FELA: A Multi-Agent Evolutionary System for Feature Engineering of Industrial Event Log Data
Pith reviewed 2026-05-18 03:57 UTC · model grok-4.3
The pith
FELA uses multiple LLM agents to evolve explainable features from industrial event logs that improve model results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FELA integrates the reasoning and coding capabilities of large language models with an insight-guided self-evolution paradigm in which specialized agents generate, validate, and implement novel feature ideas, an Evaluation Agent summarizes feedback to update a hierarchical knowledge base and dual-memory system, and an agentic evolution algorithm balances exploration and exploitation to enable continual improvement on heterogeneous industrial event logs.
What carries the argument
The collaboration of Idea Agents, Code Agents, Critic Agents, and Evaluation Agent together with the agentic evolution algorithm that combines reinforcement learning and genetic algorithm principles to drive self-evolution across the space of feature ideas.
If this is right
- FELA produces explainable and domain-relevant features from complex event logs.
- Model performance improves on real industrial datasets with less manual feature work.
- The system handles large scale, high dimensionality, diverse data types, and temporal or relational structures.
- An agentic evolution process allows ongoing adaptation without rigid predefined operations.
- The overall setup offers a general framework for automated and interpretable feature engineering in real-world environments.
Where Pith is reading between the lines
- The same agent collaboration pattern could be tried on event data from non-industrial sources such as web analytics or sensor streams.
- Over many evolution cycles the system might surface feature combinations that human engineers overlook because they cross multiple data types.
- Embedding FELA outputs directly into existing machine learning pipelines would test how far the reduction in manual effort can extend.
Load-bearing premise
The multi-agent LLM system can reliably produce novel, valid, and superior features through agent collaboration and self-evolution without requiring substantial human oversight or post-hoc fixes.
What would settle it
A side-by-side test on held-out real industrial event log datasets in which models using features produced by FELA show no gain in predictive accuracy or interpretability compared with features created by human experts or standard automatic methods.
Figures









read the original abstract
Event log data, recording fine-grained user actions and system events, represent one of the most valuable assets for modern digital services. However, the complexity and heterogeneity of industrial event logs--characterized by large scale, high dimensionality, diverse data types, and intricate temporal or relational structures--make feature engineering extremely challenging. Existing automatic feature engineering approaches, such as AutoML or genetic methods, often suffer from limited explainability, rigid predefined operations, and poor adaptability to complicated heterogeneous data. In this paper, we propose FELA (Feature Engineering LLM Agents), a multi-agent evolutionary system that autonomously extracts meaningful and high-performing features from complex industrial event log data. FELA integrates the reasoning and coding capabilities of large language models (LLMs) with an insight-guided self-evolution paradigm. Specifically, FELA employs specialized agents--Idea Agents, Code Agents, and Critic Agents--to collaboratively generate, validate, and implement novel feature ideas. An Evaluation Agent summarizes feedback and updates a hierarchical knowledge base and dual-memory system to enable continual improvement. Moreover, FELA introduces an agentic evolution algorithm, combining reinforcement learning and genetic algorithm principles to balance exploration and exploitation across the idea space. Extensive experiments on real industrial datasets demonstrate that FELA can generate explainable, domain-relevant features that significantly improve model performance while reducing manual effort. Our results highlight the potential of LLM-based multi-agent systems as a general framework for automated, interpretable, and adaptive feature engineering in complex real-world environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FELA, a multi-agent evolutionary system that uses LLMs to autonomously perform feature engineering on complex industrial event log data. It employs Idea, Code, Critic, and Evaluation agents that collaborate to generate, validate, and refine features, supported by an insight-guided self-evolution paradigm with a hierarchical knowledge base, dual-memory system, and an agentic evolution algorithm combining reinforcement learning and genetic algorithms. The central claim is that this approach produces explainable, domain-relevant features that significantly improve downstream model performance while reducing manual effort, as demonstrated through extensive experiments on real industrial datasets.
