CoRoVA: Compressed Representations for Vector-Augmented Code Completion
Pith reviewed 2026-05-18 04:36 UTC · model grok-4.3
The pith
CoRoVA trains a small projector to turn retrieved code contexts into a few single-token vectors that LLMs can use directly for better and faster completion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
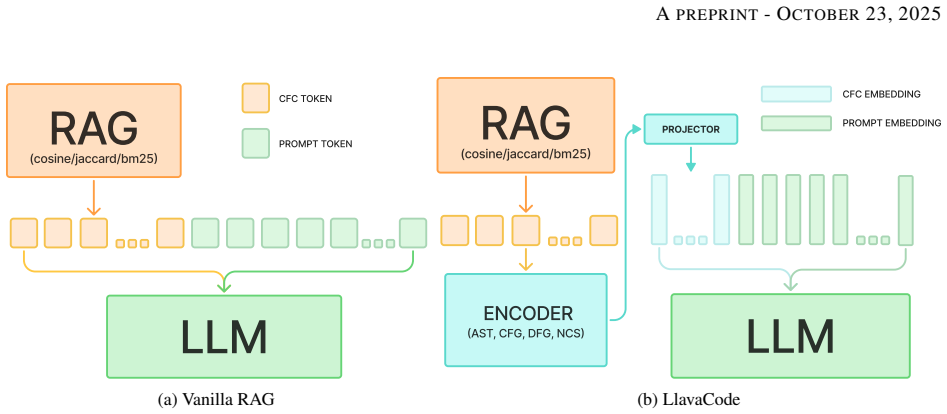
The central discovery is a framework called CoRoVA that compresses context into compact, semantically rich representations using a small projector module. These representations take the form of a few single-token vectors that remain interpretable to the base code LLM, allowing improved generation quality with significantly reduced sequence lengths and lower TTFT compared to standard RAG.
What carries the argument
The small projector module, which converts retrieved context into a fixed set of compact vector representations interpretable as single tokens by the code LLM.
If this is right
- Repository context can be incorporated without proportional increases in inference time.
- Interactive code completion in IDEs becomes more practical with RAG.
- Model quality improves without retraining the entire LLM.
- Prefill costs drop substantially for long-context tasks.
Where Pith is reading between the lines
- This method could be applied to non-code retrieval augmented tasks such as question answering.
- The number of compressed tokens might be tuned dynamically per query.
- It may enable use of larger retrieval sets than currently feasible.
Load-bearing premise
That the small projector can produce single-token vectors that remain semantically rich and interpretable to the base code LLM without critical loss of information from the original retrieved context.
What would settle it
If experiments on code completion tasks show that the compressed vectors result in lower accuracy or fail to reduce TTFT compared to uncompressed RAG, the claim would be falsified.
Figures



read the original abstract
Retrieval-augmented generation has emerged as one of the most effective approaches for code completion enhancement, especially when repository-level context is important. However, adding this extra retrieved context significantly increases sequence length, raises prefill cost, and degrades time-to-first-token (TTFT), which slows down inference -- a critical limitation for interactive settings such as IDEs. In this work, we introduce CoRoVA, a framework that compresses context into compact, semantically rich representations that remain interpretable to code LLMs. This improves generation quality while reducing prompt augmentation to only a few compressed single-token vectors. Our approach requires training only a small projector module and introduces negligible additional latency, yet it significantly improves the prediction quality of code LLMs. Our experiments show that CoRoVA enables a 20-38\% reduction in TTFT on completion tasks compared to uncompressed RAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CoRoVA, a framework that compresses long retrieved contexts for repository-level RAG in code completion into a small number of single-token vectors via a lightweight trained projector module. These vectors are fed to a frozen base code LLM, with the stated goals of reducing TTFT by 20-38% relative to uncompressed RAG while simultaneously improving generation quality and adding negligible latency.
Significance. If the central empirical claims hold, the work would be significant for practical deployment of context-augmented code models in interactive settings such as IDEs, where prefill latency is a primary bottleneck. Training only a small projector rather than the full LLM is a practical strength that could facilitate adoption.
major comments (2)
- [Abstract] Abstract: the headline claims of 20-38% TTFT reduction and quality improvement are presented without any visible experimental details, dataset descriptions, baseline implementations, number of runs, error bars, or statistical tests. This absence makes it impossible to evaluate whether the projector truly preserves semantic information or whether the reported gains are robust.
