations, uniqueness theorems, or ansatzes are invoked to justify load-bearing steps. The derivation chain is therefore self-contained as a systems implementation plus measurement.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reduces end-to-end latency by over 47.06% and improves effective GPU memory utilization by up to 16.9%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
Hive: A Multi-Agent Infrastructure for Algorithm- and Task-Level Scaling
Hive is a multi-agent infrastructure with a logits cache for reducing cross-path redundancy in sampling and agent-aware scheduling for better compute and KV-cache allocation, shown to deliver 1.11x-1.76x speedups and ...
-
Scepsy: Serving Agentic Workflows Using Aggregate LLM Pipelines
Scepsy schedules arbitrary multi-LLM agentic workflows on GPU clusters by constructing Aggregate LLM Pipelines from stable per-LLM execution time shares, then searching fractional GPU allocations, tensor parallelism, ...
-
ForkKV: Scaling Multi-LoRA Agent Serving via Copy-on-Write Disaggregated KV Cache
ForkKV uses copy-on-write disaggregated KV cache with DualRadixTree and ResidualAttention kernels to deliver up to 3x throughput over prior multi-LoRA serving systems with negligible quality loss.
-
TokenDance: Scaling Multi-Agent LLM Serving via Collective KV Cache Sharing
TokenDance scales multi-agent LLM serving to 2.7x more concurrent agents by collective KV cache reuse and block-sparse diff encoding that achieves 11-17x compression.
Reference graph
Works this paper leans on
-
[1]
AlignmentLab AI. 2024. AgentCode: A dataset for code generated by LLM agents. Hugging Face Datasets.https://huggingface.co/datasets/ AlignmentLab-AI/agentcodeAccessed: 2025-09-01
work page 2024
-
[2]
anon8231489123. 2023. ShareGPT Vicuna Unfiltered. https://huggingface.co/datasets/anon8231489123/ShareGPT_ Vicuna_unfiltered.https://huggingface.co/datasets/anon8231489123/ ShareGPT_Vicuna_unfilteredHugging Face dataset
work page 2023
-
[3]
Anthropic, Inc. 2025.Model Context Protocol Specification.https: //spec.modelcontextprotocol.io/specification/2025-08-20/Accessed: 2025-08-20
work page 2025
-
[4]
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. 2024. Cost- efficient large language model serving for multi-turn conversations with CachedAttention. InProceedings of the 2024 USENIX Conference on Usenix Annual Technical Conference(Santa Clara, CA, USA)(USENIX ATC’24). USENIX Associatio...
work page 2024
-
[5]
Dawei Gao, Zitao Li, Xuchen Pan, Weirui Kuang, Zhijian Ma, Bingchen Qian, Fei Wei, Wenhao Zhang, Yuexiang Xie, Daoyuan Chen, Liuyi Yao, Hongyi Peng, Zeyu Zhang, Lin Zhu, Chen Cheng, Hongzhu Shi, Yaliang Li, Bolin Ding, and Jingren Zhou. 2024. AgentScope: A Flexible yet Robust Multi-Agent Platform. arXiv:2402.14034 [cs.MA]https: //arxiv.org/abs/2402.14034
-
[6]
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. MetaGPT: Meta Programming for A Multi- Agent Collaborative Framework. arXiv:2308.00352 [cs.AI]https: //arxiv.org/abs/2308.00352
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Sto- ica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Germany)(SOSP ’23). As- sociation for Computing Machinery, New Yor...
-
[8]
Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, and Lili Qiu. 2024. Parrot: Efficient Serving of LLM- based Applications with Semantic Variable. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA.https://www.usenix.org/conference/ osdi24/presentation/lin-chaofan
work page 2024
- [9]
-
[10]
Michael Luo, Xiaoxiang Shi, Colin Cai, Tianjun Zhang, Justin Wong, Yichuan Wang, Chi Wang, Yanping Huang, Zhifeng Chen, Joseph E. Gonzalez, and Ion Stoica. 2025. Autellix: An Efficient Serving Engine for LLM Agents as General Programs. arXiv:2502.13965 [cs.LG] https://arxiv.org/abs/2502.13965
-
[11]
Microsoft. 2023. Microsoft 365 Copilot. Web page.https: //www.microsoft.com/en-us/microsoft-365/enterprise/microsoft- 365-copilot
work page 2023
-
[12]
Jinghua Piao, Yuwei Yan, Jun Zhang, Nian Li, Junbo Yan, Xiaochong Lan, Zhihong Lu, Zhiheng Zheng, Jing Yi Wang, Di Zhou, Chen Gao, Fengli Xu, Fang Zhang, Ke Rong, Jun Su, and Yong Li. 2025. AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society. arXiv:2502.08691 [cs.SI]https://arxiv.org/a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [13]
- [14]
-
[15]
Google Gemini Team. 2025. Gemini Fullstack LangGraph Quick- start.https://github.com/google-gemini/gemini-fullstack-langgraph- quickstart. Accessed: 2025-09-23
work page 2025
-
[16]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Has- san Awadallah, Ryen W White, Doug Burger, and Chi Wang. 2023. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Con- versation. arXiv:2308.08155 [cs.AI]https://arxiv.org/abs/2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [17]
-
[18]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fu- sion. InProceedings of the Twentieth European Conference on Computer Systems. 94–109.https://doi.org/10.1145/3689031.3696098
- [19]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.