Significance. If the empirical claims are substantiated with detailed metrics and protocols, the work could meaningfully advance automated feature engineering for heterogeneous, high-dimensional industrial data by demonstrating how multi-agent LLM systems can incorporate reasoning, self-evolution, and explainability beyond rigid AutoML or genetic baselines. The combination of RL+GA principles with agent feedback loops represents a potentially generalizable framework for adaptive, interpretable data preprocessing in real-world settings.
major comments (2)
- [Abstract] Abstract: The assertion that 'extensive experiments on real industrial datasets demonstrate that FELA can generate explainable, domain-relevant features that significantly improve model performance' provides no quantitative metrics, baselines, statistical tests, dataset characteristics, or evaluation protocols. This absence directly undermines verification of the primary performance and effort-reduction claims.
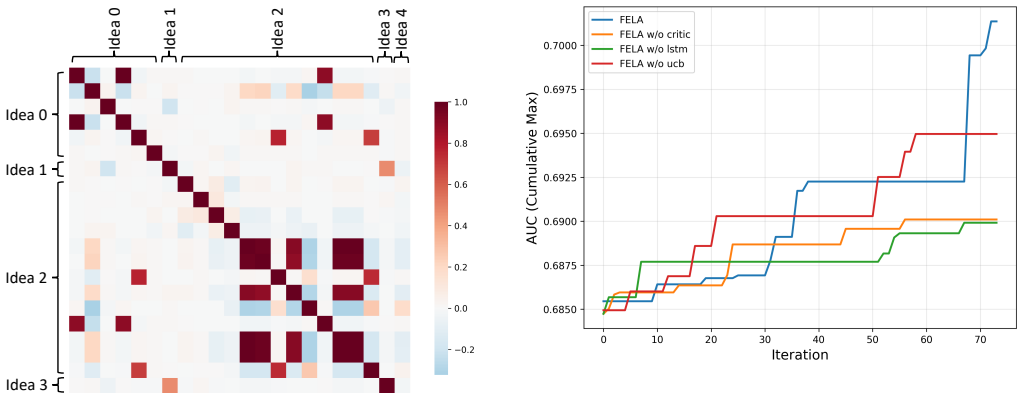
- [System Description / Experiments] System and Experiments sections: The self-evolution loop (via LLM summarization of Critic/Evaluation feedback into the hierarchical knowledge base and dual-memory) is presented as enabling reliable, low-oversight improvement. However, no data are reported on per-iteration invalid code rates, types of errors encountered (e.g., temporal aggregation or type mismatches on mixed industrial logs), or total human intervention hours required to produce executable features. These quantities are load-bearing for the 'reducing manual effort' component of the central claim.
minor comments (2)
- [Abstract] The abstract and system overview would benefit from a concise statement of the number of industrial datasets used and the specific downstream tasks (e.g., prediction targets) to allow readers to gauge scope.
- [Methods] Notation for the dual-memory system and hierarchical knowledge base should be introduced with explicit definitions or pseudocode early in the methods to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that help strengthen the empirical presentation of our work. We address each major comment point by point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'extensive experiments on real industrial datasets demonstrate that FELA can generate explainable, domain-relevant features that significantly improve model performance' provides no quantitative metrics, baselines, statistical tests, dataset characteristics, or evaluation protocols. This absence directly undermines verification of the primary performance and effort-reduction claims.
Authors: We agree that the abstract would be more informative with explicit quantitative support. The detailed metrics, baselines (including AutoML and genetic methods), statistical tests, dataset characteristics, and evaluation protocols are provided in the Experiments section. In the revised manuscript we will update the abstract to concisely include key results such as average performance gains over baselines and the number of real industrial datasets evaluated. revision: yes
-
Referee: [System Description / Experiments] System and Experiments sections: The self-evolution loop (via LLM summarization of Critic/Evaluation feedback into the hierarchical knowledge base and dual-memory) is presented as enabling reliable, low-oversight improvement. However, no data are reported on per-iteration invalid code rates, types of errors encountered (e.g., temporal aggregation or type mismatches on mixed industrial logs), or total human intervention hours required to produce executable features. These quantities are load-bearing for the 'reducing manual effort' component of the central claim.