- [Method] Method / integration description: it is unclear how the compressed single-token vectors are inserted into the base LLM's input (position embeddings, type identifiers, or attention masking). If they are simply concatenated without the positional or segment information the model was pretrained to expect, the claimed quality improvement is at risk of being undermined by distribution shift even if TTFT is reduced.
minor comments (2)
- Ensure every figure and table is explicitly referenced in the main text and that captions are self-contained.
- Clarify the exact training objective used for the projector (reconstruction, contrastive, or end-to-end next-token prediction) and state whether any ablation on this choice was performed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential practical impact of CoRoVA for reducing prefill latency in interactive code completion. We address each major comment below with clarifications drawn from the manuscript and have revised the relevant sections to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims of 20-38% TTFT reduction and quality improvement are presented without any visible experimental details, dataset descriptions, baseline implementations, number of runs, error bars, or statistical tests. This absence makes it impossible to evaluate whether the projector truly preserves semantic information or whether the reported gains are robust.
Authors: We agree that the abstract, by design, presents high-level results without the full experimental protocol. The manuscript's Experiments section (Section 4) details the evaluation on repository-level code completion benchmarks, describes the uncompressed RAG baseline and other comparators, reports results over multiple runs with error bars, and includes statistical significance testing. To make this more accessible from the abstract, we have added a brief clause referencing the evaluation setup and directing readers to Section 4 for robustness details. This revision preserves abstract length while addressing the concern. revision: yes
-
Referee: [Method] Method / integration description: it is unclear how the compressed single-token vectors are inserted into the base LLM's input (position embeddings, type identifiers, or attention masking). If they are simply concatenated without the positional or segment information the model was pretrained to expect, the claimed quality improvement is at risk of being undermined by distribution shift even if TTFT is reduced.
Authors: We appreciate this observation and have clarified the integration in the revised Method section. The compressed vectors are prepended to the input sequence and assigned consecutive positional embeddings continuing from the original prompt tokens; no additional type or segment identifiers are introduced, as the projector is trained to produce representations compatible with the base model's embedding space. Full bidirectional attention is enabled between the compressed vectors and subsequent tokens via the standard attention mask. These details were present but have been expanded with explicit pseudocode and a diagram to eliminate ambiguity and confirm that distribution shift is mitigated by design. revision: yes
Circularity Check
No significant circularity; results are direct empirical comparisons
full rationale
The paper's central claims rest on training a small projector module and then measuring TTFT reduction (20-38%) and quality improvements via direct experimental comparison to uncompressed RAG baselines. No derivation, equation, or result reduces by construction to its own inputs, fitted parameters renamed as predictions, or self-citation chains. The approach is self-contained through standard training and evaluation against external baselines without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a LLaVA-like projection mechanism... trained without unfreezing of LLM, combined with reinforcement learning that directly optimizes EM and ES.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Cosine Alignment Loss... preserves pairwise cosine similarities
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive nlp tasks, 2021
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks, 2021
work page 2021
-
[2]
Flamingo: a visual language model for few-shot learning, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Ne- matzadeh, Sahand Sharifzadeh, Mikolaj Binkowsk...
work page 2022
-
[3]
Visual instruction tuning, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023
work page 2023
-
[4]
xrag: Extreme context compression for retrieval-augmented generation with one token, 2024
Xin Cheng, Xun Wang, Xingxing Zhang, Tao Ge, Si-Qing Chen, Furu Wei, Huishuai Zhang, and Dongyan Zhao. xrag: Extreme context compression for retrieval-augmented generation with one token, 2024
work page 2024
-
[5]
Starcoder: may the source be with you!, 2023
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, João Monteiro, Oleh Shliazhko, Nicolas Gontier, Nicholas Meade, Armel Zebaze, Ming-Ho Yee, Loge...
