Recognition: 2 theorem links
· Lean TheoremTokenDance: Scaling Multi-Agent LLM Serving via Collective KV Cache Sharing
Pith reviewed 2026-05-13 17:58 UTC · model grok-4.3
The pith
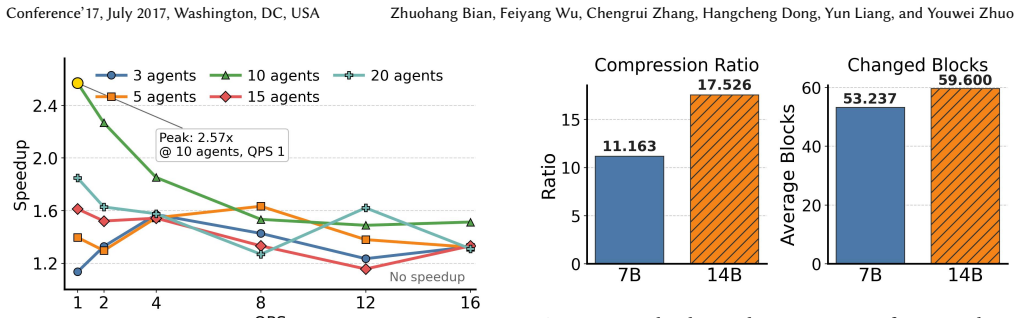
TokenDance enables multi-agent LLMs to run 2.7 times more concurrent agents by collectively reusing KV caches once per synchronization round.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TokenDance introduces a KV Collector that executes KV cache reuse across a full synchronization round in a single collective operation and a Diff-Aware Storage layer that represents sibling caches as block-sparse diffs against one master copy. On workloads drawn from GenerativeAgents and AgentSociety this yields up to 11-17x compression, supports 2.7x more concurrent agents than vLLM with prefix caching under SLO constraints, reduces per-agent storage by up to 17.5x, and delivers up to 1.9x prefill speedup relative to per-request position-independent caching.
What carries the argument
KV Collector performing one-step collective reuse over a synchronization round together with Diff-Aware Storage that encodes caches as block-sparse diffs from a master copy.
If this is right
- Supports up to 2.7 times more concurrent agents than vLLM with prefix caching while still meeting service-level objectives.
- Reduces per-agent KV cache storage by up to 17.5 times through differential encoding of sibling states.
- Delivers up to 1.9 times faster prefill compared with per-request position-independent caching.
- Applies directly to representative multi-agent workloads such as GenerativeAgents and AgentSociety.
Where Pith is reading between the lines
- The same collective-reuse idea could be applied to other LLM serving patterns that broadcast context among participants.
- Hardware or network-level collective primitives might further reduce the latency of the KV Collector step.
- Cache managers in future systems could be organized around group communication primitives rather than per-request decisions.
Load-bearing premise
The workloads must contain enough identical output blocks across agents in each round for collective reuse and differential encoding to deliver measurable compression and concurrency gains.
What would settle it
Measure the fraction of identical KV blocks across agents on a given workload; if the fraction drops near zero, the reported compression ratios, storage savings, and concurrency scaling should disappear.
Figures









read the original abstract
Multi-agent LLM applications organize execution in synchronized rounds where a central scheduler gathers outputs from all agents and redistributes the combined context. This All-Gather communication pattern creates massive KV Cache redundancy, because every agent's prompt contains the same shared output blocks, yet existing reuse methods fail to exploit it efficiently. We present TokenDance, a system that scales the number of concurrent agents by exploiting the All-Gather pattern for collective KV Cache sharing. TokenDance's KV Collector performs KV Cache reuse over the full round in one collective step, so the cost of reusing a shared block is paid once regardless of agent count. Its Diff-Aware Storage encodes sibling caches as block-sparse diffs against a single master copy, achieving 11-17x compression on representative workloads. Evaluation on GenerativeAgents and AgentSociety shows that TokenDance supports up to 2.7x more concurrent agents than vLLM with prefix caching under SLO requirement, reduces per-agent KV Cache storage by up to 17.5x, and achieves up to 1.9x prefill speedup over per-request position-independent caching.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents TokenDance, a system for scaling multi-agent LLM serving by exploiting the All-Gather communication pattern in synchronized multi-agent executions. It introduces a KV Collector for collective KV cache reuse across an entire round in one step and Diff-Aware Storage that encodes sibling agent caches as block-sparse diffs against a single master copy, claiming up to 2.7x more concurrent agents than vLLM with prefix caching under SLO constraints, up to 17.5x reduction in per-agent KV cache storage, and up to 1.9x prefill speedup on GenerativeAgents and AgentSociety workloads.