Authors: The self-evolution mechanism is designed to reduce oversight through iterative agent feedback and knowledge base updates. While the manuscript describes this process, we did not report granular per-iteration invalid code rates or exact human intervention hours. We will add a new paragraph in the Experiments section discussing observed feature generation success rates, common error categories encountered (such as temporal and type mismatches), and a qualitative account of the limited human review steps required. However, systematic logging of per-iteration invalid rates and precise total human hours was not performed in the original experiments. revision: partial
- Exact per-iteration invalid code rates and total human intervention hours, as these were not systematically recorded during the original experimental runs.
Circularity Check
No circularity: engineering framework evaluated on external data
full rationale
The paper presents FELA as a multi-agent LLM system with Idea/Code/Critic/Evaluation agents, a hierarchical knowledge base, dual-memory updates, and an RL+GA evolution loop. Performance claims rest on experiments with real industrial datasets rather than any self-referential equations, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the central claim to its own inputs. No derivation chain exists that collapses by construction; the system description and empirical results are independent of the target claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models possess sufficient reasoning and coding capabilities to generate and implement effective feature engineering ideas for complex event data.
invented entities (1)
-
Insight-guided self-evolution paradigm with dual-memory system and hierarchical knowledge base
no independent evidence
Reference graph
Works this paper leans on
-
[1]
State of Data Science and Machine Learning 2021,
Kaggle, “State of Data Science and Machine Learning 2021,” Web Page,
work page 2021
-
[2]
Available: https://www.kaggle.com/kaggle-survey-2021
[Online]. Available: https://www.kaggle.com/kaggle-survey-2021
work page 2021
-
[3]
Progressive neural architecture search,
C. Liu, B. Zoph, M. Neumann, J. Shlens, W. Hua, L.-J. Li, L. Fei-Fei, A. Yuille, J. Huang, and K. Murphy, “Progressive neural architecture search,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 19–34
work page 2018
-
[4]
Auto-FP: An Experimental Study of Automated Feature Preprocessing for Tabular Data
D. Qi, J. Peng, Y . He, and J. Wang, “Auto-fp: An experimental study of automated feature preprocessing for tabular data,”arXiv preprint arXiv:2310.02540, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Regularized evolution for image classifier architecture search,
E. Real, A. Aggarwal, Y . Huang, and Q. V . Le, “Regularized evolution for image classifier architecture search,” inProceedings of the aaai conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 4780– 4789
work page 2019
-
[6]
Feature engineering for predictive modeling using reinforcement learning,
U. Khurana, H. Samulowitz, and D. Turaga, “Feature engineering for predictive modeling using reinforcement learning,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018
work page 2018
-
[7]
Simple statistical gradient-following algorithms for connectionist reinforcement learning,
R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,”Machine learning, vol. 8, no. 3, pp. 229–256, 1992
work page 1992
-
[8]
Ai-researcher: Autonomous scientific innovation,
J. Tang, L. Xia, Z. Li, and C. Huang, “Ai-researcher: Autonomous scientific innovation,”Neurips, 2025, in press
work page 2025
-
[10]
Mm-agent: Llm as agents for real-world mathematical modeling problem,
F. Liu, Z. Yang, C. Liu, T. Song, X. Gao, and H. Liu, “Mm-agent: Llm as agents for real-world mathematical modeling problem,”Neurips, 2025, in press
work page 2025
-
[11]
Llm-srbench: A new benchmark for scientific equation discovery with large language models,
