Morphology-Aware Graph Reinforcement Learning for Tensegrity Robot Locomotion
Pith reviewed 2026-05-18 03:49 UTC · model grok-4.3
The pith
Encoding a tensegrity robot's connections as a graph in its control policy enables direct transfer of locomotion skills from simulation to real hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
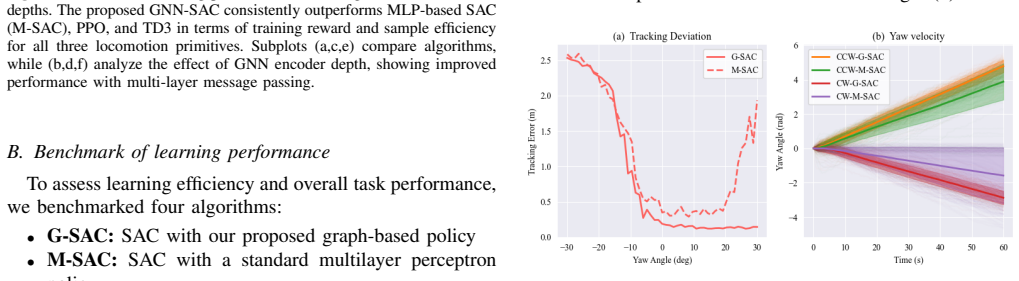
The authors state that representing the tensegrity robot's physical topology as a graph inside a graph neural network policy, integrated with Soft Actor-Critic, captures coupling among components. This yields faster and more stable learning than multilayer perceptron policies, along with higher sample efficiency, robustness to noise and stiffness variations, better trajectory accuracy, and direct transfer from simulation to hardware that produces stable real-world locomotion on three primitives for a physical 3-bar tensegrity robot.
What carries the argument
A graph neural network embedded in the policy that encodes the robot's rod-cable topology as nodes and edges to model dynamic couplings between components during reinforcement learning.
If this is right
- The graph-based policies require fewer training samples to achieve effective locomotion control than multilayer perceptron baselines.
- Performance holds up under sensor noise and changes in cable stiffness.
- Trajectory accuracy improves for straight-line tracking and bidirectional turning in both simulation and on hardware.
- Policies trained in simulation produce stable real-world locomotion on the physical robot without any fine-tuning.
Where Pith is reading between the lines
- The same graph encoding of structure could support control of other robots that combine rigid and elastic parts.
- Strong structural priors in the policy might allow simpler physics models in simulation for related underactuated systems.
- Testing the method on tensegrity robots with more bars or varied cable arrangements would show whether the benefits scale.
Load-bearing premise
Modeling the robot's connections as a graph in the control policy is sufficient to handle the important interactions for movement without needing explicit models of cable stretch or ground contact.
What would settle it
Showing that a standard multilayer perceptron policy achieves equivalent sample efficiency, robustness, trajectory accuracy, and direct sim-to-real transfer for stable locomotion on the same physical 3-bar tensegrity robot would undermine the advantage of the graph representation.
Figures







read the original abstract
Tensegrity robots combine rigid rods and elastic cables, offering high resilience and deployability but at the same time posing major challenges for locomotion control due to their underactuated and highly coupled dynamics. This paper introduces a morphology-aware reinforcement learning framework that integrates a graph neural network (GNN) into the Soft Actor-Critic (SAC) algorithm. By representing the robot's physical topology as a graph, the proposed GNN-based policy captures coupling among components, enabling faster and more stable learning than conventional multilayer perceptron (MLP) policies. The method is validated on a physical 3-bar tensegrity robot across three locomotion primitives, including straight-line tracking and bidirectional turning. It shows superior sample efficiency, robustness to noise and stiffness variations, and improved trajectory accuracy. Additionally, the learned policies transfer directly from simulation to hardware without fine-tuning, achieving stable real-world locomotion. These results demonstrate the advantages of incorporating structural priors into reinforcement learning for tensegrity robot control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a morphology-aware RL method that embeds a graph neural network into the Soft Actor-Critic algorithm to control a 3-bar tensegrity robot. The robot is represented as a fixed graph of rods and cables so that the policy can exploit structural couplings; the authors report faster learning than MLP baselines, robustness to noise and stiffness changes, and direct sim-to-real transfer without fine-tuning for straight-line tracking and bidirectional turning primitives on physical hardware.