Significance. If the empirical gains prove robust, TokenDance addresses a timely bottleneck in distributed LLM serving for multi-agent applications by shifting from per-request to collective cache management. The reported compression and concurrency improvements could influence practical deployments where shared output blocks dominate, provided the workloads exhibit the assumed redundancy patterns.
major comments (2)
- [§5] §5 (Evaluation): The reported 2.7x concurrency, 17.5x storage reduction, and 1.9x speedup lack workload statistics (e.g., agent counts per round, output block similarity distributions, or round lengths) and ablation data separating KV Collector from Diff-Aware Storage contributions. This omission makes it impossible to verify the weakest assumption that the tested workloads contain sufficient identical blocks for the claimed gains.
- [§4.2] §4.2 (Diff-Aware Storage): The 11-17x compression ratio is presented without quantification of diff computation overhead or sensitivity to block divergence rates; an analysis showing how compression degrades as agent outputs diverge would be required to support generalizability beyond the specific GenerativeAgents and AgentSociety traces.
minor comments (2)
- [Abstract] Abstract: The 'up to' performance numbers are stated without reference to specific configurations or variance measures; adding a brief note on the conditions under which maxima occur would improve precision.
- [§3] §3: The description of block-sparse diff encoding would benefit from a small illustrative example or pseudocode showing how a sibling cache is reconstructed from the master plus diff.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate the suggested additions and clarifications in the revised version to strengthen the evaluation and analysis sections.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation): The reported 2.7x concurrency, 17.5x storage reduction, and 1.9x speedup lack workload statistics (e.g., agent counts per round, output block similarity distributions, or round lengths) and ablation data separating KV Collector from Diff-Aware Storage contributions. This omission makes it impossible to verify the weakest assumption that the tested workloads contain sufficient identical blocks for the claimed gains.
Authors: We agree that workload statistics and ablation studies are essential for verifying our assumptions. In the revised manuscript, we will expand §5 with detailed statistics including agent counts per round, output block similarity distributions (e.g., percentage of identical blocks across agents), and round lengths for both GenerativeAgents and AgentSociety workloads. We will also add ablation experiments that isolate the contributions of the KV Collector (collective reuse) and Diff-Aware Storage (block-sparse diffs). Our traces show high redundancy, with typically 75-85% identical blocks per round, which directly supports the reported gains; these data will be presented explicitly to allow independent verification. revision: yes
-
Referee: [§4.2] §4.2 (Diff-Aware Storage): The 11-17x compression ratio is presented without quantification of diff computation overhead or sensitivity to block divergence rates; an analysis showing how compression degrades as agent outputs diverge would be required to support generalizability beyond the specific GenerativeAgents and AgentSociety traces.
Authors: We acknowledge the value of quantifying overhead and divergence sensitivity for broader applicability. The revised §4.2 will include direct measurements of diff computation and encoding overhead (in both time and memory) as well as sensitivity analysis showing compression ratios as a function of block divergence rates. We will add plots demonstrating graceful degradation, with compression remaining above 9x even at 30% divergence levels observed in our traces. This analysis will clarify the limits and support generalizability claims. revision: yes
Circularity Check
No significant circularity in empirical systems claims
full rationale
The paper describes a systems implementation (KV Collector and Diff-Aware Storage) that exploits All-Gather redundancy in multi-agent workloads, with all reported gains (2.7x concurrency, 17.5x storage reduction, 1.9x prefill speedup) presented as measured outcomes from evaluation on GenerativeAgents and AgentSociety rather than as outputs of any derivation, equation, or fitted model. No self-definitional quantities, predictions that reduce to inputs by construction, or load-bearing self-citations of uniqueness theorems appear; the claims remain externally falsifiable via replication on the stated workloads.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TokenDance's KV Collector performs KV Cache reuse over the full round in one collective step... Diff-Aware Storage encodes sibling caches as block-sparse diffs against a single master copy
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
achieving 11-17x compression on representative workloads
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Token Economics for LLM Agents: A Dual-View Study from Computing and Economics
The paper delivers a unified survey of token economics for LLM agents, conceptualizing tokens as production factors, exchange mediums, and units of account across micro, meso, macro, and security dimensions using esta...
Reference graph
Works this paper leans on
-
[1]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ram- jee. 2024. Taming {Throughput-Latency} tradeoff in {LLM} inference with {Sarathi-Serve}. In18th USENIX symposium on operating systems design and implementation (OSDI 24). 117–134
work page 2024
- [2]
-
[3]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
-
[4]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems35 (2022), 16344–16359
work page 2022
- [5]
-
[6]
Shiwei Gao, Youmin Chen, and Jiwu Shu. 2025. Fast state restoration in llm serving with hcache. InProceedings of the Twentieth European Conference on Computer Systems. 128–143
work page 2025
- [7]
-
[8]
In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khan- delwal, and Lin Zhong. 2024. Prompt Cache: Modular Attention Reuse for Low-Latency Inference. InProceedings of Machine Learning and Systems, P. Gibbons, G. Pekhimenko, and C. De Sa (Eds.), Vol. 6. 12 TokenDance : Scaling Multi-Agent LLM Serving via Collective KV Cache Sharing Conference’17, J...
work page 2024
-
[9]
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. arXiv:2308.00352 [cs.AI]https://arxiv.org/ abs/2308.00352
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. 2024. KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol....