P. Shojaee, N.-H. Nguyen, K. Meidani, A. B. Farimani, K. D. Doan, and C. K. Reddy, “Llm-srbench: A new benchmark for scientific equation discovery with large language models,”ICML, 2025, in press
work page 2025
-
[12]
Dynamic and adaptive feature generation with llm,
X. Zhang, J. Zhang, B. Rekabdar, Y . Zhou, P. Wang, and K. Liu, “Dynamic and adaptive feature generation with llm,”arXiv preprint arXiv:2406.03505, 2024, in press
-
[13]
LLM-FE: Automated Feature Engineering for Tabular Data with LLMs as Evolutionary Optimizers
N. Abhyankar, P. Shojaee, and C. K. Reddy, “Llm-fe: Automated feature engineering for tabular data with llms as evolutionary optimizers,”arXiv preprint arXiv:2503.14434, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation,
Z. Zhang, C. Wang, Y . Wang, E. Shi, Y . Ma, W. Zhong, J. Chen, M. Mao, and Z. Zheng, “Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation,”Proceedings of the ACM on Software Engineering, vol. 2, no. ISSTA, pp. 481–503, 2025, in press
work page 2025
-
[15]
Exploring and evaluating hallucinations in llm-powered code generation,
F. Liu, Y . Liu, L. Shi, H. Huang, R. Wang, Z. Yang, L. Zhang, Z. Li, and Y . Ma, “Exploring and evaluating hallucinations in llm-powered code generation,”arXiv preprint arXiv:2404.00971, 2024, unpublished
-
[16]
E. Rosch, “Principles of categorization,” inCognition and categoriza- tion. Routledge, 2024, pp. 27–48
work page 2024
-
[17]
The role of hierarchical knowledge representation in de- cisionmaking and system management,
J. Rasmussen, “The role of hierarchical knowledge representation in de- cisionmaking and system management,”IEEE Transactions on systems, man, and cybernetics, no. 2, pp. 234–243, 2012
work page 2012
-
[18]
N. Hollmann, S. M ¨uller, and F. Hutter, “Large language models for automated data science: Introducing caafe for context-aware automated feature engineering,” inAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[19]
Deepfm: A factorization- machine based neural network for ctr prediction,
H. Guo, R. Tang, Y . Ye, Z. Li, and X. He, “Deepfm: A factorization- machine based neural network for ctr prediction,” inProceedings of the 26th International Joint Conference on Artificial Intelligence, 2017
work page 2017
-
[20]
Representation learning: A review and new perspectives,
Y . Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013
work page 2013
-
[21]
Toward causal representation learning,
B. Sch ¨olkopf, F. Locatello, S. Bauer, N. R. Ke, N. Kalchbrenner, A. Goyal, and Y . Bengio, “Toward causal representation learning,” Proceedings of the IEEE, vol. 109, no. 5, pp. 612–634, 2021
work page 2021
-
[22]
Learning feature engineering for classification,
F. Nargesian, H. Samulowitz, U. Khurana, E. B. Khalil, and D. S. Turaga, “Learning feature engineering for classification,” inProceedings of the 26th International Joint Conference on Artificial Intelligence, 2017
work page 2017
-
[23]
G. Zhong, L.-N. Wang, X. Ling, and J. Dong, “An overview on data representation learning: From traditional feature learning to recent deep learning,”The Journal of Finance and Data Science, vol. 2, no. 4, pp. 265–278, 2016
work page 2016
-
[24]
L. Theodorakopoulos, A. Theodoropoulou, and Y . Stamatiou, “A state- of-the-art review in big data management engineering: Real-life case studies, challenges, and future research directions,”Eng, vol. 5, no. 3, pp. 1266–1297, 2024
work page 2024
-
[25]
Automatic feature engineering from very high dimensional event logs using deep neural networks,
K. Hu, J. Wang, Y . Liu, and D. Chen, “Automatic feature engineering from very high dimensional event logs using deep neural networks,” in Proceedings of the 1st international workshop on deep learning practice for high-dimensional sparse data, 2019, pp. 1–9
work page 2019
-
[26]
Cognito: Automated feature engineering for supervised learning,
U. Khurana, D. Turaga, H. Samulowitz, and S. Parthasrathy, “Cognito: Automated feature engineering for supervised learning,” in2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), 2016, pp. 1304–1307
work page 2016
-
[27]