Significance. If the empirical claims hold, the work supplies concrete evidence that structural priors encoded via GNNs can improve sample efficiency and zero-shot hardware transfer for underactuated tensegrity systems. Such results would be useful for the broader robotics community working on compliant, high-dimensional platforms where explicit dynamics modeling is difficult.
major comments (1)
- [§4 and §5] §4 (Method) and §5 (Experiments): the central sim-to-real claim requires that the static morphology graph alone encodes the dominant dynamic couplings, including intermittent ground contacts and cable elasticity. The manuscript describes a fixed graph topology but provides no indication of dynamic graph updates or explicit contact-force modeling; without ablation on contact-rich versus contact-free regimes or quantitative metrics (e.g., success rate, trajectory RMSE with error bars) showing invariance to these effects, it remains unclear whether the reported transfer exploits simulation-specific artifacts rather than invariant dynamics.
minor comments (2)
- [Abstract] The abstract asserts 'superior sample efficiency, robustness, and trajectory accuracy' yet supplies no numerical values, statistical tests, or baseline comparisons; these quantitative details should be added to the abstract and highlighted in the results section.
- [§3] Notation for the GNN message-passing update and the SAC actor-critic losses should be unified across §3 and §4 to avoid ambiguity when readers compare the morphology-aware policy to the MLP baseline.
Simulated Author's Rebuttal
We thank the referee for their valuable feedback. We respond to the major comment as follows and will make corresponding revisions to strengthen the paper.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Method) and §5 (Experiments): the central sim-to-real claim requires that the static morphology graph alone encodes the dominant dynamic couplings, including intermittent ground contacts and cable elasticity. The manuscript describes a fixed graph topology but provides no indication of dynamic graph updates or explicit contact-force modeling; without ablation on contact-rich versus contact-free regimes or quantitative metrics (e.g., success rate, trajectory RMSE with error bars) showing invariance to these effects, it remains unclear whether the reported transfer exploits simulation-specific artifacts rather than invariant dynamics.
Authors: We agree with the observation that the morphology graph is static and does not include dynamic updates or explicit contact modeling. The fixed graph captures the invariant physical topology of the tensegrity structure, enabling the GNN to learn message-passing rules that reflect how forces and states propagate through rods and cables. Intermittent contacts and elasticity are accounted for in the physics simulator used for training, and the policy is optimized to produce robust actions under these conditions. Our reported robustness to stiffness changes indirectly supports handling of elasticity variations. To provide stronger evidence against simulation artifacts, we will revise the manuscript to include: (i) an ablation study comparing locomotion performance in contact-rich environments versus contact-free regimes (e.g., by disabling ground contacts in simulation), and (ii) quantitative results with error bars, including success rates and trajectory RMSE for the sim-to-real transfers. These additions will demonstrate the contribution of the morphology-aware encoding to the observed zero-shot transfer. We thank the referee for highlighting this point, which will improve the clarity of our empirical validation. revision: partial
Circularity Check
No circularity: empirical RL method validated on hardware
full rationale
The paper describes an algorithmic framework that embeds a fixed-topology GNN into SAC for policy learning on a tensegrity robot, with performance measured via simulation training curves, baseline comparisons, and direct sim-to-real transfer on physical hardware. No derivation chain, uniqueness theorem, or fitted parameter is presented that reduces to its own inputs by construction. Claims rest on external empirical benchmarks rather than self-referential definitions or self-citation loops. The graph encoding is a design choice whose value is assessed against independent metrics, not asserted as tautological.
Axiom & Free-Parameter Ledger
free parameters (2)
- GNN architecture hyperparameters
- SAC reward and entropy coefficients
axioms (2)
- domain assumption The robot's dynamics can be adequately captured by a graph whose nodes are rigid bars and elastic cables and whose edges encode physical connections.