work page 2024
-
[11]
doi:10.52202/079017-0040
-
[12]
Junhao Hu, Wenrui Huang, Weidong Wang, Haoyi Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, and Tao Xie
- [13]
- [14]
-
[15]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[16]
InProceedings of the 29th symposium on operating systems principles
Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles. 611–626
-
[17]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. {InfiniGen}: Efficient generative inference of large language models with dynamic {KV} cache management. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 155–172
work page 2024
-
[18]
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023. CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society. InAdvances in Neural Information Processing Sys- tems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 51991– 52008.https://pro...
work page 2023
- [19]
-
[20]
Zhonghang Li, Long Xia, Lei Shi, Yong Xu, Dawei Yin, and Chao Huang
- [21]
-
[22]
Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, and Lili Qiu. 2024. Parrot: Efficient serving of {LLM-based} applications with semantic variable. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 929–945
work page 2024
-
[23]
Yuhan Liu, Yuyang Huang, Jiayi Yao, Shaoting Feng, Zhuohan Gu, Kuntai Du, Hanchen Li, Yihua Cheng, Junchen Jiang, Shan Lu, Madan Musuvathi, and Esha Choukse. 2025. DroidSpeak: KV Cache Sharing for Cross-LLM Communication and Multi-LLM Serving. arXiv:2411.02820 [cs.MA]https://arxiv.org/abs/2411.02820
-
[24]
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Anantha- narayanan, et al. 2024. Cachegen: Kv cache compression and streaming for fast large language model serving. InProceedings of the ACM SIG- COMM 2024 Conference. 38–56
work page 2024
-
[25]
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. 2023. Scissorhands: exploiting the persistence of importance hypothesis for LLM KV cache compression at test time. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA...
work page 2023
-
[26]
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen (Henry) Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. 2024. KIVI: a tuning- free asymmetric 2bit quantization for KV cache. InProceedings of the 41st International Conference on Machine Learning(Vienna, Austria) (ICML’24). JMLR.org, Article 1311, 13 pages
work page 2024
- [27]
-
[28]
moltbook. 2026. moltbook: The front page of the agent internet.https: //www.moltbook.com/. Website. Accessed: 2026-03-31
work page 2026
-
[29]
OpenClaw contributors. 2026. OpenClaw: Your own personal AI assistant. Any OS. Any Platform. The lobster way.https://github.com/ openclaw/openclaw. GitHub repository. Accessed: 2026-03-31
work page 2026
- [30]
-
[31]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Mor- ris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology. 1–22
work page 2023
-
[32]
Jinghua Piao, Yuwei Yan, Jun Zhang, Nian Li, Junbo Yan, Xiaochong Lan, Zhihong Lu, Zhiheng Zheng, Jing Yi Wang, Di Zhou, et al. 2025. Agentsociety: Large-scale simulation of llm-driven generative agents advances understanding of human behaviors and society. (2025)
work page 2025
-
[33]
Xavier Puig, Kevin Ra, Marko Boben, Jiaman Li, Tingwu Wang, Sanja Fidler, and Antonio Torralba. 2018. Virtualhome: Simulating house- hold activities via programs. InProceedings of the IEEE conference on computer vision and pattern recognition. 8494–8502
work page 2018
-
[34]
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2024. ChatDev: Communicative Agents for Software Development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, And...
-
[35]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Heyi Tang, Feng Ren, Teng Ma, Shangming Cai, Yineng Zhang, Mingxing Zhang, et al. 2024. Mooncake: A kvcache-centric disaggregated architecture for llm serv- ing.ACM Transactions on Storage(2024)
work page 2024
- [36]
-
[37]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Has- san Awadallah, Ryen W White, Doug Burger, and Chi Wang. 2023. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Con- versation. arXiv:2308.08155 [cs.AI]https://arxiv.org/abs/2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient Streaming Language Models with Attention Sinks. arXiv:2309.17453 [cs.CL]https://arxiv.org/abs/2309.17453
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [39]
-
[40]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. Cacheblend: 13 Conference’17, July 2017, Washington, DC, USA Zhuohang Bian, Feiyang Wu, Chengrui Zhang, Hangcheng Dong, Yun Liang, and Youwei Zhuo Fast large language model serving for rag with cached knowledge fusion. InProceedings of ...
work page 2025
- [41]
-
[42]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, et al. 2025. Flashinfer: Efficient and customizable attention engine for llm inference serving.Proceedings of Machine Learning and Systems7 (2025)
work page 2025
-
[43]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A distributed serving system for {Transformer-Based} generative models. In16th USENIX symposium on operating systems design and implementation (OSDI 22). 521–538
work page 2022
-
[44]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lian- min Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, Zhangyang "Atlas" Wang, and Beidi Chen. 2023. H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models. InAdvances in Neural Information Pro- cessing Systems, A. Oh, T. Naumann, A. Globerson...
work page 2023
-
[45]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. 2024. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems37 (2024), 62557–62583. 14
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.