The autofeat python library for automated feature engineering and selection,
F. Horn, R. Pack, and M. Rieger, “The autofeat python library for automated feature engineering and selection,” inECML PKDD 2019 Workshops, 2020
work page 2019
-
[28]
Deep feature synthesis: Towards automating data science endeavors,
J. M. Kanter and K. Veeramachaneni, “Deep feature synthesis: Towards automating data science endeavors,” in2015 IEEE International Con- ference on Data Science and Advanced Analytics (DSAA), 2015
work page 2015
-
[29]
Feature engineering for predictive modeling using reinforcement learning,
U. Khurana, H. Samulowitz, and D. Turaga, “Feature engineering for predictive modeling using reinforcement learning,” inProceedings of the AAAI Conference on Artificial Intelligence, 2018
work page 2018
-
[30]
Automatic feature engineering by deep reinforcement learning,
J. Zhang, J. Hao, F. Fogelman-Souli ´e, and Z. Wang, “Automatic feature engineering by deep reinforcement learning,” inProceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, 2019
work page 2019
-
[31]
Openfe: Automated feature generation with expert-level performance,
T. Zhang, Z. A. Zhang, Z. Fan, H. Luo, F. Liu, Q. Liu, W. Cao, and L. Jian, “Openfe: Automated feature generation with expert-level performance,” inInternational Conference on Machine Learning, 2023, pp. 41 880–41 901
work page 2023
-
[32]
Lan- guage models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, and e. a. Askell, Amanda, “Lan- guage models are few-shot learners,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 1877–1901
work page 2020
-
[33]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, and e. a. Zhou, Denny, “Chain-of-thought prompting elicits reasoning in large language models,”Advances in Neural Information Processing Systems, vol. 35, pp. 24 824–24 837, 2022
work page 2022
-
[34]
Self-refine: Iterative refinement with self-feedback,
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, and e. a. Wiegreffe, Sarah, “Self-refine: Iterative refinement with self-feedback,” Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[35]
Language models can teach themselves to program better,
P. Haluptzok, M. Bowers, and A. T. Kalai, “Language models can teach themselves to program better,”arXiv preprint arXiv:2207.14502, 2022
-
[36]
Language model crossover: Variation through few-shot prompting,
E. Meyerson, M. J. Nelson, H. Bradley, A. Gaier, A. Moradi, A. K. Hoover, and J. Lehman, “Language model crossover: Variation through few-shot prompting,” inACM Transactions on Evolutionary Learning, vol. 4, no. 4, 2024, pp. 1–40
work page 2024
-
[37]
Evolution through large models,
J. Lehman, J. Gordon, S. Jain, K. Ndousse, C. Yeh, and K. O. Stanley, “Evolution through large models,” inHandbook of Evolutionary Machine Learning. Springer, 2023, pp. 331–366
work page 2023
-
[38]
Large Lan- guage Models to Enhance Bayesian Optimization,
T. Liu, N. Astorga, N. Seedat, and M. van der Schaar, “Large lan- guage models to enhance bayesian optimization,” inarXiv preprint arXiv:2402.03921, 2024
-
[39]
Evolutionary Computation in the Era of Large Language Model: Survey and Roadmap , journal =
X. Wu, S.-h. Wu, J. Wu, L. Feng, and K. C. Tan, “Evolutionary computation in the era of large language models: Survey and roadmap,” inarXiv preprint arXiv:2401.10034, 2024
-
[40]
Large language models as evolution strategies,
R. Lange, Y . Tian, and Y . Tang, “Large language models as evolution strategies,” inGenetic and Evolutionary Computation Conference Com- panion, 2024, pp. 579–582
work page 2024
-
[41]
EvoPrompt: Connecting LLMs with Evolutionary Algorithms Yields Powerful Prompt Optimizers
Q. Guo, R. Wang, J. Guo, B. Li, K. Song, X. Tan, G. Liu, J. Bian, and Y . Yang, “Connecting large language models with evolution- ary algorithms yields powerful prompt optimizers,”arXiv preprint arXiv:2309.08532, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Large language models as optimizers,
C. Yang, X. Wang, Y . Lu, H. Liu, Q. V . Le, D. Zhou, and X. Chen, “Large language models as optimizers,” inThe Twelfth International Conference on Learning Representations