- domain assumption Simulation dynamics are sufficiently accurate that policies trained in simulation transfer to hardware without fine-tuning.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By representing the robot’s physical topology as a graph, the proposed GNN-based policy captures coupling among components
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GNN encoder: message generated from vertex Vi to neighbor Vj as M(Vi,Vj)=MLP_m(Vi,Vj,Ei,j)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
R. E. Skelton and M. C. De Oliveira,Tensegrity systems. Springer, 2009, vol. 1. [Online]. Available: https://link.springer.com/book/10. 1007/978-0-387-74242-7
work page 2009
-
[2]
Tensegrity robot proprioceptive state estimation with geometric constraints,
W. Tong, T.-Y . Lin, J. Mi, Y . Jiang, M. Ghaffari, and X. Huang, “Tensegrity robot proprioceptive state estimation with geometric constraints,”IEEE Robotics and Automation Letters, vol. 10, no. 4, pp. 4069–4076, 2025. [Online]. Available: https://ieeexplore.ieee.org/ document/10910166
-
[3]
Design of a variable stiffness quasi-direct drive cable-actuated tensegrity robot,
J. Mi, W. Tong, Y . Ma, and X. Huang, “Design of a variable stiffness quasi-direct drive cable-actuated tensegrity robot,”IEEE Robotics and Automation Letters, 2025. [Online]. Available: https: //ieeexplore.ieee.org/document/11072300
-
[4]
D. S. Shah, J. W. Booth, R. L. Baines, K. Wang, M. Vespignani, K. Bekris, and R. Kramer-Bottiglio, “Tensegrity robotics,”Soft robotics, vol. 9, no. 4, pp. 639–656, 2022. [Online]. Available: https://www.liebertpub.com/doi/epub/10.1089/soro.2020.0170
-
[5]
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis, “Human-level control through deep reinforcement learning,”Nature, vol. 518, no. 7540, pp. 529–533, 2015. [Online]...
-
[6]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” 2018. [Online]. Available: https://openreview.net/ forum?id=HJjvxl-Cb
work page 2018
-
[7]
Design and control of tensegrity robots for locomotion,
C. Paul, F. Valero-Cuevas, and H. Lipson, “Design and control of tensegrity robots for locomotion,”IEEE Transactions on Robotics, vol. 22, no. 5, pp. 944–957, 2006
work page 2006
-
[8]
Gait production in a tensegrity based robot,
C. Paul, J. Roberts, H. Lipson, and F. Valero Cuevas, “Gait production in a tensegrity based robot,” inICAR ’05. Proceedings., 12th Interna- tional Conference on Advanced Robotics, 2005., 2005, pp. 216–222
work page 2005
-
[9]
Robust learning of tensegrity robot control for locomotion through form-finding,
K. Kim, A. K. Agogino, A. Toghyan, D. Moon, L. Taneja, and A. M. Agogino, “Robust learning of tensegrity robot control for locomotion through form-finding,” in2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2015, pp. 5824–5831
work page 2015
-
[10]
Rolling locomotion of cable-driven soft spherical tensegrity robots,
K. Kim, A. K. Agogino, and A. M. Agogino, “Rolling locomotion of cable-driven soft spherical tensegrity robots,”Soft Robotics, vol. 7, no. 3, pp. 346–361, 2020, pMID: 32031916. [Online]. Available: https://doi.org/10.1089/soro.2019.0056
-
[11]
Full-actuation rolling locomotion with tensegrity robot via deep reinforcement learning,
Y . Guo and H. Peng, “Full-actuation rolling locomotion with tensegrity robot via deep reinforcement learning,” in2021 5th International Conference on Robotics and Automation Sciences (ICRAS), 2021, pp. 51–55
work page 2021
-
[12]
Real2sim2real transfer for control of cable-driven robots via a differentiable physics engine,
K. Wang, W. R. Johnson, S. Lu, X. Huang, J. Booth, R. Kramer- Bottiglio, M. Aanjaneya, and K. Bekris, “Real2sim2real transfer for control of cable-driven robots via a differentiable physics engine,” in 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023, pp. 2534–2541
work page 2023
-
[13]
B. Cera and A. M. Agogino, “Multi-cable rolling locomotion with spherical tensegrities using model predictive control and deep learn- ing,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018, pp. 1–9
work page 2018
-
[14]