work page 2025
-
[6]
The stack: 3 tb of permissively licensed source code, 2022
Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, Dzmitry Bahdanau, Leandro von Werra, and Harm de Vries. The stack: 3 tb of permissively licensed source code, 2022
work page 2022
-
[7]
Qwen2.5- coder technical report, 2024
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. Qwen2.5- coder technical report, 2024
work page 2024
-
[8]
Efficiently scaling transformer inference, 2022
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Anselm Levskaya, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference, 2022
work page 2022
-
[9]
Gqa: Training generalized multi-query transformer models from multi-head checkpoints, 2023
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints, 2023
work page 2023
-
[10]
Qwen3 embedding: Advancing text embedding and reranking through foundation models, 2025
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models, 2025
work page 2025
-
[11]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page 2025
-
[12]
Mteb: Massive text embedding benchmark, 2023
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. Mteb: Massive text embedding benchmark, 2023
work page 2023
-
[13]
Graphcodebert: Pre-training code representations with data flow, 2021
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang, and Ming Zhou. Graphcodebert: Pre-training code representations with data flow, 2021
work page 2021
-
[14]
Unixcoder: Unified cross-modal pre-training for code representation, 2022
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. Unixcoder: Unified cross-modal pre-training for code representation, 2022
work page 2022
-
[15]
Rennie, Etienne Marcheret, Youssef Mroueh, Jarret Ross, and Vaibhava Goel
Steven J. Rennie, Etienne Marcheret, Youssef Mroueh, Jarret Ross, and Vaibhava Goel. Self-critical sequence training for image captioning, 2017
work page 2017
- [16]
-
[17]
Gaussian error linear units (gelus), 2023
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus), 2023
work page 2023
-
[18]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization, 2016
work page 2016
-
[19]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 4651–4664. PMLR, 18–24 Jul 2021
work page 2021
-
[20]
3dgraphllm: Combining semantic graphs and large language models for 3d scene understanding, 2025
Tatiana Zemskova and Dmitry Yudin. 3dgraphllm: Combining semantic graphs and large language models for 3d scene understanding, 2025
work page 2025
-
[21]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine ...
work page 2021
-
[22]
Scheduled sampling for sequence prediction with recurrent neural networks
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks. InProceedings of the 29th International Conference on Neural Information Processing Systems - Volume 1, NIPS’15, page 1171–1179, Cambridge, MA, USA, 2015. MIT Press
work page 2015
-
[23]
Sequence Level Training with Recurrent Neural Networks
Marc’Aurelio Ranzato, Sumit Chopra, Michael Auli, and Wojciech Zaremba. Sequence level training with recurrent neural networks.CoRR, abs/1511.06732, 2015. 10 APREPRINT- OCTOBER23, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[24]
Richard S. Sutton and Andrew G. Barto. Reinforsement learning: An introduction, adaptive computation and machine learning series. 1998
work page 1998
-
[25]
Optuna: A next-generation hyperparameter optimization framework, 2019
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework, 2019
work page 2019
-
[26]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[27]
{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 193–210, 2024
work page 2024
-
[28]
Taming{Throughput-Latency} tradeoff in {LLM} inference with {Sarathi- Serve}
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. Taming{Throughput-Latency} tradeoff in {LLM} inference with {Sarathi- Serve}. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 117–134, 2024
work page 2024
-
[29]
Revisiting slo and goodput metrics in llm serving.arXiv preprint arXiv:2410.14257, 2024
Zhibin Wang, Shipeng Li, Yuhang Zhou, Xue Li, Rong Gu, Nguyen Cam-Tu, Chen Tian, and Sheng Zhong. Revisiting slo and goodput metrics in llm serving.arXiv preprint arXiv:2410.14257, 2024
-
[30]
Transformers: State-of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, pages 38–45, 2020
work page 2020
-
[31]
Yuri Kuratov, Mikhail Arkhipov, Aydar Bulatov, and Mikhail Burtsev. Cramming 1568 tokens into a single vector and back again: Exploring the limits of embedding space capacity, 2025. A LLM usage statement We used ChatGPT-5 and ChatGPT-4o to correct grammatical and stylistic errors, condense text, perform translations and rephrase content. B Training Parame...
work page 2025
-
[32]
demonstrate that up to 1,568 tokens can be compressed into a single continuous "memory" token by treating the token as a trainable parameter and optimizing it via backpropagation with a cross-entropy reconstruction loss. Because these continuous tokens reconstruct to reference texts, we treat them as ground truth for training our projection layer. Concret...
work page 1976
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.