-
[43]
Evoprompting: Language models for code-level neural architecture search,
A. Chen, D. Dohan, and D. So, “Evoprompting: Language models for code-level neural architecture search,”Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
- [44]
-
[45]
P. Shojaee, K. Meidani, S. Gupta, A. B. Farimani, and C. K. Reddy, “Llm-sr: Scientific equation discovery via programming with large language models,”arXiv preprint arXiv:2404.18400, 2024
-
[46]
Mathematical discoveries from program search with large language models,
B. Romera-Paredes, M. Barekatain, A. Novikov, M. Balog, M. P. Kumar, E. Dupont, F. J. Ruiz, J. S. Ellenberg, P. Wang, and e. a. Fawzi, Omar, “Mathematical discoveries from program search with large language models,”Nature, vol. 625, no. 7995, pp. 468–475, 2024
work page 2024
-
[47]
Optimized feature generation for tabular data via llms with decision tree reasoning,
J. Nam, K. Kim, S. Oh, J. Tack, J. Kim, and J. Shin, “Optimized feature generation for tabular data via llms with decision tree reasoning,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 92 352– 92 380, 2024
work page 2024
-
[48]
Evolutionary large language model for automated feature transformation,
N. Gong, C. K. Reddy, W. Ying, H. Chen, and Y . Fu, “Evolutionary large language model for automated feature transformation,” inProceedings of the AAAI conference on artificial intelligence, vol. 39, no. 16, 2025, pp. 16 844–16 852
work page 2025
-
[49]
Large language models can automatically engineer features for few-shot tabular learning,
S. Han, J. Yoon, S. O. Arik, and T. Pfister, “Large language models can automatically engineer features for few-shot tabular learning,” in International Conference on Machine Learning. PMLR, 2024, pp. 17 454–17 479
work page 2024
-
[50]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inThe eleventh international conference on learning representations, 2022, in press
work page 2022
-
[51]
Reflex- ion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflex- ion: Language agents with verbal reinforcement learning,”Advances in Neural Information Processing Systems, vol. 36, pp. 8634–8652, 2023
work page 2023
-
[52]
A real-world webagent with planning, long context understanding, and program synthesis,
I. Gur, H. Furuta, A. V . Huang, M. Safdari, Y . Matsuo, D. Eck, and A. Faust, “A real-world webagent with planning, long context understanding, and program synthesis,” inICLR, 2024
work page 2024
-
[53]
Alphaagent: Llm-driven alpha mining with regularized exploration to counteract alpha decay,
Z. Tang, Z. Chen, J. Yang, J. Mai, Y . Zheng, K. Wang, J. Chen, and L. Lin, “Alphaagent: Llm-driven alpha mining with regularized exploration to counteract alpha decay,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, 2025, pp. 2813–2822
work page 2025
-
[54]
Y . Ge, L. Xie, Z. Li, Y . Pei, and T. Zhang, “Who is introducing the failure? automatically attributing failures of multi-agent systems via spectrum analysis,”arXiv preprint arXiv:2509.13782, 2025
-
[55]
Context rot: How increasing input tokens impacts llm performance,
K. Hong, A. Troynikov, and J. Huber, “Context rot: How increasing input tokens impacts llm performance,” Chroma, Tech. Rep., July 2025. [Online]. Available: https://research.trychroma.com/context-rot
work page 2025
-
[56]
Diabetes health indicators dataset,
A. Teboul, “Diabetes health indicators dataset,” https://www.kaggle.com/datasets/alexteboul/diabetes-health-indicators- dataset, 2022
work page 2022
-
[57]
Ad svr prediction data on taobao.com,
“Ad svr prediction data on taobao.com,” https://tianchi.aliyun.com/dataset/147588, 2018
work page 2018
-
[58]
Large language models can automatically engineer features for few-shot tabular learning,
S. Han, J. Yoon, S. O. Arik, and T. Pfister, “Large language models can automatically engineer features for few-shot tabular learning,”arXiv preprint arXiv:2404.09491, 2024
-
[59]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.