Continuous control with deep reinforcement learning
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforce- ment learning,”arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[15]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” 2017. [Online]. Available: https://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Addressing function approxi- mation error in actor-critic methods,
S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approxi- mation error in actor-critic methods,” inInternational conference on machine learning. PMLR, 2018, pp. 1587–1596
work page 2018
-
[17]
Learning dexterous in-hand manipulation,
O. M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. Mc- Grew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Rayet al., “Learning dexterous in-hand manipulation,”The International Journal of Robotics Research, vol. 39, no. 1, pp. 3–20, 2020
work page 2020
-
[18]
J. Hwangbo, J. Lee, A. Dosovitskiy, D. Bellicoso, V . Tsounis, V . Koltun, and M. Hutter, “Learning agile and dynamic motor skills for legged robots,”Science Robotics, vol. 4, no. 26, Jan. 2019. [Online]. Available: http://dx.doi.org/10.1126/scirobotics.aau5872
-
[19]
D. Gandhi, L. Pinto, and A. Gupta, “Learning to fly by crashing,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017, pp. 3948–3955
work page 2017
-
[20]
Domain randomization for transferring deep neural networks from simulation to the real world,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” in2017 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS), 2017, pp. 23–30
work page 2017
-
[21]
Deep reinforcement learning for tensegrity robot locomotion,
M. Zhang, X. Geng, J. Bruce, K. Caluwaerts, M. Vespignani, V . Sun- Spiral, P. Abbeel, and S. Levine, “Deep reinforcement learning for tensegrity robot locomotion,” in2017 IEEE International Conference on Robotics and Automation (ICRA), 2017, pp. 634–641
work page 2017
-
[22]
Tensegrity robot locomotion under limited sensory inputs via deep reinforcement learning,
J. Luo, R. Edmunds, F. Rice, and A. M. Agogino, “Tensegrity robot locomotion under limited sensory inputs via deep reinforcement learning,” in2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 6260–6267
work page 2018
-
[23]
Adaptive Tensegrity Locomotion on Rough Terrain via Reinforcement Learning
D. Surovik, K. Wang, and K. E. Bekris, “Adaptive tensegrity locomotion on rough terrain via reinforcement learning,” 2018. [Online]. Available: https://arxiv.org/abs/1809.10710
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
D. Surovik, K. Wang, M. Vespignani, J. Bruce, and K. E. Bekris, “Adaptive tensegrity locomotion: Controlling a compliant icosahedron with symmetry-reduced reinforcement learning,”The International Journal of Robotics Research, vol. 40, no. 1, pp. 375–396, 2021. [Online]. Available: https://doi.org/10.1177/0278364919859443
-
[25]
Nervenet: Learning structured policy with graph neural networks,
T. Wang, R. Liao, J. Ba, and S. Fidler, “Nervenet: Learning structured policy with graph neural networks,” inInternational Conference on Learning Representations, 2018. [Online]. Available: https://openreview.net/forum?id=S1sqHMZCb
work page 2018
-
[26]
Universal morphology control via contextual modulation,
Z. Xiong, J. Beck, and S. Whiteson, “Universal morphology control via contextual modulation,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 38 286–38 300
work page 2023
-
[27]
Learning differentiable tensegrity dynamics using graph neural networks,
N. Chen, K. Wang, W. R. Johnson III, R. Kramer-Bottiglio, K. Bekris, and M. Aanjaneya, “Learning differentiable tensegrity dynamics using graph neural networks,”arXiv preprint arXiv:2410.12216, 2024
-
[28]
Sim2sim evaluation of a novel data-efficient differentiable physics engine for tensegrity robots,
K. Wang, M. Aanjaneya, and K. Bekris, “Sim2sim evaluation of a novel data-efficient differentiable physics engine for tensegrity robots,” in2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 1694–1701
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.